Mamdani's algorithm in fuzzy inference systems
Introduction
It just so happened that it is customary to start any article about fuzzy logic by mentioning the name Lotfi Zadeh. And I will not be an exception. The fact is that this man became not only the founding father of a whole scientific theory, writing the fundamental work “Fuzzy Sets” in 1965, but also worked out various possibilities for its practical application. He described his approach in 1973 in the text “Outline of a New Approach to the Analysis of Complex Systems and Decision Processes” (published in the journal IEEE Transactions on Systems). It is noteworthy that immediately after its release, one enterprising Danish company very successfully applied the principles set forth in it to improve its management system for a complex production process.
But with all the merits of L. Zade, the followers of this theory made an equally important contribution. For example, the English mathematician E. Mamdani (Ebrahim Mamdani). In 1975, he developed an algorithm that was proposed as a method for controlling a steam engine. The algorithm he proposed, based on fuzzy inference, made it possible to avoid an excessively large amount of computation and was appreciated by specialists. This algorithm has currently received the greatest practical application in fuzzy modeling problems.
Key Definitions
Before you begin familiarizing yourself with the algorithm, it is important to briefly familiarize yourself with the following definitions: A
fuzzy variable is a tuple of the form <α, X , Α >, where:
α is the name of the fuzzy variable;
X is its domain of definition;
A - fuzzy set in the universe of X .
Example: Fuzzy variable <"Heavy body armor", { x | 0 kg < x <35 kg}, B = { x , μ ( x )}> characterizes the mass of military body armor. We will consider it heavy if its mass is> 16 kg (Fig. 1).
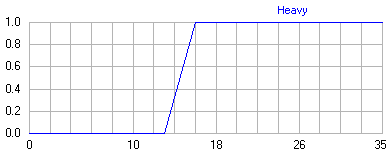
Fig. 1. The graph of the membership function μ ( x ) for a fuzzy set B. A
linguistic variable is a tuple <β, T, X, G, M >, where:
β is the name of the linguistic variable;
T is the set of its meanings (terms);
X is the universe of fuzzy variables;
G is the syntactic procedure for the formation of new terms;
M is a semantic procedure that forms fuzzy sets for each term of a given linguistic variable.
Example:Suppose we have a subjective assessment of the mass of body armor. It, for example, can be obtained from military personnel (acting as experts) who directly deal with such ammunition. This assessment can be formalized using the following linguistic variable <β, T, X, G, M > (Fig. 2), where:
β - Bulletproof vest;
T - {"Light body armor (Light)", "Medium-weight body armor (Medium)", "Heavy body armor (Heavy)"};
X = [0; 35];
G - the procedure for the formation of new terms using logical connectives and modifiers. For example, “very heavy body armor”;
M is the task procedure on the universe X = [0; 35] values of the linguistic variable, ie terms from the setT .
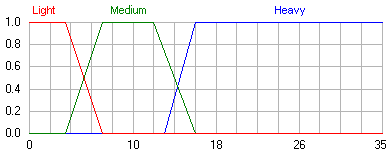
Fig. 2. Graphs of membership functions of the values of the linguistic variable “Bulletproof vest” A
fuzzy statement will be a statement of the form “β IS α”, where:
β is a linguistic variable;
α is one of the terms of this variable.
Example: “IS Lightweight Body Armor.” Here "Bulletproof vest" is a linguistic variable, and its "light" meaning.
To put it simply, the rule of fuzzy products (hereinafter simply the rule) will be called the classic rule of the form “IF ... THEN ...”, where fuzzy statements will be used as conditions and conclusions. Such rules are written in the following form:
IF (β 1 IS α 1 ) AND (β 2 IS α 2) THEN (β 3 IS α 3 ).
In addition to “AND”, the logical connective “OR” is also used. But they usually try to avoid such a record by dividing such rules into several simpler ones (without "OR"). Also, each of the fuzzy statements in the condition of any rule will be called a subcondition . Similarly, each of the statements in the conclusion is called a subclause .
Example: The following examples will help to fix the definition:
1) IF (heavy body armor) THEN (tired soldier);
2) IF (Husband is sober) AND (High salary) THEN (Satisfied wife).
All. This minimum is enough for understanding the principles of the algorithm.
Mamdani Algorithm
This algorithm describes several successive stages (Fig. 3). At the same time, each subsequent stage receives the values obtained in the previous step as input.

Fig. 3. The activity diagram of the fuzzy inference process
The algorithm is noteworthy in that it works on the principle of a “black box”. The input receives quantitative values, the output is the same. At the intermediate stages, the apparatus of fuzzy logic and the theory of fuzzy sets are used. This is the elegance of using fuzzy systems. You can manipulate the usual numerical data, but at the same time use the flexible features that fuzzy inference systems provide.
To implement the algorithm, an object-oriented approach was used. The source code is written in the Java programming language. The diagram (Fig. 4) shows the most significant relationships and relationships between the classes involved in the algorithm.
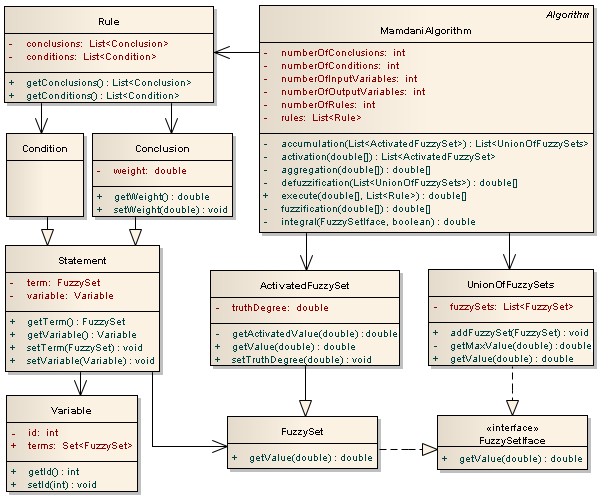
Fig. 4. Class diagram of the implementation of the Mamdani algorithm
Rules (Rule) consist of conditions (Condition) and conclusions (Conclusion), which in turn are fuzzy statements (Statement). A fuzzy statement includes a linguistic variable (Variable) and a term that is represented by a fuzzy set (FuzzySet). A membership function is defined on a fuzzy set, the value of which can be obtained using the getValue () method. This is the method defined in the FuzzySetIface interface. When executing the algorithm, it will be necessary to use the “activated” fuzzy set (ActivatedFuzzySet), which in some way redefines the membership function of the fuzzy set (FuzzySet). The algorithm also uses a union of fuzzy sets (UnionOfFuzzySets). The union is also a fuzzy set,
Mamdani Algorithm (MamdaniAlgorithm), includes all the stages (Fig. 3) and uses the rule base (List
So, the stages of fuzzy inference are performed sequentially. And all the values obtained in the previous step can be used in the next.
1. Formation of a rule base A rule
base is a set of rules where a specific weight coefficient is associated with each subclause.
The rule base can have the following form (for example, the rules of various constructions are used):
RULE_1: IF “Condition_1” THEN “Conclusion_1” ( F 1 ) AND “Conclusion_2” ( F 2 );
RULE_2: IF "Condition_2" AND "Condition_3" THEN "Conclusion_3" (F 3 );
...
RULE_n: IF “Condition_k” THEN “Conclusion_ (q-1)” ( F q-1 ) AND “Conclusion_q” ( F q );
Where F i - weighting coefficients, indicating the degree of confidence in the truth of the resulting subcontract ( i = 1 .. q ). By default, the weighting factor is assumed to be 1. Linguistic variables present in conditions are called input , and in conclusions output .
Legend:
n - the number of fuzzy production rules (numberOfRules).
m - number of input variables (numberOfInputVariables).
s- number of output variables (numberOfOutputVariables).
k is the total number of subconditions in the rule base (numberOfConditions).
q is the total number of subconnections in the rule base (numberOfConclusions).
Note: These designations will be used in subsequent steps. In parentheses are the names of the corresponding variables in the source code.
2. Fuzzification of input variables
This stage is often called reduction to fuzziness. The formed rule base and the input data array A = {a 1 , ..., a m}. This array contains the values of all input variables. The purpose of this step is to obtain truth values for all sub-conditions from the rule base. This happens as follows: for each of the subconditions, the value b i = μ ( a i ) is found. Thus, the set of values b i ( i = 1 .. k ) is obtained .
Implementation: Note: The input data array is formed in such a way that the i- th element of the array corresponds to the i- th input variable (the variable number is stored in the integer field "id"). 3. Aggregation of preconditions
private double[] fuzzification(double[] inputData) {
int i = 0;
double[] b = new double[numberOfConditions];
for (Rule rule : rules) {
for (Condition condition : rule.getConditions()) {
int j = condition.getVariable().getId();
FuzzySet term = condition.getTerm();
b[i] = term.getValue(inputData[j]);
i++;
}
}
return b;
}As mentioned above, a rule condition can be composite, i.e. include subconditions interconnected using the logical AND operation. The purpose of this stage is to determine the degree of truth of the conditions for each rule of the fuzzy inference system. Simply put, for each condition we find the minimum truth value of all its subconditions. Formally, it looks like this:
c j = min { b i }.
Where:
j = 1 .. n ;
i is the number from the set of numbers of subconditions in which the j- th input variable is involved .
Implementation: 4. Activation of subcontracts
private double[] aggregation(double[] b) {
int i = 0;
int j = 0;
double[] c = new double[numberOfInputVariables];
for (Rule rule : rules) {
double truthOfConditions = 1.0;
for (Condition condition : rule.getConditions()) {
truthOfConditions = Math.min(truthOfConditions, b[i]);
i++;
}
c[j] = truthOfConditions;
j++;
}
return c;
}At this stage, there is a transition from conditions to subcontracts. For each subscription, the degree of truth is found d i = c i * F i , where i = 1 .. q . Then, again, for each i- th subclusion, the set D i is associated with a new membership function. Its value is determined from at least d i and the value of the term membership function from the subclause. This method is called min-activation, which is formally written as follows:
μ ' i ( x ) = min { d i, μ i ( x )}.
Where:
μ ' i ( x ) - “activated” membership function;
μ i ( x ) is the membership function of the term;
d i - the degree of truth of the i- th subconnection.
So, the goal of this stage is to obtain a set of “activated” fuzzy sets D i for each of the subclauses in the rule base ( i = 1 .. q ).
Implementation: 5. Accumulation of conclusions
private List activation(double[] c) {
int i = 0;
List activatedFuzzySets = new ArrayList();
double[] d = new double[numberOfConclusions];
for (Rule rule : rules) {
for (Conclusion conclusion : rule.getConclusions()) {
d[i] = c[i]*conclusion.getWeight();
ActivatedFuzzySet activatedFuzzySet = (ActivatedFuzzySet) conclusion.getTerm();
activatedFuzzySet.setTruthDegree(d[i]);
activatedFuzzySets.add(activatedFuzzySet);
i++;
}
}
return activatedFuzzySets;
} private double getActivatedValue(double x) {
return Math.min(super.getValue(x), truthDegree);
}The purpose of this step is to obtain a fuzzy set (or their combination) for each of the output variables. It is performed as follows: the i- th output variable is associated with the union of the sets E i = ∪ D j . Where j are the numbers of the subconnections in which the i -th output variable is involved ( i = 1 .. s ). The union of two fuzzy sets is the third fuzzy set with the following membership function:
μ ' i ( x ) = max {μ 1 ( x ), μ 2 ( x )}, where μ1 ( x ), μ 2 ( x ) are membership functions of joined sets.
Implementation: 6. Defuzzification of output variables. The purpose of defuzzification is to obtain a crisp value for each of the output linguistic variables. Formally, this happens as follows. The i- th output variable and the set E i ( i = 1 .. s ) related to it are considered . Then, using the defuzzification method, the final quantitative value of the output variable is found. In this implementation of the algorithm, the center of gravity method is used, in which the value of i
private List accumulation(List activatedFuzzySets) {
List unionsOfFuzzySets =
new ArrayList(numberOfOutputVariables);
for (Rule rule : rules) {
for (Conclusion conclusion : rule.getConclusions()) {
int id = conclusion.getVariable().getId();
unionsOfFuzzySets.get(id).addFuzzySet(activatedFuzzySets.get(id));
}
}
return unionsOfFuzzySets;
} private double getMaxValue(double x) {
double result = 0.0;
for (FuzzySet fuzzySet : fuzzySets) {
result = Math.max(result, fuzzySet.getValue(x));
}
return result;
}-th output variable is calculated by the formula:
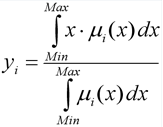
Where:
μ i ( x ) - membership function of the corresponding fuzzy set E i ;
Min and Max are the boundaries of the universe of fuzzy variables;
y i is the result of defazzification.
Implementation:
private double[] defuzzification(List unionsOfFuzzySets) {
double[] y = new double[numberOfOutputVariables];
for(int i = 0; i < numberOfOutputVariables; i++) {
double i1 = integral(unionsOfFuzzySets.get(i), true);
double i2 = integral(unionsOfFuzzySets.get(i), false);
y[i] = i1 / i2;
}
return y;
} Conclusion
Mamdani's algorithm and many other fuzzy inference algorithms are already implemented in such wonderful products as the Fuzzy Logic Toolbox (extension for MatLab), fuzzyTECH and many others. Therefore, such a detailed consideration of the algorithm, as in this article, has more theoretical value than practical. However, I note that only with a solid foundation of knowledge and understanding of the basics of the algorithm does it become possible to apply it with maximum effect.
Literature
For those who want to get acquainted with concrete examples of the application of the described algorithm, I recommend that you turn to the following literature:
1. Leonenkov A.V. Fuzzy modeling in MATLAB and fuzzyTECH / A. Leonenkov. - St. Petersburg: BHV-Petersburg, 2003 .-- 736 p.
2. Shtovba S.D. Designing fuzzy systems using MATLAB / S. Shtovba. - M: Hotline – Telecom, 2007. - 288 p.