Containers: Searches for the “magic framework” and why Kubernetes became it

We at Later are engaged in creating billing for telecom operators . In the blog on Habré we not only talk about the features of our system and the details of its development (for example, ensuring fault tolerance ), but also publish materials on working with the infrastructure as a whole. Haleby.se project engineer wrote in a blog material , in which he spoke about the reasons for the selection as an instrument orchestration Kubernetes technology-Docker containers. We present to your attention the main thoughts of this article.
Background
The project engineering team initially used the Jenkins continuous delivery methodology for each service. This allowed you to run integration tests on each commit, generate an artifact and a Docker image, and then deploy it on a test server. With a single click, any image could be deployed to a “battle” server. The diagram looked something like this:
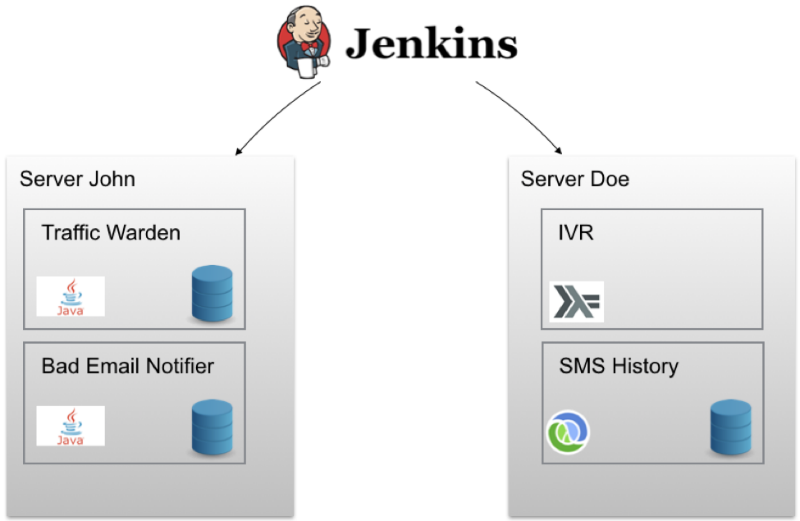
Cells called John and Doe contain sets of Docker containers deployed on a specific node. In addition, Ansible is used for provisioning.. As a result, you can create a new cloud server and install the correct version of Docker / Docker-Compose on it, configure firewall rules and perform other settings with a single command. For each service running in the Docker container there are watchdog scripts that “raise” it in the event of a failure. But in this configuration, problems are possible.
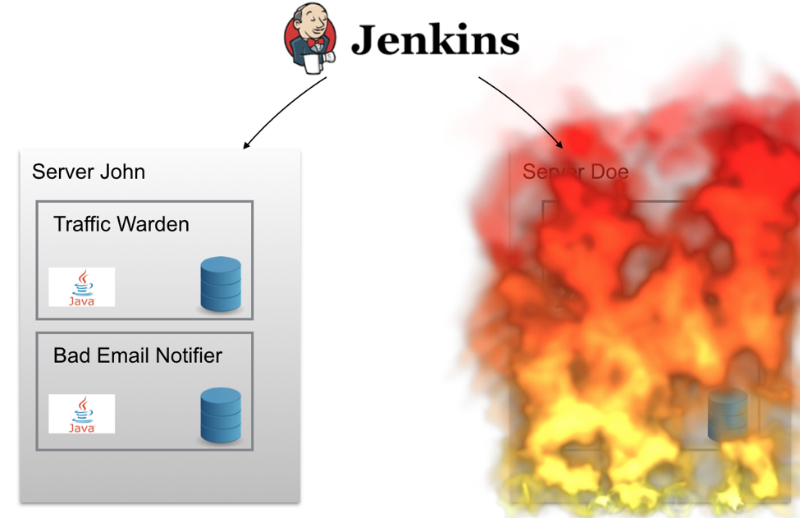
If the Doe server “burns out” one night (or just a short-term serious failure occurs on it), the project technical team will have to rise in the middle of the night to return the system to a working state. Services installed on Doe do not automatically move to another server - for example, John, so for some time the system would stop working.
There are other difficulties - the location on the same node of the maximum number of containers, network discovery (service discovery), "upload" updates, aggregation of log data. It was necessary to somehow cope with all this.
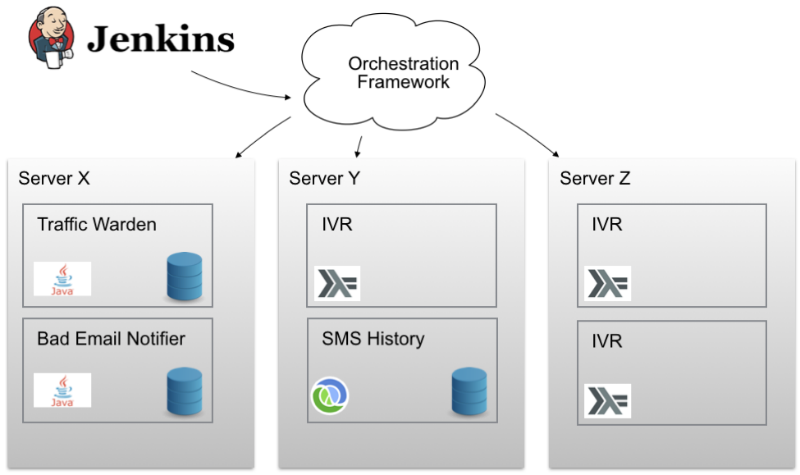
What was needed was some magical orchestration framework, with which it would be possible to distribute containers among cluster nodes. It was necessary to achieve that it would be possible to work with multiple nodes as with one single one. It was necessary for this magical framework to be able to say “expand 3 copies of such a Docker container somewhere in the cluster and see that everything works”. Great plan! The only thing left was to find such a framework.
Wish List
Technologies are developing very fast, so even to meet very moderate standards, you still need to choose tools so that they are alive and maintained for some time. Haleby engineers would like their “dream framework” to use something like the docker-compose they already used - this would eliminate the need for a lot of reconfiguration and configuration work.
In addition, the simplicity of the framework and the absence of too many magic features that are difficult to control would be a plus. Some kind of modular solution would be perfect, which would leave the possibility of replacing some parts if necessary. An open license would also be a plus - in this case it would be possible to easily track the progress of the project and make sure that it has an active community.
In addition, Haleby team members would like to see the selected tool present support for working with containers in multiple clouds at the same time, as well as the presence of network discovery functionality. Also, the engineers did not want to spend a lot of time setting up, so the use of the framework as service model would be preferable.
Framework selection
Analysis of the options available on the market made it possible to identify several candidate frameworks. Among them:
AWS ECS
AWS ECS Container Service is a highly scalable and fast container management tool that lets you start, stop, and work with Docker containers in your Amazon EC2 instance cluster. If any project is already working in this cloud, then not consider this option is just strange. However, Haleby did not work for Amazon, so the move seemed to the engineers of the company not the best solution.
In addition, it turned out that the system does not have built-in network discovery functionality, which was one of the key requirements. In addition, in the case of AWS ECS, it would not be possible to launch many containers using one port on one node.
Docker swarm
Docker Swarm is a native clustering tool for Docker. Since Swarm uses the Docker API, any tool that can work with the Docker daemon can be scaled using it. Since Haleby uses docker-compose, the latter option sounded very tempting. In addition, the use of a native tool of familiar technology meant that the team did not have to learn something new.
However, not everything was so rosy. Despite the fact that Swarm supports several engines for network discovery, setting up workable integration is not an easy task. In addition, Swarm is not a managed service, so you would have to configure and maintain its work yourself, which was not originally included in the plans of the project team.
Moreover, it would also be impossible to update containers automatically. To do this, for example, you would have to configure Nginx as a load balancer for various groups of containers. Also, many engineers on the Internet expressed doubts about the performance of Swarm - among them, for example, Google employees .
Mesosphere DCOS
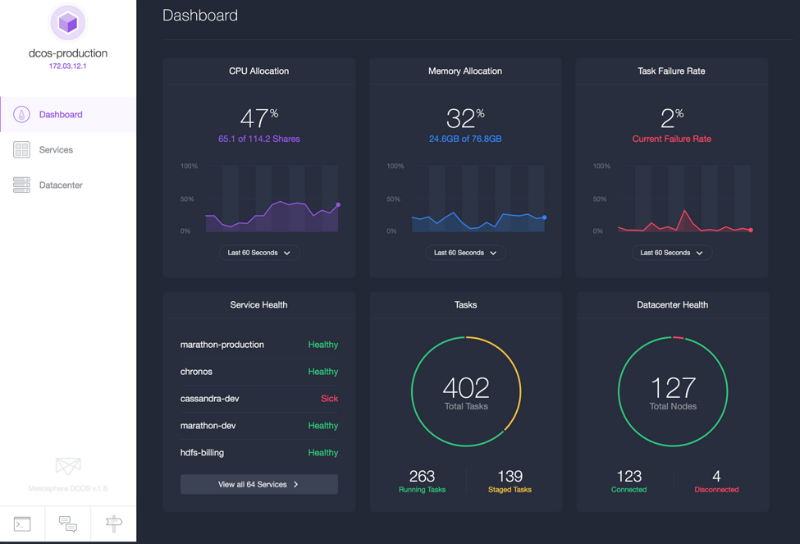
After setting up DCOS (data center operating system) on AWS and starting work, Mesosphere seems like a good option. Using a convenient interface, you can get all the information about the cluster, including running services, processor load and memory consumption. DCOS can work in any cloud and with multiple clouds at once. Mesos is a tool that has been proven to work in large clusters. DCOS also allows you to run not only containers, but also individual applications, such as Ruby, and you can install important services using the simple dcos install command (this is like apt-get for the data center).
Moreover, with this tool you can work with several clusters at the same time - you can run Marathon, Kubernetes, Docker and Swarm within the same system.
However, along with the pros, this option also had its drawbacks. For example, support for working with multiple clouds is present only in the Enterprise version of Mesosphere DCOS, however, the price of this version is not listed on the site, and no one responded to requests.
Also, the documentation at that time (October / November 2015) did not contain information on how to move to a new cluster without the need to interrupt the system - here it is important to understand that this is also not a managed service, so problems can occur during the move .
Tutum
The project team describes it as a “Docker platform for Dev and Ops,” and the slogan sounds like “build, deploy and manage your applications in any cloud.” The interface looks like this:
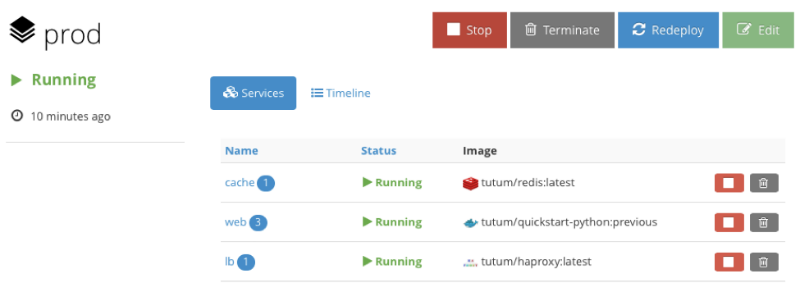
To some it may not seem as spectacular as that of DCOS, but nevertheless, the system allows you to perform most of the necessary manipulations with simple mouse clicks, although Tutum has good command line support. To start working with the system, you need to install a Tutum agent on each node of the cluster, after which the node begins to appear in the administrative panel. An interesting point - Tutum uses a stack ad format from several services or containers, which is similar to docker-compose - so it’s even easier for specialists familiar with Docker to get started.
In addition, Tutum supports volumes through integration into the Flocker cluster . Tests in which certain containers were "killed" were passed successfully - they were recreated in the same state (sometimes on different nodes). Another plus was the function of creating links between containers - with its help you can associate certain containers in a group.
For load balancing, HAProxy is used, which supports virtual hosts, so several services can be hosted on a single HAProxy instance. Deploying services can also be done in different ways, and to update Docker in the entire cluster, just a couple of clicks. In the future, Docker bought the Tutum service, so that in the future it will be fully integrated into the ecosystem.
However, at the time of the search for the best framework, Tutum was in beta testing. Nevertheless, the main argument against this option was the incident when, during the test, the engineers specially made the node completely inaccessible - loading the CPU 100% did not even allow connecting to the machine via SSH, the containers from it were not transferred to another node. Tutum Technical Support has stated that it is familiar with this problem, but it has not yet been fixed. It was necessary to search further.
Kubernetes
The Kubernetes team describes the project as a tool for "managing a cluster of Linux containers as a single system to speed up Dev and simplify Ops." This is an open project that is supported by Google, and a number of other companies are also involved in its development, including Red Hat, Microsoft, SaltStack, Docker, CoreOS, Mesosphere, IBM.
What's really good about Kubernetes is that it combines Google’s ten-year-old experience in building and managing clusters — all for free! You can run Kubernetes on your own hardware or on the capabilities of cloud providers such as AWS for which there are even special formation templates.
Google also offers a managed version of Kubernetes called the Google Container Engine. Due to interface flaws, starting to work with it is not as easy as for example with Tutum, however, after the user manages to understand the system, working with it becomes simple.
A team of engineers conducted many tests, during which the nodes were “killed” in the process of updating updates, containers were randomly destroyed, their number increased above the declared maximum bar, etc. Not always everything went without problems, but in each case, after certain searches, it was possible to find a way to correct the situation.
Another significant advantage of Kubernetes was the ability to upgrade the entire cluster without interruption. Tests also confirmed the efficiency of network discovery - you just need to drive the name of the desired service into the address bar (
http://my-service), and Kubernetes create a connection to the desired container. Kubernetes is a modular system whose components can be combined. The framework also has its drawbacks - when working with the Google Container Engine, the system is limited to one data center. If something happens to him, nothing good will happen. You can get out of any situation, for example, by organizing several clusters using a load balancer, but there is no solution out of the box. However, support for working with multiple data centers is planned in new versions of the lighter version of the Ubernetes framework . In addition, Kubernetes uses its yaml format, which makes it necessary to convert docker-compose files. In addition, the project is not yet as developed as the same Mesos, which allows you to work with a large number of nodes.
Conclusion
After exploring the options available on the market, the Haleby team settled on Kubernetes, which seemed to engineers the most suitable tool for solving their problems. At the same time, the other considered services also showed themselves on the good side, however, they had their drawbacks, which in this case turned out to be unacceptable.