AlphaStar - a new artificial intelligence system for StarCraft II from DeepMind (full translation)
- Transfer
Games have been used for decades as one of the main methods of testing and evaluating the success of artificial intelligence systems. As opportunities grew, researchers looked for games with ever-increasing complexity that reflected the different elements of thinking needed to solve real-world scientific or applied problems. In recent years, StarCraft is considered one of the most multifaceted and complex real-time strategies and one of the most popular eSports on stage in history, and now StarCraft has also become a major challenge for AI research.
AlphaStar is the first artificial intelligence system capable of defeating top professional players. In a series of matches that took place on December 19, AlphaStar won a landslide victory over Grzegorz Komincz ( MaNa ) from the team of Liquid , one of the strongest players in the world , with a score of 5: 0. Before this, a successful demonstration match was also played against his teammate Dario Wünsch ( TLO ). Matches were held according to all professional rules on a special tournament card and without any restrictions.
Despite significant success in games like Atari , Mario , Quake III Arena and Dota 2, AI techniques unsuccessfully struggled with the complexity of StarCraft. The best results were achieved by manually constructing the basic elements of the system, imposing various restrictions on the rules of the game, providing the system with superhuman abilities or playing on simplified maps. But even these nuances made it impossible to approach the level of professional players. In terms of this, AlphaStar plays a full-fledged game using deep neural networks that are trained on the basis of raw game data, using teaching methods with a teacher and reinforcement training .
Main challenge
StarCraft II is a fictional fantasy universe with rich, multi-level gameplay. Along with the original edition, this is the biggest and most successful game of all time, which has been fighting in tournaments for more than 20 years.

There are many ways to play, but the most common in eSports is one-on-one tournaments consisting of 5 matches. To begin with, the player must choose one of three dissolves, protoss or terrans, each of which has its own characteristics and capabilities. Therefore, professional players most often specialize in one race. Each player starts with several working units that extract resources to build buildings, other units, or develop technology. This allows the player to capture other resources, build increasingly sophisticated bases and develop new abilities to outwit the opponent. To win, a player must very elegantly balance the picture of the overall economy, called “macro”, and the low-level control of individual units, called “micro”.
The need to balance short-term and long-term goals and adapt to unforeseen situations poses a big challenge to systems that are often completely inflexible. Solving this problem requires a breakthrough in several areas of AI:
Game Theory : StarCraft is a game where, like in Stone, Scissors, Paper, there is no single winning strategy. Therefore, in the learning process, the AI must constantly explore and expand the horizons of its strategic knowledge.
Incomplete Information : Unlike chess or go, where players see everything that happens, important information in StarCraft is often hidden and must be actively obtained through exploration.
Long-term planning: As in real-world problems, cause-and-effect relationships may not be instantaneous. The game can also last an hour or more, so the actions performed at the beginning of the game may not have any meaning at all in the long run.
Real Time : Unlike traditional board games, where participants take turns in turns, in StarCraft, players perform actions continuously, along with the passage of time.
Huge action space: Hundreds of different units and buildings should be monitored simultaneously, in real time, which gives a truly huge combinatorial space of possibilities. In addition to this, many actions are hierarchical and can be changed and supplemented along the way. Our game parameterization gives on average about 10 to 26 actions per unit of time.
Due to these challenges, StarCraft has become a big challenge for AI researchers. The current StarCraft and StarCraft II competitions have their beginnings since the launch of the BroodWar API in 2009. Among them - AIIDE StarCraft AI Competition , CIG StarCraft Competition , Student StarCraft AI Tournament and Starcraft II AI Ladder .
Note: In 2017, PatientZero published on Habré an excellent translation of the “ History of AI Starcraft competitions ”.
To help the community explore these issues further, we, working together with Blizzard in 2016 and 2017, published the PySC2 toolkit , including the largest anonymized replay array ever published. Based on this work, we have combined our engineering and algorithmic achievements to create AlphaStar.

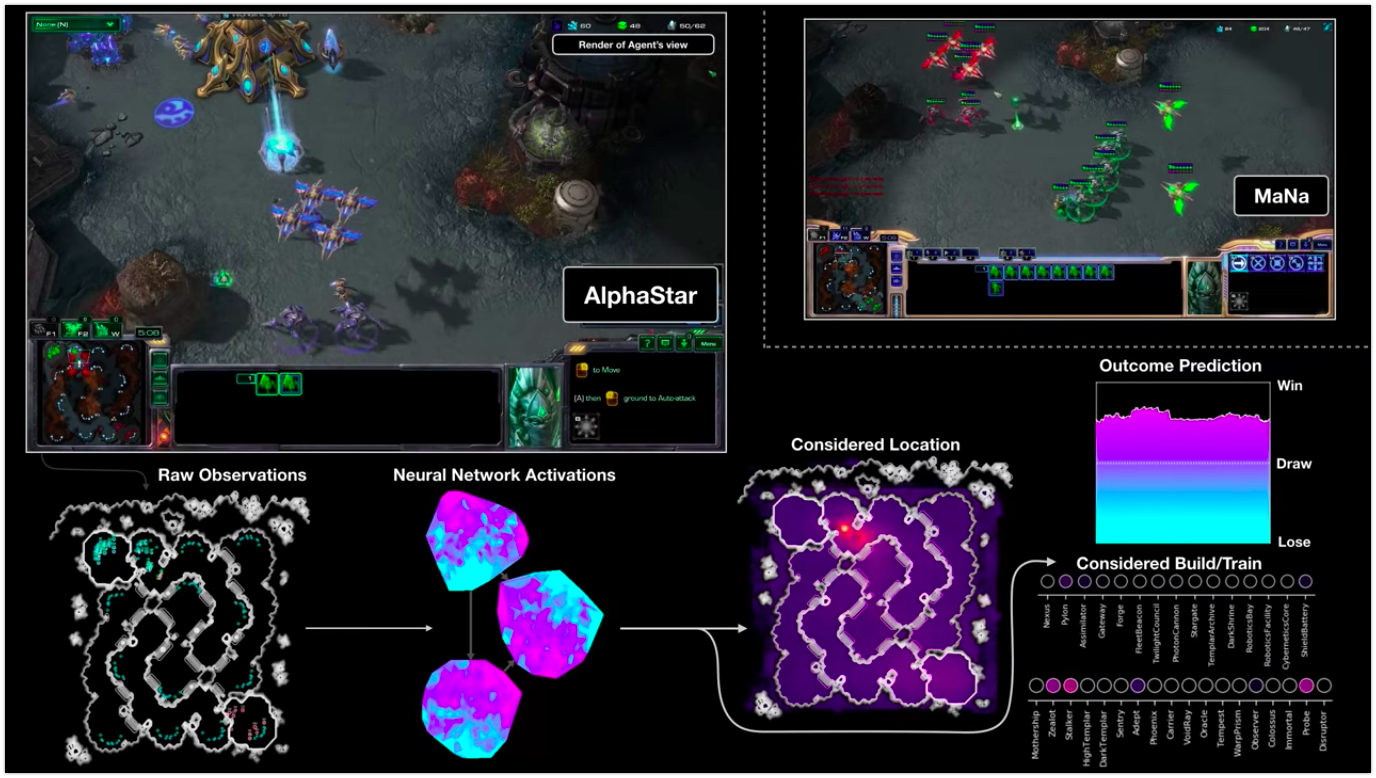
The AlphaStar visualization during the fight against MaNa demonstrates the game as an agent — the initial observable data, the activity of the neural network, some of the proposed actions and required coordinates, and the expected outcome of the match. The appearance of the MaNa player is also shown, but of course it is not available to the agent.
How is the training going
The behavior of AlphaStar is generated by a deep learning neural network that receives raw data through the interface (a list of units and their properties) and gives a sequence of instructions that are actions in the game. More specifically, the architecture of the neural network uses an approach « transformer the torso to the units, combined with a deep LSTM core , an auto-regressive policy head with a pointer network A , and a centralised baseline of value » (for the accuracy of the terms left untranslated). We believe that these models will further help to cope with other important machine learning tasks, including long-term sequence modeling and large output spaces, such as translation, language modeling, and visual representations.
AlphaStar also uses a new multi-agent learning algorithm. This neural network was originally trained using a teacher-based learning method based on anonymized replays that are available through Blizzard. This allowed AlphaStar to study and simulate the basic micro and macro strategies used by players in tournaments. This agent defeated the built-in AI of the Elite level, which is equivalent to the player level of the golden league, in 95% of test games.
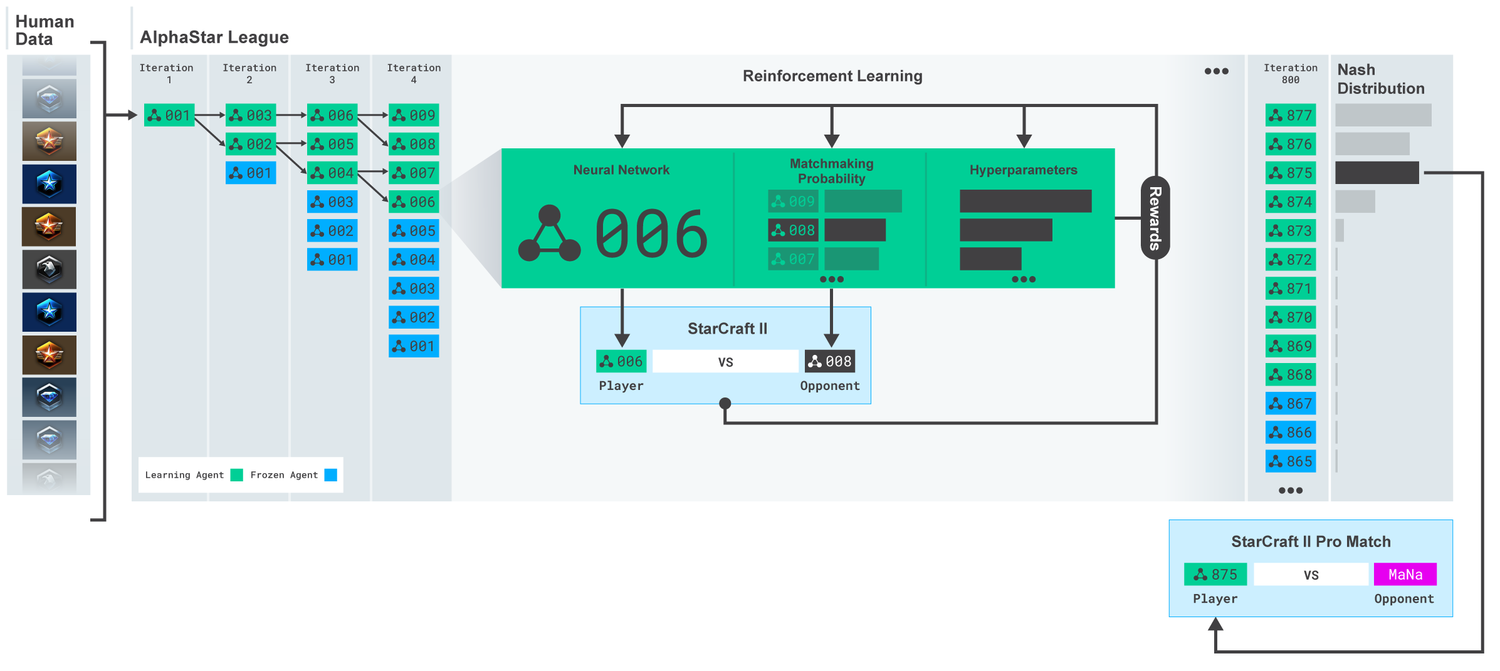
League AlphaStar. Agents were originally trained on the basis of replays of human matches, and then on the basis of competitive matches between themselves. At each iteration, new contenders forked, and the initial rivals freeze. Chances of meeting other opponents and hyperparameters determine the learning objectives for each agent, which increases the complexity that preserves diversity. Agent parameters are updated with reinforcement training based on the outcome of the game against opponents. The final agent is selected (without replacement) on the basis of the Nash distribution.
These results are then used to begin a multi-agent learning process with reinforcement. For this, a league was created, where opponents play against each other, just as people get experience playing tournaments. New rivals were added to the league by duplicating the current agents. Such a new form of training, borrowing some ideas from the method of training with reinforcement with elements of population-based algorithms, allows you to create a continuous process of exploring the huge strategic space of the StarCraft gameplay, and be sure that agents can resist the strongest strategies, not forgetting the old ones.

The MMR (Match Making Rating) is a rough indicator of player skill. For rivals in the league AlphaStar during training, in comparison with the online leagues Blizzard'a.
With the development of the league and the creation of new agents, counter-strategies appeared that were able to defeat the previous ones. While some agents only improved the strategies that were met earlier, other agents created completely new ones, including new unusual build orders, the composition of units and macro-management. For example, at an early stage, “cheese” flourished - fast rush with photon ( Photon Cannons ) cannons or dark templar ( Dark Templars).). But as the learning process progressed, these risky strategies were discarded, giving way to others. For example, the production of an excess number of workers to obtain additional inflow of resources or the donation of two oracles ( Oracles ) to strike at the adversary’s workers and undermine their economy. This process is similar to how ordinary players discovered new strategies and defeated old popular approaches, over the course of many years since the release of StarCraft.
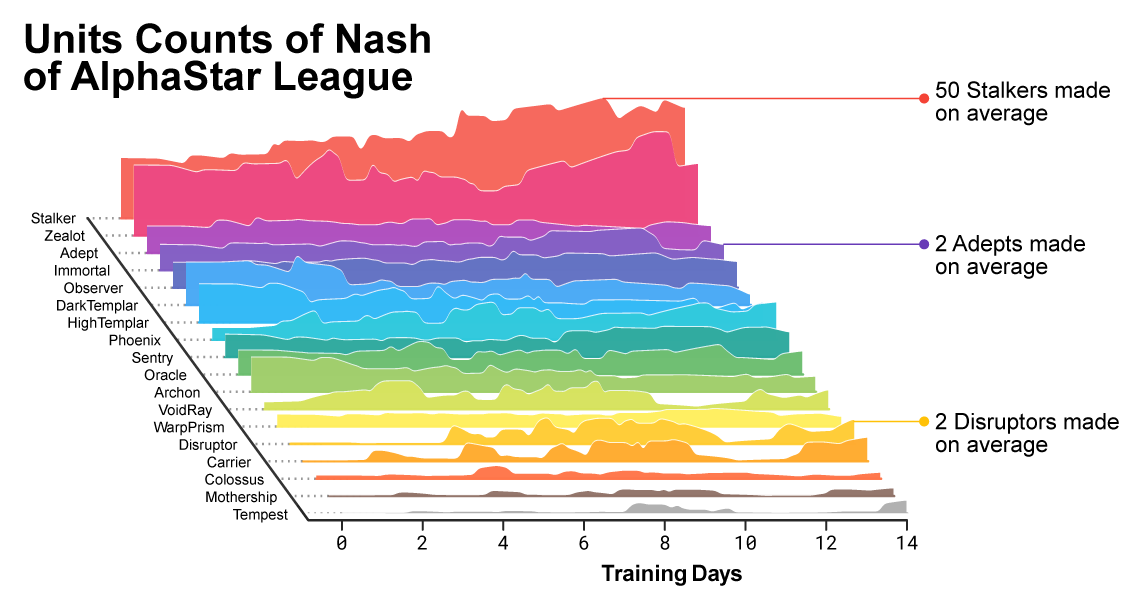
As the training progressed, it was noticeable how the composition of the units used by the agents was changing.
To ensure diversity, each agent is endowed with its own learning goal. For example, which opponents should win this agent, or any other intrinsic motivation that determines the agent's game. A certain agent may have a goal to defeat one particular opponent, and another - a whole sample of opponents, but to do this only with specific units. These goals changed as the learning progressed.

Interactive visualization (interactive features are available in the original article ), which shows rivals from the AlphaStar league. An agent who played against TLO and MaNa is separately noted.
The coefficients (weights) of the neural network of each agent were updated using reinforced learning based on games with opponents in order to optimize their specific learning goals. Weight update rule - a new efficient algorithm for learning « off-policy actor is-critic reinforcement learning algorithm with experience replay , the self-imitation learning and policy Distillation » (for the accuracy of the terms left without translation) .

The image shows how one agent (black dot), which was eventually chosen to play against MaNa, developed his strategy in comparison with his opponents (colored dots) in the learning process. Each point represents an opponent in the league. The position of the point shows the strategy, and the size - the frequency with which it is selected as an opponent for the MaNa agent in the learning process.
For the AlphaStar training, we created a scalable distributed system based on Google TPU 3, which provides a parallel learning process for a whole population of agents with thousands of running copies of StarCraft II. AlphaStar League worked for 14 days, using 16 TPU for each agent. During the training, each agent experienced up to 200 years of experience playing StarCraft in real time. The final version of the AlphaStar agent contains componentsNash distribution throughout the league. In other words, the most effective mix of strategies that were discovered during the games. And this configuration can be run on one standard desktop GPU. A full technical description is now being prepared for publication in a peer-reviewed scientific journal.
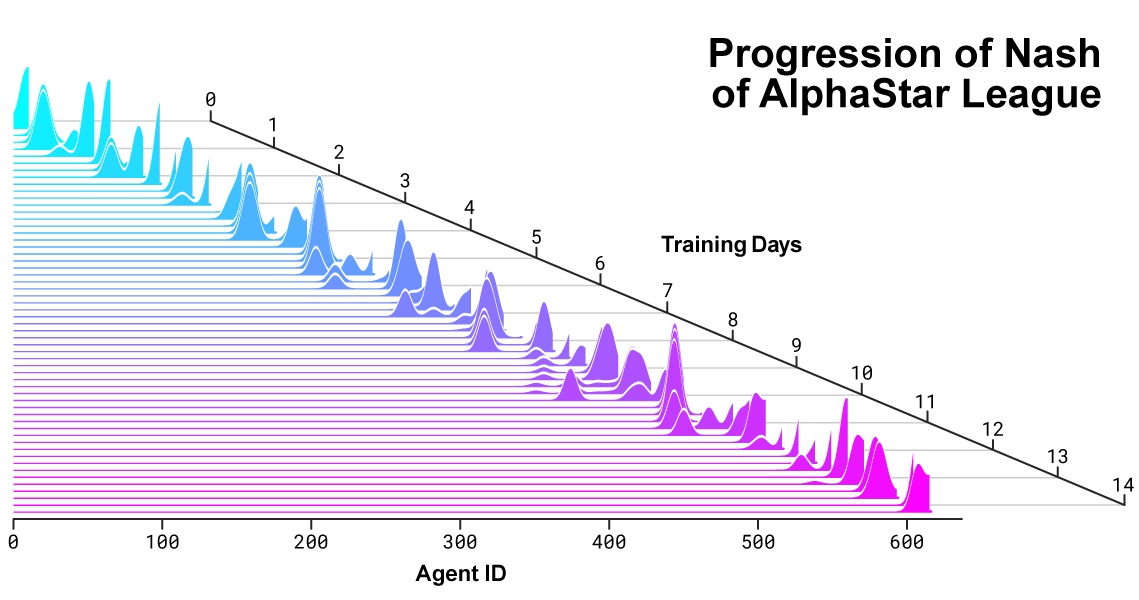
The distribution of Nash between rivals during the development of the league and the creation of new opponents. The distribution of Nash, which is set by the complementary competitors, highly appreciates the new players, thus demonstrating constant progress compared to all past competitors.
How AlphaStar acts and sees the game
Professional players like TLO or MaNa are capable of performing hundreds of actions per minute ( APM ). But it is much less than most existing bots , which independently control each unit and generate thousands, if not tens of thousands of actions.
In our games against TLO and MaNa, AlphaStar kept the APM at an average level of 280, which is much less than that of professional players, although its actions may be more accurate. Such a low APM is due in part to the fact that AlphaStar began to learn from the replays of ordinary players and tried to imitate the manner of the human game. In addition to this, AlphaStar responds with a delay between observation and action on average about 350 ms.

The distribution of APM AlphaStar in matches against MaNa and TLO, and the total delay between observation and action.
During matches against TLO and MaNa, AlphaStar interacted with the StarCraft game engine through a basic (raw) interface, that is, he could see the attributes of his and visible enemy units on the map directly, without having to move the camera — effectively play with a reduced view of the entire territory . Contrary to this, living people must clearly manage the "economy of attention" in order to constantly decide where to focus the camera. However, an analysis of the games AlphaStar shows that it implicitly controls the focus of attention. On average, an agent switches its attentional context about 30 times per minute, like MaNa and TLO.
In addition, we developed the second version of AlphaStar. As human players, this version of AlphaStar clearly chooses when and where to move the camera. In this embodiment, his perception is limited to information on the screen, and actions are also permissible only on the visible area of the screen.

AlphaStar performance when using the basic interface and interface with the camera. The graph shows that the new agent working with the camera quickly achieves comparable performance of the agent using the basic interface.
We trained two new agents, one using the basic interface and one that had to learn how to control the camera by playing against the AlphaStar league. At the beginning, each agent was trained with a teacher on the basis of human matches, followed by reinforcement training described above. The AlphaStar version using the camera interface achieved almost the same results as the base interface version, exceeding the 7000 MMR mark on our internal leaderboard. In an exemplary match, MaNa defeated the AlphaStar prototype using the camera. We trained this version only for 7 days. We hope to be able to evaluate a fully trained version with a camera in the near future.
These results show that the success of AlphaStar in matches against MaNa and TLO is primarily the result of good macro and micro management, and not just a large click rate, quick response, or access to basic interface information.
Results of the game AlphaStar against professional players
StarCraft allows players to choose from one of three races, zerg or protoss. We have decided that AlphaStar will at the moment specialize in one particular race, the Protoss, in order to reduce the training time and variations in the evaluation of the results of our internal league. But it should be noted that a similar learning process can be applied to any race. Our agents were trained to play StarCraft II version 4.6.2 in protoss vs. protoss mode, on a CatalystLE map. To evaluate the performance of AlphaStar, we initially tested our agents in matches against TLO - a professional player for Zerg and a player for Protoss of the GrandMaster level. AlphaStar won matches 5-0, using a wide range of units and build orders. “I was surprised at how strong the agent was,” he said. “AlphaStar takes known strategies and turns them upside down. The agent showed such strategies that I had never even thought about. And this shows that there can still be ways to play that have not yet been fully studied. ”
After an extra week of training, we played against MaNa, one of the strongest StarCraft II players in the world, and included in the top 10 strongest players for the protoss. AlphaStar won this time with a score of 5: 0, demonstrating strong micro-management skills and macro strategies. “I was amazed to see how AlphaStar uses the most advanced approaches and different strategies in each game, showing a very human style of play that I never expected to see,” he said. “I realized how strong my playing style depends on the use of errors based on human reactions. And that puts the game on a whole new level. We all enthusiastically expect to see what will happen next. ”
AlphaStar and other difficult issues
Despite the fact that StarCraft is just a game, even if it is very difficult, we think that the techniques that underlie AlphaStar can be useful in other tasks. For example, this type of neural network architecture is capable of simulating very long sequences of probable actions, in games often lasting up to a full hour and containing tens of thousands of actions based on incomplete information. Each frame in StarCraft is used as one input step. In this case, the neural network each such step predicts the expected sequence of actions for the rest of the game. The fundamental task of making complex predictions for very long data sequences is encountered in many real-world problems, such as weather forecasting, climate modeling, language understanding, etc. We are very pleased to realize the enormous potential
We also think that some of our teaching methods may be useful in studying the safety and reliability of AI. One of the most difficult problems in the field of AI is the number of options for which the system can make mistakes. And professional players in the past quickly found ways to circumvent AI, originally using its mistakes. AlphaStar's innovative league-based approach finds such approaches and makes the overall process more reliable and safe from such errors. We are pleased that the potential of such an approach can help to improve the security and reliability of the AI systems as a whole. In particular, in such critical areas as energy, where it is extremely important to react correctly in difficult situations.
Achieving such a high level of playing StarCraft is a big breakthrough in one of the most difficult video games ever created. We believe that these achievements, along with successes in other projects, whether AlphaZero or AlphaFold , represent a step forward in the realization of our mission to create intelligent systems that one day will help us find solutions for the most complex and fundamental scientific issues.
11 replays of all matches
Video demonstration match against MaNa
Video with AlphaStar visualization of the full second match against MaNa