"Tumbler", or how to make the operation of the call-center exclude possible interruptions in its work
The work of the help desk (call-center) involves processing calls 24 hours a day, 7 days a week, 365 days a year, in other words, around the clock and continuously. This requirement is highly desirable for call centers providing commercial services. But there are a number of call centers for which this condition is mandatory. Such call-centers are “09” services or emergency response services “01” - “04” and “112”. Despite the assurances of the suppliers of call-center platforms about the high reliability and reliability of the system, it still happens that there are situations when the hardware-software complex fails. And the processing of incoming calls to the call center becomes impossible. Whether this fall is related to software problems or to hardware problems is no longer important,
Not all call center platforms assume the possibility of full “hot” redundancy, but in many platforms involving a full “hot” reservation, the budget for it is comparable to buying a second such call center.
So how to make it possible to reserve call-center capacities even if the call-center architecture does not allow making “hot” redundancy or optimizing your costs for organizing a redundancy scheme. I will make a reservation right away, this solution is mainly focused on large call centers, although in some cases, it can be useful for a small number of operators, too.
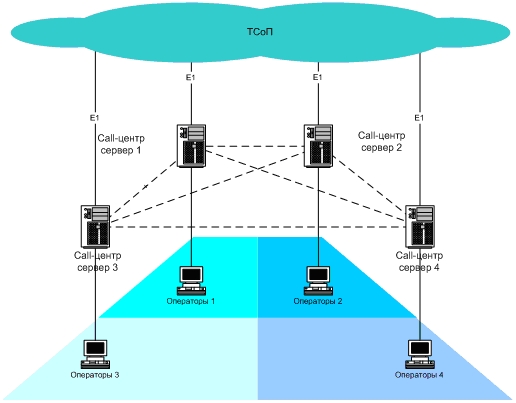
Recently, we implemented a hot standby scheme for a real call center, where the existing call center platform did not provide a hot standby scheme. The total number of operators is 75, the connection to the public switched telephone network (PSTN) is E1 (edss1) in the amount of 4 units from one telecom operator. The maximum load of lines in NNN is no more than 90 simultaneous calls in the system (conversation with the operator + waiting in line).
Our strategic task was to eliminate a possible interruption in servicing telephone calls. We started by understanding that when processing calls, even in CNN, the loss of one E1 stream is unpleasant, but not scary. The problem could not be solved within the framework of the existing call center platform, and we decided to expand the scope and solve the problem within the framework of building two independently installed call center servers, and then increasing their number to four. Ideally, it would be desirable to distribute the E1 streams into four different call centers installed independently. That is, if any of the independent call centers “crashes”, the other platforms should continue to service calls, and the operator’s workplaces, having lost contact with the call center server,
A “fall” of any of the independently established call centers is accompanied by a break in the E1 connection of the flow brought into this call center and the communication operator. Thus, we believe that the event “call center drop” and “communication breakdown on E1 flow” are equivalent.
Work on the side of the telecom operator.The equipment of telecom operators allows you to route calls to alternative destinations in case the main one is unavailable. That is, if when routing a call to a specific E1 stream, the current direction is not available (“loss of communication on the E1 stream”), the telecom operator routes the same call to an alternative direction - other E1 flows. We resolved this issue together with the telecom operator by setting up “cross-routing” of calls for E1 flows on the telecom operator's side. That is, if in the course of operation the switch of the communication operator fixed a disconnection with any E1 stream, then calls are routed to other E1 flows, and in the case of communication restoration, the initial routing scheme is resumed. In addition, we determined with the telecom operator the priority order of E1 flows for receiving calls.
The cross-routing of calls on E1 streams made it possible to completely eliminate the likelihood of a refusal to process a call when any of the call centers fell.
Work at the site of the help desk.After the issues of receiving calls to the help desk were resolved in any case (even if any of the E1 streams “fell”), it was necessary to set a number of routing tasks between independent call centers. We suggested that it would be administratively difficult to control the number of operators connected to a call center. Consequently, the number of operators logged into the system at any of the call centers is not regulated. That is, at any moment of time in any of the call-centers there can be any, even zero, number of operators. In addition, it is necessary to ensure a uniform load on the operators. That is, for the same time interval, each of the operators connected to any of the call centers should receive approximately the same number of calls. In addition, it is necessary to provide automatic switching of the operator’s workplace to another call-center, provided that the current one falls. Well, actually, it is necessary to combine the statistics of call processing from all call centers, leaving the display of real-time statistics indicators in each call center separately.
First of all, we combined all the call centers in such a way that each call center was connected to the other other VoIP channels, which provided processing for 30 voice connections. Such redundancy made it possible, if necessary, to “give off” all 30 calls received on the E1 stream to any of the neighboring call centers. The next task was to implement such a logic of call routing between call centers that would balance the load between call center operators and exclude the appearance of a service queue on one of the call centers if there are free agents on the other.
The next step was to develop a logic for exchanging calls between call centers in such a way that the requirements of balancing the load on call center operators are met. It was done like that. Upon receipt of each call (from the E1 stream) to each of the call centers, the call center calls the stored procedure in an external database, passing the parameters there:
- number A (AON)
- number B (dialed number)
- number of free operators ( Fi), that is, about the number of agents who are in the system and in the status of “ready to serve a call”
- the total number of agents (Ni) serving calls, that is, the number of operators who are in the system in any status (“ready”, “busy” ”,“ Post call processing ”), with the exception of the status“ break ”.
- the number of subscribers in the queue (Qi)
- the estimated response time (Ti), in case the call is distributed to this server.
As an output parameter, the stored procedure returns the name of the server to which the call should be redirected. The following constants are used in the stored procedure: the time interval (P) during which we consider the information received from the servers relevant. An error (E), not exceeding which we assume that the load on the operators is the same.
The logic of deciding which server to direct the call to takes into account the instant, relevant only at the moment, indicators of operator workload (Ri) on each server. We take the following values as an instant indicator of the operator workload: a) if there is a queue, this is the estimated customer waiting time in the queue (Ti) or the ratio of the queue length (Qi) to the total number of operators in the system (Ni). b) in the absence of a queue, the inverse of the number of free operators (1 / Fi) serves as an indicator of operator workload. If, in the absence of a queue, the instant load indicator is not suspicious, then the question of which indicator to choose in the case of a queue required additional study. Empirically, it was found that to balance the load between different platforms, the call center, Using the ratio of the queue length to the total number of operators in the system (Qi / Ni) gives the best results. The reason for the greater confidence in this indicator also lies in the fact that different call center platforms (and in our case there were two different platforms of two manufacturers) use their own algorithms for calculating the expected waiting time in the queue, different algorithms assume different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified. The reason for the greater confidence in this indicator also lies in the fact that different call center platforms (and in our case there were two different platforms of two manufacturers) use their own algorithms for calculating the expected waiting time in the queue, different algorithms assume different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified. The reason for the greater confidence in this indicator also lies in the fact that different call center platforms (and in our case there were two different platforms of two manufacturers) use their own algorithms for calculating the expected waiting time in the queue, different algorithms assume different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified. different algorithms imply different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified. different algorithms imply different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified.
Thus, for each of the call center servers, an instant indicator of operator workload was calculated. In the calculation, we handle exceptional situations when the number of free operators is zero, when the total number of operators is zero. We cut off the server load indicators (Ri) received earlier than the specified time interval (P).
The final step in deciding which server to send a call to is the choice of the least loaded call center server. At the same time, if the difference in workload between the servers does not exceed the specified error (in practice, we assumed it to be 10% or E = 0.10), then the mechanism for cyclic distribution of calls to the server call center (the first call to the first server, the second to the second etc).
Here, in fact, everything is according to the distribution of calls. Unless it should be added that if it is impossible to transfer the call to the server specified as the target server according to the results of the stored procedure, we transfer the call to the next server, with a note of this in the database.
Organization of jobs at the site of the help desk. All help desk jobs were logically divided into 4 zones. The workstations of each zone were connected to a call center, which was the main one for the workstations of this zone (see figure). At the same time, alternative (additional) call-center servers were indicated in the workplace settings, to which the operator’s workstation should be connected if there was a disconnection between the workstation and the call-center and the call-center does not respond to client worker's requests places.
Another issue that needed to be addressed was the collection of statistics in a single place. But there everything is quite simple, the usual collection of statistics from different databases into one with the reduction of data to one general view. In general, there is nothing to describe.
As a result, we got such an organization of work in the help desk, when the “drop” of any of the call center servers results in only a 25% power loss. The flow of incoming calls continues to be processed, and operators automatically switch to another working call center server.
Sahabutdinov Airat
PS: at the moment, the task of building such a distributed system for two different call centers of different manufacturers, including load balancing and statistics collection, has been solved and is working. In work - the construction of a complete distributed system for 4 e1 flows based on a call-center solution from one manufacturer
Not all call center platforms assume the possibility of full “hot” redundancy, but in many platforms involving a full “hot” reservation, the budget for it is comparable to buying a second such call center.
So how to make it possible to reserve call-center capacities even if the call-center architecture does not allow making “hot” redundancy or optimizing your costs for organizing a redundancy scheme. I will make a reservation right away, this solution is mainly focused on large call centers, although in some cases, it can be useful for a small number of operators, too.
Recently, we implemented a hot standby scheme for a real call center, where the existing call center platform did not provide a hot standby scheme. The total number of operators is 75, the connection to the public switched telephone network (PSTN) is E1 (edss1) in the amount of 4 units from one telecom operator. The maximum load of lines in NNN is no more than 90 simultaneous calls in the system (conversation with the operator + waiting in line).
Our strategic task was to eliminate a possible interruption in servicing telephone calls. We started by understanding that when processing calls, even in CNN, the loss of one E1 stream is unpleasant, but not scary. The problem could not be solved within the framework of the existing call center platform, and we decided to expand the scope and solve the problem within the framework of building two independently installed call center servers, and then increasing their number to four. Ideally, it would be desirable to distribute the E1 streams into four different call centers installed independently. That is, if any of the independent call centers “crashes”, the other platforms should continue to service calls, and the operator’s workplaces, having lost contact with the call center server,
A “fall” of any of the independently established call centers is accompanied by a break in the E1 connection of the flow brought into this call center and the communication operator. Thus, we believe that the event “call center drop” and “communication breakdown on E1 flow” are equivalent.
Work on the side of the telecom operator.The equipment of telecom operators allows you to route calls to alternative destinations in case the main one is unavailable. That is, if when routing a call to a specific E1 stream, the current direction is not available (“loss of communication on the E1 stream”), the telecom operator routes the same call to an alternative direction - other E1 flows. We resolved this issue together with the telecom operator by setting up “cross-routing” of calls for E1 flows on the telecom operator's side. That is, if in the course of operation the switch of the communication operator fixed a disconnection with any E1 stream, then calls are routed to other E1 flows, and in the case of communication restoration, the initial routing scheme is resumed. In addition, we determined with the telecom operator the priority order of E1 flows for receiving calls.
The cross-routing of calls on E1 streams made it possible to completely eliminate the likelihood of a refusal to process a call when any of the call centers fell.
Work at the site of the help desk.After the issues of receiving calls to the help desk were resolved in any case (even if any of the E1 streams “fell”), it was necessary to set a number of routing tasks between independent call centers. We suggested that it would be administratively difficult to control the number of operators connected to a call center. Consequently, the number of operators logged into the system at any of the call centers is not regulated. That is, at any moment of time in any of the call-centers there can be any, even zero, number of operators. In addition, it is necessary to ensure a uniform load on the operators. That is, for the same time interval, each of the operators connected to any of the call centers should receive approximately the same number of calls. In addition, it is necessary to provide automatic switching of the operator’s workplace to another call-center, provided that the current one falls. Well, actually, it is necessary to combine the statistics of call processing from all call centers, leaving the display of real-time statistics indicators in each call center separately.
First of all, we combined all the call centers in such a way that each call center was connected to the other other VoIP channels, which provided processing for 30 voice connections. Such redundancy made it possible, if necessary, to “give off” all 30 calls received on the E1 stream to any of the neighboring call centers. The next task was to implement such a logic of call routing between call centers that would balance the load between call center operators and exclude the appearance of a service queue on one of the call centers if there are free agents on the other.
The next step was to develop a logic for exchanging calls between call centers in such a way that the requirements of balancing the load on call center operators are met. It was done like that. Upon receipt of each call (from the E1 stream) to each of the call centers, the call center calls the stored procedure in an external database, passing the parameters there:
- number A (AON)
- number B (dialed number)
- number of free operators ( Fi), that is, about the number of agents who are in the system and in the status of “ready to serve a call”
- the total number of agents (Ni) serving calls, that is, the number of operators who are in the system in any status (“ready”, “busy” ”,“ Post call processing ”), with the exception of the status“ break ”.
- the number of subscribers in the queue (Qi)
- the estimated response time (Ti), in case the call is distributed to this server.
As an output parameter, the stored procedure returns the name of the server to which the call should be redirected. The following constants are used in the stored procedure: the time interval (P) during which we consider the information received from the servers relevant. An error (E), not exceeding which we assume that the load on the operators is the same.
The logic of deciding which server to direct the call to takes into account the instant, relevant only at the moment, indicators of operator workload (Ri) on each server. We take the following values as an instant indicator of the operator workload: a) if there is a queue, this is the estimated customer waiting time in the queue (Ti) or the ratio of the queue length (Qi) to the total number of operators in the system (Ni). b) in the absence of a queue, the inverse of the number of free operators (1 / Fi) serves as an indicator of operator workload. If, in the absence of a queue, the instant load indicator is not suspicious, then the question of which indicator to choose in the case of a queue required additional study. Empirically, it was found that to balance the load between different platforms, the call center, Using the ratio of the queue length to the total number of operators in the system (Qi / Ni) gives the best results. The reason for the greater confidence in this indicator also lies in the fact that different call center platforms (and in our case there were two different platforms of two manufacturers) use their own algorithms for calculating the expected waiting time in the queue, different algorithms assume different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified. The reason for the greater confidence in this indicator also lies in the fact that different call center platforms (and in our case there were two different platforms of two manufacturers) use their own algorithms for calculating the expected waiting time in the queue, different algorithms assume different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified. The reason for the greater confidence in this indicator also lies in the fact that different call center platforms (and in our case there were two different platforms of two manufacturers) use their own algorithms for calculating the expected waiting time in the queue, different algorithms assume different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified. different algorithms imply different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified. different algorithms imply different accuracy of these calculations and different discretization of values. In the event that the balancing mechanism is used to balance the load between two identical call center platforms, the use of the expected response timeout is more justified.
Thus, for each of the call center servers, an instant indicator of operator workload was calculated. In the calculation, we handle exceptional situations when the number of free operators is zero, when the total number of operators is zero. We cut off the server load indicators (Ri) received earlier than the specified time interval (P).
The final step in deciding which server to send a call to is the choice of the least loaded call center server. At the same time, if the difference in workload between the servers does not exceed the specified error (in practice, we assumed it to be 10% or E = 0.10), then the mechanism for cyclic distribution of calls to the server call center (the first call to the first server, the second to the second etc).
Here, in fact, everything is according to the distribution of calls. Unless it should be added that if it is impossible to transfer the call to the server specified as the target server according to the results of the stored procedure, we transfer the call to the next server, with a note of this in the database.
Organization of jobs at the site of the help desk. All help desk jobs were logically divided into 4 zones. The workstations of each zone were connected to a call center, which was the main one for the workstations of this zone (see figure). At the same time, alternative (additional) call-center servers were indicated in the workplace settings, to which the operator’s workstation should be connected if there was a disconnection between the workstation and the call-center and the call-center does not respond to client worker's requests places.
Another issue that needed to be addressed was the collection of statistics in a single place. But there everything is quite simple, the usual collection of statistics from different databases into one with the reduction of data to one general view. In general, there is nothing to describe.
As a result, we got such an organization of work in the help desk, when the “drop” of any of the call center servers results in only a 25% power loss. The flow of incoming calls continues to be processed, and operators automatically switch to another working call center server.
Sahabutdinov Airat
PS: at the moment, the task of building such a distributed system for two different call centers of different manufacturers, including load balancing and statistics collection, has been solved and is working. In work - the construction of a complete distributed system for 4 e1 flows based on a call-center solution from one manufacturer