WAFL File System - NetApp Foundation

In my first post on this blog, I promised to tell you about NetApp "from the technical side." However, before I talk about most of the capabilities available in NetApp systems, I will have to talk about the “foundation”, what lies at the heart of any NetApp storage system — the special data organization structure, which is traditionally called the “WAFL file system” - Write Anywhere File Layout - File Structure with Record Everywhere, translated literally.
If you find that the text is “dry for Habr,” be patient, it will be more interesting further, but I can’t talk about the device of what lies at the basis of the vast majority of practical “NetApp” features. In the future, there will be where to refer “for those interested” to a detailed explanation in the following posts about more practical “chips”.
One way or another, but almost everything that NetApp knows how to grow unique grows precisely from the idea invented in the early 90s by David Hitz and James Lau, co-founders of the startup of Network Appliance, the file system. A good argument for how important and useful the future development of an initially competent and thought-out “architecture” of the product may turn out to be.
But first, why did NetApp need its own file system? What did the existing ones at that time not suit him? Here's what one of the creators of NetApp, co-founder and CTO of Dave Hitz says:
“Initially, we did not intend to write our own file system. It seemed to us that Berkeley FFS was quite suitable for us. But several intrinsic problems inherent in it soon forced us to tackle our own file system.
Testing the integrity of the file system in the event of an emergency shutdown (fsck) with FFS at that time was unacceptably slow. As the size of the file system increased, the situation worsened, making our idea of combining all disks into a single disk volume with a single space practically impossible.
We wanted to make the device as easy to use as possible. To do this, we had to combine all the disks into a single file system. At that time (we are talking about the beginning of the 90s, prim track), people usually created a separate file system on each separate disk and mounted them together in a common tree, which was inconvenient and non-universal.
Using many disks at once, with a common file system on them, we would need RAID. There were two reasons for this. First: when combining multiple disks at once into a single file system, you risked losing the entire file system as a result of the failure of one of the many disks. Second: the probability of failure increased with increasing number of drives. We needed RAID, and we decided to implement RAID simply as part of our file system.
Previously existing file systems worked on top of RAID, and did not know anything about how data is allocated at the physical level, so they could not optimize their work based on this information. Having built our own file system, which knew all the features of the location of data on many physical disks, and independently implementing RAID, we were able to optimize its work as much as possible.
That's why, looking at all this, we decided to write our own file system for our device. ”
(who said “with blackjack and whores”?;)
The main principle underlying the functioning of the WAFL file system, distinguishing it from all then existing file systems, may seem a little paradoxical: once a recorded block of data in a file is not overwritten in the future. It can only be deleted (cleared), but NOT RENEWED.
Thus, any data block on the file system can be either “empty”, and then it can be written, or “written”, and then it can either be read or deleted when no record of an overlying structure refers to it anymore. Writing (overwriting) to a block already occupied by any data is not possible according to the internal logic of the file system.
The necessary changes to the contents of the recorded file are "appended" to it, on the free space of the file system.
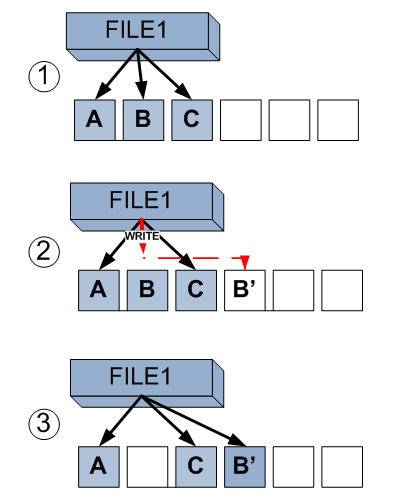
Consider the steps.
In the first step, we see a file occupying three blocks on the file system: A, B and C.
Step 2. The program using this file wants to change the data in its middle, which is stored in block B. Opening the file for writing, it changes this data, but FS, instead of changing the data in the already recorded block B, writes them to a completely empty block in the free block area.
Step 3. The file system shifts the pointer of the blocks used by the file to the recorded block B 'from block B. And since no one else refers to block B, it is freed and becomes empty.
Such a peculiar model allows us to obtain two important features of use:
- Turn random storage entries into sequential.
- It is very simple and effective to organize the so-called Snapshots, snapshots, or instant "snapshots" of the state of data on disks.
Let us examine these points in more detail.
The structure of the organization of WAFL file system blocks will be clear to everyone familiar with the inodes file systems, all of Berkeley's FFS’s numerous “unix” heirs.
Blocks of file data are addressed using a structure called 'inode'.
Inode can point to blocks of directly file data, as well as to intermediate inodes of “indirect addressing”, forming a kind of “tree”, where in the root is the “root inode”, and at the very end of the branches there are blocks of directly data.
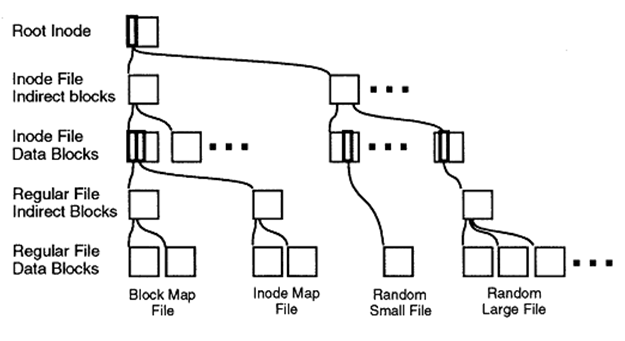
Most Unix file systems use this scheme, so what is new in WAFL?
Since, as I already mentioned above, the contents of already recorded data of the file system do not change, and new blocks are only added to the “tree” (and remain there until at least someone refers to them), it’s obvious that preserving the “root” of such tree, the root inode, at some point in time, we get as a result a complete "snapshot" of all the data on the disk at that moment. After all, the contents of any blocks already recorded (for example, with the previous contents of the file) are guaranteed not to change.
By saving the only block containing the root inode, we also save all the data that it refers to in one way or another.
This makes it easy to create snapshots of data states on disks.
Such a “snapshot” looks like the full contents of your entire file system at a certain point in time, the one in which the root inode was saved. Each file on it is readable (of course, changing it will not work).
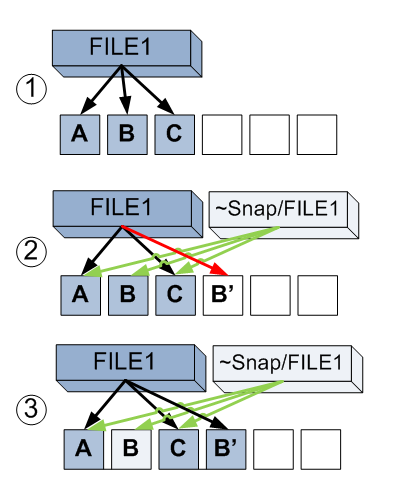
Let's consider in more detail. In the first step, we again have a file that spans three blocks of the file system.
In step 2, we create a snapshot. As mentioned above, this is just a copy of the active file system links to the blocks occupied by files. Now each of blocks A, B and C has two links. One from file File1, the second from this file from a snapshot. This is similar to a link in a UNIX file system, but links do not lead to a file, but to data blocks of this file on the file system. The program changes the data in block B of the file, instead of which new content is written to block B '.
Step 3. However, the old block B does not become empty, so it is referenced from the snapshot. Now, if we want to read the contents of File1 before the changes, we can use the file ~ snap / File1, which will access blocks A, B and C. And the new content is available when reading File1 itself - A, B 'and C. Thus, we can both the old, through its snapshot, and the new contents of the file system.
As I said above, such an organization of writing to a file system allows you to achieve several important things from the point of view of the system:
- Turn the random write operation into a much faster and more efficient sequential write operation for the storage system (since the entire group of cache entries that were logically assigned to different files in different FS places can be written into one consecutive segment of empty blocks).
- Record to discs efficiently, “full stripe”.
Unusual in NetApp systems is also what they implemented in their file system, which, I remind you, is also itself a RAID and volume manager, an unusual type of RAID - RAID type 4. This, I recall, is a “striping with parity" model, similar to the usual RAID-5, but the parity disk is allocated to a separate physical disk (and not “smeared” throughout the RAID as in type 5).
Typically, RAID-4 is rarely used "in the wild", as it has one, but a very serious drawback - its performance, when it is "used" normally, rests on the performance of the parity disk, there is a change operation for each write operation to the RAID group on a parity disk, which means that no matter how you increase the size of a RAID group, its total performance will still run into the performance of one disk for recording.
On the other hand, RAID-4, like RAID with dedicated parity (unlike, for example, RAID-5, with “non-dedicated parity”) has a very solid plus, which consists in the ability to expand the capacity of RAID by adding drives “instantly”. Adding a disk to RAID-4 does not lead to the need for "rebuilding RAID", immediately after physically inserting the HDD and adding a data disk to an existing RAID, we can start writing to it by expanding both the internal WAFL file system and those lying on top of it Structures, such as CIFS, NFS, or LUN data volumes. For the device, which was initially oriented towards ease of maintenance, and “non-IT companies” as customers, this was a big plus.
However, what to do with speed?
It turned out that if we write on RAID-4 sequentially and with “full RAID strips”, then there is simply no problem with abutting the parity disk. A prepared stripe is recorded in one RAID operation into all disks of a RAID group, then it waits for the next stripe to be assembled, and writes it in one go.
What prevents to do also on any file system?
"Random" record. The vast majority of records on modern tasks are rather chaotic records on disk space. Since in the classical file system we are forced to overwrite thousands, tens of thousands of data blocks randomly scattered across the disk space, and usually without any logic from the point of view of the disk, it becomes extremely difficult to collect “full strip” in the cache. To do this, you must either increase the write space of the cache, or increase the time the data is in it, which increases the likelihood that, finally, at some point we will collect the strip we need in this “puzzle” and we can reset it as efficiently as possible on RAID.
However, as you remember, in WAFL we do not need to drive the disk heads “pancake” to overwrite a couple (kilo) bytes somewhere in the middle of the file. Need to change data? Not a problem. Here we have a large empty segment, write everything that has accumulated there at once, and then rearrange the pointer in the inode to a new location. The entire group of bytes waiting for the recording queue at once, without chasing the heads through the pancake, in one go, sequentially (Sequental), leaks onto the disks. Recording is completed, and the parity value, previously calculated for the stripe, is also recorded in one go, on the parity disk.
Of course, nothing is given for nothing, and turning a random record into a sequential one in some cases can turn a “sequential” reading into a “random” one. However, practice shows that there are not so many consecutive readings (as well as consecutive records) in practice, and such a “smearing” of a file over the file system affects comparatively little random reads.
In addition, a large read cache most often successfully copes with this problem.
For those cases where the performance of SEQUENTIAL reading is really important (for example, when backing up, which occurs predominantly sequentially within a file), NetApp systems have a special background optimization process that continuously increases the degree of “sequencing” of data placement (as in unix FS called 'contiguous'), with the data evaluated as being sequentially collected in longer sequential “chunks”, which facilitates their further sequential reading sie (sequental read).
The second feature of WAFL is the unusual “logging” scheme. It must be said that for 1993, when WAFL appeared, journaling was still a rather rare feature in file systems, and one of the tasks when creating WAFL was to organize consistent storage of data and quickly restart after a failure. During these years, a “dirty” restart of large file systems on UNIX servers often caused fsck to start for many minutes, and sometimes even hours.
WAFL uses a somewhat unusual scheme, with a "journal" rendered on a separate physical device - NVRAM. NVRAM is an unusual device. Although outwardly it really resembles a caching controller familiar today, with RAM and a battery for powering it on a turned off system, and storing data in it, the principle of its operation is completely different.

The data and commands coming to the storage system (for example, NFS operations) are pre-accumulated in NVRAM, after which they are “atomically” transferred to disks, creating the so-called Consistency Points (CP), “consistency points”, and “consistent state” (by the way CP is also such a special internal “snapshot”, the same logical mechanism is used). The operation of creating a CP occurs either every few seconds, or when a certain amount of memory is filled in NVRAM (high watermark). Between CP, the state of the file system is completely consistent, and switching to the next CP is instantaneous and atomic, so the file system is always in an integral state, which is similar to how the work with SQL databases is organized.
From the point of view of the system, the data is either completely successfully recorded, or has not yet left the NVRAM and has not got to the drives. Since the file system does not overwrite its contents already on the disks, it is very simple to organize “atomicity”, the situation is when the data has already been changed in some of the blocks and not yet (for example, a software or hardware failure has occurred) is simply impossible. It is possible that some of the blocks considered to be EMPTY are already filled with new data, but until the “pointer” has been moved to a new CP (momentary action) that fixes the new state of the file system, it remains in the consistent state of the previous CP, and this is not a problem. If the system is restored to operability, recording will continue from the moment it was interrupted at the last successful CP, and writes down the data in the NVRAM with battery power (up to a week without the power supply of the system as a whole), the data on which the process broke off, and then rearranges the CP. The “semi-recorded” data at the time of the failure will be “at the FS level” considered “empty” (and the data in NVRAM will not have left it) until the pointer to CP is updated.
That is, the operation of the system is as follows:
NVRAM - system: It's time to write CP!
System - NVRAM: Well, let's go.
We are writing.
NVRAM system: How are you doing? All is ready?
NVRAM: Done, Chef!
System - File System: Well, with God! Plyusadin!
File system: (increment the pointer of its current state to the generated CP) oink!
Variant of unsuccessful recording:
NVRAM - system: Everything is gone, boss! Disks do not respond! Chef? Are you here?
System (booted up): Uh, what was it? NVRAM! Freeze File System - Nobody Goes Anywhere! We use the last valid CP entry before the failure! NVRAM - now repeat the last recording operation that was interrupted from the very beginning!
NVRAM: Yes, chief!
This ingenious scheme makes the file system extremely coherent and stable, to the point that many practical administrators over many years of NetApp systems have never encountered any cases of violation of its integrity and the need to “run chkdsk (fsck for residents of a neighboring OS galaxy; ) ".
In parentheses, I note that WAFL integrity control tools in the system, of course, are in case you need them.
You can read more about the WAFL device and principles of operation from the author’s publication “Creating a Specialized File System for the NFS File Server”, published in 1994 in the USENIX journal, which describes the basic principles of WAFL construction. On the website of the Russian distributor of the company Netwell, in the regularly updated library of translated Best Practices, you can download the translation of this document.
In the next article, I’ll talk about how WAFL managed to implement data deduplication that did not slow down the storage system.