Fighting the load on DiPHOST.Ru. Success story

The load and resources as they are.
A year ago, I made a tedious report on the load, it can be found here: http://vimeo.com/7631344 .
Briefly outline the main provisions of it:
- According to the provisioning strategy, resources can be guaranteed and shared. There is no holivar between them - they are either such or such. With its own characteristics.
- Resources should be divided by functionality. The more fully selected services that are separate in the sense of functioning, the easier it is to cope with resource control. With a "bunch" is always more difficult to understand.
- Shared resources must run at full performance. You cannot “slow down” a resource. It is required to optimally select the “entry point” and limit it to only it.
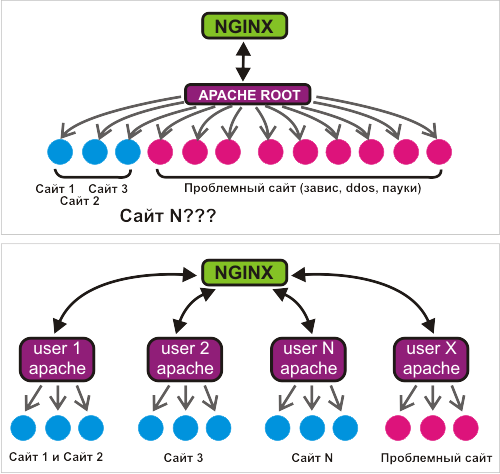
Problem.
In our case, we are considering virtual UNIX hosting with shared resources. Those. many different sites on one server or server group.

One of the most striking problems of shared hosting is an uncontrolled, not formalizable attendance, especially its sharp jumps. The result is a periodic explosive increase in connections to the web server, the resulting load on the database and / or disk, and the slowdown in the output of results for the sum of the reasons. Feedback - increased connections to the web server due to slowing processing.
In 90% of cases, this happens due to the fault of various robots, both white ones (Yandex, Google, etc.) and gray ones (other indexing services - sape, linkfeed and the like) and even (oh my god!) Black ones "- robots stealing content. “Black robots” usually try to pull content “at a time”, so they come to the site in dozens of simultaneous streams, which creates considerable problems.
The situation is almost always aggravated by the fact that the queue of people who want to get to the web server at the time of the influx of connections to any site is growing. Even when the “culprit” is quiet, the freed up resources are sharply trying to occupy the accumulated “queue”. This leads to the so-called "swell." In my practice, there were often problematic cases even with respect to one server - three sites.
Installing a thin proxy (for example, nginx) in front of the web server eliminates a number of symptoms of the problem. The problem itself remains.
"Removing" the database to a separate machine reduces the order of the negative effect, but does not eliminate it, and is not economically justified in all cases.
There is an option for caching site pages. But let’s be realistic - most developers do not know anything about the execution environment of their developments, they do not want to and will not. At about the fifth site, you will already forget what is being cached, what is never cached, who has just changed the structure of the site or anything else.
Theory.
Obviously, in the described situation, the “entry point” is the connection to the web server, and it is necessary to limit it. The question immediately arises - what do we want to "say" to the "unnecessary" connection that has arrived? If we “say” anything to him, be it a 503 error or a connection reset, we will eventually have “broken” sites in an undetermined number of visitors in a chaotic manner. Of the ready-made solutions, we only have limit_req in nginx with high burst. But the problem arises - how to choose the query speed parameter? You can, of course, modify limit_conn to the burst parameter from limit_req. But both solutions have a problem - the entry point to the "thin proxy" is limited.
In our opinion, the entry point of the "thin proxy" is not the best place to limit. Ready-made solutions for apache have a common problem - they return something. Refinement is impossible even theoretically - not to keep the Apache handler waiting for "permission", this negates the whole point of the idea.
Background
We provide a hosting service for applications in python language through mod_wsgi. Apache runs for each site a number of special handlers that are constantly in memory. What was our surprise when we realized that we did not particularly notice the “influx” effect on such sites (for example, http://twihoo.ru , which is quite large in traffic, but not the largest in terms of server load!).
Take a closer look. It is clear - Apache communicates with handlers on a unix-socket, and all the "extra" connections just wait for them to be processed. The result is a “spreading” of the load over time without unnecessary gestures. This practice greatly reduced our religious fear of user processes that are constantly in our memory, and we began to search for a solution.
Eureka!
The decision came completely unexpectedly. I participated in setting up a server for our partners and wanted to supply them with several separately configured apache web servers. Having looked at the apache startup script from the FreeBSD package collection, I suddenly found that such an opportunity was provided there “out of the box”. Sites at partners are untwisted, visited, heavy. Partners are demanding and completely dependent on the quality of the sites. Considering our experience with WSGI hosting, the temptation to conduct an “in battle” experiment won.
"To each his own apache" was a very good idea. More recently, the FreeBSD scheduler depended on the number of processes (default to version 7.1), but we, as a progressive company, have already used new versions of FreeBSD with a new scheduler. The experiment showed that, with the availability of resources, the 3-4 Apache processes withstand quite a lot of traffic even of "heavy" sites. Such a solution has a number of obvious advantages over specialized solutions like mod_peruser and mod_itk - the lack of slurred code for these modules, the ability to control the number of Apache modules, the ability to make specialized settings for these modules.
So far, we have used apache 1.3.x for hosting with a slightly redone the very first patch by Dmitry Koterov - apache did vfork () for each request, then setgid () and setuid (), after servicing the request - _exit (). The new way gives us the opportunity to save CPU time spent on these procedures.
But there is a minus - the requirements for the amount of constantly occupied memory. Modern virtual memory machines, especially those inherited from the mach OS, are very complex. It is not possible to calculate and even estimate in advance how much physical memory will be actually used.
By the way, some Russian and some foreign hosting providers use a similar scheme of dedicated web servers. For example: MediaTemple with GridContainers (http://mediatemple.net/webhosting/gs/features/containers.php ). The truth is somewhat more complicated with virtualization, but the general idea is similar.
Through hardship to the stars.
We made a strong-willed decision to take a chance . For a whole month we wrote a program for building configurations according to the panel, responding to changes, starting and stopping a web server, automatically monitoring the status of each of hundreds of running web servers, rotating logs, and changing the configuration of a thin proxy - nginx. At the same time, we combed and optimized all the nodes involved in the reconstruction.
The first failure awaited us with ... php. We tried to build php 5.2.x statically with Apache in order to reduce the start time of the web server and, theoretically, the runtime overhead. Unfortunately, without tricky editing inside the php build system, this could not be done. Time did not allow us to adequately fix it, and we had to temporarily abandon the undertaking. By the way, if there are people who wish, this problem is described in LJ, you can try to solve it using suitable methods: community.livejournal.com/ru_root/1884339.html .
But finally the system is ready. We transferred several “our” sites to it. The result was encouraging - three Apache handlers were more than enough for a heavy site on drupal with an attendance of ~ 1200 unique. As a special test, we tried a small “dos-attack” on this site (10,000 requests for 100 simultaneous) - the site slowed down but had almost no effect on the operation of other sites. We did not diagnose any noticeable shifts in the distribution of memory. Our hosting site, which we also transferred to the new system, did not appear at all in the top output. And so, for three nights I joyfully transferred all the other servers to the new system. Why at night? Because at night the servers are usually empty, and due to this, all the alterations are done most quickly and quietly.
Monday morning arrived ...
Complete failure.
The server with the fewest sites began to work noticeably better, but noticeably slower. On a server with the i386 architecture of the OS, a lack of memory was not diagnosed, but suddenly mysql took over all the disk accesses and almost paralyzed it. The most powerful server made a gigabyte swap and also almost paralyzed the disks.
This state of the "overloaded" server has its advantages. Stressful situations generally contribute to mental work. We immediately caught all those who create temporary tables in mysql for hundreds of megabytes, we caught several sites that made several hundred database updates per second. We completely tidied up all the mysql server settings. At the same time, they fixed the mytop utility for themselves, which previously did not reach the hands: schors.livejournal.com/652161.html. But nothing brought tangible improvements. In a fit of light panic, we tried to make large buffers for writing Apache logs - buffers for frequent recordings are generally useful. Practice has shown zero result in the given circumstances.
By the end of the day, we were ready to give the go-ahead to roll back everything back. But a rollback is a surrender of positions, because we still do not understand what is happening. This means that a new system and solution to the problem will not appear soon. We pulled a little more time. Almost a day was spent on a complete diagnosis of the system and the incense of all possible manuals and manuals.
The results in theory turned out to be commonplace - after all, there is not enough memory. Not all memory wants to be in a disk swap, not all programs report this when there is not enough memory (for example, mysql with temporary tables and caches) using other tools. Having considered the cost of additional RAM, we decided not to hesitate to upgrade the equipment. And guessed it.
A twofold increase in memory is everything. I want to note that all this after looks strange - it was initially clear that there might not be enough memory. But everything was unclear. Anything could be missing - the scheduler could not cope, the processor could not cope, there might not be any memory at all, there might not be enough apache handlers, there might not be enough buffers, there might not be enough disk. In general, the latter confused us. Instead of making a direct correlation between memory utilization and disk activity, we rushed to solve the problem of “what loads the disk like that” in spite of what the programs do with it.
And then unexpectedly hit us in the back ... php. Php 5.2.11, compiled by statics, suddenly refused to work normally with the gd module (graphics). Moreover, he generally refused to work on the section of libraries that we had. By magic methods for a sleepless night, we managed to bring only php with dynamically loaded extensions into working condition. This problem is located at: www.google.com/#hl=en&newwindow=1&q=gd-png+fatal+libpng+error+freebsd+imagecreatefrompng&lr=&aq=f&oq=&fp=7b635a504e075d30 . It was not possible to understand on which dependence this occurs. The problem is open.
On the way to world domination.
The result was amazing. We leveled the load. Introducing the indicative graph in the “Parrots” Load Average. In the area of the 44th week, a clearly equalized 15-minute load is clearly visible (the "knolls" are smoothed out), which predictably fell at the end of the week with the equipment upgrade.

We won CPU time by abandoning vfork () constants. The graph shows that the use of cpu fell markedly at the beginning of the 44th week, after the equipment upgrade at the end of the week the changes were less noticeable.

One question remains - have we overdid it with a limit of three apache web server handlers per user? On average, in a hospital, each user places two sites. But some often have ten. We closely monitor the messages of our monitoring. For each running apache, we have to check the connection with a timeout of 60 seconds. So we determine that the site is exactly "laid down." Two weeks have already passed. The monitoring is calculated in isolated cases. What is characteristic is literally three clients out of hundreds. Usually this happens either from non-standard influxes who want to “rock” something, or sometimes during a database backup, or from errors made during the site updating process.
The new system brought us pleasant surprises. We got an “honest top”. The top program shows the processes in the system, by default sorting them by some strange parameter - the percentage of processor utilization. It is calculated over a fixed period of time by the kernel using a rather tricky estimation algorithm and is not really a pure percentage. In the case when one web server process can handle connections to sites of different users, we see a “residual” percentage of the last use of the process. In the case when we do vfork (), we generally see only those processes that manage to get into the survey. In the new system, this obviously does not happen. Those processes that appear at the top of the top are really the most demanding of resources.
So, stepping over the subconscious fear of the new, redoing a slightly less than fully functional hosting architecture, we got rid of the “Monday effect”.