Machine Learning Data Extraction
- Transfer
Want to learn about three data mining methods for your next ML project? Then read the translation of the Rebecca Vickery article published on the Towards Data Science blog on Medium! She will be interesting to beginners.

Getting quality data is the first and most important step in any machine learning project. Data Science specialists often use various methods for obtaining datasets. They can use publicly available data, as well as data available via API or obtained from various databases, but most often combine these methods.
The purpose of this article is to provide a brief overview of three different methods for retrieving data using Python. I will tell you how to do this with the Jupyter Notebook. In my previous article, I wrote about the application of some commands that run in the terminal.
If you need to get data from a relational database, most likely you will work with the SQL language. The SQLAlchemy library allows you to associate your laptop code with the most common types of databases. On the link you will find information about which databases are supported and how to bind to each type.
You can use the SQLAlchemy library to browse tables and query data, or write raw queries. To bind to the database, you will need a URL with your credentials. Next, you need to initialize the method
Now you can write database queries and get results.
Web scraping is used to download data from websites and extract the necessary information from their pages. There are many Python libraries available for this, but the simplest is Beautiful Soup .
You can install the package through pip.
Let's look at a simple example how to use it. We are going to use Beautiful Soup and the urllib library to scrape hotel names and prices from TripAdvisor .
First, we import all the libraries we are going to work with.
Now load the content of the page that we will scrap. I want to collect data on prices for hotels on the Greek island of Crete and take the URL address containing a list of hotels in this place.
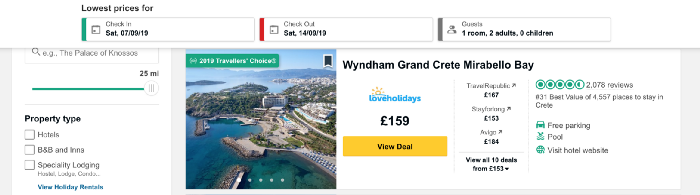
The code below defines the URL as a variable and uses the urllib library to open the page, and the Beautiful Soup library to read it and return the results in a simple format. Part of the output data is shown below the code.

Now let's get a list with the names of the hotels on the page. We will introduce a function
In order to understand how best to provide access to the data in the tag, we need to check the code for this element on the page. We find the code for the hotel name by right-clicking on the name in the list, as shown in the figure below.

After clicking on

We see that the name of the hotel is the only piece of text in the class with the name
Each section of the code with the name of the hotel is returned as a list.

To extract hotel names from the code, we use the function of the
Hotel names are returned as a list.

In the same way we get price data. The code structure for the price is shown below.

As you can see, we can work with a code very similar to the one used for hotels.
In the case of the price, there is little difficulty. You can see it by running the following code:
The result is shown below. If a price reduction is indicated in the list of hotels, in addition to some text, both the initial price and the final price are returned. To fix this problem, we simply return the current price for today.

We can use simple logic to get the latest price indicated in the text.
This will give us the following result:

API - application programming interface (from the English application programming interface). From a data mining perspective, it is a web-based system that provides a data endpoint that you can contact through programming. Usually data is returned in JSON or XML format.
This method will probably come in handy in machine learning. I will give a simple example of retrieving weather data from the public Dark Sky API . To connect to it, you need to register, and you will have 1000 free calls per day. This should be sufficient for testing.
To access data from Dark Sky I will use the library
The structure of this URL is:
We will use the library
results for a specific latitude and longitude, as well as date and time. Imagine that after extracting daily price data for hotels in Crete, we decided to find out if the price policy is related to the weather.
For example, let's take the coordinates of one of the hotels on the list - Mitsis Laguna Resort & Spa.

First, create a URL with the correct coordinates, as well as the requested time and date. Using the library
To make the results easier to read and analyze, we can convert the data to a data frame.

There are many more options for automating data extraction using these methods. In the case of web scraping, you can write different functions to automate the process and make it easier to extract data for more days and / or places. In this article, I wanted to review and provide enough code examples. The following materials will be more detailed: I will tell you how to create large datasets and analyze them using the methods described above.
Thank you for attention!
Getting quality data is the first and most important step in any machine learning project. Data Science specialists often use various methods for obtaining datasets. They can use publicly available data, as well as data available via API or obtained from various databases, but most often combine these methods.
The purpose of this article is to provide a brief overview of three different methods for retrieving data using Python. I will tell you how to do this with the Jupyter Notebook. In my previous article, I wrote about the application of some commands that run in the terminal.
SQL
If you need to get data from a relational database, most likely you will work with the SQL language. The SQLAlchemy library allows you to associate your laptop code with the most common types of databases. On the link you will find information about which databases are supported and how to bind to each type.
You can use the SQLAlchemy library to browse tables and query data, or write raw queries. To bind to the database, you will need a URL with your credentials. Next, you need to initialize the method
create_engineto create the connection.from sqlalchemy import create_engine
engine = create_engine('dialect+driver://username:password@host:port/database')Now you can write database queries and get results.
connection = engine.connect()
result = connection.execute("select * from my_table")Scraping
Web scraping is used to download data from websites and extract the necessary information from their pages. There are many Python libraries available for this, but the simplest is Beautiful Soup .
You can install the package through pip.
pip install BeautifulSoup4Let's look at a simple example how to use it. We are going to use Beautiful Soup and the urllib library to scrape hotel names and prices from TripAdvisor .
First, we import all the libraries we are going to work with.
from bs4 import BeautifulSoup
import urllib.requestNow load the content of the page that we will scrap. I want to collect data on prices for hotels on the Greek island of Crete and take the URL address containing a list of hotels in this place.
The code below defines the URL as a variable and uses the urllib library to open the page, and the Beautiful Soup library to read it and return the results in a simple format. Part of the output data is shown below the code.
URL = 'https://www.tripadvisor.co.uk/Hotels-g189413-Crete-Hotels.html'
page = urllib.request.urlopen(URL)
soup = BeautifulSoup(page, 'html.parser')
print(soup.prettify())Now let's get a list with the names of the hotels on the page. We will introduce a function
find_allthat allows you to extract parts of the document we are interested in. You can filter it differently using a function find_allto pass a single line, regular expression, or list. You can also filter out one of the tag attributes - this is exactly the method that we will apply. If you are new to HTML tags and attributes, see this article for a quick overview . In order to understand how best to provide access to the data in the tag, we need to check the code for this element on the page. We find the code for the hotel name by right-clicking on the name in the list, as shown in the figure below.
After clicking on
inspectthe item code will appear, and the section with the hotel name will be highlighted. We see that the name of the hotel is the only piece of text in the class with the name
listing_title. After the class comes the code and the name of this attribute to the function find_all, as well as the tag div.content_name = soup.find_all('div', attrs={'class': 'listing_title'})
print(content_name)Each section of the code with the name of the hotel is returned as a list.
To extract hotel names from the code, we use the function of the
getTextlibrary Beautiful Soup.content_name_list = []
for div in content_name:
content_name_list.append(div.getText().split('\n')[0])
print(content_name_list)Hotel names are returned as a list.
In the same way we get price data. The code structure for the price is shown below.
As you can see, we can work with a code very similar to the one used for hotels.
content_price = soup.find_all('div', attrs={'class': 'price-wrap'})
print(content_price)
In the case of the price, there is little difficulty. You can see it by running the following code:
content_price_list = []
for div in content_price:
content_price_list.append(div.getText().split('\n')[0])
print(content_price_list)The result is shown below. If a price reduction is indicated in the list of hotels, in addition to some text, both the initial price and the final price are returned. To fix this problem, we simply return the current price for today.
We can use simple logic to get the latest price indicated in the text.
content_price_list = []
for a in content_price:
a_split = a.getText().split('\n')[0]
if len(a_split) > 5:
content_price_list.append(a_split[-4:])
else:
content_price_list.append(a_split)
print(content_price_list)This will give us the following result:
API
API - application programming interface (from the English application programming interface). From a data mining perspective, it is a web-based system that provides a data endpoint that you can contact through programming. Usually data is returned in JSON or XML format.
This method will probably come in handy in machine learning. I will give a simple example of retrieving weather data from the public Dark Sky API . To connect to it, you need to register, and you will have 1000 free calls per day. This should be sufficient for testing.
To access data from Dark Sky I will use the library
requests. First of all, I need to get the correct URL for the request. In addition to the forecast, Dark Sky provides historical weather data. In this example, I will take them and get the correct URL from the documentation . The structure of this URL is:
https://api.darksky.net/forecast/[key]/[latitude],[longitude],[time]We will use the library
requeststo get results for a specific latitude and longitude, as well as date and time. Imagine that after extracting daily price data for hotels in Crete, we decided to find out if the price policy is related to the weather.
For example, let's take the coordinates of one of the hotels on the list - Mitsis Laguna Resort & Spa.
First, create a URL with the correct coordinates, as well as the requested time and date. Using the library
requests, we get access to data in the JSON format.import requests
request_url = 'https://api.darksky.net/forecast/fd82a22de40c6dca7d1ae392ad83eeb3/35.3378,-25.3741,2019-07-01T12:00:00'
result = requests.get(request_url).json()
result
To make the results easier to read and analyze, we can convert the data to a data frame.
import pandas as pd
df = pd.DataFrame.from_dict(json_normalize(result), orient='columns')
df.head()There are many more options for automating data extraction using these methods. In the case of web scraping, you can write different functions to automate the process and make it easier to extract data for more days and / or places. In this article, I wanted to review and provide enough code examples. The following materials will be more detailed: I will tell you how to create large datasets and analyze them using the methods described above.
Thank you for attention!