The R Manual has recently been the most cited non-academic publication in academic papers.
In the Web of Science bibliographic database, the “R: a language and environment for statistical computing” guide recently * bypassed other sources mentioned in the References section of publications indexed by this database. Unfortunately, access to it is limited, and it’s difficult to give a link (for each session, a link is generated), but a number of users ** can reproduce my observations, under the cut it is described how and with what reservations it is worth understanding the headline of the news.

The illustration shows a list of the most cited sources in publications indexed by WoS, which themselves are not indexed by WoS in the main collection (Core Collection), but are only in the database of bibliographic references.
Besides the fact that three indexed publications (all in biology) are still ahead of the R manual, and in many other respects this is a rather limited record with a number of assumptions. Firstly, it concerns only WoS, in the Scopus database, which is often mentioned along with WoS, the nomenclature “Diagnostic and Statistical Manual of mental disorders” is still (but judging by the growth rate, not for long) overtaking the manual on R. Secondly, Of course, I am aware that this is an absolute record, without normalization by field of knowledge, year of publication, etc. Thirdly, I use probably not the most honest calculation, namely, I summarize citations of all versions of the manual (as well as other such bibliographic references - all versions of DSM, all volumes of Numerical recipes, etc.), whereas in the usual calculation, without any summation
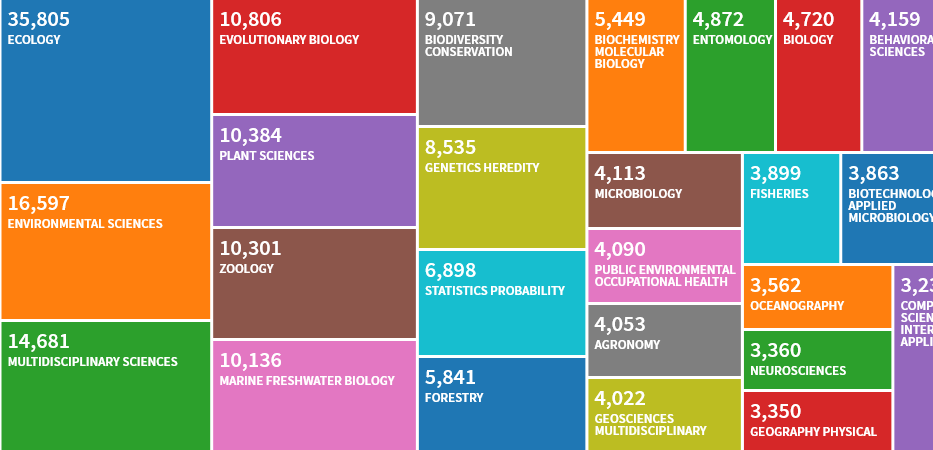
TOP 25 WoS categories cited by the manual. The situation is similar in Scopus.
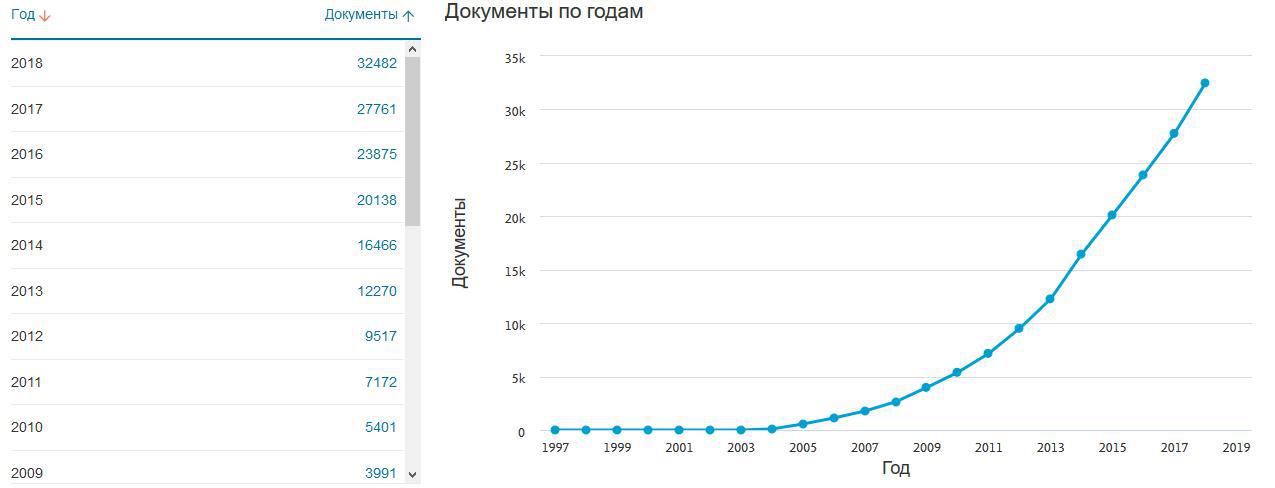
An increase in the number of citations of the manual in Scopus, with similar values for WoS.
It is also worth keeping in mind that not in all cases, if the authors of an academic publication used some kind of tool (in the broad sense, whether hardware or software, or a theorem, or a logical argument, etc.), they will definitely give a link to it, so the subject of a separate study, how much such a frequent mention of the manual reflects its frequent use in writing scientific papers (it is known that R is popular in science, the question is different, according to the numbers, maybe there is some other non-academic source, de actually used often, but not mentioned in the bibliography).
For example, according to this reviewde facto, when searching the Google Scholar database and according to the data for 2018, SPSS is used one and a half times more often for writing academic works. The author explains this by the complexity of mastering R. I would like, however, a comparative analysis on different bases, because the selection of indexed publications and, accordingly, citation indicators differ.
Why is R so important for scientists? Andy Wills in the Linux Journal writes about R in the light of the idea of Open Science, and in connection with the relevance of the crisis of reproducibility in psychology. The psychologist and data-scientist Evgeny Tomilov , whom I turned to, justified the importance of R for science in the answer:
* It is difficult to give an exact date due to the peculiarities of calculating and detailing the data, most likely this has happened in the last few months.
** namely, the owners of the library card of the Russian National Library, RSL, and the Gorky library and student card of St. Petersburg State University, as well as several other universities.
How to reproduce KDPV:
In the “Search by reference bibliography” section, you can enter the query 1000-2999 in the search by year and get a sample of 264 million results from 268 (the remaining ones probably did not indicate the year, but it is unlikely that they are somehow essential for subsequent manipulations) . Rank by number of citations. Next, export the results, and filter out those that have a Source column, but no Title column (for example, in the case of a journal article, the journal’s name is given in the first case, and the publication’s title in the second, then the contents both columns will be the same, and only in the case of non-indexed sources, the "Heading" column will be empty).
The illustration shows a list of the most cited sources in publications indexed by WoS, which themselves are not indexed by WoS in the main collection (Core Collection), but are only in the database of bibliographic references.
Besides the fact that three indexed publications (all in biology) are still ahead of the R manual, and in many other respects this is a rather limited record with a number of assumptions. Firstly, it concerns only WoS, in the Scopus database, which is often mentioned along with WoS, the nomenclature “Diagnostic and Statistical Manual of mental disorders” is still (but judging by the growth rate, not for long) overtaking the manual on R. Secondly, Of course, I am aware that this is an absolute record, without normalization by field of knowledge, year of publication, etc. Thirdly, I use probably not the most honest calculation, namely, I summarize citations of all versions of the manual (as well as other such bibliographic references - all versions of DSM, all volumes of Numerical recipes, etc.), whereas in the usual calculation, without any summation
TOP 25 WoS categories cited by the manual. The situation is similar in Scopus.
An increase in the number of citations of the manual in Scopus, with similar values for WoS.
It is also worth keeping in mind that not in all cases, if the authors of an academic publication used some kind of tool (in the broad sense, whether hardware or software, or a theorem, or a logical argument, etc.), they will definitely give a link to it, so the subject of a separate study, how much such a frequent mention of the manual reflects its frequent use in writing scientific papers (it is known that R is popular in science, the question is different, according to the numbers, maybe there is some other non-academic source, de actually used often, but not mentioned in the bibliography).
For example, according to this reviewde facto, when searching the Google Scholar database and according to the data for 2018, SPSS is used one and a half times more often for writing academic works. The author explains this by the complexity of mastering R. I would like, however, a comparative analysis on different bases, because the selection of indexed publications and, accordingly, citation indicators differ.
Why is R so important for scientists? Andy Wills in the Linux Journal writes about R in the light of the idea of Open Science, and in connection with the relevance of the crisis of reproducibility in psychology. The psychologist and data-scientist Evgeny Tomilov , whom I turned to, justified the importance of R for science in the answer:
R allows you to create reproducible research protocols, including data and their processing. In conditions of total falsifications and an urgent need to increase the reproducibility and credibility of scientific works, the use of this tool is at least useful, and at least ethical.Z.Y. It is also interesting that on Google Scholar there is an R Core Team profile similar to the profiles of individual researchers, with a good Hirsch index of 50 (for this you need to have more than 50 publications, while the publication of 50 in a row, when ranking by the number of citations, should have a number citations equal to 50).
* It is difficult to give an exact date due to the peculiarities of calculating and detailing the data, most likely this has happened in the last few months.
** namely, the owners of the library card of the Russian National Library, RSL, and the Gorky library and student card of St. Petersburg State University, as well as several other universities.
How to reproduce KDPV:
In the “Search by reference bibliography” section, you can enter the query 1000-2999 in the search by year and get a sample of 264 million results from 268 (the remaining ones probably did not indicate the year, but it is unlikely that they are somehow essential for subsequent manipulations) . Rank by number of citations. Next, export the results, and filter out those that have a Source column, but no Title column (for example, in the case of a journal article, the journal’s name is given in the first case, and the publication’s title in the second, then the contents both columns will be the same, and only in the case of non-indexed sources, the "Heading" column will be empty).