Even better zip bomb
- Transfer
The article shows how to create a non - recursive zip bomb that provides a high degree of compression by overlapping files inside a zip container. “Non-recursive” means that it does not depend on the decompressors decompressing files attached to zip archives: there is only one round. The output size increases quadratically from the input, reaching a compression ratio of more than 28 million (10 MB → 281 TB) within the zip format. Further expansion is possible with 64-bit extensions. The design uses only the most common DEFLATE compression algorithm and is compatible with most zip parsers.
Source:
Data and sources of illustrations:
* There are two versions of 42.zip: the old 42 374 bytes, and the newer 42 428 bytes. The difference is that the new one requires a password before unpacking. We compare only with the old version. Here is a copy of the file if you need it: 42.zip .
** I would like to know and indicate the author of 42.zip, but could not find it - let me know if you have any information.
Zip bombs must overcome the fact that the DEFLATE compression algorithm most often supported by parsers cannot exceedthe compression ratio is 1032 to 1. For this reason, zip bombs usually rely on recursive decompression by inserting zip files into zip files to get an additional 1032 ratio with each layer. But the trick only works in implementations that decompress recursively, and most don't. The most famous 42.zip bomb expands to a formidable 4.5 PB if all six layers are recursively unpacked, but on the top layer it has trifling 0.6 MB. Zip-quines, like those of Cox and Ellingsen , give out a copy of themselves and, thus, expand indefinitely when recursively unpacking. But they are also completely safe when unpacking once.
This article shows how to create a non-recursive zip bomb, the compression ratio of which exceeds the DEFLATE limit of 1032. It works by overlapping files inside a zip container to reference the “core” of highly compressed data in multiple files without making multiple copies. The output size of the zip bomb grows quadratically from the input size; i.e., the compression ratio improves with increasing bomb size. The design depends on the features of zip and DEFLATE: it cannot be transferred directly to other file formats or compression algorithms. The bomb is compatible with most zip parsers, except for streaming ones, which analyze files in a single pass without checking the central directory of the zip file. We try to balance two conflicting goals:
Zip-file consists of a central directory of links to files .

The central directory is at the end of the zip file. This is a list of central directory headers . Each central directory header contains metadata for a single file, such as the file name and CRC-32 checksum, as well as a pointer back to the local file header. The central directory header has a length of 46 bytes plus the length of the file name.
The file consists of the header of the local file, followed by the compressed file data. The length of the local file header is 30 bytes plus the length of the file name. It contains a redundant copy of the metadata from the header of the central directory, as well as the sizes of the compressed and uncompressed data files behind it. Zip is a container format, not a compression algorithm. Each file's data is compressed using the algorithm specified in the metadata — usually DEFLATE .
This description of the zip format omits many details that are not needed to understand the zip bomb. For full information, see section 4.3 APPNOTE.TXT or the PKZip File Structure by Florian Buchholz, or see the source code .
Significant redundancy and a lot of ambiguities in the zip format open up opportunities for mischief of different kinds. A zip bomb is just the tip of the iceberg. Links for further reading:
By compressing a long string of repeated bytes, we can create a core of highly compressed data. The compression ratio of the kernel itself cannot exceed the DEFLATE limit of 1032, so we need a way to reuse the kernel in many files, without creating a separate copy of it in each file. We can do this by overlapping files: make so that many headers of the central directory point to a single file whose data is the core.

Consider an example of how this design affects the compression ratio. Suppose a core of 1000 bytes is unpacked in 1 MB. Then the first megabyte of output “costs” 1078 bytes of input data:
But each 1 MB of output after the first costs only 47 bytes - we do not need another header of the local file or another copy of the kernel, only an additional header of the central directory. Thus, while the first link from the core has a compression ratio of 1,000,000 / 1,078 ≈ 928, each additional link moves the coefficient closer to 1,000,000 / 47 ≈ 21,277, and a large core raises the ceiling.
The problem with this idea is the lack of compatibility. Since many headers of the central directory point to one header of the local file, the metadata (in particular, the file name) cannot be the same for each file. Some parsers swear at this . For example, Info-ZIP UnZip (standard
Python zipfile also throws an exception :
Next, we’ll look at how to redesign for file name consistency, while preserving most of the benefits of overlapping files.
We need to separate the headers of local files for each file, while reusing one core. Simply combining all the headers does not work, because the zip parser will find the header of the local file where it expects the start of the DEFLATE stream. But the idea will work, with minor changes. We will use the DEFLATE function of uncompressed blocks to “quote” the headers of local files so that they appear to be part of the same DEFLATE stream that ends in the kernel. Each header of the local file (except the first) will be interpreted in two ways: as code (part of the structure of the zip file) and as data (part of the file content).

A DEFLATE stream is a sequence of blockswhere each block can be compressed or uncompressed. We usually only think about compressed blocks, for example, the kernel is one big compressed block. But there are also uncompressed ones that start with a 5-byte header with a length field, which simply means: "print the next n bytes verbatim." Unpacking an uncompressed block means only deleting the 5-byte header. Compressed and uncompressed blocks can mix freely in the DEFLATE stream. The output is a concatenation of the results of unpacking all the blocks in order. The concept of “uncompressed” only matters at the DEFLATE level; file data is still considered “compressed” at the zip level, regardless of which blocks are used.
The easiest way to imagine this design is as an internal overlap, from the last file to the first. We start by inserting a kernel that will form the end of the data file for each file. Add the header of the local LFH N file and the header of the central CDH N directory that points to it. Set the “compressed size” metadata field in LFH N and CDH N to the compressed core size. Now add 5-byte header uncompressed block (green color in the diagram), which is equal to the size of length field LFH N . Add the second header of the local file LFH N −1 and the header of the central directory CDH N −1that points to it. Set metadata field "compressed size" as the new header of the compressed kernel size plus the size of the uncompressed block header (5 bytes) plus the size LFH N .
At the moment, the zip file contains two files with the names Y and Z. Let's go through what the parser will see when parsing. Suppose the compressed kernel size is 1000 bytes and the LFH N size is 31 bytes. Start with CDH N −1 and follow the sign for LFH N −1. The name of the first file is Y, and the compressed size of its data file is 1036 bytes. Interpreting the next 1036 bytes as a DEFLATE stream, we first come across a 5-byte header of an uncompressed block that says to copy the next 31 bytes. We write down the next 31 bytes, which are LFH N , which we unpack and add to the Y file. Moving further in the DEFLATE stream, we find the compressed block (kernel), which we unpack into the Y file. Now we have reached the end of the compressed data and finished with the Y file.
Moving on to the next file, we follow the pointer from CDH N to LFH Nand find a file called Z, whose compressed size is 1000 bytes. Interpreting these 1000 bytes as a DEFLATE stream, we immediately encounter a compressed block (core again) and unpack it into a Z file. Now we have reached the end of the final file and finished. The output file Z contains the unpacked kernel; output image Y is the same, but additionally with the prefix 31 bytes LFH N .
We complete the construction by repeating the citation procedure until the zip archive includes the required number of files. Each new file adds a central directory header, a local file header, and an uncompressed block to quote directly from the next local file header. Compressed file data is typically a chain of uncompressed DEFLATE blocks (quoted local file headers) followed by a compressed core. Each byte in the kernel contributes about 1032 N to the output size, because each byte is part of all Nfiles. The output files are also of different sizes: the earlier ones are larger than the later ones because they quote the headers of the local files more. The contents of the output files do not make much sense, but no one said that it should make sense.
This overlap citation design has better compatibility than the full overlap design from the previous section, but compatibility is achieved through compression. There, each added file cost only the title of the central directory, here it costs the title of the central directory, the header of the local file and another 5 bytes for the citation header.
Having received the basic design of the zip bomb, we will try to make it as efficient as possible. We want to answer two questions:
Our advantage as much as possible to compress the core, because each unpacked bytes multiplied by the of N . For this purpose, we use a custom DEFLATE compressor called bulk_deflate, specialized in compressing a string of repeated bytes.
All decent DEFLATE archivers come close to the compression ratio of 1032 on an endless stream of repeated bytes, but we are concerned about the specific size. In our archive size, bulk_deflate holds more data than general purpose archivers: about 26 KB more than zlib and Info-ZIP, and about 15 KB more than Zopfli , which sacrifices speed for the sake of compression quality.

The price of a high compression ratio bulk_deflate - the lack of versatility. It can compress only lines of repeating bytes and only a certain length, namely 517 + 258 k for an integer k ≥ 0. In addition to good compression, bulk_deflate works quickly, performing work in almost the same time, regardless of the size of the input data, not counting the work of actually writing a compressed line.
For our purposes, file names are almost dead weight. Although they contribute to the output size by being part of the quoted headers of local files, the bytes in the file name contribute much less than the bytes in the kernel. We want the file names to be as short as possible, while being different, without forgetting about compatibility.
Each byte spent on a file name means two bytes not spent on the kernel (two because each file name appears twice: in the header of the central directory and in the header of the local file). Filename bytes leads to an average of only ( of N + 1) / 4 bytes of output, while the bytes in the kernel counts as 1032 of N . Examples: 1 , 2 , 3 .
The first compatibility consideration is encoding. The zip format specification states that file names should be interpreted as CP 437 or UTF-8 if a specific flag bit is set ( APPNOTE.TXT, appendix D ). This is the main point of incompatibility between zip parsers, which can interpret file names in some fixed or locale-specific encoding. Therefore, for compatibility, it is better to limit yourself to characters with the same encoding in both CP 437 and UTF-8. Namely, these are 95 printable US-ASCII characters.
We are also bound by file system naming restrictions. Some file systems are case insensitive, so 'a' and 'A' are not considered different names. Common file systems, such as FAT32, prohibit certain characters , such as '*' and '?'.
As a safe, but not necessarily optimal compromise, our zip bomb will use file names from the 36-character alphabet, which does not include special characters and characters of different case:
File names are generated in an obvious way, all positions in turn, with the addition of a position at the end of the loop:
There are 36 one-character file names, 36² two-character names, and so on. Four bytes is enough for 1,727,604 different file names.
Given that the file names in the archive will usually have different lengths, how can I better sort them: from the shortest to the longest or vice versa? If you think a little, it is better to put the longest names last. This sorting adds more than 900 MB of output to zblg.zip , compared to the longest to shortest ordering. However, this is a minor optimization, because 900 MB is only 0,0003% of the total size of the issue.
Overlapping quoting design allows you to place a compressed data core, and then cheaply copy it many times. For a specific size of the zip file X , how much space is optimal to allocate for storing the kernel, and how much to create copies?
To find the optimal balance, you need to optimize only one variable N , the number of files in the zip archive. Each N value requires a certain amount of overhead for the headers of the central directory, headers of local files, headers of citation blocks and file names. The rest of the space will be occupied by the core. Since Nmust be an integer, and you can only put a certain number of files before the kernel size drops to zero, just check every possible value of N and select the one that gives the greatest output.
Applying the optimization procedure to X = 42,374 for 42.zip finds a maximum at N = 250. These 250 files require 21,195 bytes of overhead, leaving 21,179 bytes for the kernel. A kernel of this size is unpacked into 21,841,249 bytes (1031.3 to 1 ratio). 250 copies of the unpacked kernel plus a few cited headers of local files gives a total unpacked output of 5,461,307,620 bytes and a compression ratio of 129,000.
Optimization has led to an almost even distribution of space between the kernel and the file headers. This is not a coincidence. Consider a simplified model of a citation construction with overlap. In a simplified model, we ignore file names, as well as a slight increase in the size of the output file due to quoting the headers of local files. Analysis of the simplified model will show that the optimal distribution between the kernel and the file headers is approximately uniform, and the output size with the optimal distribution grows quadratically depending on the size of the input.
Definition of some constants and variables:
Let H (N) be the volume of the overhead for headers for N files. See the chart to understand the essence of the formula.
For the kernel, X - H (N) places remain . The total unpacked size S X (N) is equal to the size of N copies of the kernel unpacked with the ratio C (in this simplified model, we ignore the slight additional extension from the mentioned local file headers).
S X (N) is a polynomial in part N, therefore, the maximum should be where the derivative S ' X (N) is equal to zero. Taking the derivative and finding zero gives us N OPT , the optimal number of files.
H (N OPT ) gives the optimal amount of space for placing file headers. It is independent of CDH, LFH and C and is close to X / 2 .
S X (N OPT ) - total unpacked size at optimal distribution. From this we see that the size of the output increases quadratically with increasing input data.
Increasing the size of the zip file, in the end we will encounter the limits of the zip format: the archive can have no more than 2 16 −1 files with a size of no more than 2 32 −1 bytes each. Worse, some implementations take maximum values as an indicator of the presence of 64-bit extensions , so our limits are actually 2 16 −2 and 2 32 −2. It happens that the first time we encounter a limit on the size of an uncompressed file. With a zip file size of 8 319 377 bytes, naive optimization will give us the number of files 47 837 and a maximum file of 2 32 +311 bytes.
(Actually, it’s a bit more complicated because the exact limits are implementation dependent. Python's zipfile ignoresthe number of files archive / zip in Go allows you to increase the number of files until they match the lower 16 bits. But for general compatibility, we must adhere to the established limits).
If we cannot infinitely increase N or kernel size, we would like to find the maximum compression ratio within the zip format. You need to make the kernel as large as possible with the maximum number of files. Despite the fact that we can no longer maintain approximately uniform separation between the kernel and the file headers, each added file still increases the compression ratio - just not as fast as if we could continue to increase the kernel. In fact, as we add files, we will need to reducekernel size to make room for the maximum file size, which grows slightly with each file added.
The plan leads to a zip archive with 2 16 −2 files and a kernel, which is unpacked into 2 32 −2 178 825 bytes. The files will be larger towards the beginning of the zip archive - the first and largest file is unpacked in 2 32 −56 bytes. This is as close as we can using the rough output parameters of bulk_deflate - encoding the final 54 bytes will cost more than their size (the zip file as a whole has a compression ratio of 28 million, and the final 54 bytes will receive a maximum of 54 ⋅ 10 32 ⋅ ( 2 16- 2) ≈ 36? 5 million bytes, so this only helps if 54 bytes can be encoded into one byte - and I could not code less than two. Therefore, if you cannot encode 54 bytes into 1 byte, this only reduces the compression ratio). The output size of this zip bomb is 281,395,456,244,934 bytes, 99.97% of the theoretical maximum (2 32 - 1) × (2 16 - 1). Any significant improvement in compression ratio can be achieved only by reducing the size of the input signal, and not by increasing the output.
Among the metadata in the header of the central directory and the header of the local file is a checksum of the uncompressed file data - CRC-32 . This poses a problem because the amount of CRC-32 calculations for each file is proportional to its size, which is very large by default (after all, it's a zip bomb). We would prefer to do work that is at least proportional to the size of the archive. Two factors work in our favor: all files have a common core, and an uncompressed kernel is a string of repeated bytes. Imagine CRC-32 as a matrix product - this will allow us not only to quickly calculate the checksum of the kernel, but also to reuse the calculations between files. The method described in this section is a small extension of the crc32_combine function in zlib, which Mark Adler explainshere .
CRC-32 can be modeled as a state machine, updating a 32-bit state register for each input bit. The basic update operations for bits 0 and 1 are:
If you represent the state register as a 32-element binary vector and use XOR for addition and multiplication, then it
Also,

Transformation matrices 33 × 33 M 0 and M 1, которые вычисляют изменение состояния CRC-32, выполненное битами 0 и 1, соответственно. Векторы столбцов хранятся с наиболее значащим битом внизу: читая первый столбец снизу вверх, вы видите полиномиальную константу CRC-32 edb8832016 = 111011011011100010000011001000002. Эти две матрицы различаются только в конечном столбце, который представляет вектор трансляции в однородных координатах. В M0 трансляция равна нулю, а в M1 — edb8832016, полиномиальная константа CRC-32. Единицы сразу над диагональю представляют состояние операции
Both operations
And we can imagine a change in the state of a row repeating 'a' by multiplying many copies of M a - raising the matrix to a power. We can do this quickly using fast exponentiation algorithm , which allows to calculate the M n just log 2 n steps. For example, here is a matrix for changing the state of a string of 9 characters 'a':
The matrix quick multiplication algorithm is useful for computing M kernel , a matrix for an uncompressed kernel, since the kernel is a string of repeated bytes. To get the CRC-32 checksum from the matrix, multiply the matrix by the zero vector (the zero vector is in uniform coordinates, that is 32 zeros, and then the unit; here we omit the slight complication of the pre- and post-processing of the checksum to check for compliance). To calculate the checksum for each file, we work in the opposite direction. We start by initializing M: = M kernel . The kernel checksum is also the checksum of the final file N , so we multiply Ma zero vector and stores the received checksum in the CDH N and LFH N . The data of file N − 1 is the same as the file data of file N , but with the prefix LFH N added . Therefore, we calculate , state change matrix for LFH N and update
, state change matrix for LFH N and update . Now M represents the cumulative change in state from processing LFH N behind the nucleus. We calculate the checksum for the file N − 1 , again multiplying M by the zero vector. We continue the procedure by accumulating state change matrices in M until all files are processed.
. Now M represents the cumulative change in state from processing LFH N behind the nucleus. We calculate the checksum for the file N − 1 , again multiplying M by the zero vector. We continue the procedure by accumulating state change matrices in M until all files are processed.
Earlier, we faced the problem of expansion due to limitations of the zip format - it was impossible to issue more than 281 TB, regardless of how smartly the zip file was packaged. You can transcend these limits using Zip64, a zip format extension that increases the size of some header fields to 64 bits. Support for Zip64 is by no means universal, but it is one of the most commonly implemented extensions. As for the compression ratio, the effect of Zip64 is to increase the size of the header of the central directory from 46 to 58 bytes, and the size of the header of the local directory from 30 to 50 bytes. Looking at the optimal expansion coefficient formula in a simplified model, we see that the zip bomb in Zip64 format still grows quadratically, but slower due to the larger denominator - this can be seen in the diagram below. Due to the loss of compatibility and growth retardation, we remove almost any restrictions on file size.
Suppose we need a zip bomb that expands to 4.5 PB, like 42.zip. How big should the archive be? Using binary search, we find that the minimum size of such a file is 46 MB.
4.5 petabytes - roughly the same amount of data was recorded by the Event Horizon Telescope for the first image of a black hole : racks and racks with hard drives in the data center.
With Zip64, it’s almost not interesting to consider the maximum compression ratio, because we can simply continue to increase the size of the zip file and the compression ratio with it, until even the compressed zip file becomes prohibitive. An interesting threshold, however, is 2 64 bytes (18 EB or 16 EiB) - so much data will not fit on most file systems. Binary search finds the smallest zip bomb that produces at least as much output: it contains 12 million files and a compressed core of 1.5 GB. The total zip file size is 2.9 GB and it is unpacked in 2 64+11 727 895 877 bytes with a compression ratio of more than 6.2 billion to one. I did not upload this file for download, but you can generate it yourself using the source code . He has files of such a size that even a bug was revealed in Info-ZIP UnZip 6.0.
DEFLATE is the most common compression algorithm for the zip format, but this is only one of many options. Probably the second most common algorithm is bzip2 . Although it is not as compatible as DEFLATE. Theoretically, in bzip2, the maximum compression ratio is about 1.4 million to one, which allows a denser packing of the core.
bzip2 first encodes the “run-length encoding”, reducing the string length of repeating bytes by 51 times. Then the data is divided into 900 KB blocks and each block is compressed separately. Theoretically, one block can compress up to 32 bytes. 900 000 × 51/32 = 1 434 375.
Ignoring the loss of compatibility, does bzip2 make a more effective bomb?
Yes - but only for small files. The problem is that in bzip2 there is nothing like the uncompressed DEFLATE blocks that we used to quote the headers of local files. Thus, it is impossible to overlap files and reuse the kernel - for each file you need to write your own copy, so the overall compression ratio will not be better than the ratio for any single file. In the graph below, we see that without overlapping, bzip2 is superior to DEFLATE only for files about megabytes in size.
There is only hope for an alternative means of quoting headers in bzip2, which is discussed in the next section. In addition, if you know that a particular zip parser supports bzip2 andallows for mismatched file names, you can use the complete overlap construct, which does not need to be quoted.

Comparison of the compression ratio of different zip bombs. Pay attention to the logarithmic axis. Each design is shown with and without Zip64. Structures without overlap have a linear growth rate, which can be seen from the constant ratio of the axes. The vertical offset of the bzip2 graph means that the compression ratio of bzip2 is about a thousand times greater than that of DEFLATE. The DEFLATE constructs cited have a quadratic growth rate, as evidenced by an inclination to the 2: 1 axes. The Zip64 variant is slightly less effective, but allows for more than 281 TB. Graphs for bzip2 with quoting through an additional field go from quadratic to linear when either the maximum file size is reached (2 32−2 bytes), or the maximum allowed number of files
So far, we have used the DEFLATE function to quote the headers of local files, and we just saw that this trick does not work in bzip2. However, there is an alternative citation method, somewhat more limited, that uses only zip format functions and is independent of the compression algorithm.
At the end of the header structure of the local file, there is an additional field of variable length for storing information that does not fit into the usual header fields ( APPNOTE.TXT, section 4.3.7) Additional information may include, for example, a timestamp or uid / gid from Unix. Zip64 information is also stored in an additional field. An additional field is represented as a length-value structure; if you increase the length without adding a value, the additional field will include what is behind it in the zip file, namely the next header of the local file. Using this method, each header of the local file can “quote” the following headers, enclosing them in its own additional field. Compared to DEFLATE, there are three advantages:
Despite these advantages, quoting through additional fields is less flexible. This is not a chain, as in DEFLATE: each heading of a local file should contain not only the immediately following heading, but also all subsequent headings. Additional fields increase as you approach the beginning of the zip file. Since the maximum field length is 2 16 −1 bytes, only up to 1808 local file headers (or 1170 in Zip64) can be quoted, assuming the names are assigned as expected(in the case of DEFLATE, you can use an additional field to quote the first (shortest) headers of local files, and then switch to quoting DEFLATE for the rest). Another problem: in order to correspond to the internal data structure of the additional field, it is necessary to select a 16-bit tag for the type ( APPNOTE.TXT, section 4.5.2 ) preceding the citation data. We want to select a type tag that will cause parsers to ignore the data in quotation marks, rather than try to interpret them as meaningful metadata. Zip parsers should ignore tags of an unknown type, so we can select tags at random, but there is a risk that in the future some tag will violate the compatibility of the design.
The previous diagram illustrates the possibility of using additional fields in bzip2, c and without Zip64. On both graphs there is a turning point, when the growth goes from quadratic to linear. Without Zip64, this happens where the maximum size of the uncompressed file is reached (2 32−2 bytes); then you can only increase the number of files, but not their size. The graph completely ends when the number of files reaches 1809, then we run out of space in an additional field for quoting additional headers. With Zip64, a fracture occurs on 1171 files, after which only the file size can be increased, but not their number. An additional field helps in the case of DEFLATE, but the difference is so small that it is not visually noticeable. It increases the compression ratio of zbsm.zip by 1.2%; zblg.zip by 0.019%; and zbxl.zip by 0.0025%.
In their work on this subject, Pletz and colleagues use file overlap to create an almost self-replicating zip archive. The file overlap itself was suggested earlier (slide 47) by Ginvael Coldwind.
We developed a design of a zip bomb with a quotation overlap taking into account compatibility - a number of differences in implementations, some of which are shown in the table below. The resulting design is compatible with zip parsers that work in the usual way, that is, first checking the central directory and using it as an index of files. Among them, a unique zip parser from Nailwhich is automatically generated from formal grammar. However, the design is incompatible with "streaming" parsers, which analyze the zip file from start to finish in one pass without first reading the central directory. By their nature, streaming parsers do not allow files to overlap in any way. Most likely, they will only extract the first file. In addition, they may even throw an error, as is the case with sunzip , which parses the central directory at the end and checks for consistency with the headers of the local files that it has already seen.
If you want the extracted files to start with a specific prefix that is different from the header bytes of the local file, you can insert a DEFLATE block before the uncompressed block that the following header quotes. Not every file in the zip archive should participate in the creation of the bomb: you can include ordinary files in the archive, if necessary, in order to correspond to some special format (there is a parameter in the source code
Pdfin many ways similar to zip. It has a cross-reference table at the end of the file that points to previous objects, and it supports compression of objects through the FlateDecode filter. I have not tried, but you can use the idea of quoting with overlap to make a PDF bomb. Perhaps you don’t even have to work hard here: binaryhax0r writes in a blog post that you can simply specify several FlateDecode layers on one object, after which creating a PDF bomb becomes trivial.
Defining a particular class of zip bombs described in this article is easy: just find the overlapping files. Mark Adler wrote a patchfor Unzip Info-ZIP, which does just that. However, in general, blocking overlapping files does not protect against all classes of zip bombs. It is difficult to predict in advance whether the file is a zip bomb or not if you do not have accurate knowledge about the internal components of the parsers that will be used to analyze it. Looking at the headers and summing the “uncompressed size” fields of all files does not work , because the value in the headers may not match the actual uncompressed size (in the compatibility table, see the line “allows the file is too small”). Reliable protection against zip bombs includes limits on time, memory and disk space in the zip parser during its operation. Take parsing of zip files, like any complex operations with untrusted data, with caution.
Таблица с перечислением некоторых zip-парсеров, а также различных функций, пограничных ситуаций и конструкций zip-бомб. Для лучшей совместимости используйте сжатие DEFLATE без Zip64, сопоставляйте имена в заголовках центрального каталога и заголовках локальных файлов, вычисляйте правильные значения CRC и избегайте максимальных значений 32-битных и 16-битных полей.
Thanks to Mark Adler , Russ Cox , Brandon Enright , Marek Maykovsky , Josh Wolfe and the reviewers of USENIX WOOT 2019 for comments on the draft of this article. Kaolan McNamara assessed the impact of zip bombs on LibreOffice's security.
A version of this article has been prepared for the USENIX WOOT 2019 Workshop . Source code is available. Artifacts for presentation at the workshop are in the zipbomb-woot19.zip file .
Did you find a system that drops one of the bombs? Did bombs help you find a bug or make money in a bug search program? Let me know, I will try to mention it here.
After renaming zblg.zip to zblg.odt or zblg.docx, LibreOffice creates and deletes a series of temporary files of approximately 4 GB, trying to determine the file format. Ultimately, he finishes doing this and deletes the temporary files as they arrive, so the zip bomb only causes a temporary DoS without filling up the disk. Kaolan McNamara answered my error message.
I tried zip bombs against the local addons-server installation, which is part of the addons.mozilla.org software. The system gracefully handles the bomb, imposing a time limit of 110 seconds on the extraction of files. The zip bomb expands quickly, as far as the disk allows up to this time limit, but then the process is killed and the unpacked files are ultimately automatically cleared.
Mark Adler wrote a patch for UnZip to detect this class of zip bombs.
July 5, 2019: I noticed that CVE-2019-13232 was assigned to UnZip. Personally, I would argue that the ability / inability of UnZip (or any zip parser) to process this kind of zip bomb is necessarily a vulnerability or even a bug. This is a natural implementation that does not violate the specification, what can I say. The bomb type in this article is just one type, and there are many other ways you can puzzle a zip parser. As mentioned above, if you want to protect yourself from resource exhaustion attacks, you should not try to list, detect, and block every single known attack; rather, it is necessary to establish external restrictions on time and other resources so that the parser does not get into such a situation, regardless of what kind of attack it encountered. There is nothing wrong with trying to detect and reject certain designs as an optimization of the first pass, but you can not stop there. Unless you end up isolating and restricting operations with untrusted data, your system is probably still vulnerable. Consider the analogy with cross-site scripting in HTML: the right protection is not to try to filter out specific bytes that can be interpreted as code, but to avoid everything correctly.
Twitter user @TVqQAAMAAAAEAAA reports : "McAfee antivirus on my test machine just exploded." I have not tested it myself and I do not have such details as the version number.
Tavis Ormandi indicates that VirusTotal has a number of timeouts for zblg.zip ( screenshot from June 6, 2019 ): AhnLab-V3, ClamAV, DrWeb, Endgame, F-Secure, GData, K7AntiVirus, K7GW, MaxSecure, McAfee, McAfee-GW -Edition, Panda, Qihoo-360, Sophos ML, VBA32. Results for zbsm.zip ( screenshot from June 6, 2019) are similar, but with a different set of timeout engines: Baido, Bkav, ClamAV, CMC, DrWeb, Endgame, ESET-NOD32, F-Secure, GData, Kingsoft, McAfee-GW-Edition, NANO-Antivirus, Acronis. Interestingly, there are no timeouts in the results of zbxl.zip ( screenshot from June 6, 2019 ). Perhaps some antiviruses do not support Zip64? Several engines detect files as a kind of “compression bomb”. It is interesting to see if they will continue to do so with minor changes, such as changing file names or adding an ASCII prefix to each file.
It's time to put an end to Facebook. This is not a neutral job for you: every day when you come to work, you are doing something wrong. If you have a Facebook account, delete it. If you work on Facebook, get laid off.
And do not forget that the National Security Agency must be destroyed.
- zbsm.zip 42 kB → 5.5 GB
- zblg.zip 10 MB → 281 TB
- zbxl.zip 46 MB → 4.5 PB (Zip64, less compatible with parsers)
Source:
git clone https://www.bamsoftware.com/git/zipbomb.gitzipbomb-20190702.zip
Data and sources of illustrations:
git clone https://www.bamsoftware.com/git/zipbomb-paper.git
| non-recursive | recursive | ||||
|---|---|---|---|---|---|
| archive size | uncompressed size | ratio | uncompressed size | ratio | |
| Quine Cox | 440 | 440 | 1.0 | ∞ | ∞ |
| Quine Ellingsen | 28,809 | 42 569 | 1.5 | ∞ | ∞ |
| 42.zip | 42,374 * | 558 432 | 13.2 | 4 507 981 343 026 016 | 106 billion |
| this technique | 42,374 | 5 461 307 620 | 129 thousand | 5 461 307 620 | 129 thousand |
| this technique | 9 893 525 | 281 395 456 244 934 | 28 million | 281 395 456 244 934 | 28 million |
| this technique (Zip64) | 45 876 952 | 4 507 981 427 706 459 | 98 million | 4 507 981 427 706 459 | 98 million |
* There are two versions of 42.zip: the old 42 374 bytes, and the newer 42 428 bytes. The difference is that the new one requires a password before unpacking. We compare only with the old version. Here is a copy of the file if you need it: 42.zip .
** I would like to know and indicate the author of 42.zip, but could not find it - let me know if you have any information.
Zip bombs must overcome the fact that the DEFLATE compression algorithm most often supported by parsers cannot exceedthe compression ratio is 1032 to 1. For this reason, zip bombs usually rely on recursive decompression by inserting zip files into zip files to get an additional 1032 ratio with each layer. But the trick only works in implementations that decompress recursively, and most don't. The most famous 42.zip bomb expands to a formidable 4.5 PB if all six layers are recursively unpacked, but on the top layer it has trifling 0.6 MB. Zip-quines, like those of Cox and Ellingsen , give out a copy of themselves and, thus, expand indefinitely when recursively unpacking. But they are also completely safe when unpacking once.
This article shows how to create a non-recursive zip bomb, the compression ratio of which exceeds the DEFLATE limit of 1032. It works by overlapping files inside a zip container to reference the “core” of highly compressed data in multiple files without making multiple copies. The output size of the zip bomb grows quadratically from the input size; i.e., the compression ratio improves with increasing bomb size. The design depends on the features of zip and DEFLATE: it cannot be transferred directly to other file formats or compression algorithms. The bomb is compatible with most zip parsers, except for streaming ones, which analyze files in a single pass without checking the central directory of the zip file. We try to balance two conflicting goals:
- Increase compression ratio. We define the compression ratio as the sum of the sizes of all the files in the archive divided by the size of the zip file itself. It does not take into account file names or other file system metadata, but only the contents.
- Keep compatibility. Zip is a complex format, and parsers differ, especially in borderline situations, and additional functions. Do not use techniques that work only with certain parsers. We will note some ways to increase the efficiency of a zip bomb with a certain loss of compatibility.
Zip file structure
Zip-file consists of a central directory of links to files .
The central directory is at the end of the zip file. This is a list of central directory headers . Each central directory header contains metadata for a single file, such as the file name and CRC-32 checksum, as well as a pointer back to the local file header. The central directory header has a length of 46 bytes plus the length of the file name.
The file consists of the header of the local file, followed by the compressed file data. The length of the local file header is 30 bytes plus the length of the file name. It contains a redundant copy of the metadata from the header of the central directory, as well as the sizes of the compressed and uncompressed data files behind it. Zip is a container format, not a compression algorithm. Each file's data is compressed using the algorithm specified in the metadata — usually DEFLATE .
This description of the zip format omits many details that are not needed to understand the zip bomb. For full information, see section 4.3 APPNOTE.TXT or the PKZip File Structure by Florian Buchholz, or see the source code .
Significant redundancy and a lot of ambiguities in the zip format open up opportunities for mischief of different kinds. A zip bomb is just the tip of the iceberg. Links for further reading:
- “Ten Thousand Security Traps: A ZIP Format,” by Ginwael Coldwind
- Ambiguous zip parsing allows you to hide Firefox add-on files from the linter and people : my vulnerability at addons.mozilla.org
First discovery: overlapping files
By compressing a long string of repeated bytes, we can create a core of highly compressed data. The compression ratio of the kernel itself cannot exceed the DEFLATE limit of 1032, so we need a way to reuse the kernel in many files, without creating a separate copy of it in each file. We can do this by overlapping files: make so that many headers of the central directory point to a single file whose data is the core.
Consider an example of how this design affects the compression ratio. Suppose a core of 1000 bytes is unpacked in 1 MB. Then the first megabyte of output “costs” 1078 bytes of input data:
- 31 bytes for the local file header (including 1 byte file name)
- 47 bytes for the central directory header (including a 1-byte file name)
- 1000 bytes per core
But each 1 MB of output after the first costs only 47 bytes - we do not need another header of the local file or another copy of the kernel, only an additional header of the central directory. Thus, while the first link from the core has a compression ratio of 1,000,000 / 1,078 ≈ 928, each additional link moves the coefficient closer to 1,000,000 / 47 ≈ 21,277, and a large core raises the ceiling.
The problem with this idea is the lack of compatibility. Since many headers of the central directory point to one header of the local file, the metadata (in particular, the file name) cannot be the same for each file. Some parsers swear at this . For example, Info-ZIP UnZip (standard
unzipUnix program ) retrieves files, but with warnings:$ unzip overlap.zip
inflating: A
B: mismatching "local" filename (A),
continuing with "central" filename version
inflating: B
...Python zipfile also throws an exception :
$ python3 -m zipfile -e overlap.zip. Traceback (most recent call last): ... __main __. BadZipFile: File name in directory 'B' and header b'A 'differ.
Next, we’ll look at how to redesign for file name consistency, while preserving most of the benefits of overlapping files.
Second discovery: quoting the headers of local files
We need to separate the headers of local files for each file, while reusing one core. Simply combining all the headers does not work, because the zip parser will find the header of the local file where it expects the start of the DEFLATE stream. But the idea will work, with minor changes. We will use the DEFLATE function of uncompressed blocks to “quote” the headers of local files so that they appear to be part of the same DEFLATE stream that ends in the kernel. Each header of the local file (except the first) will be interpreted in two ways: as code (part of the structure of the zip file) and as data (part of the file content).
A DEFLATE stream is a sequence of blockswhere each block can be compressed or uncompressed. We usually only think about compressed blocks, for example, the kernel is one big compressed block. But there are also uncompressed ones that start with a 5-byte header with a length field, which simply means: "print the next n bytes verbatim." Unpacking an uncompressed block means only deleting the 5-byte header. Compressed and uncompressed blocks can mix freely in the DEFLATE stream. The output is a concatenation of the results of unpacking all the blocks in order. The concept of “uncompressed” only matters at the DEFLATE level; file data is still considered “compressed” at the zip level, regardless of which blocks are used.
The easiest way to imagine this design is as an internal overlap, from the last file to the first. We start by inserting a kernel that will form the end of the data file for each file. Add the header of the local LFH N file and the header of the central CDH N directory that points to it. Set the “compressed size” metadata field in LFH N and CDH N to the compressed core size. Now add 5-byte header uncompressed block (green color in the diagram), which is equal to the size of length field LFH N . Add the second header of the local file LFH N −1 and the header of the central directory CDH N −1that points to it. Set metadata field "compressed size" as the new header of the compressed kernel size plus the size of the uncompressed block header (5 bytes) plus the size LFH N .
At the moment, the zip file contains two files with the names Y and Z. Let's go through what the parser will see when parsing. Suppose the compressed kernel size is 1000 bytes and the LFH N size is 31 bytes. Start with CDH N −1 and follow the sign for LFH N −1. The name of the first file is Y, and the compressed size of its data file is 1036 bytes. Interpreting the next 1036 bytes as a DEFLATE stream, we first come across a 5-byte header of an uncompressed block that says to copy the next 31 bytes. We write down the next 31 bytes, which are LFH N , which we unpack and add to the Y file. Moving further in the DEFLATE stream, we find the compressed block (kernel), which we unpack into the Y file. Now we have reached the end of the compressed data and finished with the Y file.
Moving on to the next file, we follow the pointer from CDH N to LFH Nand find a file called Z, whose compressed size is 1000 bytes. Interpreting these 1000 bytes as a DEFLATE stream, we immediately encounter a compressed block (core again) and unpack it into a Z file. Now we have reached the end of the final file and finished. The output file Z contains the unpacked kernel; output image Y is the same, but additionally with the prefix 31 bytes LFH N .
We complete the construction by repeating the citation procedure until the zip archive includes the required number of files. Each new file adds a central directory header, a local file header, and an uncompressed block to quote directly from the next local file header. Compressed file data is typically a chain of uncompressed DEFLATE blocks (quoted local file headers) followed by a compressed core. Each byte in the kernel contributes about 1032 N to the output size, because each byte is part of all Nfiles. The output files are also of different sizes: the earlier ones are larger than the later ones because they quote the headers of the local files more. The contents of the output files do not make much sense, but no one said that it should make sense.
This overlap citation design has better compatibility than the full overlap design from the previous section, but compatibility is achieved through compression. There, each added file cost only the title of the central directory, here it costs the title of the central directory, the header of the local file and another 5 bytes for the citation header.
Optimization
Having received the basic design of the zip bomb, we will try to make it as efficient as possible. We want to answer two questions:
- What is the maximum compression ratio for a given zip file size?
- What is the maximum compression ratio given the limitations of the zip format?
Kernel Compression
Our advantage as much as possible to compress the core, because each unpacked bytes multiplied by the of N . For this purpose, we use a custom DEFLATE compressor called bulk_deflate, specialized in compressing a string of repeated bytes.
All decent DEFLATE archivers come close to the compression ratio of 1032 on an endless stream of repeated bytes, but we are concerned about the specific size. In our archive size, bulk_deflate holds more data than general purpose archivers: about 26 KB more than zlib and Info-ZIP, and about 15 KB more than Zopfli , which sacrifices speed for the sake of compression quality.
The price of a high compression ratio bulk_deflate - the lack of versatility. It can compress only lines of repeating bytes and only a certain length, namely 517 + 258 k for an integer k ≥ 0. In addition to good compression, bulk_deflate works quickly, performing work in almost the same time, regardless of the size of the input data, not counting the work of actually writing a compressed line.
File names
For our purposes, file names are almost dead weight. Although they contribute to the output size by being part of the quoted headers of local files, the bytes in the file name contribute much less than the bytes in the kernel. We want the file names to be as short as possible, while being different, without forgetting about compatibility.
Each byte spent on a file name means two bytes not spent on the kernel (two because each file name appears twice: in the header of the central directory and in the header of the local file). Filename bytes leads to an average of only ( of N + 1) / 4 bytes of output, while the bytes in the kernel counts as 1032 of N . Examples: 1 , 2 , 3 .
The first compatibility consideration is encoding. The zip format specification states that file names should be interpreted as CP 437 or UTF-8 if a specific flag bit is set ( APPNOTE.TXT, appendix D ). This is the main point of incompatibility between zip parsers, which can interpret file names in some fixed or locale-specific encoding. Therefore, for compatibility, it is better to limit yourself to characters with the same encoding in both CP 437 and UTF-8. Namely, these are 95 printable US-ASCII characters.
We are also bound by file system naming restrictions. Some file systems are case insensitive, so 'a' and 'A' are not considered different names. Common file systems, such as FAT32, prohibit certain characters , such as '*' and '?'.
As a safe, but not necessarily optimal compromise, our zip bomb will use file names from the 36-character alphabet, which does not include special characters and characters of different case:
0 1 2 3 4 5 6 7 8 9 ABCDEFGHIJKLMNOPQRSTU VWXYZ
File names are generated in an obvious way, all positions in turn, with the addition of a position at the end of the loop:
"0", "1", "2", ..., "Z", "00", "01", "02", ..., "0Z", ... "Z0", "Z1", "Z2", ..., "ZZ", "000", "001", "002", ...
There are 36 one-character file names, 36² two-character names, and so on. Four bytes is enough for 1,727,604 different file names.
Given that the file names in the archive will usually have different lengths, how can I better sort them: from the shortest to the longest or vice versa? If you think a little, it is better to put the longest names last. This sorting adds more than 900 MB of output to zblg.zip , compared to the longest to shortest ordering. However, this is a minor optimization, because 900 MB is only 0,0003% of the total size of the issue.
Core size
Overlapping quoting design allows you to place a compressed data core, and then cheaply copy it many times. For a specific size of the zip file X , how much space is optimal to allocate for storing the kernel, and how much to create copies?
To find the optimal balance, you need to optimize only one variable N , the number of files in the zip archive. Each N value requires a certain amount of overhead for the headers of the central directory, headers of local files, headers of citation blocks and file names. The rest of the space will be occupied by the core. Since Nmust be an integer, and you can only put a certain number of files before the kernel size drops to zero, just check every possible value of N and select the one that gives the greatest output.
Applying the optimization procedure to X = 42,374 for 42.zip finds a maximum at N = 250. These 250 files require 21,195 bytes of overhead, leaving 21,179 bytes for the kernel. A kernel of this size is unpacked into 21,841,249 bytes (1031.3 to 1 ratio). 250 copies of the unpacked kernel plus a few cited headers of local files gives a total unpacked output of 5,461,307,620 bytes and a compression ratio of 129,000.
- zbsm.zip 42 kB → 5.5 GB
zipbomb --mode = quoted_overlap --num-files = 250 --compressed-size = 21179> zbsm.zip
Optimization has led to an almost even distribution of space between the kernel and the file headers. This is not a coincidence. Consider a simplified model of a citation construction with overlap. In a simplified model, we ignore file names, as well as a slight increase in the size of the output file due to quoting the headers of local files. Analysis of the simplified model will show that the optimal distribution between the kernel and the file headers is approximately uniform, and the output size with the optimal distribution grows quadratically depending on the size of the input.
Definition of some constants and variables:
| X | zip file size (considered fixed) | |
| N | number of files in zip archive (variable for optimization) | |
| Cdh | = 46 | central directory header size (without file name) |
| Lfh | = 30 | local file header size (without file name) |
| Q | = 5 | DEFLATE block uncompressed size |
| C | ≈ 1032 | kernel compression ratio |
Let H (N) be the volume of the overhead for headers for N files. See the chart to understand the essence of the formula.

For the kernel, X - H (N) places remain . The total unpacked size S X (N) is equal to the size of N copies of the kernel unpacked with the ratio C (in this simplified model, we ignore the slight additional extension from the mentioned local file headers).
S X (N) is a polynomial in part N, therefore, the maximum should be where the derivative S ' X (N) is equal to zero. Taking the derivative and finding zero gives us N OPT , the optimal number of files.
H (N OPT ) gives the optimal amount of space for placing file headers. It is independent of CDH, LFH and C and is close to X / 2 .
S X (N OPT ) - total unpacked size at optimal distribution. From this we see that the size of the output increases quadratically with increasing input data.

Increasing the size of the zip file, in the end we will encounter the limits of the zip format: the archive can have no more than 2 16 −1 files with a size of no more than 2 32 −1 bytes each. Worse, some implementations take maximum values as an indicator of the presence of 64-bit extensions , so our limits are actually 2 16 −2 and 2 32 −2. It happens that the first time we encounter a limit on the size of an uncompressed file. With a zip file size of 8 319 377 bytes, naive optimization will give us the number of files 47 837 and a maximum file of 2 32 +311 bytes.
(Actually, it’s a bit more complicated because the exact limits are implementation dependent. Python's zipfile ignoresthe number of files archive / zip in Go allows you to increase the number of files until they match the lower 16 bits. But for general compatibility, we must adhere to the established limits).
If we cannot infinitely increase N or kernel size, we would like to find the maximum compression ratio within the zip format. You need to make the kernel as large as possible with the maximum number of files. Despite the fact that we can no longer maintain approximately uniform separation between the kernel and the file headers, each added file still increases the compression ratio - just not as fast as if we could continue to increase the kernel. In fact, as we add files, we will need to reducekernel size to make room for the maximum file size, which grows slightly with each file added.
The plan leads to a zip archive with 2 16 −2 files and a kernel, which is unpacked into 2 32 −2 178 825 bytes. The files will be larger towards the beginning of the zip archive - the first and largest file is unpacked in 2 32 −56 bytes. This is as close as we can using the rough output parameters of bulk_deflate - encoding the final 54 bytes will cost more than their size (the zip file as a whole has a compression ratio of 28 million, and the final 54 bytes will receive a maximum of 54 ⋅ 10 32 ⋅ ( 2 16- 2) ≈ 36? 5 million bytes, so this only helps if 54 bytes can be encoded into one byte - and I could not code less than two. Therefore, if you cannot encode 54 bytes into 1 byte, this only reduces the compression ratio). The output size of this zip bomb is 281,395,456,244,934 bytes, 99.97% of the theoretical maximum (2 32 - 1) × (2 16 - 1). Any significant improvement in compression ratio can be achieved only by reducing the size of the input signal, and not by increasing the output.
- zblg.zip 10 MB → 281 TB
zipbomb --mode = quoted_overlap --num-files = 65534 --max-uncompressed-size = 4292788525> zblg.zip
Efficient CRC-32 Computing
Among the metadata in the header of the central directory and the header of the local file is a checksum of the uncompressed file data - CRC-32 . This poses a problem because the amount of CRC-32 calculations for each file is proportional to its size, which is very large by default (after all, it's a zip bomb). We would prefer to do work that is at least proportional to the size of the archive. Two factors work in our favor: all files have a common core, and an uncompressed kernel is a string of repeated bytes. Imagine CRC-32 as a matrix product - this will allow us not only to quickly calculate the checksum of the kernel, but also to reuse the calculations between files. The method described in this section is a small extension of the crc32_combine function in zlib, which Mark Adler explainshere .
CRC-32 can be modeled as a state machine, updating a 32-bit state register for each input bit. The basic update operations for bits 0 and 1 are:
uint32 crc32_update_0(uint32 state) {
// Shift out the least significant bit.
bit b = state & 1;
state = state >> 1;
// If the shifted-out bit was 1, XOR with the CRC-32 constant.
if (b == 1)
state = state ^ 0xedb88320;
return state;
}
uint32 crc32_update_1(uint32 state) {
// Do as for a 0 bit, then XOR with the CRC-32 constant.
return crc32_update_0(state) ^ 0xedb88320;
}If you represent the state register as a 32-element binary vector and use XOR for addition and multiplication, then it
crc32_update_0is a linear mapping ; i.e., it can be represented as a multiplication by a binary 32 × 32 transition matrix . To understand why, note that multiplying a matrix by a vector is simply adding up the columns of the matrix after multiplying each column by the corresponding element of the vector. The shift operation state >> 1simply takes each bit i of the state vector and multiplies it by a vector that is equal to zero everywhere except for bit i - 1 (numbering of bits from right to left). Relatively speaking, the final XOR state ^ 0xedb88320occurs only when the bitbequal to one. This can be represented as the first multiplication of b by 0xedb88320, and then XORing to this state. Also,
crc32_update_1it's just a crc32_update_0plus (XOR) constant. This makes crc32_update_1an affine transformation : matrix multiplication followed by mapping (i.e., vector addition). We can imagine matrix multiplication and mapping in one step, if we increase the size of the transformation matrix to 33 × 33 and add an additional element to the state vector, which is always 1 (this representation is called homogeneous coordinates ). Transformation matrices 33 × 33 M 0 and M 1, которые вычисляют изменение состояния CRC-32, выполненное битами 0 и 1, соответственно. Векторы столбцов хранятся с наиболее значащим битом внизу: читая первый столбец снизу вверх, вы видите полиномиальную константу CRC-32 edb8832016 = 111011011011100010000011001000002. Эти две матрицы различаются только в конечном столбце, который представляет вектор трансляции в однородных координатах. В M0 трансляция равна нулю, а в M1 — edb8832016, полиномиальная константа CRC-32. Единицы сразу над диагональю представляют состояние операции
state >> 1Both operations
crc32_update_0and crc32_update_1can be represented by the transition matrix of 33 × 33. Matrices M 0 and M 1 are shown . The advantage of the matrix representation is that matrices can be multiplied. Suppose we want to see a state change made by processing an ASCII character 'a', whose binary representation is 01100001 2 . We can imagine the cumulative change in the state of the CRC-32 of these eight bits in one transformation matrix:
And we can imagine a change in the state of a row repeating 'a' by multiplying many copies of M a - raising the matrix to a power. We can do this quickly using fast exponentiation algorithm , which allows to calculate the M n just log 2 n steps. For example, here is a matrix for changing the state of a string of 9 characters 'a':

The matrix quick multiplication algorithm is useful for computing M kernel , a matrix for an uncompressed kernel, since the kernel is a string of repeated bytes. To get the CRC-32 checksum from the matrix, multiply the matrix by the zero vector (the zero vector is in uniform coordinates, that is 32 zeros, and then the unit; here we omit the slight complication of the pre- and post-processing of the checksum to check for compliance). To calculate the checksum for each file, we work in the opposite direction. We start by initializing M: = M kernel . The kernel checksum is also the checksum of the final file N , so we multiply Ma zero vector and stores the received checksum in the CDH N and LFH N . The data of file N − 1 is the same as the file data of file N , but with the prefix LFH N added . Therefore, we calculate
, state change matrix for LFH N and update. Now M represents the cumulative change in state from processing LFH N behind the nucleus. We calculate the checksum for the file N − 1 , again multiplying M by the zero vector. We continue the procedure by accumulating state change matrices in M until all files are processed.Extension: Zip64
Earlier, we faced the problem of expansion due to limitations of the zip format - it was impossible to issue more than 281 TB, regardless of how smartly the zip file was packaged. You can transcend these limits using Zip64, a zip format extension that increases the size of some header fields to 64 bits. Support for Zip64 is by no means universal, but it is one of the most commonly implemented extensions. As for the compression ratio, the effect of Zip64 is to increase the size of the header of the central directory from 46 to 58 bytes, and the size of the header of the local directory from 30 to 50 bytes. Looking at the optimal expansion coefficient formula in a simplified model, we see that the zip bomb in Zip64 format still grows quadratically, but slower due to the larger denominator - this can be seen in the diagram below. Due to the loss of compatibility and growth retardation, we remove almost any restrictions on file size.
Suppose we need a zip bomb that expands to 4.5 PB, like 42.zip. How big should the archive be? Using binary search, we find that the minimum size of such a file is 46 MB.
- zbxl.zip 46 MB → 4.5 PB (Zip64, less compatible)
zipbomb --mode = quoted_overlap --num-files = 190023 --compressed-size = 22982788 --zip64> zbxl.zip
4.5 petabytes - roughly the same amount of data was recorded by the Event Horizon Telescope for the first image of a black hole : racks and racks with hard drives in the data center.
With Zip64, it’s almost not interesting to consider the maximum compression ratio, because we can simply continue to increase the size of the zip file and the compression ratio with it, until even the compressed zip file becomes prohibitive. An interesting threshold, however, is 2 64 bytes (18 EB or 16 EiB) - so much data will not fit on most file systems. Binary search finds the smallest zip bomb that produces at least as much output: it contains 12 million files and a compressed core of 1.5 GB. The total zip file size is 2.9 GB and it is unpacked in 2 64+11 727 895 877 bytes with a compression ratio of more than 6.2 billion to one. I did not upload this file for download, but you can generate it yourself using the source code . He has files of such a size that even a bug was revealed in Info-ZIP UnZip 6.0.
zipbomb --mode = quoted_overlap --num-files = 12056313 --compressed-size = 1482284040 --zip64> zbxxl.zip
Extension: bzip2
DEFLATE is the most common compression algorithm for the zip format, but this is only one of many options. Probably the second most common algorithm is bzip2 . Although it is not as compatible as DEFLATE. Theoretically, in bzip2, the maximum compression ratio is about 1.4 million to one, which allows a denser packing of the core.
bzip2 first encodes the “run-length encoding”, reducing the string length of repeating bytes by 51 times. Then the data is divided into 900 KB blocks and each block is compressed separately. Theoretically, one block can compress up to 32 bytes. 900 000 × 51/32 = 1 434 375.
Ignoring the loss of compatibility, does bzip2 make a more effective bomb?
Yes - but only for small files. The problem is that in bzip2 there is nothing like the uncompressed DEFLATE blocks that we used to quote the headers of local files. Thus, it is impossible to overlap files and reuse the kernel - for each file you need to write your own copy, so the overall compression ratio will not be better than the ratio for any single file. In the graph below, we see that without overlapping, bzip2 is superior to DEFLATE only for files about megabytes in size.
There is only hope for an alternative means of quoting headers in bzip2, which is discussed in the next section. In addition, if you know that a particular zip parser supports bzip2 andallows for mismatched file names, you can use the complete overlap construct, which does not need to be quoted.
Comparison of the compression ratio of different zip bombs. Pay attention to the logarithmic axis. Each design is shown with and without Zip64. Structures without overlap have a linear growth rate, which can be seen from the constant ratio of the axes. The vertical offset of the bzip2 graph means that the compression ratio of bzip2 is about a thousand times greater than that of DEFLATE. The DEFLATE constructs cited have a quadratic growth rate, as evidenced by an inclination to the 2: 1 axes. The Zip64 variant is slightly less effective, but allows for more than 281 TB. Graphs for bzip2 with quoting through an additional field go from quadratic to linear when either the maximum file size is reached (2 32−2 bytes), or the maximum allowed number of files
Extension: quoting through an additional field
So far, we have used the DEFLATE function to quote the headers of local files, and we just saw that this trick does not work in bzip2. However, there is an alternative citation method, somewhat more limited, that uses only zip format functions and is independent of the compression algorithm.
At the end of the header structure of the local file, there is an additional field of variable length for storing information that does not fit into the usual header fields ( APPNOTE.TXT, section 4.3.7) Additional information may include, for example, a timestamp or uid / gid from Unix. Zip64 information is also stored in an additional field. An additional field is represented as a length-value structure; if you increase the length without adding a value, the additional field will include what is behind it in the zip file, namely the next header of the local file. Using this method, each header of the local file can “quote” the following headers, enclosing them in its own additional field. Compared to DEFLATE, there are three advantages:
- Quoting through an extra field requires only 4 bytes, not 5, leaving more space for the kernel.
- It does not increase file size, which means a larger kernel, given the limitations of the zip format.
- It provides quoting in bzip2.
Despite these advantages, quoting through additional fields is less flexible. This is not a chain, as in DEFLATE: each heading of a local file should contain not only the immediately following heading, but also all subsequent headings. Additional fields increase as you approach the beginning of the zip file. Since the maximum field length is 2 16 −1 bytes, only up to 1808 local file headers (or 1170 in Zip64) can be quoted, assuming the names are assigned as expected(in the case of DEFLATE, you can use an additional field to quote the first (shortest) headers of local files, and then switch to quoting DEFLATE for the rest). Another problem: in order to correspond to the internal data structure of the additional field, it is necessary to select a 16-bit tag for the type ( APPNOTE.TXT, section 4.5.2 ) preceding the citation data. We want to select a type tag that will cause parsers to ignore the data in quotation marks, rather than try to interpret them as meaningful metadata. Zip parsers should ignore tags of an unknown type, so we can select tags at random, but there is a risk that in the future some tag will violate the compatibility of the design.
The previous diagram illustrates the possibility of using additional fields in bzip2, c and without Zip64. On both graphs there is a turning point, when the growth goes from quadratic to linear. Without Zip64, this happens where the maximum size of the uncompressed file is reached (2 32−2 bytes); then you can only increase the number of files, but not their size. The graph completely ends when the number of files reaches 1809, then we run out of space in an additional field for quoting additional headers. With Zip64, a fracture occurs on 1171 files, after which only the file size can be increased, but not their number. An additional field helps in the case of DEFLATE, but the difference is so small that it is not visually noticeable. It increases the compression ratio of zbsm.zip by 1.2%; zblg.zip by 0.019%; and zbxl.zip by 0.0025%.
Discussion
In their work on this subject, Pletz and colleagues use file overlap to create an almost self-replicating zip archive. The file overlap itself was suggested earlier (slide 47) by Ginvael Coldwind.
We developed a design of a zip bomb with a quotation overlap taking into account compatibility - a number of differences in implementations, some of which are shown in the table below. The resulting design is compatible with zip parsers that work in the usual way, that is, first checking the central directory and using it as an index of files. Among them, a unique zip parser from Nailwhich is automatically generated from formal grammar. However, the design is incompatible with "streaming" parsers, which analyze the zip file from start to finish in one pass without first reading the central directory. By their nature, streaming parsers do not allow files to overlap in any way. Most likely, they will only extract the first file. In addition, they may even throw an error, as is the case with sunzip , which parses the central directory at the end and checks for consistency with the headers of the local files that it has already seen.
If you want the extracted files to start with a specific prefix that is different from the header bytes of the local file, you can insert a DEFLATE block before the uncompressed block that the following header quotes. Not every file in the zip archive should participate in the creation of the bomb: you can include ordinary files in the archive, if necessary, in order to correspond to some special format (there is a parameter in the source code
--templatefor this use case). Many formats use zip as a container, such as Java JAR documents, Android APK, and LibreOffice. Pdfin many ways similar to zip. It has a cross-reference table at the end of the file that points to previous objects, and it supports compression of objects through the FlateDecode filter. I have not tried, but you can use the idea of quoting with overlap to make a PDF bomb. Perhaps you don’t even have to work hard here: binaryhax0r writes in a blog post that you can simply specify several FlateDecode layers on one object, after which creating a PDF bomb becomes trivial.
Defining a particular class of zip bombs described in this article is easy: just find the overlapping files. Mark Adler wrote a patchfor Unzip Info-ZIP, which does just that. However, in general, blocking overlapping files does not protect against all classes of zip bombs. It is difficult to predict in advance whether the file is a zip bomb or not if you do not have accurate knowledge about the internal components of the parsers that will be used to analyze it. Looking at the headers and summing the “uncompressed size” fields of all files does not work , because the value in the headers may not match the actual uncompressed size (in the compatibility table, see the line “allows the file is too small”). Reliable protection against zip bombs includes limits on time, memory and disk space in the zip parser during its operation. Take parsing of zip files, like any complex operations with untrusted data, with caution.
| Info-zip UnZip 6.0 | Python 3.7 zipfile | Go 1.12 archive/zip | yauzl 2.10.0 (Node.js) | Nail examples/zip | Android 9.0.0 r1 libziparchive | sunzip 0.4 (streaming) | |
|---|---|---|---|---|---|---|---|
| DEFLATE | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Zip64 | ✓ | ✓ | ✓ | ✓ | − | − | ✓ |
| bzip2 | ✓ | ✓ | − | − | − | − | ✓ |
| разрешает несовпадение имён файлов | предупреждает | − | ✓ | ✓ | ✓ | − | ✓ |
| разрешает неправильный CRC-32 | предупреждает | − | если нулевое | ✓ | − | ✓ | − |
| разрешает слишком малый размер файла | ✓ | − | − | − | − | − | − |
| разрешает 232−1 файлов | ✓ | ✓ | ✓ | − | ✓ | ✓ | ✓ |
| разрешает 216−1 файлов | ✓ | ✓ | ✓ | − | ✓ | ✓ | ✓ |
| разархивирует overlap.zip | предупреждает | − | ✓ | ✓ | ✓ | − | − |
| разархивирует zbsm.zip и zblg.zip | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | − |
| разархивирует zbxl.zip | ✓ | ✓ | ✓ | ✓ | − | − | − |
Таблица с перечислением некоторых zip-парсеров, а также различных функций, пограничных ситуаций и конструкций zip-бомб. Для лучшей совместимости используйте сжатие DEFLATE без Zip64, сопоставляйте имена в заголовках центрального каталога и заголовках локальных файлов, вычисляйте правильные значения CRC и избегайте максимальных значений 32-битных и 16-битных полей.
Благодарности
Thanks to Mark Adler , Russ Cox , Brandon Enright , Marek Maykovsky , Josh Wolfe and the reviewers of USENIX WOOT 2019 for comments on the draft of this article. Kaolan McNamara assessed the impact of zip bombs on LibreOffice's security.
A version of this article has been prepared for the USENIX WOOT 2019 Workshop . Source code is available. Artifacts for presentation at the workshop are in the zipbomb-woot19.zip file .
Did you find a system that drops one of the bombs? Did bombs help you find a bug or make money in a bug search program? Let me know, I will try to mention it here.
LibreOffice 6.1.5.2
After renaming zblg.zip to zblg.odt or zblg.docx, LibreOffice creates and deletes a series of temporary files of approximately 4 GB, trying to determine the file format. Ultimately, he finishes doing this and deletes the temporary files as they arrive, so the zip bomb only causes a temporary DoS without filling up the disk. Kaolan McNamara answered my error message.
Mozilla addons-server 2019.06.06
I tried zip bombs against the local addons-server installation, which is part of the addons.mozilla.org software. The system gracefully handles the bomb, imposing a time limit of 110 seconds on the extraction of files. The zip bomb expands quickly, as far as the disk allows up to this time limit, but then the process is killed and the unpacked files are ultimately automatically cleared.
UnZip 6.0
Mark Adler wrote a patch for UnZip to detect this class of zip bombs.
July 5, 2019: I noticed that CVE-2019-13232 was assigned to UnZip. Personally, I would argue that the ability / inability of UnZip (or any zip parser) to process this kind of zip bomb is necessarily a vulnerability or even a bug. This is a natural implementation that does not violate the specification, what can I say. The bomb type in this article is just one type, and there are many other ways you can puzzle a zip parser. As mentioned above, if you want to protect yourself from resource exhaustion attacks, you should not try to list, detect, and block every single known attack; rather, it is necessary to establish external restrictions on time and other resources so that the parser does not get into such a situation, regardless of what kind of attack it encountered. There is nothing wrong with trying to detect and reject certain designs as an optimization of the first pass, but you can not stop there. Unless you end up isolating and restricting operations with untrusted data, your system is probably still vulnerable. Consider the analogy with cross-site scripting in HTML: the right protection is not to try to filter out specific bytes that can be interpreted as code, but to avoid everything correctly.
Antivirus engines
Twitter user @TVqQAAMAAAAEAAA reports : "McAfee antivirus on my test machine just exploded." I have not tested it myself and I do not have such details as the version number.
Tavis Ormandi indicates that VirusTotal has a number of timeouts for zblg.zip ( screenshot from June 6, 2019 ): AhnLab-V3, ClamAV, DrWeb, Endgame, F-Secure, GData, K7AntiVirus, K7GW, MaxSecure, McAfee, McAfee-GW -Edition, Panda, Qihoo-360, Sophos ML, VBA32. Results for zbsm.zip ( screenshot from June 6, 2019) are similar, but with a different set of timeout engines: Baido, Bkav, ClamAV, CMC, DrWeb, Endgame, ESET-NOD32, F-Secure, GData, Kingsoft, McAfee-GW-Edition, NANO-Antivirus, Acronis. Interestingly, there are no timeouts in the results of zbxl.zip ( screenshot from June 6, 2019 ). Perhaps some antiviruses do not support Zip64? Several engines detect files as a kind of “compression bomb”. It is interesting to see if they will continue to do so with minor changes, such as changing file names or adding an ASCII prefix to each file.
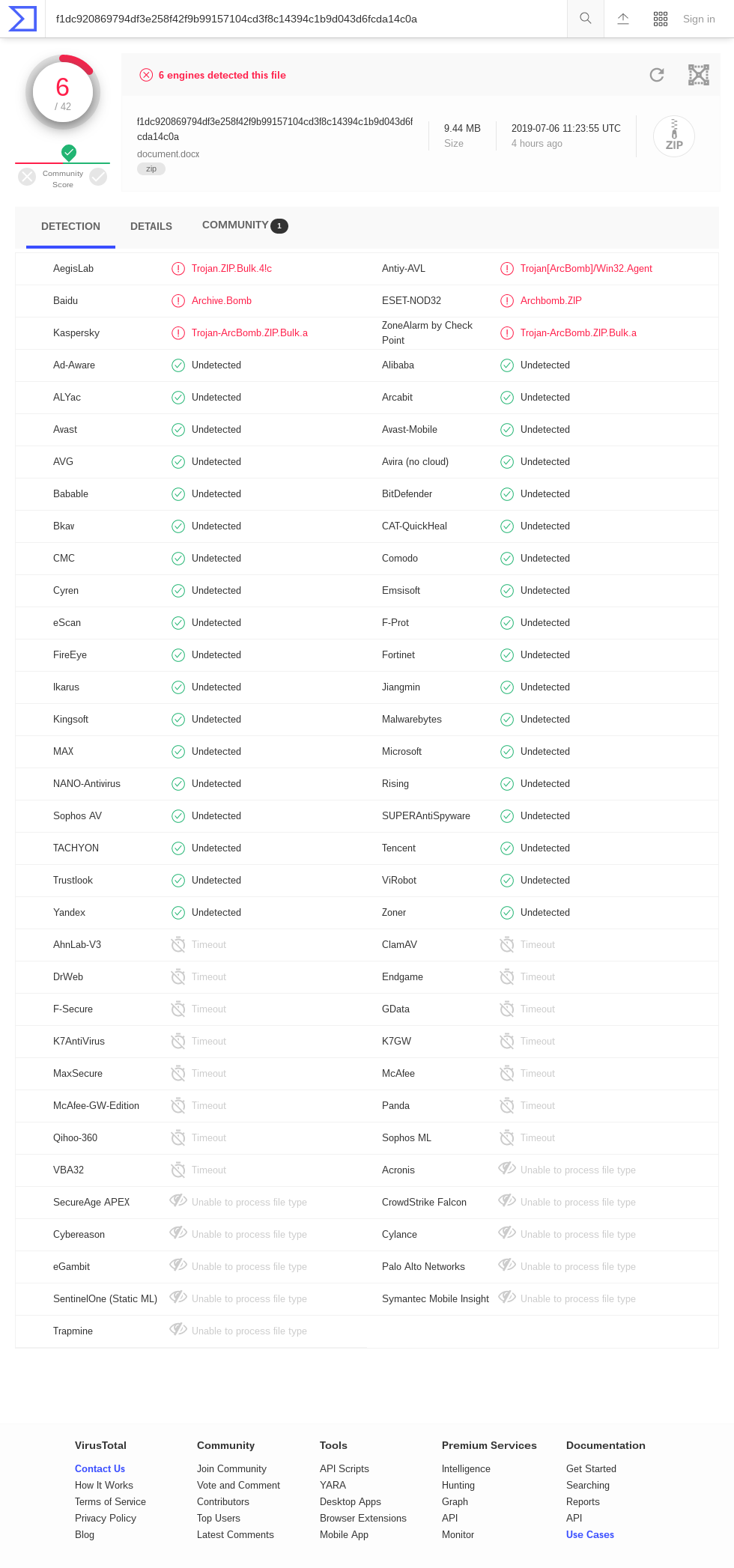{kind=link}
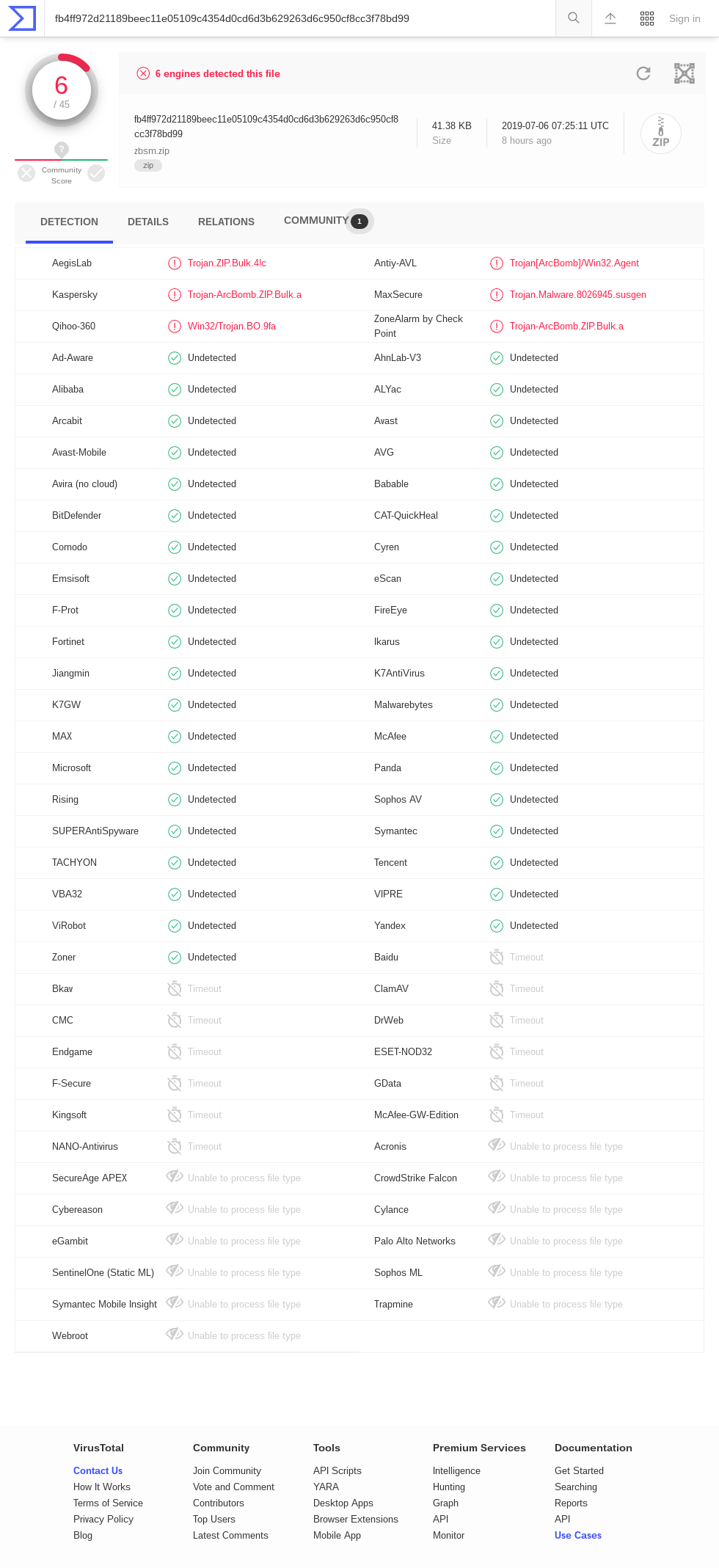{kind=link}
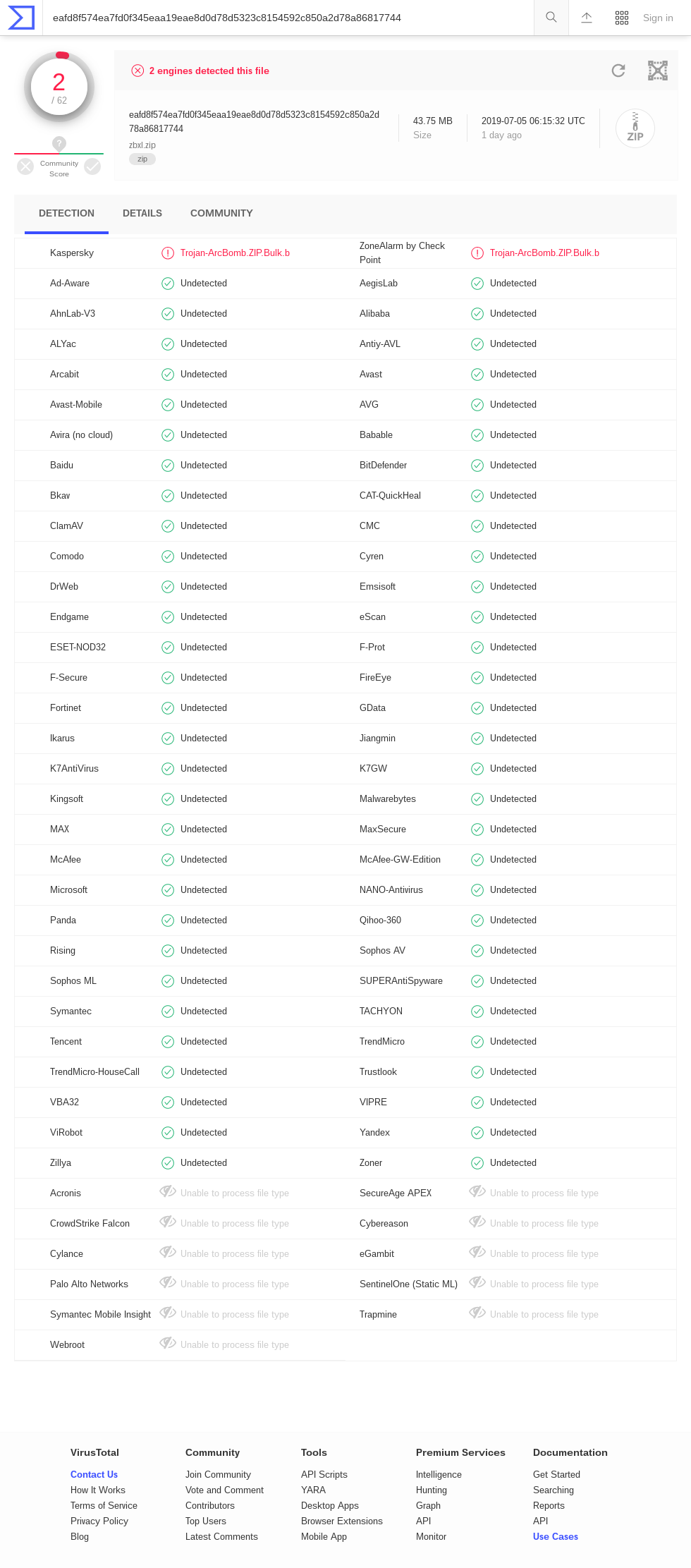{kind=link}
Final statement
It's time to put an end to Facebook. This is not a neutral job for you: every day when you come to work, you are doing something wrong. If you have a Facebook account, delete it. If you work on Facebook, get laid off.
And do not forget that the National Security Agency must be destroyed.