Transition from monolith to microservices: history and practice
In this article I will talk about how the project in which I work turned from a large monolith into a set of microservices.
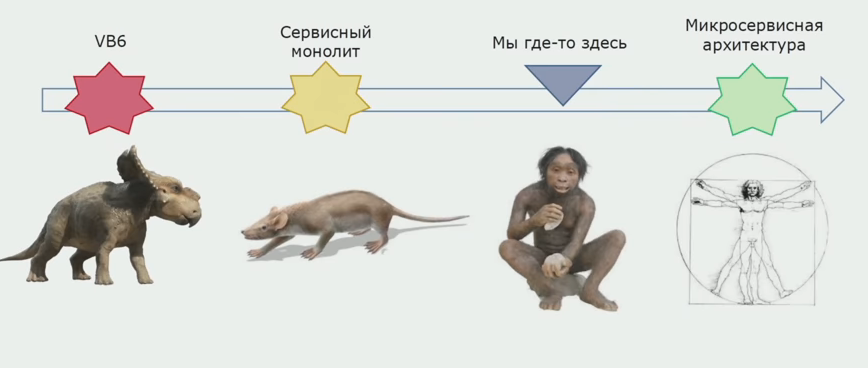
The project began its history a long time ago, in early 2000. The first versions were written in Visual Basic 6. Over time, it became clear that development in this language in the future would be difficult to support, since the IDE and the language itself are poorly developed. In the late 2000s, it was decided to switch to a more promising C #. The new version was written in parallel with the refinement of the old one, gradually more and more code was on .NET. Backend in C # initially focused on the service architecture, however, during development, shared libraries with logic were used, and services were launched in a single process. It turned out the application, which we called the "service monolith".
One of the few advantages of this bundle was the ability of services to call each other through an external API. There were clear prerequisites for the transition to a more correct service, and in the future, microservice architecture.
We started our decomposition work around 2015. We have not yet reached an ideal state - there are parts of a large project that are difficult to call monoliths, but they do not look like microservices either. However, the progress is substantial.
I’ll talk about him in the article.
Initially, the architecture looked as follows: UI is a separate application, the monolithic part is written in Visual Basic 6, the application in .NET was a set of related services that works with a fairly large database.
Disadvantages of the previous solution.
Single point of failure
. We had a single point of failure: the .NET application started in one process. If any of the modules crashed, the entire application failed and had to be restarted. Since we are automating a large number of processes for different users, due to a failure in one of them, some could not work for some time. And with a software error, redundancy did not help either.
The lineup of improvements
This flaw is rather organizational. Our application has many customers, and they all want to finalize it as soon as possible. Previously, it was impossible to do this in parallel, and all customers stood in line. This process caused a negative effect on the business, because they needed to prove that their task was valuable. And the development team was taking the time to organize this lineup. This took a lot of time and effort, and the product as a result could not change as quickly as it would have been from him.
Optimal use of resources
When placing services in a single process, we always completely copied the configuration from server to server. We wanted to place the most loaded services separately so as not to waste resources and get more flexible management of our deployment scheme.
It is difficult to introduce modern technologies.
A problem familiar to all developers: there is a desire to introduce modern technologies into the project, but there is no possibility. With a large monolithic solution, any update of the current library, not to mention the transition to a new one, turns into a rather non-trivial task. It takes a long time to prove the team leader that this will bring more bonuses than spent nerves.
Difficulty issuing changes
This was the most serious problem - we issued releases every two months.
Each release turned into a real disaster for the bank, despite testing and the efforts of developers. The business understood that part of the functionality would not work for him at the beginning of the week. And the developers understood that they were waiting for a week of serious incidents.
Everyone had a desire to change the situation.
Delivery of components upon availability. Delivery of components as they become available due to decomposition of the solution and separation of various processes.
Small food teams. This is important because it was difficult to manage a large team working on an old monolith. Such a team was forced to work according to a strict process, but I wanted more creativity and independence. Only small teams could afford it.
Isolation of services in separate processes. Ideally, I wanted to isolate in containers, but a large number of services written in the .NET Framework run only under Windows. Services are now appearing on .NET Core, but so far they are few.
Deployment Flexibility.I would like to combine services as we need, and not as the code forces.
Use of new technologies. This is interesting to any programmer.
Of course, if it were simple to break a monolith into microservices, you would not have to talk about it at conferences and write articles. In this process, there are many pitfalls, I will describe the main ones that interfered with us.
The first problem is typical of most monoliths: the coherence of business logic. When we write a monolith, we want to reuse our classes so as not to write extra code. And when switching to microservices, this becomes a problem: all the code is quite tightly connected, and it is difficult to separate services.
At the time of the beginning of work, the repository had more than 500 projects and more than 700 thousand lines of code. This is a fairly large solution and the second problem . It was not possible to simply take and divide it into microservices.
Third problem- lack of necessary infrastructure. In fact, we were involved in manually copying the source code to the servers.
Isolation of microservices
First, we immediately determined for ourselves that the separation of microservices is an iterative process. We have always been required to conduct business task development in parallel. How we will carry out this technically is already our problem. Therefore, we were preparing for the iterative process. It will not work differently if you have a large application, and it is not ready to be rewritten from the very beginning.
What methods do we use to isolate microservices?
The first way is to port existing modules as services. In this regard, we were lucky: there were already formalized services that worked on the WCF protocol. They were distributed in separate assemblies. We moved them separately, adding a small launcher to each assembly. It was written using the wonderful Topshelf library, which allows you to run the application both as a service and as a console. This is convenient for debugging, since no additional projects are required in the solution.
Services were connected according to business logic, since they used common assemblies and worked with a common database. It was difficult to call them microservices in their pure form. Nevertheless, we could issue these services separately, in different processes. This already allowed us to reduce their influence on each other, reducing the problem with parallel development and a single point of failure.
Building with a host is just one line of code in the Program class. We hid Topshelf in a helper class.
The second way to isolate microservices: create them to solve new problems. If the monolith does not grow at the same time, this is already excellent, which means that we are moving in the right direction. To solve new problems, we tried to do separate services. If there was such an opportunity, then we created more “canonical” services that completely control their data model, a separate database.
We, like many, started with authentication and authorization services. They are perfect for this. They are independent, as a rule, they have a separate data model. They themselves do not interact with the monolith, only he turns to them to solve some problems. On these services, you can begin the transition to a new architecture, debug the infrastructure on them, try some approaches related to network libraries, etc. In our organization, there are no teams that could not make an authentication service.
The third way to isolate the microservices that we use is a little specific to us. This is pulling business logic out of the UI layer. We have the main desktop UI application, it, like the backend, is written in C #. Developers periodically made mistakes and brought out on the UI parts of the logic that were supposed to exist in the backend and be reused.
If you look at a real example from the code of the UI part, you can see that most of this solution contains real business logic, which is useful in other processes, not only for building a UI form.
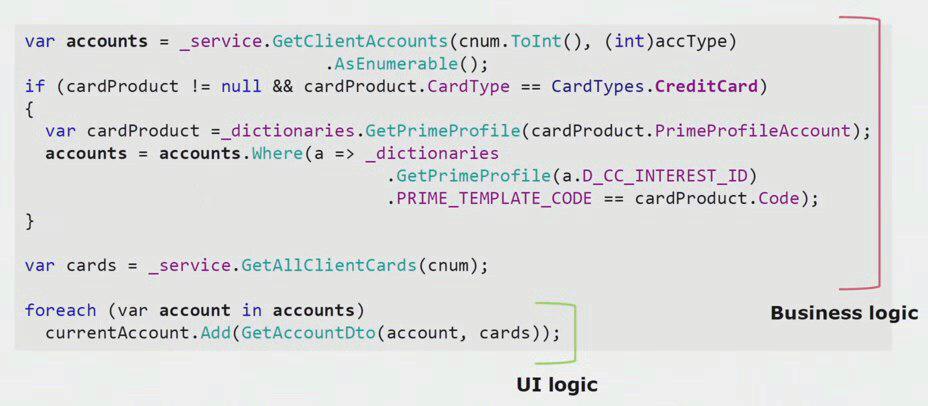
The real UI logic there is only the last couple of lines. We transferred it to the server so that we could reuse it, thereby reducing the UI and achieving the correct architecture.
The fourth, most important way to isolate microservices , which allows you to reduce the monolith, is the removal of existing services with processing. When we take out existing modules as is, the result is not always pleasant for developers, and the business process from the time the functionality was created could become outdated. Thanks to refactoring, we can support a new business process because business requirements are constantly changing. We can improve the source code, remove known defects, create a better data model. There are many benefits.
The processing services division is inextricably linked to the concept of a limited context. This is a concept from subject-oriented design. It means a domain model section in which all terms of a single language are uniquely defined. Consider the context of insurance and bills as an example. We have a monolithic application, and it is necessary to work with the insurance in the insurance account. We expect the developer to find the existing “Account” class in another assembly, make a link to it from the “Insurance” class, and we will get a working code. The DRY principle will be respected, the task through the use of existing code will be done faster.
As a result, it turns out that the contexts of accounts and insurance are connected. When new requirements arise, this connection will interfere with development, increasing the complexity of an already complex business logic. To solve this problem, you need to find the boundaries between the contexts in the code and remove their violations. For example, in the context of insurance, it is quite possible that the 20-digit account number of the Central Bank and the date of opening the account will be sufficient.
In order to separate these limited contexts from each other and begin the process of isolating microservices from a monolithic solution, we used an approach such as creating external APIs inside the application. If we knew that some module should become a microservice, somehow change within the process, then we immediately made calls to the logic, which belongs to another limited context, through external calls. For example, through REST or WCF.
We decided for ourselves that we would not avoid code that would require distributed transactions. In our case, it turned out to be quite easy to comply with this rule. We still haven’t encountered such situations when hard distributed transactions are really needed - the final consistency between the modules is enough.
Consider a specific example. We have the concept of an orchestra - conveyor, which processes the essence of the "application". He takes turns creating a customer, account and bank card. If the client and the account were created successfully, and the creation of the card failed, the application does not go into the status “successfully” and remains in the status “card not created”. In the future, background activity will pick it up and finish it. The system is in a state of inconsistency for some time, but this, on the whole, suits us.
If, nevertheless, a situation arises when it will be necessary to consistently save part of the data, we will most likely go to enlarge the service in order to process this in one process.
Consider an example of microservice allocation. How can it be relatively safely brought to production? In this example, we have a separate part of the system - the salary service module, one of the sections of the code of which we would like to make microservice.
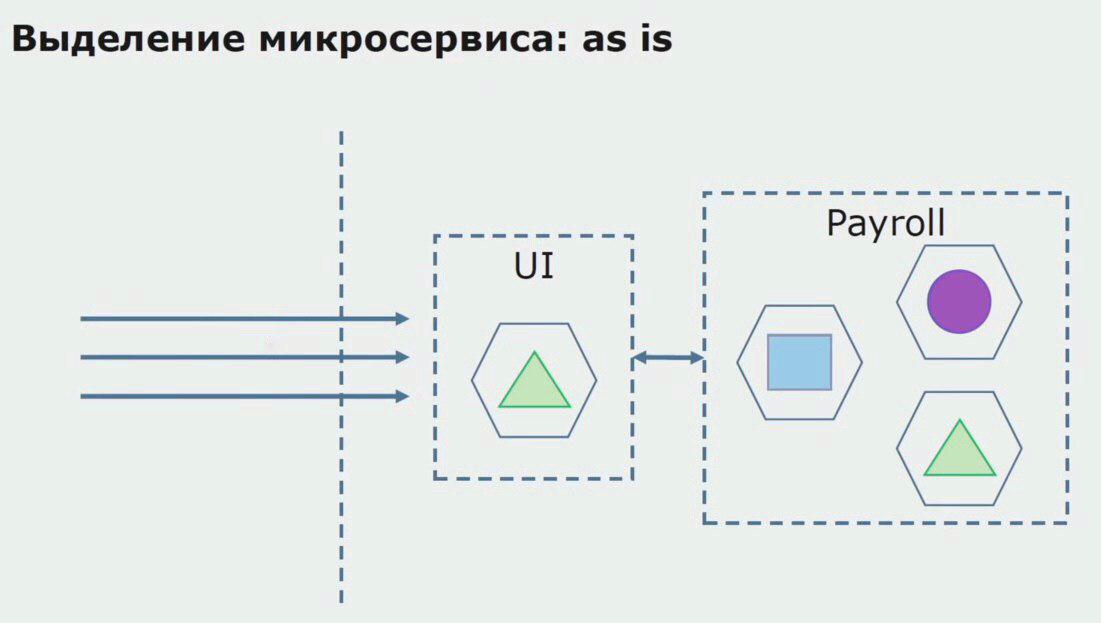
First of all, we create a microservice by rewriting the code. We improve some points that did not suit us. We realize new business requirements from the customer. Add to the bundle between the UI and the API Gateway backend, which will provide call forwarding.
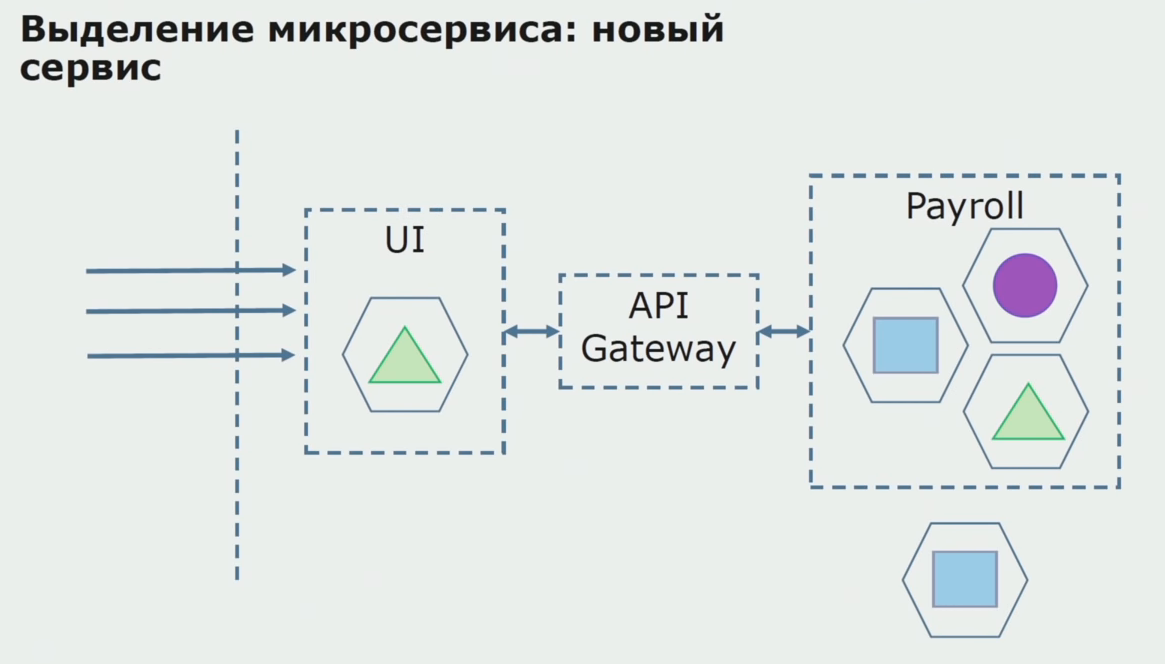
Next, we release this configuration into operation, but in the state of the pilot. Most of our users still work with old business processes. For new users, we are developing a new version of a monolithic application that this process no longer contains. In fact, we have a bunch of monolith and microservice working in the form of a pilot.
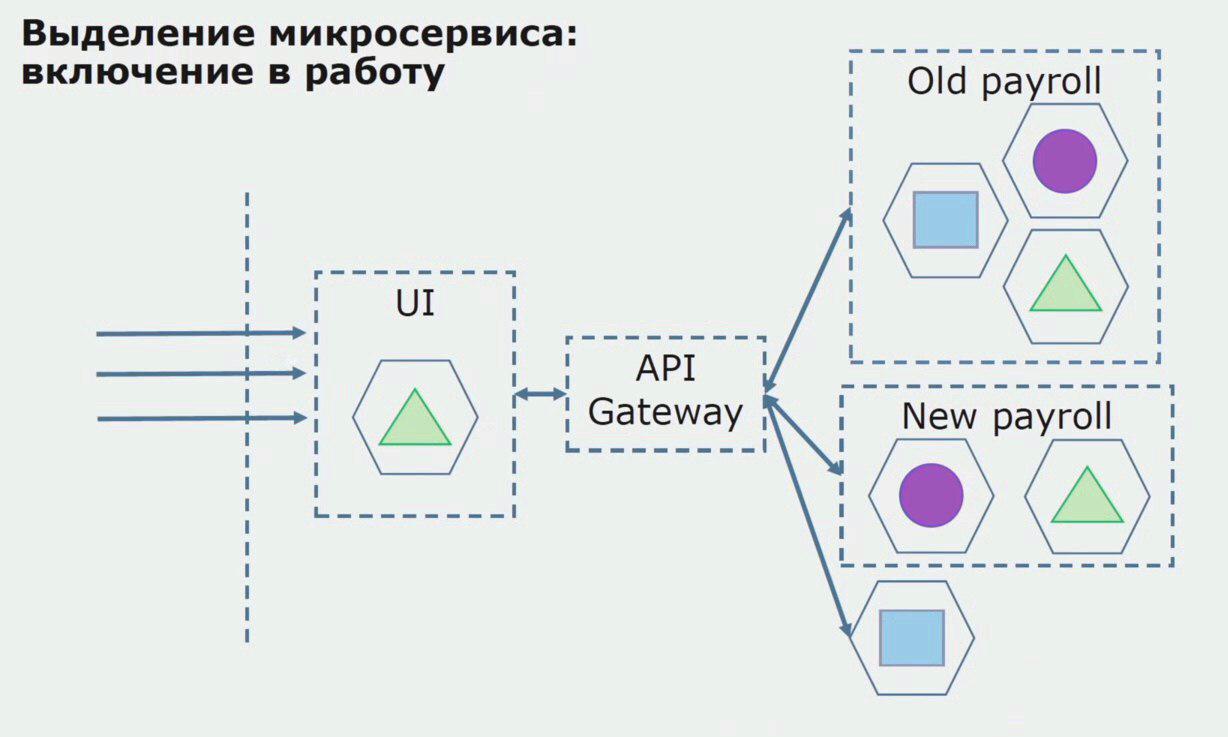
With a successful pilot, we understand that the new configuration is really operational, we can remove the old monolith from the equation and leave the new configuration in the place of the old solution.
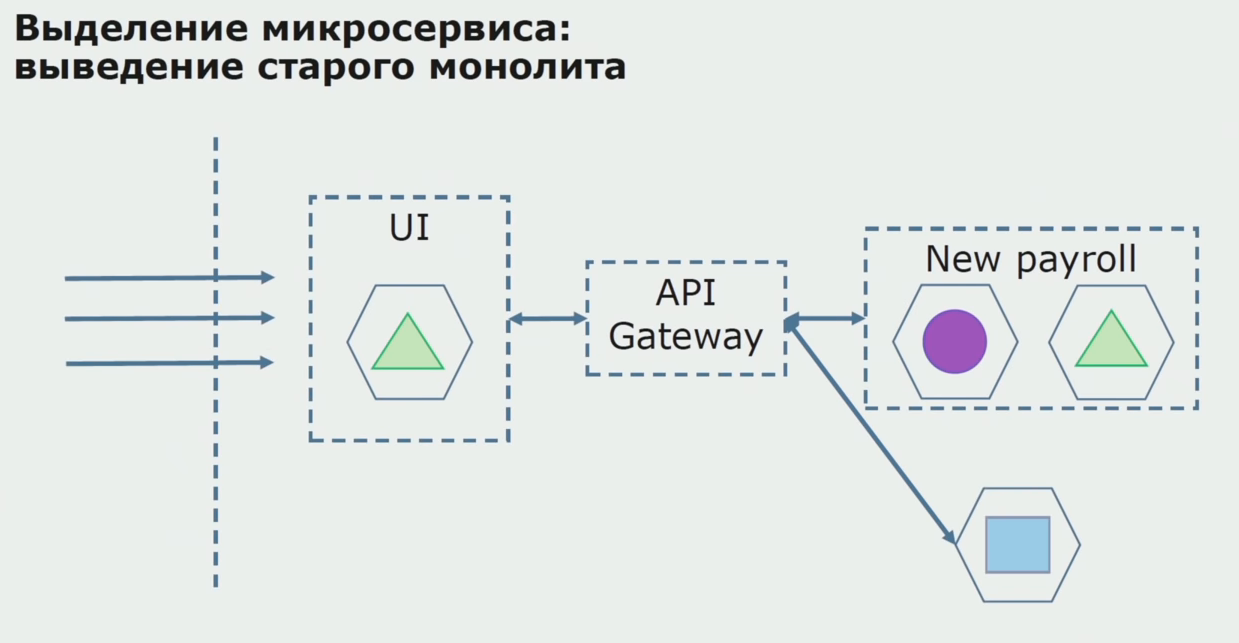
In total, we use almost all existing methods for separating the source code of a monolith. All of them allow us to reduce the size of parts of the application and transfer them to new libraries, making better source code.
The database can be divided worse than the source code, since it contains not only the current schema, but also the accumulated historical data.
Our database, like many others, had another important drawback - its huge size. This database was designed in accordance with the intricate business logic of the monolith, and links have accumulated between the tables of various limited contexts.
In our case, to complete all the troubles (a large database, many relationships, sometimes incomprehensible borders between tables), a problem arose in many large projects: using the shared database template. Data was taken from tables through view, through replication, and shipped to other systems where this replication is needed. As a result, we could not take out the tables in a separate scheme, because they were actively used.
The separation helps us to break up into limited contexts in the code. It usually gives us a pretty good idea of how we break up data at the database level. We understand which tables relate to one limited context and which relate to another.
We applied two global ways to split the database: splitting existing tables and splitting.
Separation of existing tables is a method that is good to use if the data structure is of high quality, satisfies business requirements and suits everyone. In this case, we can select existing tables in a separate schema.
A processing department is needed when the business model has changed a lot and the tables no longer completely satisfy us.
Branch existing tables. We need to determine what we will separate. Without this knowledge, nothing will come of it, and here the separation of limited contexts in the code will help us. As a rule, if you can understand the boundaries of the contexts in the source code, it becomes clear which tables should be included in the list for separation.
Imagine that we have a solution in which two monolith modules interact with one database. We need to make sure that only one module interacts with the part of the separated tables, and the other starts interacting with it through the API. For starters, it’s enough that only an entry is made through the API. This is a necessary condition so that we can talk about the independence of microservices. Reading links can remain until there is a big problem.

As the next step, we can already select a code section that works with detachable tables with or without processing into a separate microservice and run it in a separate process, container. This will be a separate service with communication with the monolith database and those tables that are not directly related to it. The monolith still interacts with the detachable part for reading.

Later we will remove this connection, that is, reading the data of the monolithic application from the separated tables will also be transferred to the API.
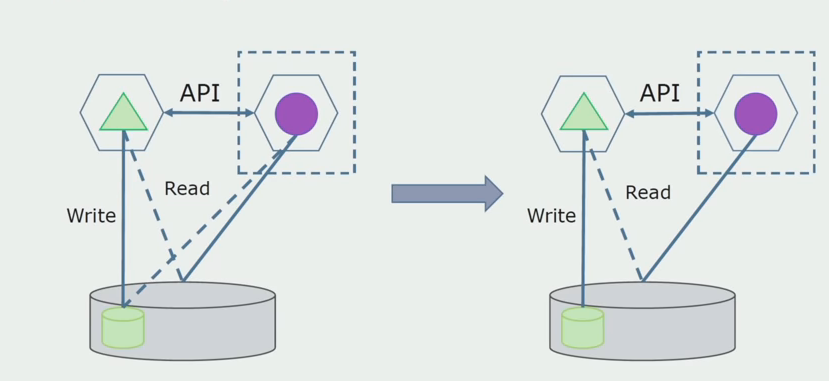
Next, we select from the general database the tables with which only the new microservice works. We can move tables to a separate schema or even to a separate physical database. There was a reading connection between the microservice and the monolith database, but there is nothing to worry about, in this configuration it can live for a long time.
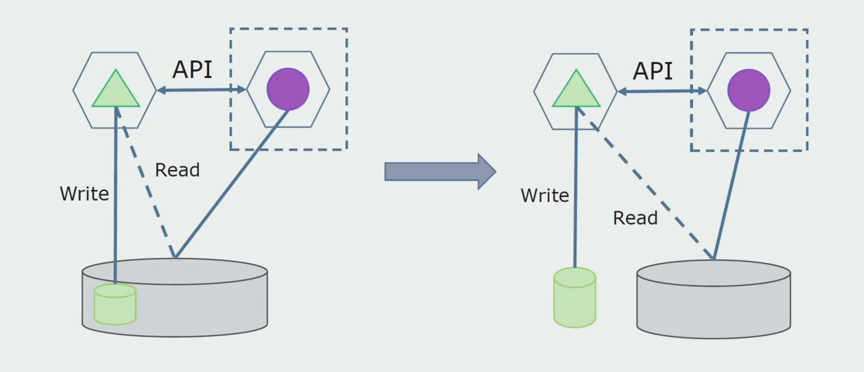
The last step is to completely remove all connections. In this case, we may need data migration from the main database. Sometimes we want to reuse some data or directories that are replicated from external systems in several databases. We occasionally meet this.
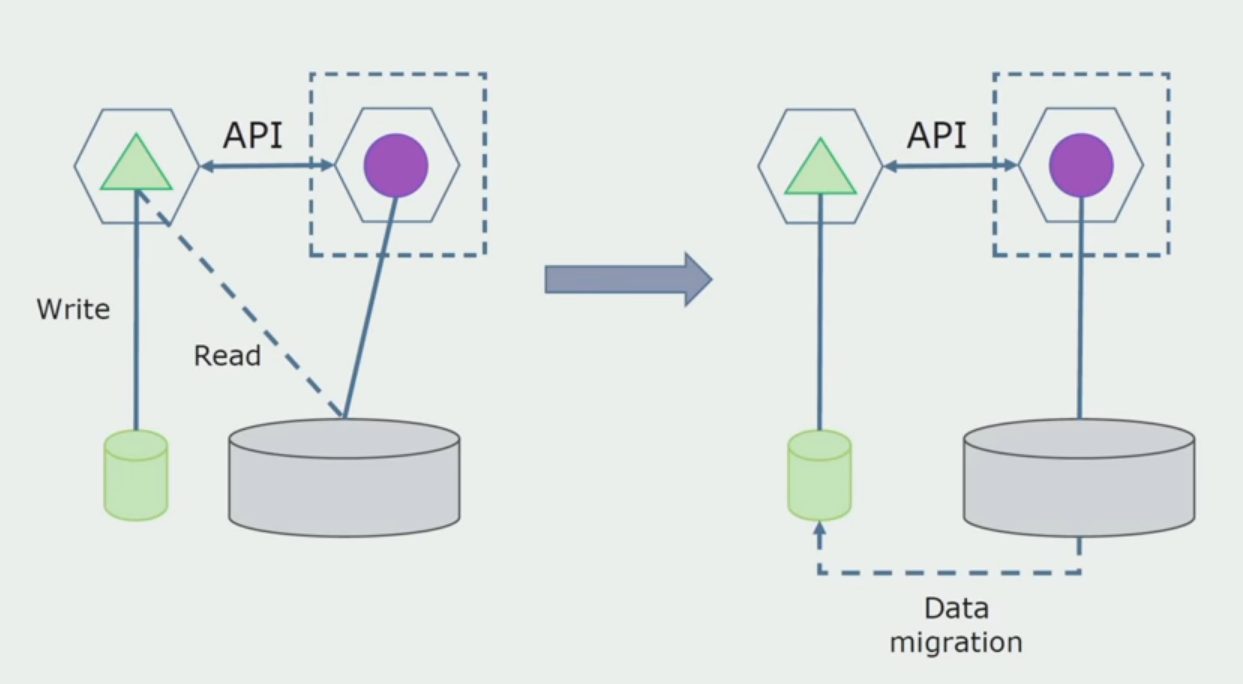
Processing department. This method is very similar to the first, only goes in the reverse order. We immediately have a new database and a new microservice that interacts with the monolith through the API. But at the same time, there remains a set of database tables that we want to delete in the future. We will no longer need it, in the new model we replaced it.
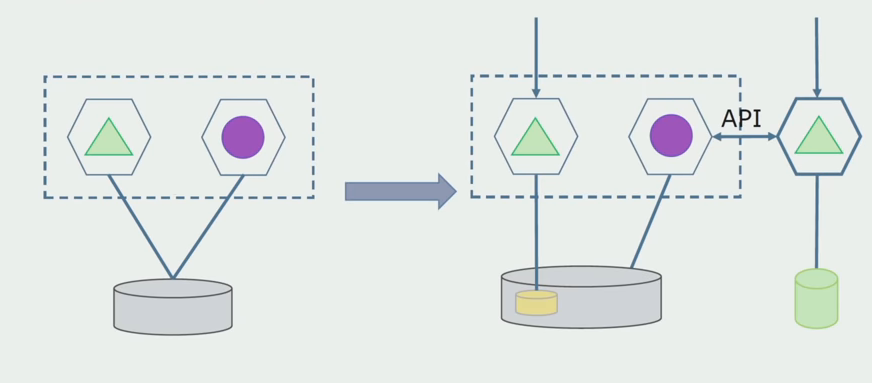
For this scheme to work, we most likely will need a transition period.
There are two possible approaches.
First : we duplicate all the data in the new and old databases. In this case, we have data redundancy, there may be problems with synchronization. But then we can take two different customers. One will work with the new version, the other with the old.
Second: share data for some business attribute. For example, in our system there were 5 products that are stored in the old database. The sixth as part of a new business task, we put in a new database. But we need the Gateway API, which synchronizes this data and shows the client where and what to take.
Both approaches are working, choose according to the situation.
After we make sure that everything works, the part of the monolith that works with the old database structures can be disabled.
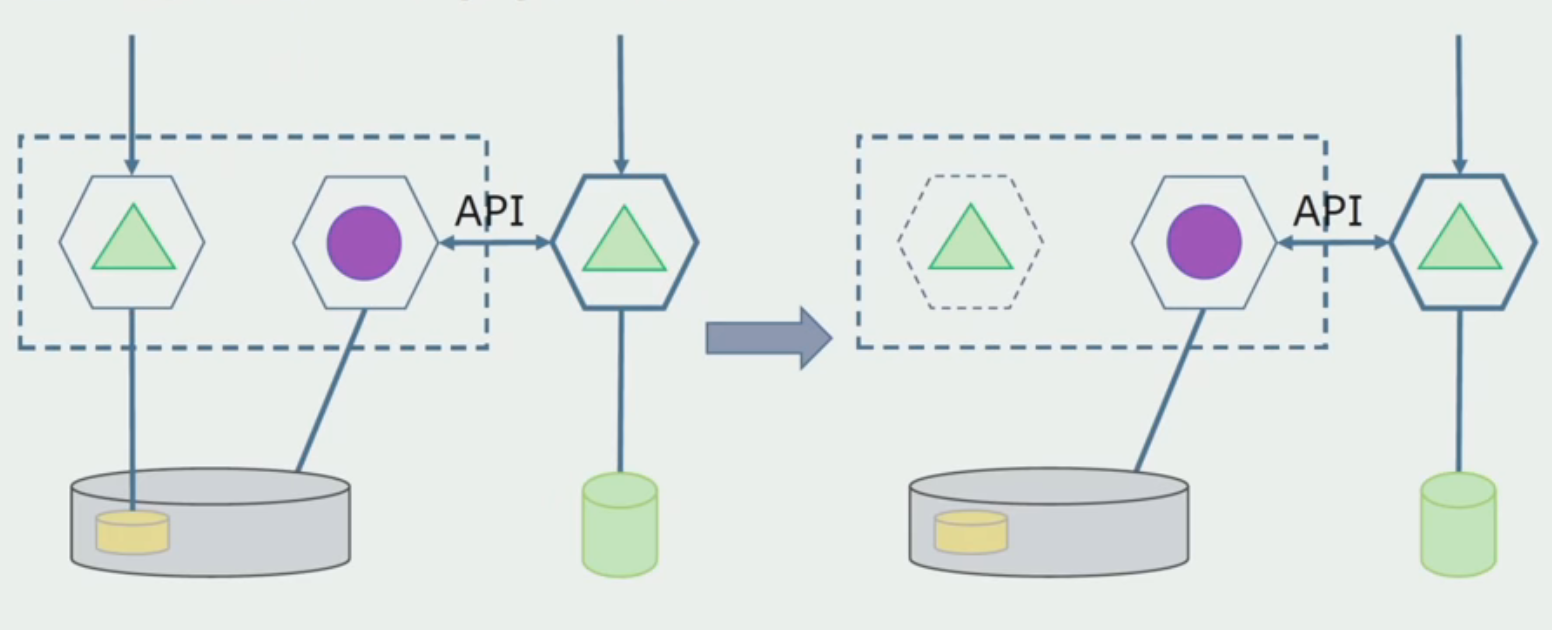
The final step is to remove the old data structures.

Summing up, we can say that we have problems with the database: it is difficult to work with it compared to the source code, it is more difficult to separate, but this can and should be done. We found some ways that allow this to be done quite safely, yet it is easier to make a mistake with the data than with the source code.
This is what the source code diagram looked like when we started analyzing a monolithic project.

It can conditionally be divided into three layers. This is a layer of launched modules, plugins, services and individual activities. In fact, these were the entry points within the monolithic solution. All of them were tightly bonded with a Common layer. It had business logic that was shared between services, and many connections. Each service and plugin used up to 10 or more common assemblies, depending on their size and the conscience of the developers.
We were lucky, we had infrastructure libraries that could be used separately.
Sometimes a situation arose when some of the Common objects did not actually belong to this layer, but were infrastructure libraries. This was decided by renaming.
Most worrying were limited contexts. It happened that 3-4 contexts were mixed in one assembly of Common and used each other within the framework of the same business functions. It was necessary to understand where this can be divided and at what boundaries, and what to do next with mapping of this separation into source code assemblies.
We have formulated several rules for the code separation process.
First: We no longer wanted to share business logic between services, activities, and plugins. They wanted to make business logic independent within the framework of microservices. On the other hand, microservices, in the ideal case, are perceived as services that exist completely independently. I believe that this approach is somewhat wasteful, and it is difficult to achieve it, because, for example, services in C # will in any case be connected by a standard library. Our system is written in C #, other technologies have not yet been used. Therefore, we decided that we can afford to use common technical assemblies. The main thing is that they do not have any fragments of business logic. If you have a convenient wrapper over the ORM that you use, then copying it from service to service is very expensive.
Our team is a fan of subject-oriented design, so the “onion architecture” is perfect for us. The basis of our services was not a data access layer, but an assembly with domain logic, which contains only business logic and is devoid of infrastructure connections. At the same time, we can independently modify the domain assembly to solve the problems associated with the frameworks.
At this stage, we met the first serious problem. The service was supposed to refer to one domain assembly, we wanted to make the logic independent, and here the DRY principle strongly interfered with us. To avoid duplication, the developers wanted to reuse classes from neighboring assemblies, and as a result, the domains began to communicate with each other again. We analyzed the results and decided that perhaps the problem lies also in the area of the source code storage device. We had a large repository in which all the source codes lay. Solution for the whole project was very difficult to assemble on a local machine. Therefore, separate small solutions were created for the parts of the project, and no one forbade adding any Comm- or domain assembly to them and reusing them. The only tool that did not allow us to do this was the review code.
Then we began to switch to a model with separate repositories. Business logic has ceased to flow from service to service, domains have truly become independent. Limited contexts are supported more clearly. How do we reuse infrastructure libraries? We selected them in a separate repository, then placed them in the Nuget packages that we put in Artifactory. With any change, the assembly and publication occurs automatically.
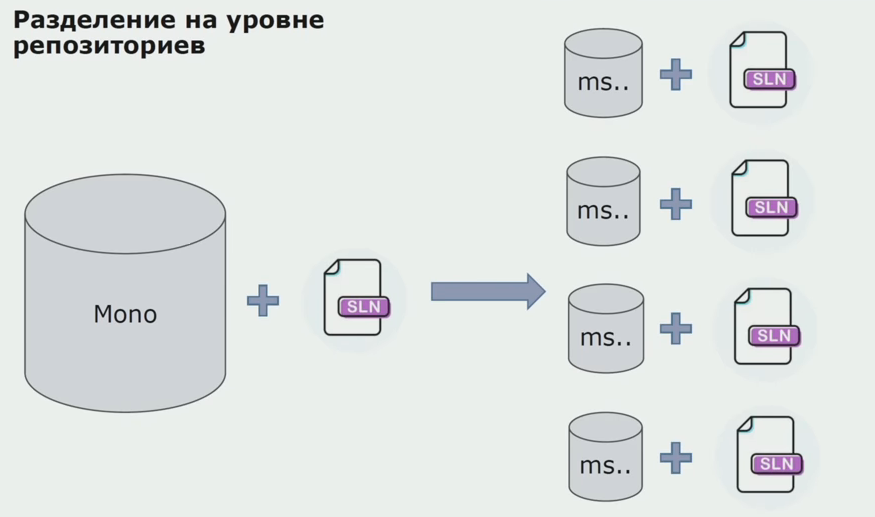
Our services began to refer to internal infrastructure packages in the same way as to external ones. We download external libraries from Nuget. To work with Artifactory, where we put these packages, we used two package managers. In small repositories, we also used Nuget. In repositories with several services, we used Paket, which provides more version consistency between modules.
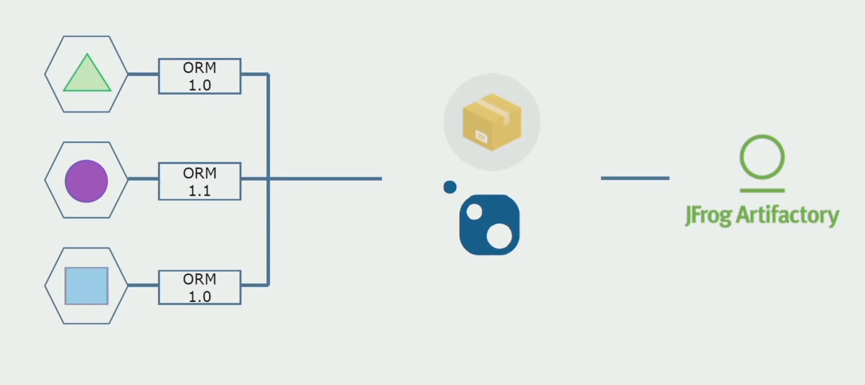
Thus, working on the source code, slightly changing the architecture and sharing repositories, we make our services more independent.
Most of the downsides to switching to microservices are related to infrastructure. You will need automated deployment, you will need new libraries to operate the infrastructure.
Manual installation in environments
Initially, we installed the solution on environments manually. To automate this process, we created a CI / CD pipeline. They chose the continuous delivery process, because continuous deployment for us is not yet acceptable from the point of view of business processes. Therefore, sending to operation is carried out by the button, and for testing - automatically.
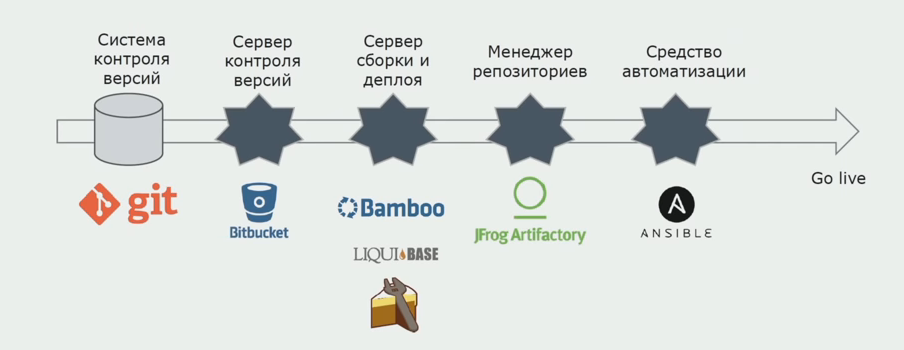
We use Atlassian, Bitbucket to store the source code, and Bamboo to build. We like to write assembly scripts on Cake because it is the same C #. Ready-made packages come to Artifactory, and Ansible automatically gets to the test servers, after which they can be tested immediately.
At one time, one of the ideas of the monolith was the provision of joint logging. We also needed to understand what to do with the individual logs that lie on the disks. Logs are written to us in text files. We decided to use the standard ELK stack. We did not write directly to the ELK through providers, but decided that we would finalize the text logs and write down the trace ID in them as an identifier, adding the service name so that these logs could then be parsed.

Using Filebeat, we get the opportunity to collect our logs from servers, then convert them, using Kibana to build requests in the UI and watch how the call went between services. The trace ID helps a lot in this.
Initially, we did not fully understand how to debug developed services. Everything was simple with the monolith, we ran it on the local machine. At first, they tried to do the same with microservices, but sometimes to fully launch one microservice, you need to start several others, which is inconvenient. We realized that it is necessary to switch to the model when we leave only the service or services that we want to debug on the local machine. The remaining services are used from servers that match the configuration with prod. After debugging, during testing, for each task, only changed services are issued to the test server. Thus, the solution is tested in the form in which it will be available in the future.
There are servers on which only production versions of services stand. These servers are needed in case of incidents, to verify delivery before deployment, and for internal training.
We have added an automatic testing process using the popular Specflow library. Tests run automatically with NUnit immediately after deployment from Ansible. If the coverage of the task is fully automatic, then there is no need for manual testing. Although sometimes additional manual testing is still required. To determine which tests to run for a specific task, we use tags in Jira.
Additionally, the need for stress testing has grown, previously it was carried out only in rare cases. To run the tests, we use JMeter, to store them - InfluxDB, and to build process graphs - Grafana.
First, we got rid of the concept of "release." Two-month-old monstrous releases disappeared when this colossus was deployed in a production environment, breaking business processes for a while. Now we deploy services on average every 1.5 days, grouping them, because they go into operation after approval.
There are no fatal crashes in our system. If we released a microservice with an error, then the functionality associated with it will be broken, and all other functionality will not be affected. This greatly improves the user experience.
We can manage the deployment scheme. You can select service groups separately from the rest of the solution, if necessary.
In addition, we significantly reduced the problem with a large queue of improvements. We now have separate product teams that work with part of the services independently. The Scrum process is already a good fit. A particular team may have a separate owner of the product, which sets its tasks.
The project began its history a long time ago, in early 2000. The first versions were written in Visual Basic 6. Over time, it became clear that development in this language in the future would be difficult to support, since the IDE and the language itself are poorly developed. In the late 2000s, it was decided to switch to a more promising C #. The new version was written in parallel with the refinement of the old one, gradually more and more code was on .NET. Backend in C # initially focused on the service architecture, however, during development, shared libraries with logic were used, and services were launched in a single process. It turned out the application, which we called the "service monolith".
One of the few advantages of this bundle was the ability of services to call each other through an external API. There were clear prerequisites for the transition to a more correct service, and in the future, microservice architecture.
We started our decomposition work around 2015. We have not yet reached an ideal state - there are parts of a large project that are difficult to call monoliths, but they do not look like microservices either. However, the progress is substantial.
I’ll talk about him in the article.
Content
- Architecture and problems of the existing solution
- Microservice Expectations
- Transition problems
- How to switch from monolith to microservices
- First way
- Second way
- Third way
- Fourth way
- Work with a DB
- Branch existing tables
- Processing Department
- Working with source code
- Infrastructure issues
- Manual installation in environments
- Separate Logging
- Testing and debugging related services
Architecture and problems of the existing solution
Initially, the architecture looked as follows: UI is a separate application, the monolithic part is written in Visual Basic 6, the application in .NET was a set of related services that works with a fairly large database.
Disadvantages of the previous solution.
Single point of failure
. We had a single point of failure: the .NET application started in one process. If any of the modules crashed, the entire application failed and had to be restarted. Since we are automating a large number of processes for different users, due to a failure in one of them, some could not work for some time. And with a software error, redundancy did not help either.
The lineup of improvements
This flaw is rather organizational. Our application has many customers, and they all want to finalize it as soon as possible. Previously, it was impossible to do this in parallel, and all customers stood in line. This process caused a negative effect on the business, because they needed to prove that their task was valuable. And the development team was taking the time to organize this lineup. This took a lot of time and effort, and the product as a result could not change as quickly as it would have been from him.
Optimal use of resources
When placing services in a single process, we always completely copied the configuration from server to server. We wanted to place the most loaded services separately so as not to waste resources and get more flexible management of our deployment scheme.
It is difficult to introduce modern technologies.
A problem familiar to all developers: there is a desire to introduce modern technologies into the project, but there is no possibility. With a large monolithic solution, any update of the current library, not to mention the transition to a new one, turns into a rather non-trivial task. It takes a long time to prove the team leader that this will bring more bonuses than spent nerves.
Difficulty issuing changes
This was the most serious problem - we issued releases every two months.
Each release turned into a real disaster for the bank, despite testing and the efforts of developers. The business understood that part of the functionality would not work for him at the beginning of the week. And the developers understood that they were waiting for a week of serious incidents.
Everyone had a desire to change the situation.
Microservice Expectations
Delivery of components upon availability. Delivery of components as they become available due to decomposition of the solution and separation of various processes.
Small food teams. This is important because it was difficult to manage a large team working on an old monolith. Such a team was forced to work according to a strict process, but I wanted more creativity and independence. Only small teams could afford it.
Isolation of services in separate processes. Ideally, I wanted to isolate in containers, but a large number of services written in the .NET Framework run only under Windows. Services are now appearing on .NET Core, but so far they are few.
Deployment Flexibility.I would like to combine services as we need, and not as the code forces.
Use of new technologies. This is interesting to any programmer.
Transition problems
Of course, if it were simple to break a monolith into microservices, you would not have to talk about it at conferences and write articles. In this process, there are many pitfalls, I will describe the main ones that interfered with us.
The first problem is typical of most monoliths: the coherence of business logic. When we write a monolith, we want to reuse our classes so as not to write extra code. And when switching to microservices, this becomes a problem: all the code is quite tightly connected, and it is difficult to separate services.
At the time of the beginning of work, the repository had more than 500 projects and more than 700 thousand lines of code. This is a fairly large solution and the second problem . It was not possible to simply take and divide it into microservices.
Third problem- lack of necessary infrastructure. In fact, we were involved in manually copying the source code to the servers.
How to switch from monolith to microservices
Isolation of microservices
First, we immediately determined for ourselves that the separation of microservices is an iterative process. We have always been required to conduct business task development in parallel. How we will carry out this technically is already our problem. Therefore, we were preparing for the iterative process. It will not work differently if you have a large application, and it is not ready to be rewritten from the very beginning.
What methods do we use to isolate microservices?
The first way is to port existing modules as services. In this regard, we were lucky: there were already formalized services that worked on the WCF protocol. They were distributed in separate assemblies. We moved them separately, adding a small launcher to each assembly. It was written using the wonderful Topshelf library, which allows you to run the application both as a service and as a console. This is convenient for debugging, since no additional projects are required in the solution.
Services were connected according to business logic, since they used common assemblies and worked with a common database. It was difficult to call them microservices in their pure form. Nevertheless, we could issue these services separately, in different processes. This already allowed us to reduce their influence on each other, reducing the problem with parallel development and a single point of failure.
Building with a host is just one line of code in the Program class. We hid Topshelf in a helper class.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
The second way to isolate microservices: create them to solve new problems. If the monolith does not grow at the same time, this is already excellent, which means that we are moving in the right direction. To solve new problems, we tried to do separate services. If there was such an opportunity, then we created more “canonical” services that completely control their data model, a separate database.
We, like many, started with authentication and authorization services. They are perfect for this. They are independent, as a rule, they have a separate data model. They themselves do not interact with the monolith, only he turns to them to solve some problems. On these services, you can begin the transition to a new architecture, debug the infrastructure on them, try some approaches related to network libraries, etc. In our organization, there are no teams that could not make an authentication service.
The third way to isolate the microservices that we use is a little specific to us. This is pulling business logic out of the UI layer. We have the main desktop UI application, it, like the backend, is written in C #. Developers periodically made mistakes and brought out on the UI parts of the logic that were supposed to exist in the backend and be reused.
If you look at a real example from the code of the UI part, you can see that most of this solution contains real business logic, which is useful in other processes, not only for building a UI form.
The real UI logic there is only the last couple of lines. We transferred it to the server so that we could reuse it, thereby reducing the UI and achieving the correct architecture.
The fourth, most important way to isolate microservices , which allows you to reduce the monolith, is the removal of existing services with processing. When we take out existing modules as is, the result is not always pleasant for developers, and the business process from the time the functionality was created could become outdated. Thanks to refactoring, we can support a new business process because business requirements are constantly changing. We can improve the source code, remove known defects, create a better data model. There are many benefits.
The processing services division is inextricably linked to the concept of a limited context. This is a concept from subject-oriented design. It means a domain model section in which all terms of a single language are uniquely defined. Consider the context of insurance and bills as an example. We have a monolithic application, and it is necessary to work with the insurance in the insurance account. We expect the developer to find the existing “Account” class in another assembly, make a link to it from the “Insurance” class, and we will get a working code. The DRY principle will be respected, the task through the use of existing code will be done faster.
As a result, it turns out that the contexts of accounts and insurance are connected. When new requirements arise, this connection will interfere with development, increasing the complexity of an already complex business logic. To solve this problem, you need to find the boundaries between the contexts in the code and remove their violations. For example, in the context of insurance, it is quite possible that the 20-digit account number of the Central Bank and the date of opening the account will be sufficient.
In order to separate these limited contexts from each other and begin the process of isolating microservices from a monolithic solution, we used an approach such as creating external APIs inside the application. If we knew that some module should become a microservice, somehow change within the process, then we immediately made calls to the logic, which belongs to another limited context, through external calls. For example, through REST or WCF.
We decided for ourselves that we would not avoid code that would require distributed transactions. In our case, it turned out to be quite easy to comply with this rule. We still haven’t encountered such situations when hard distributed transactions are really needed - the final consistency between the modules is enough.
Consider a specific example. We have the concept of an orchestra - conveyor, which processes the essence of the "application". He takes turns creating a customer, account and bank card. If the client and the account were created successfully, and the creation of the card failed, the application does not go into the status “successfully” and remains in the status “card not created”. In the future, background activity will pick it up and finish it. The system is in a state of inconsistency for some time, but this, on the whole, suits us.
If, nevertheless, a situation arises when it will be necessary to consistently save part of the data, we will most likely go to enlarge the service in order to process this in one process.
Consider an example of microservice allocation. How can it be relatively safely brought to production? In this example, we have a separate part of the system - the salary service module, one of the sections of the code of which we would like to make microservice.
First of all, we create a microservice by rewriting the code. We improve some points that did not suit us. We realize new business requirements from the customer. Add to the bundle between the UI and the API Gateway backend, which will provide call forwarding.
Next, we release this configuration into operation, but in the state of the pilot. Most of our users still work with old business processes. For new users, we are developing a new version of a monolithic application that this process no longer contains. In fact, we have a bunch of monolith and microservice working in the form of a pilot.
With a successful pilot, we understand that the new configuration is really operational, we can remove the old monolith from the equation and leave the new configuration in the place of the old solution.
In total, we use almost all existing methods for separating the source code of a monolith. All of them allow us to reduce the size of parts of the application and transfer them to new libraries, making better source code.
Work with a DB
The database can be divided worse than the source code, since it contains not only the current schema, but also the accumulated historical data.
Our database, like many others, had another important drawback - its huge size. This database was designed in accordance with the intricate business logic of the monolith, and links have accumulated between the tables of various limited contexts.
In our case, to complete all the troubles (a large database, many relationships, sometimes incomprehensible borders between tables), a problem arose in many large projects: using the shared database template. Data was taken from tables through view, through replication, and shipped to other systems where this replication is needed. As a result, we could not take out the tables in a separate scheme, because they were actively used.
The separation helps us to break up into limited contexts in the code. It usually gives us a pretty good idea of how we break up data at the database level. We understand which tables relate to one limited context and which relate to another.
We applied two global ways to split the database: splitting existing tables and splitting.
Separation of existing tables is a method that is good to use if the data structure is of high quality, satisfies business requirements and suits everyone. In this case, we can select existing tables in a separate schema.
A processing department is needed when the business model has changed a lot and the tables no longer completely satisfy us.
Branch existing tables. We need to determine what we will separate. Without this knowledge, nothing will come of it, and here the separation of limited contexts in the code will help us. As a rule, if you can understand the boundaries of the contexts in the source code, it becomes clear which tables should be included in the list for separation.
Imagine that we have a solution in which two monolith modules interact with one database. We need to make sure that only one module interacts with the part of the separated tables, and the other starts interacting with it through the API. For starters, it’s enough that only an entry is made through the API. This is a necessary condition so that we can talk about the independence of microservices. Reading links can remain until there is a big problem.
As the next step, we can already select a code section that works with detachable tables with or without processing into a separate microservice and run it in a separate process, container. This will be a separate service with communication with the monolith database and those tables that are not directly related to it. The monolith still interacts with the detachable part for reading.
Later we will remove this connection, that is, reading the data of the monolithic application from the separated tables will also be transferred to the API.
Next, we select from the general database the tables with which only the new microservice works. We can move tables to a separate schema or even to a separate physical database. There was a reading connection between the microservice and the monolith database, but there is nothing to worry about, in this configuration it can live for a long time.
The last step is to completely remove all connections. In this case, we may need data migration from the main database. Sometimes we want to reuse some data or directories that are replicated from external systems in several databases. We occasionally meet this.
Processing department. This method is very similar to the first, only goes in the reverse order. We immediately have a new database and a new microservice that interacts with the monolith through the API. But at the same time, there remains a set of database tables that we want to delete in the future. We will no longer need it, in the new model we replaced it.
For this scheme to work, we most likely will need a transition period.
There are two possible approaches.
First : we duplicate all the data in the new and old databases. In this case, we have data redundancy, there may be problems with synchronization. But then we can take two different customers. One will work with the new version, the other with the old.
Second: share data for some business attribute. For example, in our system there were 5 products that are stored in the old database. The sixth as part of a new business task, we put in a new database. But we need the Gateway API, which synchronizes this data and shows the client where and what to take.
Both approaches are working, choose according to the situation.
After we make sure that everything works, the part of the monolith that works with the old database structures can be disabled.
The final step is to remove the old data structures.
Summing up, we can say that we have problems with the database: it is difficult to work with it compared to the source code, it is more difficult to separate, but this can and should be done. We found some ways that allow this to be done quite safely, yet it is easier to make a mistake with the data than with the source code.
Working with source code
This is what the source code diagram looked like when we started analyzing a monolithic project.
It can conditionally be divided into three layers. This is a layer of launched modules, plugins, services and individual activities. In fact, these were the entry points within the monolithic solution. All of them were tightly bonded with a Common layer. It had business logic that was shared between services, and many connections. Each service and plugin used up to 10 or more common assemblies, depending on their size and the conscience of the developers.
We were lucky, we had infrastructure libraries that could be used separately.
Sometimes a situation arose when some of the Common objects did not actually belong to this layer, but were infrastructure libraries. This was decided by renaming.
Most worrying were limited contexts. It happened that 3-4 contexts were mixed in one assembly of Common and used each other within the framework of the same business functions. It was necessary to understand where this can be divided and at what boundaries, and what to do next with mapping of this separation into source code assemblies.
We have formulated several rules for the code separation process.
First: We no longer wanted to share business logic between services, activities, and plugins. They wanted to make business logic independent within the framework of microservices. On the other hand, microservices, in the ideal case, are perceived as services that exist completely independently. I believe that this approach is somewhat wasteful, and it is difficult to achieve it, because, for example, services in C # will in any case be connected by a standard library. Our system is written in C #, other technologies have not yet been used. Therefore, we decided that we can afford to use common technical assemblies. The main thing is that they do not have any fragments of business logic. If you have a convenient wrapper over the ORM that you use, then copying it from service to service is very expensive.
Our team is a fan of subject-oriented design, so the “onion architecture” is perfect for us. The basis of our services was not a data access layer, but an assembly with domain logic, which contains only business logic and is devoid of infrastructure connections. At the same time, we can independently modify the domain assembly to solve the problems associated with the frameworks.
At this stage, we met the first serious problem. The service was supposed to refer to one domain assembly, we wanted to make the logic independent, and here the DRY principle strongly interfered with us. To avoid duplication, the developers wanted to reuse classes from neighboring assemblies, and as a result, the domains began to communicate with each other again. We analyzed the results and decided that perhaps the problem lies also in the area of the source code storage device. We had a large repository in which all the source codes lay. Solution for the whole project was very difficult to assemble on a local machine. Therefore, separate small solutions were created for the parts of the project, and no one forbade adding any Comm- or domain assembly to them and reusing them. The only tool that did not allow us to do this was the review code.
Then we began to switch to a model with separate repositories. Business logic has ceased to flow from service to service, domains have truly become independent. Limited contexts are supported more clearly. How do we reuse infrastructure libraries? We selected them in a separate repository, then placed them in the Nuget packages that we put in Artifactory. With any change, the assembly and publication occurs automatically.
Our services began to refer to internal infrastructure packages in the same way as to external ones. We download external libraries from Nuget. To work with Artifactory, where we put these packages, we used two package managers. In small repositories, we also used Nuget. In repositories with several services, we used Paket, which provides more version consistency between modules.
Thus, working on the source code, slightly changing the architecture and sharing repositories, we make our services more independent.
Infrastructure issues
Most of the downsides to switching to microservices are related to infrastructure. You will need automated deployment, you will need new libraries to operate the infrastructure.
Manual installation in environments
Initially, we installed the solution on environments manually. To automate this process, we created a CI / CD pipeline. They chose the continuous delivery process, because continuous deployment for us is not yet acceptable from the point of view of business processes. Therefore, sending to operation is carried out by the button, and for testing - automatically.
We use Atlassian, Bitbucket to store the source code, and Bamboo to build. We like to write assembly scripts on Cake because it is the same C #. Ready-made packages come to Artifactory, and Ansible automatically gets to the test servers, after which they can be tested immediately.
Separate Logging
At one time, one of the ideas of the monolith was the provision of joint logging. We also needed to understand what to do with the individual logs that lie on the disks. Logs are written to us in text files. We decided to use the standard ELK stack. We did not write directly to the ELK through providers, but decided that we would finalize the text logs and write down the trace ID in them as an identifier, adding the service name so that these logs could then be parsed.
Using Filebeat, we get the opportunity to collect our logs from servers, then convert them, using Kibana to build requests in the UI and watch how the call went between services. The trace ID helps a lot in this.
Testing and debugging related services
Initially, we did not fully understand how to debug developed services. Everything was simple with the monolith, we ran it on the local machine. At first, they tried to do the same with microservices, but sometimes to fully launch one microservice, you need to start several others, which is inconvenient. We realized that it is necessary to switch to the model when we leave only the service or services that we want to debug on the local machine. The remaining services are used from servers that match the configuration with prod. After debugging, during testing, for each task, only changed services are issued to the test server. Thus, the solution is tested in the form in which it will be available in the future.
There are servers on which only production versions of services stand. These servers are needed in case of incidents, to verify delivery before deployment, and for internal training.
We have added an automatic testing process using the popular Specflow library. Tests run automatically with NUnit immediately after deployment from Ansible. If the coverage of the task is fully automatic, then there is no need for manual testing. Although sometimes additional manual testing is still required. To determine which tests to run for a specific task, we use tags in Jira.
Additionally, the need for stress testing has grown, previously it was carried out only in rare cases. To run the tests, we use JMeter, to store them - InfluxDB, and to build process graphs - Grafana.
What have we achieved?
First, we got rid of the concept of "release." Two-month-old monstrous releases disappeared when this colossus was deployed in a production environment, breaking business processes for a while. Now we deploy services on average every 1.5 days, grouping them, because they go into operation after approval.
There are no fatal crashes in our system. If we released a microservice with an error, then the functionality associated with it will be broken, and all other functionality will not be affected. This greatly improves the user experience.
We can manage the deployment scheme. You can select service groups separately from the rest of the solution, if necessary.
In addition, we significantly reduced the problem with a large queue of improvements. We now have separate product teams that work with part of the services independently. The Scrum process is already a good fit. A particular team may have a separate owner of the product, which sets its tasks.
Summary
- Microservices are well suited for the decomposition of complex systems. In the process, we begin to understand what is in our system, what are the limited contexts, where their borders go. This allows you to correctly distribute the improvements to the modules and prevent code obfuscation.
- Microservices provide organizational benefits. They are often referred to only as architecture, but any architecture is needed to meet the needs of the business, and not by itself. Therefore, we can say that microservices are well suited for solving problems in small teams, given that Scrum is now very popular.
- Separation is an iterative process. You can’t take the application and simply divide it into microservices. The resulting product is unlikely to be workable. When allocating microservices, it’s advantageous to rewrite the existing legacy, that is, turn it into code that we like and better meets the needs of the business in terms of functionality and speed.
A little caveat:the costs of switching to microservices are quite substantial. It only took a long time to solve the infrastructure problem. Therefore, if you have a small application that does not require specific scaling, if there is not a large number of customers who are fighting for the attention and time of your team, then perhaps microservices are not what you need today. It is quite expensive. If you start the process with microservices, then the costs will initially be greater than if you start the same project with the development of a monolith.
PS A more emotional story (and as if personally to you) - click here .
Here is the full report.