Another way to optimize docker images for Java applications
The story of image optimization for java applications began with the spring blog article Spring Boot in a Container . It discussed various aspects of creating docker images for spring boot applications, including such an interesting issue as reducing the size of images. For our teams, this was relevant for a number of reasons, so we decided to apply this solution to our applications.
As it often happens, not everything took off the first time, there were nuances with multi-module projects and an attempt to drive all this on the CI system, so in this article you will find a solution to these problems.
The goal of optimization is to reduce the difference between the resulting images from assembly to assembly, which gives a good result in the process of continuous delivery, so if you are interested in minimizing the size of the image as such, you can refer to other articles on the hub
If you don’t have to explain why you should do something with a multi-meter boot application before placing it in the image, you can immediately go on to the description of the optimization approach . If you managed to get acquainted with the article from the spring blog, you can proceed to the solution of the problems found .
Why is this all, or the flip side of fat jar
By default, the jar that Spring Boot produces is an executable jar file containing the application code and all its dependencies.
The advantage of this approach is obvious: it’s convenient to work with one file, it has everything you need to run through . Dockerfile is trivial and not of interest.java -jar
The downside is inefficient storage. In a classic boot application, the ratio of code and libraries is clearly not in favor of our code. For example, an empty application with a web part and libraries for working with the database, which can be generated via start.spring.io , will take 20mb, of which 98% will be libraries. And this ratio does not change much during the development process.
But we collect the application more than once, but regularly on the CI server, and then deploy through a chain of environments. Thus, 10 assemblies grow at 200mb, and 100 already at 2gb, of which modifications will take very little.
It can be argued that for the current cost of storage, these are ridiculous figures and you can not waste time on such optimizations, but it all depends on the size of the organization and the number of applications whose images need to be stored. Deployment conditions can also strongly motivate: when the registry and server are nearby, even a difference of 100mb is not very noticeable, but in distributed systems this can be much more important, especially when you need to deploy to such specific countries as China with its firewall and unstable channels to the outside world.
So, with the reasons figured out, it's time to optimize.
We optimize the assembly, or What can be learned from the spring blog
The article offers a reasonable solution: instead of a single layer generated by the team COPY my-jar.jar app.jar, we need to make several layers.
One layer will contain libraries, the second is our own code. To do this, you need to unzip the jar file and copy the contents to different layers of the image.
The script for preparing the jar file looks like this:
#!/bin/sh
set -e
path_to_jar=$1
dir=$(dirname "${path_to_jar}")
jar_name=$(basename "${path_to_jar}")
mkdir -p "${dir}/docker-dist" && cd "${dir}/docker-dist"
jar -xf ../"${jar_name}"A dockerfile using a multi-stage build might look like this
FROM openjdk:8-jdk-alpine as build
WORKDIR /wd
COPY prepare_for_docker.sh /usr/local/bin/prepare_for_docker
COPY target/demo.jar /wd/app.jar
RUN prepare_for_docker /wd/app.jar
FROM openjdk:8-jdk-alpine
COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib
COPY --from=build /wd/docker-dist/META-INF /app/META-INF
COPY --from=build /wd/docker-dist/BOOT-INF/classes /app
ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"]At the first stage, we copy everything we need, run our script to unpack the jar file, and at the second stage we lay out separate libraries and our code separately in layers.
It is easy to make sure of operability:
- Collecting for the first time
- Make any change to our code.
- We start
docker buildagain and see the cherished linesUsing cachewhen copying the entire lib directory... Step 5/10 : RUN prepare_for_docker app.jar ---> Running in c8e422491eb2 Removing intermediate container c8e422491eb2 ---> c7dcec4ae18a Step 6/10 : FROM openjdk:8-jdk-alpine ---> a3562aa0b991 Step 7/10 : COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib ---> Using cache ---> 01b600d7e350 Step 8/10 : COPY --from=build /wd/docker-dist/META-INF /app/META-INF ---> Using cache ---> 5c0c03a3c8f1 Step 9/10 : COPY --from=build /wd/docker-dist/BOOT-INF/classes /app ---> 5ffed6ee5696 Step 10/10 : ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"] ---> Running in 99957250fe5d Removing intermediate container 99957250fe5d ---> 6735799d9f32 Successfully built 6735799d9f32 Successfully tagged boot2-sample:latest
An obvious way to improve this approach is to build a small base image with a script so as not to drag it from project to project. Thus, the first layer becomes more concise.
FROM zeldigas/java-layered-builder as build
COPY target/demo.jar app.jar
RUN prepare_for_docker app.jarWe are finalizing the solution
As already mentioned at the beginning of the article, the solution is working, but during the operation a couple of problems were found which will be discussed later.
Not all files in the libsame library
If your project is multi-module (at least there is module A, on which module B depends, assembled as a spring fat jar), applying an original solution to it, you will find that no layer caching occurs. What went wrong?
The matter is in additional modules: they are sources of constant changes for the layer, even if you do not make any changes to the module code. This is due to the peculiarity of creating javen files by maven (with gradle, the situation is slightly better, but not sure). The task of obtaining reproducible artifacts is not the topic of this article (although, of course, it is interesting and achievable), so we turn to a fairly simple solution.
We distribute the contents libinto 2 directories, after unpacking, separating the project modules from other libraries. Let's finalize the fat jar unpacking script:
#!/bin/sh
set -e
path_to_jar=$1
shift #(1)
app_modules=$* #(2)
dir=$(dirname "${path_to_jar}")
jar_name=$(basename "${path_to_jar}")
mkdir -p "${dir}/docker-dist" && cd "${dir}/docker-dist"
jar -xf ../"${jar_name}"
if [ -n "${app_modules}" ]; then #(3)
mkdir app-lib
for i in $app_modules; do
mv "BOOT-INF/lib/$i"* app-lib #(4)
done
fiAs a result, the script began to support the transfer of additional parameters (see 1 and 2). If additional arguments (3) are passed, each of them is considered as a prefix for the name of the file that we move (4) to a separate directory.
Dockerfile example for a scenario with one additional. module shared-moduleand version1.0-SNAPSHOT
FROM openjdk:8-jdk-alpine as build
COPY target/demo.jar /wd/app.jar
RUN prepare_for_docker /wd/app.jar shared-module-1.0
FROM openjdk:8-jdk-alpine
COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib
COPY --from=build /wd/docker-dist/app-lib /app/lib
COPY --from=build /wd/docker-dist/META-INF /app/META-INF
COPY --from=build /wd/docker-dist/BOOT-INF/classes /app
ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"]Run on the CI server
Having debugged everything locally, satisfied with the result, we started to run on the CI server and from the build logs found that a miracle did not occur, or rather the results were not constant: in some cases, caching was performed, and the next time all layers were new.
As a result, the culprit was discovered - docker cache, or rather its absence in the case of different agents (our assembly is not nailed to a specific agent of the CI system). As it turned out, if there are no suitable layers in the docker cache, then layers with a different checksum are obtained from the same set of files. You can verify this locally by running the assembly with the option --no-cache, or build a second time by first deleting the image and all the intermediate layers. As a result, you will get a completely different checksum of the layer, which negates all previous efforts.

There are several ways to solve the problem:
- If your CI-system supports this out of the box (for example, Circle CI in the plans part has built-in support for the shared cache during assemblies)
- Shuffling a section with a docker cache between agents
- Take advantage of the built-in docker for cache management (
--cache-from)
We went the third way, since in our case it was the simplest. The option allows you to tell the docker daemon which images it should take into account and try to use for caching during assembly. You can specify as many images as you consider necessary, the main thing is that they are on the file system. If the specified image does not exist, it will simply be ignored, so you need to pull before building.
Here's what container assembly looks like with this approach:
set -e
version=...
# забираем последнюю версию нашего образа
docker pull registy.example.com/my-image:latest || true
#собираем новый используя только слои из последнего для кэша
docker build -t registry.example.com/my-image:$version --cache-from registry.example.com/my-image:latest .
# пушим в registry конкретную версию и latest
docker tag registry.example.com/my-image:$version registry.example.com/my-image:latest
docker push registry.example.com/my-image:$version
docker push registry.example.com/my-image:latestWe try to reuse layers only from the most recent image, which is often enough, but no one bothers to wind up more complex logic and backtrack several versions or rely on the id of vcs commits.
Адаптируем этот подход под возможности вашего CI и получаем надежное переиспользование слоев с библиотеками.
Итого
Решение показывает хорошие результаты, особенно когда применяется в проектах с активной стадией разработки и настроенным CD пайплайном. На графике ниже показан результат применения оптимизации к одному из приложений. Хорошо видно, что линейный рост сменился на скачкообразный начиная с 70-й сборки (провалы в 60-х связаны как раз с отладкой работы на билд агентах). Выбросы после связаны с обновлением базового образа (высокие) и библиотек (пониже)
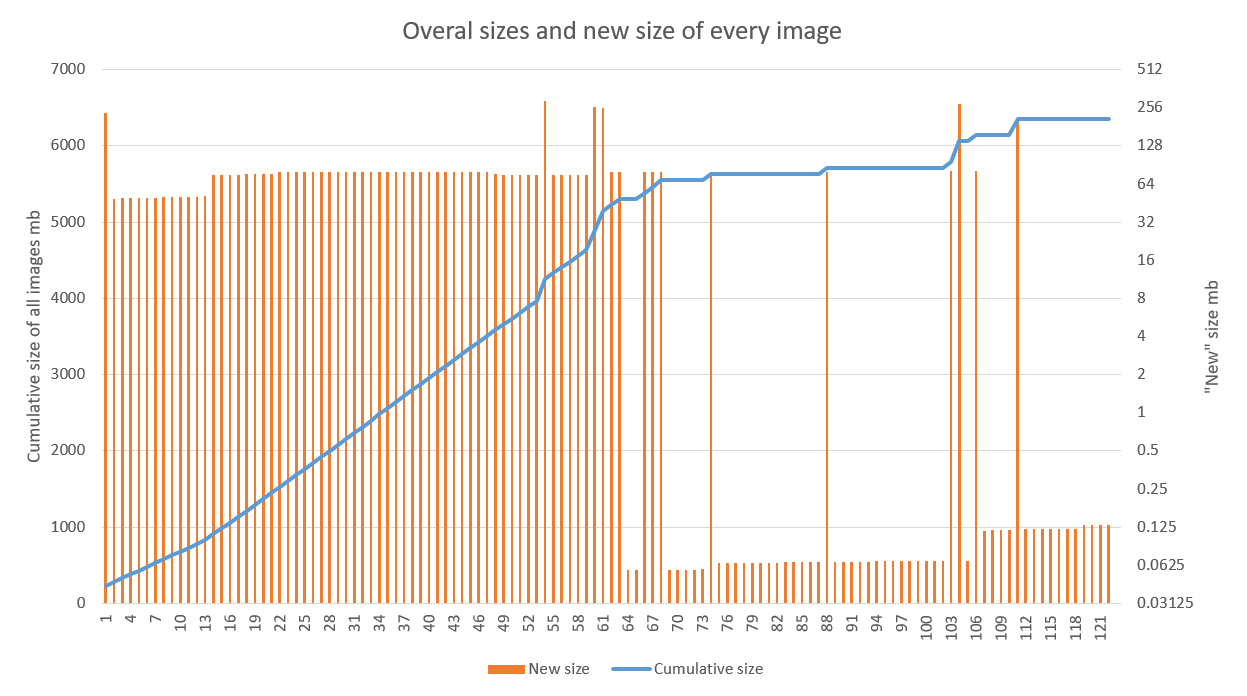
Оптимизация хранения в нашем случае является приятным, но скорее вторичным бонусом. Ускорение деплоя новой версии поверх старой в несколько регионов радует куда сильнее.
I want to note that this technique is quite compatible with other approaches aimed at reducing the size of a single image (alpine and other lightweight basic images, custom runtime for the application). The main thing is to follow the general rules for assembling the image in terms of caching and make sure that the result is reproducible.