The eternal issue of technical debt
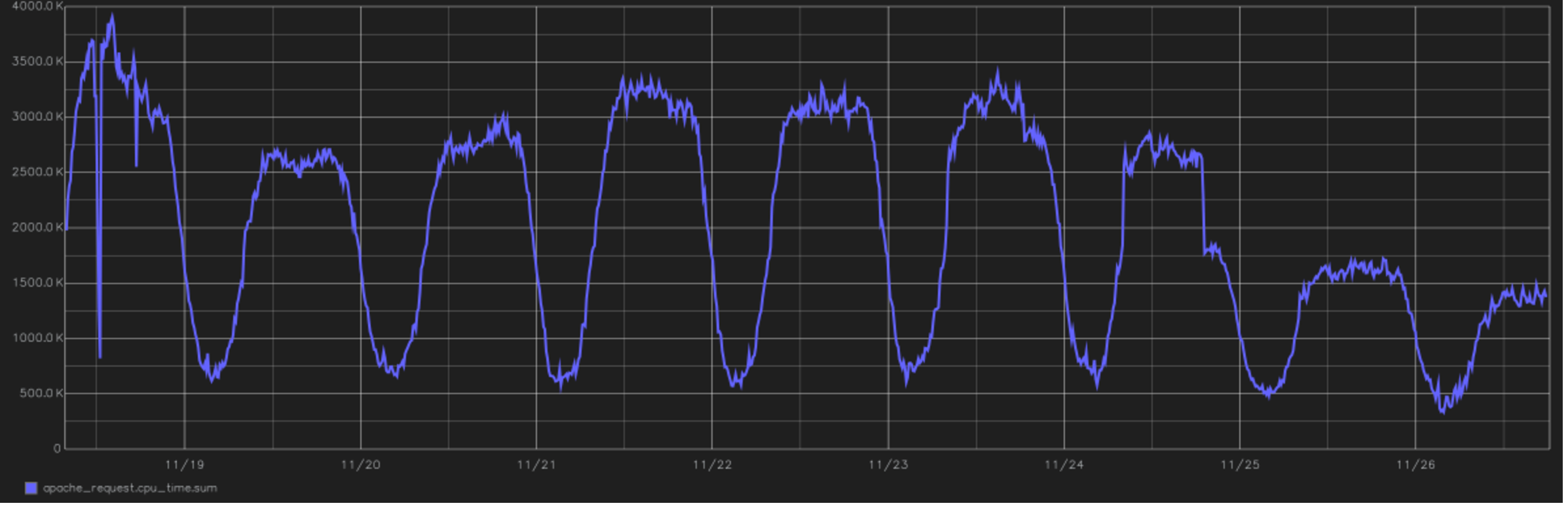
This is one of the coolest project reliefs. In the picture - a graph of the total time spent by the CPU to process all user requests. At the end you can see the transition to PHP 7.0. since version 5.6. This is the year 2016, switching in the afternoon from November 24th.
From the point of view of calculations, Tutu.ru is primarily an opportunity to buy a ticket from point A to point B. To do this, we grind a huge number of schedules, cache the responses of many airline systems and periodically make incredibly long join queries to the database. In general, we are written in PHP and until recently we were completely on it (if the language is prepared correctly, you can even build real-time systems on it). Recently, performance-critical areas have become refactored on Go.
We constantly have a technical debt . And this happens faster than we would like. The good news: you don’t have to cover it all. Bad: as the supported functionality grows, the technical debt also grows proportionally.
In general, technical debt is the cost of making a mistake in making a decision. You didn’t predict something like the architect, that is, you made a forecasting error or made a decision in the conditions of insufficient information. At some point, you understand that you need to change something in the code (often at the architecture level). Then you can immediately change, but you can wait. If you wait - interest rushed to the tech debt. Therefore, it is good practice to restructure it from time to time. Well, or declare yourself bankrupt and write the whole block again.
How it all began: monolith and general functions
The Tutu.ru project began in 2003 as a regular Runet website of those times. That is, it was a bunch of files instead of a database, a PHP page on the front of HTML + JS. There were a couple of excellent hacks from my colleague Yuri, but he’ll better tell him someday. I joined the project in 2006, first as an external consultant who could help with both advice and a code, and then, in 2009, I transferred to the state as a technical director. First of all, it was necessary to put things in order in the direction of air tickets: it was the most loaded and the most complex part in architecture.
In 2006, I remind you, there was a train schedule and there was an opportunity to buy a train ticket. We decided to make the air tickets section as a separate project, that is, all this was united only at the front. All three projects (train schedules, railway and air) were eventually written in their own way. At that time, the code seemed normal to us, but somewhat unfinished. Non-perfectionist. Then he got old, covered himself with crutches and in the railway direction turned into a pumpkin by 2010.
In railway, we did not have time to give technical debt. Refactoring was unrealistic: the problems were in architecture. We decided to demolish and redo everything all over again, but it was also difficult on a live project. As a result, only the old URLs were left at the front, and then block by block was rewritten. As a basis, we took the approaches used a year before in the development of the aviation sector.
Rewritten in PHP. Then it was clear that this was not the only way, but there were no reasonable alternatives for us. They chose it because they already had experience and achievements, it was clear that this is a good language in the hands of senior developers. Of the alternatives, C and C ++ were insanely productive, but any rebuilding or introducing changes to them then resembled a nightmare. Okay, not reminded. Were a nightmare.
MS and all .NET from the point of view of a high-load project were not even considered. Then there were no options other than Linux-based at all. Java is a good option, but it is demanding on resources from memory, it never forgives junior errors and then it did not make it possible to release releases quickly - well, or we didn’t know that. Even now we do not consider Python as a backend, only for data manipulation tasks. JS - purely under the front. There were no Ruby on Rails developers then (and now). Go was gone. There was still Perl, but experts rated it as unpromising for web development, so they also abandoned it. PHP is left.
The next holiv story is PostgreSQL vs. MySQL. Somewhere better one, somewhere else. In general, then it was good practice to choose what turned out better, so we chose MySQL and its forks.
The development approach was monolithic, then there were simply no other approaches, but with the orthogonal structure of the libraries. These are the beginnings of the modern API-centric approach, when each library has a facade outside, for which you can pull directly inside the code from other parts of the project. Libraries were written in “layers” when each level has a specific format at the input and passes a certain format further to the code, and unit tests spin between them. That is, something like test-driven-development, but pixelated and scary.
All this was hosted on several servers, which made it possible to scale under load. But at the same time, the code base of different projects intersected quite strongly at the system level. This in fact meant that changes in the railway project could affect our own aircraft. And touched often. For example, in railway it was necessary to expand work with payments - this is a revision of the shared library. And the aircraft works with it, therefore, joint testing is needed. We screened the dependencies with tests, and this was more or less normal. Even in 2009, the method was quite advanced. But still, the load could add another from one resource. There was an intersection in the databases, which led to unpleasant effects in the form of brakes throughout the site with local problems in one product. Railway killed the aircraft several times on the disk due to heavy queries to the database.
We scaled by adding instances and balancing between them. Monolith as is.
Tire age
Then we went along a rather marginal path. On the one hand, we started to allocate services (today this approach is called microservice, but we did not know the word “micro”), but for interaction we started using the bus for data transfer, rather than REST or gRPC, as they do now. We chose AMQP as the protocol, and RabbitMQ as the message broker. By that time, we had quite famously mastered the launch of daemons for PHP (yes, there is a fully working fork () implementation and everything else for working with processes), since for a long time in the monolith we used such a thing as Gearman to parallelize requests to reservation systems .
They made a broker on top of the rabbit, and it turned out that all this does not really live under load. Some kind of network losses, retransmits, delays. For example, a cluster of several brokers “out of the box” behaves somewhat differently than stated by the developer (it never happened before, and again). In general, they learned a lot. But in the end, we got the SLAs required for the services. For example, the most loaded RPS service has at 400 rps, the 99th percentile round-trip from client to client including the bus and service processing of the order of 35 ms. Now in total on the bus we observe about 18 krps.
Then came the direction of the buses. We immediately wrote it without a monolith on the service architecture. Since everything was written from scratch, it turned out very well, quickly and conveniently, although it was necessary to constantly refine the tools for a new approach. Yes, all this was spinning on virtual machines, inside of which PHP daemons communicate via the bus. Demons started inside Docker containers, but there were no solutions for orchestration like Openshift or Kubernetes. At 2014, we were just starting to talk about it, but we did not consider such an approach to sales.
If you compare how many bus tickets are sold in comparison with plane or train tickets, you get a drop in the bucket. And in trains and planes, moving to a new architecture was difficult, because there was working functionality, a real load, and there was always a choice between doing something new or spending money on paying off a technical debt.
Moving to services is a good thing, but a long one, but you need to deal with the load and reliability now. Therefore, in parallel, they began to take targeted measures to improve the life of the monolith. Backends were divided into product types, that is, they began to more flexibly control the routing of requests depending on their type: air separately from the railway, etc. It was possible to predict the load, scale independently. When they knew that in railways, for example, the peak of New Year’s sales, then several instances of virtual machines were added. It then began exactly 45 days before the last working day of the year, and on November 14-15 we had a double load. Now FPK and other carriers have made many tickets with the start of sales for 60, 90 and even 120 days, and this peak has spread. But on the last working day of April there will always be a load on electric trains before May, and there are still peaks.
Somewhere in 2014, they began to derban a large database of many small ones. This was important because it was growing dangerously, and the fall was critical. We began to allocate separate small databases (for 5-10 tables) for a specific functionality, so that other services would affect less disruptions, and so that all this could be scaled easier. It is worth noting that for load balancing and scaling we used replicas for reading. Recovering replicas for a large base after a replication failure could take hours, and all this time I had to "fly on parole and on one wing." Memories of such periods still cause an unpleasant chill somewhere between the ears. Now we have about 200 instances of different bases, and administering so many installations with our hands is a laborious and unreliable business. Therefore we use Github Orchestrator,
Like now
In general, we gradually began to allocate asynchronous tasks and separate their launches in the event handler so that one does not interfere with the other.
When PHP 7 came out, we saw in the tests a very big progress in performance and reducing resource consumption. Moving to it took place with a little hemorrhoids, the whole project from the beginning of the tests to the complete translation of the entire production took a little more than six months, but after that the consumption of resources fell by almost half. CPU load timeline - at the top of the post.
The monolith has survived to this day and, in my estimation, is approximately 40% of the code base. It is worth saying that the task of replacing the entire monolith with services is not explicitly set. We are moving pragmatically: everything new is done on microservices, if you need to refine the old functionality in a monolith, then we try to transfer it to the service architecture, if only the refinement is not really very small. At the same time, the monolith is covered in tests so that we can deploy twice a week with a sufficient level of quality. Features are covered in different ways, unit tests are quite complete, UI tests and Acceptance tests cover almost the entire portal functionality (we have about 15,000 test cases), API tests are more or less complete. We almost do not do load testing. More precisely, our staging is similar to prod in structure, but not in power, and is lined with the same monitoring. We are generating a load if we see that the previous run on the old release differs in timings, we look how critical. If the new release and the old are approximately the same, then we release them in the prod. In any case, all the features go out under the switch so that you can turn it off at any second if something goes wrong.
Heavy features are always tested for 1% of users. Then we go to 2%, 5%, 10% and so we reach all users. That is, we can always see the atypical load before the surge killing the servers and disconnect in advance.
Where necessary, we took (and will take) 4-5 months for a reengineering project, when the team focuses on a specific task. This is a good way to cut the Gordian knot when local refactoring no longer helps. So we did a few years ago with air: we redid the architecture, did it - immediately got instant acceleration in development, were able to launch many new features. Two months after reengineering, they grew by an order of magnitude for customers due to features. They began to more accurately manage prices, connecting partners, everything became faster. Joy. I must say, now it’s time to do the same thing again, but this is fate: the ways of building applications are changing, new solutions, approaches, tools are appearing. To stay in business, you need to grow.
The main task of reengineering for us is to accelerate development further. If nothing new is needed, then reengineering is not needed. No need to invent a new one: it makes no sense to invest in modernization. And so, while maintaining a modern stack and architecture, people get into work faster, a new one connects faster, the system behaves more predictably, developers are more interested in working on a project. Now there is a task to finish the monolith without throwing it out completely, so that each product can upload updates, not depending on others. That is, get a specific CI / CD in a monolith.
Today we use not only rabbit, but also REST, and gRPC to exchange information between services. Some of the microservices are written in Golang: the computational speed and memory handling are excellent there. There was a call to implement nodeJS support, but in the end we left the node only for server rendering, and the business logic was left in PHP and Go. In principle, the chosen approach allows us to develop services in almost any language, but we decided to limit the zoo so as not to increase the complexity of the system.
Now we go to microservices that will work in Docker containers under the OpenShift orchestration. The task within a year and a half - 90% of all twist inside the platform. Why? So it’s faster to deploy, faster to check versions, there is less difference in selling from the devel environment. The developer can think more about the feature that he implements, and not about how to deploy the environment, how to configure it, where to start it, that is, more benefit. Again - operational issues: there are many microservices, they need to be automated by management. Manually - very high costs, the risks of errors with manual control, and the platform gives normal scaling.
Every year we have an increase in workload - by 30–40%: more and more people are mastering tricks with the Internet, stop going to physical cash desks, we are adding new products and features to existing ones. Now about 1 million users a day comes to the portal. Of course, not all users generate the same load. Something does not require computational resources at all, and, for example, searches are a rather resource-intensive component. There, a single tick “plus or minus three days” in aviation increases the load by 49 times (when looking back and forth, the matrix is 7 by 7). Everything else in comparison with the search for a ticket inside the railway systems and air is quite simple. The easiest resource - adventure and tour search(there’s not the easiest cache from the architectural point of view, but still there are far fewer tours than ticket combinations), then the train schedule (it is easily cached by standard means), and only then everything else.
Of course, technical debt still piles up. From all sides. The main thing is to understand in time where you can manage to refactor, and everything will be fine, where you don’t have to touch anything (sometimes it happens: we live with Legacy if there are no changes planned), but somewhere we need to rush and reengineer ourselves, because without this future will not. Of course, we make mistakes, but in general, Tutu.ru has been around for 16 years, and I like the dynamics of the project.