Tupperware: Facebook killer Kubernetes?
- Transfer
Efficient and reliable cluster management at any scale with Tupperware

Today at the Systems @Scale conference, we introduced Tupperware, our cluster management system that orchestrates containers on millions of servers, where almost all of our services work. We first launched Tupperware in 2011, and since then our infrastructure has grown from 1 data center to as many as 15 geo-distributed data centers . All this time Tupperware did not stand still and developed with us. We will tell you in which situations Tupperware provides first-class cluster management, including convenient support for stateful services, a single control panel for all data centers and the ability to distribute power between services in real time. And we will share the lessons that we learned as our infrastructure developed.
Tupperware performs various tasks. Application developers use it to deliver and manage applications. It packs the code and application dependencies into an image and delivers it to the servers in the form of containers. Containers provide isolation between applications on the same server so that developers are busy with the application logic and not think about how to find servers or control updates. Tupperware also monitors the server’s performance, and if it finds a failure, it transfers containers from the problem server.
Capacity Planning Engineers use Tupperware to distribute server capacities into teams according to budget and constraints. They also use it to improve server utilization. Data center operators turn to Tupperware to properly distribute containers among data centers and stop or move containers during maintenance. Due to this, the maintenance of servers, networks and equipment requires minimal human involvement.
Tupperware Architecture
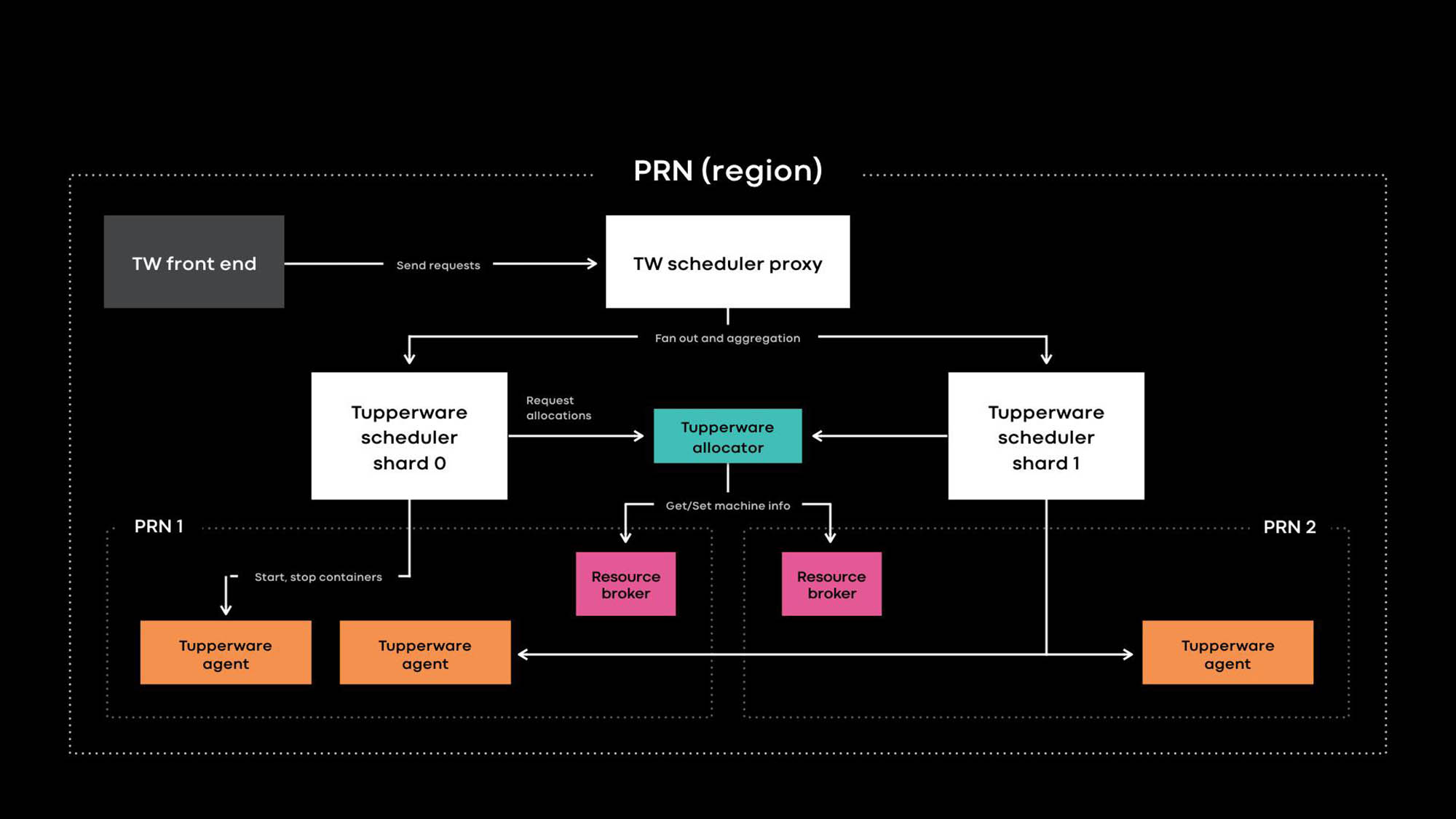
Architecture Tupperware PRN is one of the regions of our data centers. The region consists of several data center buildings (PRN1 and PRN2) located nearby. We plan to make one control panel that will manage all servers in one region.
Application developers deliver services in the form of Tupperware jobs. A task consists of several containers, and all of them usually execute the same application code.
Tupperware is responsible for container provisioning and lifecycle management. It consists of several components:
- The Tupperware Frontend provides an API for the user interface, CLI, and other automation tools through which you can interact with Tupperware. They hide the entire internal structure from Tupperware job owners.
- The Tupperware Scheduler is the control panel responsible for managing the container and job life cycle. It is deployed at the regional and global levels, where a regional scheduler manages servers in one region, and a global scheduler manages servers from different regions. The scheduler is divided into shards, and each shard controls a set of tasks.
- The scheduler proxy in Tupperware hides the internal sharding and provides a convenient unified control panel for Tupperware users.
- The Tupperware Distributor assigns containers to the servers. The scheduler is responsible for stopping, starting, updating, and failing containers. Currently, a single distributor can manage an entire region without dividing into shards. (Note the difference in terminology. For example, the scheduler in Tupperware corresponds to the control panel in Kubernetes , and the Tupperware distributor is called the scheduler in Kubernetes.)
- The resource broker stores the source of truth for the server and service events. We run one resource broker for each data center, and it stores all the server information in this data center. A resource broker and a capacity management system, or resource allocation system, dynamically decide which scheduler supply controls which server. The health check service monitors servers and stores data on their health in the resource broker. If the server has problems or needs maintenance, the resource broker tells the distributor and scheduler to stop the containers or transfer them to other servers.
- Tupperware Agent is a daemon running on each server that prepares and removes containers. Applications work inside the container, which gives them more isolation and reproducibility. At last year’s Systems @Scale conference, we already described how individual Tupperware containers are created using images, btrfs, cgroupv2, and systemd.
Distinctive features of Tupperware
Tupperware is very similar to other cluster management systems, such as Kubernetes and Mesos , but there are some differences:
- Native support for stateful services.
- A single control panel for servers in different data centers to automate the delivery of containers based on intent, decommissioning clusters and maintenance.
- Clear separation of the control panel for zooming.
- Flexible calculations allow you to distribute power between services in real time.
We designed these cool features to support a variety of stateless and stateful applications in a huge global shared server park.
Native support for stateful services.
Tupperware manages many critical stateful services that store persistent product data for Facebook, Instagram, Messenger and WhatsApp. These can be large key-value pairs (for example, ZippyDB ) and monitoring data stores (for example, ODS Gorilla and Scuba ). Maintaining stateful services is not easy, because the system must ensure that container deliveries can withstand large-scale failures, including a power outage or a power outage. Although conventional methods, such as distributing containers across failure domains, are well suited for stateless services, stateful services need additional support.
For example, if as a result of a server failure one replica of the database becomes unavailable, is it necessary to allow automatic maintenance that will update the kernels on 50 servers from a 10-thousandth pool? Depends on the situation. If on one of these 50 servers there is another replica of the same database, it is better to wait and not to lose 2 replicas at once. In order to dynamically make decisions about the maintenance and health of the system, you need information about the internal data replication and the location logic of each stateful service.
The TaskControl interface allows stateful services to influence decisions that affect data availability. Using this interface, the scheduler notifies external applications of container operations (restart, update, migration, maintenance). The Stateful service implements a controller that tells Tupperware when each operation can be safely performed, and these operations can be swapped or temporarily delayed. In the above example, the database controller may instruct Tupperware to upgrade 49 of the 50 servers, but not touch a specific server (X) so far. As a result, if the kernel update period passes, and the database still cannot restore the problem replica, Tupperware will still upgrade the X server.

Many stateful services in Tupperware do not use TaskControl directly, but through ShardManager, a common platform for creating stateful services on Facebook. With Tupperware, developers can indicate their intent on how containers should be distributed across data centers. With ShardManager, developers indicate their intent on how data shards should be distributed across containers. ShardManager is aware of data hosting and replication of its applications and interacts with Tupperware through the TaskControl interface to plan container operations without direct application involvement. This integration greatly simplifies the management of stateful services, but TaskControl is capable of more. For example, our extensive web tier is stateless and uses TaskControl to dynamically adjust the speed of updates in containers. Eventuallythe web tier can quickly execute multiple software releases per day without compromising availability.
Server management in data centers
When Tupperware first appeared in 2011, a separate scheduler controlled each server cluster. Then the Facebook cluster was a group of server racks connected to one network switch, and the data center contained several clusters. The scheduler could manage servers in only one cluster, that is, the task could not extend to several clusters. Our infrastructure was growing, we were increasingly writing off clusters. Since Tupperware could not transfer the task from the decommissioned cluster to other clusters without changes, it took a lot of effort and careful coordination between application developers and data center operators. This process led to a waste of resources when the servers were idle for months due to the decommissioning procedure.
We created a resource broker to solve the problem of decommissioning clusters and coordinate other types of maintenance tasks. The resource broker monitors all the physical information associated with the server, and dynamically decides which scheduler manages each server. Dynamic binding of servers to schedulers allows the scheduler to manage servers in different data centers. Since the Tupperware job is no longer limited to one cluster, Tupperware users can specify how containers should be distributed across the failure domains. For example, a developer may declare his intention (for example: “run my task on 2 failure domains in the PRN region”) without specifying specific availability zones. Tupperware itself will find the right servers to embody this intention even in the case of decommissioning a cluster or service.
Scaling to support the entire global system
Historically, our infrastructure has been divided into hundreds of dedicated server pools for individual teams. Due to fragmentation and the lack of standards, we had high transaction costs, and idle servers were harder to use again. At last year’s Systems @Scale conference, we introduced Infrastructure as a Service (IaaS) , which should integrate our infrastructure into a large, unified server fleet. But a single server fleet has its own difficulties. It must meet certain requirements:
- Scalability. Our infrastructure grew with the addition of data centers in each region. Servers have become smaller and more energy efficient, so in each region there are much more. As a result, a single scheduler for a region cannot cope with the number of containers that can be run on hundreds of thousands of servers in each region.
- Reliability. Even if the scale of the scheduler can be so increased, due to the large scope of the scheduler, the risk of errors will be higher, and the entire container region may become unmanageable.
- Fault tolerance. In the event of a huge infrastructure failure (for example, due to a network breakdown or a power outage, the servers where the scheduler is running will fail), only a part of the region’s servers will have negative consequences.
- Ease of use. It may seem that you need to run several independent schedulers in one region. But in terms of convenience, a single point of entry into a common pool in the region simplifies capacity and job management.
We divided the scheduler into shards to solve problems with supporting a large shared pool. Each scheduler shard manages its set of tasks in the region, and this reduces the risk associated with the scheduler. As the total pool grows, we can add more scheduler shards. For Tupperware users, shards and proxy schedulers look like one control panel. They do not have to work with a bunch of shards that orchestrate tasks. The scheduler shards are fundamentally different from the cluster schedulers that we used before, when the control panel was divided without static separation of the common server pool according to the network topology.
Improving utilization with elastic computing
The larger our infrastructure, the more important it is to efficiently use our servers to optimize infrastructure costs and reduce the load. There are two ways to improve server utilization:
- Flexible computing - reduce the scale of online services during quiet hours and use the freed up servers for offline loads, for example, for machine learning and MapReduce tasks.
- Excessive load - host online services and batch workloads on the same servers so that batch loads are executed with low priority.
The bottleneck in our data centers is energy consumption . Therefore, we prefer small, energy-efficient servers that together provide more processing power. Unfortunately, on small servers with a small amount of processor resources and memory, excessive loading is less efficient. Of course, we can place several containers of small services on one small energy-efficient server that consume little processor resources and memory, but large services will have low performance in this situation. Therefore, we advise the developers of our large services to optimize them so that they use the entire server.
Basically, we improve utilization with elastic computing. The intensity of use of many of our large services, for example, news feeds, message features and front-end web level, depends on the time of day. We intentionally reduce the scale of online services during quiet hours and use the freed-up servers for offline loads, for example, for machine learning and MapReduce tasks.
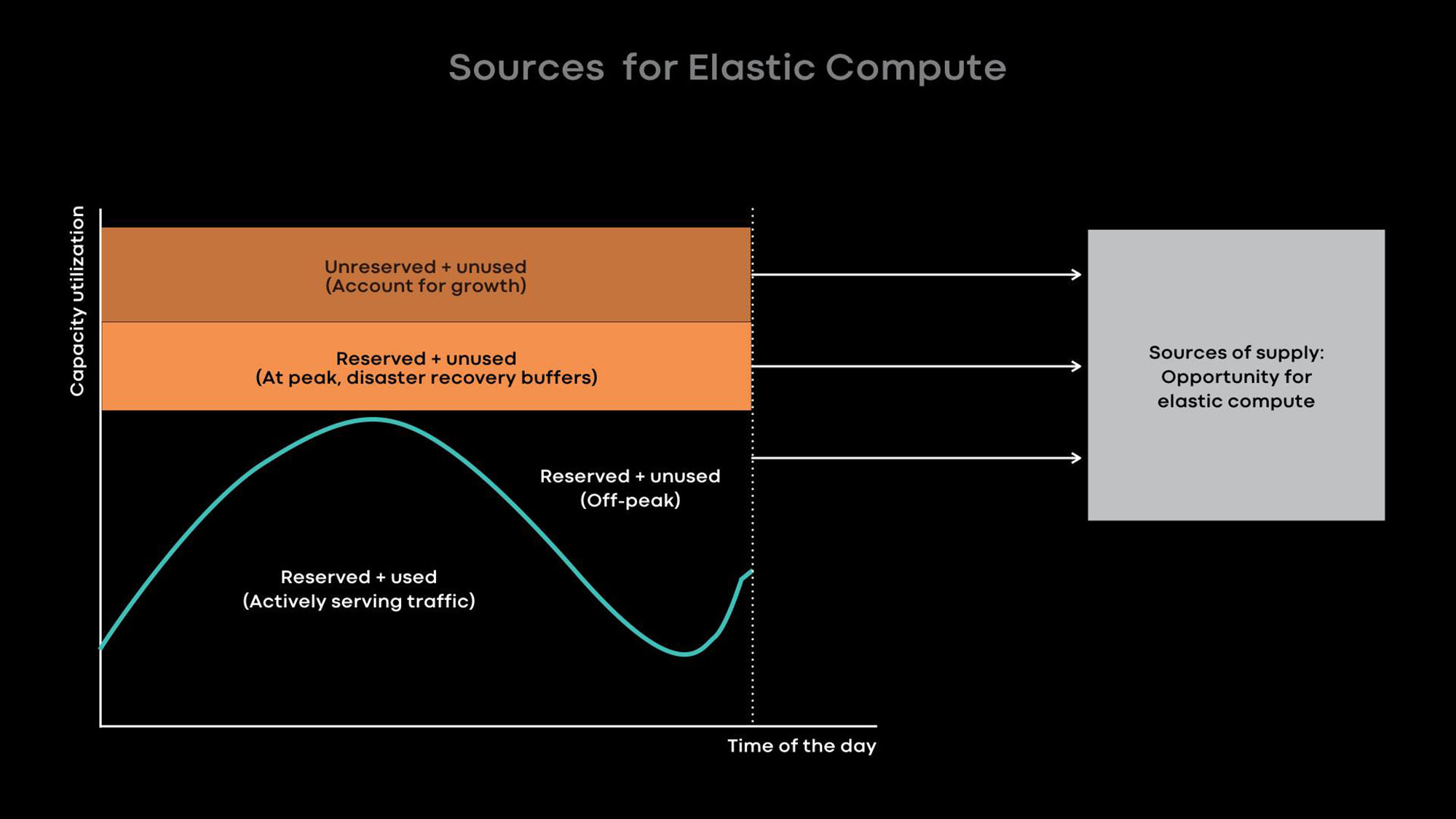
From experience, we know that it is best to provide entire servers as units of elastic power, because large services are both the main donors and the main consumers of elastic power, and they are optimized for the use of entire servers. When the server is freed from the online service in the quiet hours, the resource broker gives the server to the scheduler for temporary use so that it runs offline loads on it. If a load peak occurs in an online service, the resource broker quickly recalls the lent server and, together with the scheduler, returns it to the online service.
Lessons Learned and Future Plans
Over the past 8 years, we have developed Tupperware to keep up with the rapid development of Facebook. We talk about what we have learned and hope that it helps others manage rapidly growing infrastructures:
- Настраивайте гибкую связь между панелью управления и серверами, которыми она управляет. Эта гибкость позволяет панели управления управлять серверами в разных датацентрах, помогает автоматизировать списание и обслуживание кластеров и обеспечивает динамическое распределение мощностей с помощью эластичных вычислений.
- С единой панелью управления в регионе становится удобнее работать с заданиями и проще управлять крупным общим парком серверов. Обратите внимание, что панель управления поддерживает единую точку входа, даже если ее внутренняя структура разделена по соображениям масштаба или отказоустойчивости.
- Используя модель плагина, панель управления может уведомлять внешние приложения о предстоящих операциях с контейнером. Более того, stateful-сервисы могут использовать интерфейс плагина, чтобы настраивать управление контейнером. С помощью такой модели плагина панель управления обеспечивает простоту и при этом эффективно обслуживает множество различных stateful-сервисов.
- Мы считаем, что эластичные вычисления, при которых мы забираем у донорских сервисов целые серверы для пакетных заданий, машинного обучения и других несрочных сервисов, — это оптимальный способ повысить эффективность использования маленьких и энергоэффективных серверов.
We are just starting to implement a single global common server park . Now about 20% of our servers are in the common pool. To achieve 100%, you need to solve many issues, including supporting a common pool for storage systems, automating maintenance, managing the requirements of different clients, improving server utilization and improving support for machine learning workloads. We cannot wait to tackle these tasks and share our successes.