How to revive the documentation?
Probably every pain knows this pain - irrelevant documentation. No matter how hard the team tries, in modern projects we will release so often that it is almost impossible to describe all the changes. Our testing team, together with system analysts, decided to try to revitalize our project documentation.

Alfa-Bank’s web projects use the Akita testing automation framework , which is used for BDD scripts. To date, the framework has gained great popularity due to its low entry threshold, usability and the ability to test layout. But we decided to go further - on the basis of the described test scenarios, to generate documentation, thereby greatly reducing the time that analysts spend on the eternal problem of updating the documentation.
In fact, together with Akita, a documentation generation plug-in was already used, which went through the steps in the scripts and uploaded them to the html format, but in order to make this document popular, we needed to add:
We looked at our existing plug-in, which was, in fact, a static analyzer and generated documentation based on the scripts described in the .feature files. We decided to add speakers, and in order not to make the plug-in look like a plug-in, we decided to write our own.
First, we decided to find out how we can collect screenshots and values of variables used in test scripts from feature files. Everything turned out to be quite simple. Cucumber, when running tests for each feature file, creates a separate cucumber.json.
Inside this file contains the following objects:
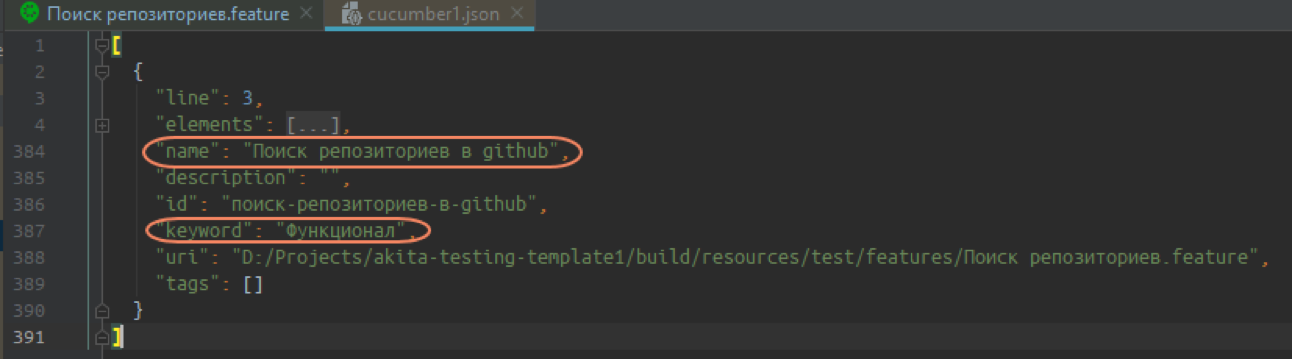
Test case name and keyword:
Arrays of elements - the scripts and steps themselves:
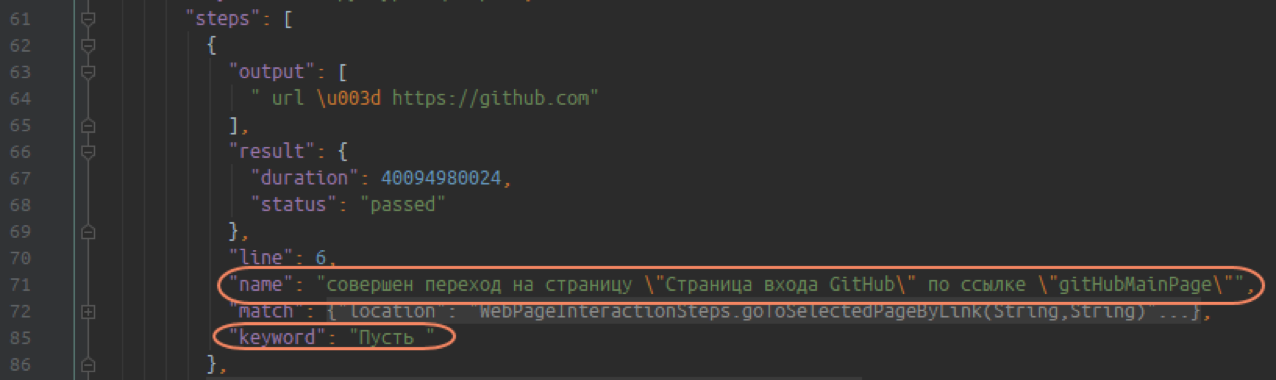
The output field contains additional information, for example, variables - addresses, links, user accounts, etc.:

The embeddings contain screenshots that selenium takes during the tests:

Thus, we just need to go through the cucumber.json files, collect the names of the test suites, test scripts, pull out the steps, collect additional information and screenshots.
In order for the documentation to display requests that occur in the background or for a specific action, we had to ask our front developers for help. With the help of proxy, we were able to catch traceId, which generate front-end service requests. By the same traceId, logs are written in elastic, from where we pull all the necessary query parameters into the test report and documentation.
As a result, we got a file in the Asciidoc format - a convenient file format, a bit more complicated than the markdown analogue, but has much more formatting options (you can insert an image or a table, which cannot be done in markdown).
To convert the resulting Asciidoc to other formats, we use Ascii doctorj, which is the official version for the AsciiDoctor Java tool. As a result, we get ready-made documentation in html format, which can be downloaded in confluence, sent to a colleague or put into the repository.

Now, to generate front-end documentation for your project, you just need to connect the documentation plugin to it and after running all the tests run the command
Alfa-Bank’s web projects use the Akita testing automation framework , which is used for BDD scripts. To date, the framework has gained great popularity due to its low entry threshold, usability and the ability to test layout. But we decided to go further - on the basis of the described test scenarios, to generate documentation, thereby greatly reducing the time that analysts spend on the eternal problem of updating the documentation.
In fact, together with Akita, a documentation generation plug-in was already used, which went through the steps in the scripts and uploaded them to the html format, but in order to make this document popular, we needed to add:
- Screenshots
- values of variables (config file, user accounts, etc.);
- statuses and query parameters.
We looked at our existing plug-in, which was, in fact, a static analyzer and generated documentation based on the scripts described in the .feature files. We decided to add speakers, and in order not to make the plug-in look like a plug-in, we decided to write our own.
First, we decided to find out how we can collect screenshots and values of variables used in test scripts from feature files. Everything turned out to be quite simple. Cucumber, when running tests for each feature file, creates a separate cucumber.json.
Inside this file contains the following objects:
Test case name and keyword:
Arrays of elements - the scripts and steps themselves:
The output field contains additional information, for example, variables - addresses, links, user accounts, etc.:
The embeddings contain screenshots that selenium takes during the tests:
Thus, we just need to go through the cucumber.json files, collect the names of the test suites, test scripts, pull out the steps, collect additional information and screenshots.
In order for the documentation to display requests that occur in the background or for a specific action, we had to ask our front developers for help. With the help of proxy, we were able to catch traceId, which generate front-end service requests. By the same traceId, logs are written in elastic, from where we pull all the necessary query parameters into the test report and documentation.
As a result, we got a file in the Asciidoc format - a convenient file format, a bit more complicated than the markdown analogue, but has much more formatting options (you can insert an image or a table, which cannot be done in markdown).
To convert the resulting Asciidoc to other formats, we use Ascii doctorj, which is the official version for the AsciiDoctor Java tool. As a result, we get ready-made documentation in html format, which can be downloaded in confluence, sent to a colleague or put into the repository.
How to connect?
Now, to generate front-end documentation for your project, you just need to connect the documentation plugin to it and after running all the tests run the command
adoc.What do we want to improve?
- Add configurable technical steps.
In the current version of the plugin there are steps "And a screenshot was taken ...". Such steps do not carry a semantic load for documentation, and we want to hide them. Now we have sewn them inside the plugin, and they are skipped, but there is a drawback - each addition of this step leads to the fact that we need to build a new version of the plugin. In order to get away from this, we plan to transfer such steps to the configuration file and write down those steps that we do not want to see in the scripts. - Make an open sourse plugin.
Which teams are suitable for our implementation?
- use Cucumber (or a similar framework);
- want to have up-to-date documentation for the front and the knowledge base;
- They want to engage analysts in testing.
Result:
Pilot on several teams showed that with the help of the plugin we manage to keep the documentation up to date, analysts no longer need to spend their time maintaining it. In addition, the implementation of this feature made us think about continuing to implement full-fledged BDD within teams. Today we are conducting an experiment - analysts formulate a positive way for the client, indicate business restrictions using Akita BDD steps, testers, in turn, write custom steps and additional checks for these scenarios.By the way, about holivar, whether BDD is needed or not, on Monday we will hold a special meeting .