Data recovery from XtraDB tables without structure file using byte analysis of ibd file

Background
It so happened that the server was attacked by a ransomware virus, which, by a "fluke", partially set aside the .ibd files (raw data files of innodb tables), but completely encrypted the .fpm files (structure files). At the same time .idb could be divided into:
- subject to recovery through standard tools and guides. For such cases, there is a great article ;
- partially encrypted tables. Mostly these are large tables, on which (as I understood), the attackers did not have enough RAM for full encryption;
- Well, fully encrypted tables that cannot be recovered.
It was possible to determine which option the tables belong to by opening in any text editor under the desired encoding (in my case it is UTF8) and simply looking at the file for the presence of text fields, for example:
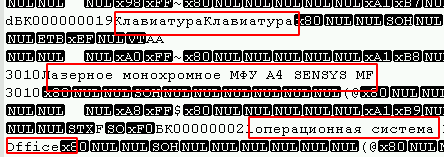
Also, at the beginning of the file you can observe a large number of 0-bytes, and viruses that use the block encryption algorithm (the most common) usually affect them.
In my case, the attackers at the end of each encrypted file left a string of 4 bytes (1, 0, 0, 0), which simplified the task. A script was enough to search for uninfected files:
def opened(path):
files = os.listdir(path)
for f in files:
if os.path.isfile(path + f):
yield path + f
for full_path in opened("C:\\some\\path"):
file = open(full_path, "rb")
last_string = ""
for line in file:
last_string = line
file.close()
if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0):
print(full_path)Thus it turned out to find files belonging to the first type. The second implies a long manual, but already found was enough. Everything would be fine, but it is necessary to know the absolutely exact structure and (of course) there was such a case that I had to work with a frequently changing table. No one remembered whether the type of the field was changing, or a new column was being added.
Unfortunately, Debri City could not help with this case, therefore this article is being written.
Get to the point
There is a table structure of 3 months ago that does not coincide with the current one (perhaps one field, but possibly more). Table structure:
CREATE TABLE `table_1` (
`id` INT (11),
`date` DATETIME ,
`description` TEXT ,
`id_point` INT (11),
`id_user` INT (11),
`date_start` DATETIME ,
`date_finish` DATETIME ,
`photo` INT (1),
`id_client` INT (11),
`status` INT (1),
`lead__time` TIME ,
`sendstatus` TINYINT (4)
); in this case, you need to extract:
id_pointINT (11);id_userINT (11);date_startDATETIMEdate_finishDATETIME
For recovery, a byte analysis of the .ibd file is used, followed by their translation in a more readable form. Since to find what is required, it is enough for us to analyze such data types as int and datatime, only they will be described in the article, but sometimes they will also refer to other data types, which can help in other similar incidents.
Problem 1 : fields with types DATETIME and TEXT had a NULL value, and they are simply skipped in the file, because of this, it was not possible to determine the structure for recovery in my case. In the new columns, the default value was null, and some of the transactions could be lost due to the setting innodb_flush_log_at_trx_commit = 0, so additional time would have to be spent to determine the structure.
Problem 2 : it should be noted that the rows deleted through DELETE will all be exactly in the ibd file, but their structure will not be updated with ALTER TABLE. As a result, the data structure can vary from the beginning of the file to its end. If you often use OPTIMIZE TABLE, you are unlikely to encounter a similar problem.
Please note that the DBMS version affects the way data is stored, and this example may not work for other major versions. In my case, windows version mariadb 10.1.24 was used. Also, although in mariadb you work with InnoDB tables, in fact they are XtraDB , which excludes the applicability of the method with InnoDB mysql.
File analysis
In python, the bytes () data type displays data in Unicode instead of the usual set of numbers. Although you can consider the file in this form, but for convenience, you can translate bytes into a numerical form by translating the byte array into a regular array (list (example_byte_array)). In any case, both methods are useful for analysis.
After looking at several ibd files, you can find the following:
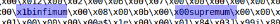
Moreover, if you divide the file by these keywords, you will get mostly flat data blocks. We will use infimum as a divisor.
table = table.split("infimum".encode())An interesting observation, for tables with a small amount of data, between infimum and supremum there is a pointer to the number of rows in the block.
 - test table with 1st row
- test table with 1st row
 - test table with 2 rows
- test table with 2 rows
The array of rows table [0] can be skipped. Having looked at it, I still could not find the raw data of the tables. Most likely, this block is used to store indexes and keys.
Starting with table [1] and translating it into a numerical array, you can already notice some patterns, namely:

These are int values stored in a string. The first byte indicates whether the number is positive or negative. In my case, all numbers are positive. From the remaining 3 bytes, you can determine the number using the following function. Script:
def find_int(val: str): # example '128, 1, 2, 3'
val = [int(v) for v in val.split(", ")]
result_int = val[1]*256**2 + val[2]*256*1 + val[3]
return result_intFor example, 128, 0, 0, 1 = 1 , or 128, 0, 75, 108 = 19308 .
The table had a primary key with auto-increment, and here you can also find it

Comparing the data from the test tables, it was revealed that the DATETIME object consists of 5 bytes, starting with 153 (most likely indicating annual intervals). Since the DATTIME range is '1000-01-01' to '9999-12-31', I think the number of bytes can vary, but in my case, the data falls in the period from 2016 to 2019, so we assume that 5 bytes is enough .
To determine the time without seconds, the following functions were written. Script:
day_ = lambda x: x % 64 // 2 # {x,x,X,x,x }
def hour_(x1, x2): # {x,x,X1,X2,x}
if x1 % 2 == 0:
return x2 // 16
elif x1 % 2 == 1:
return x2 // 16 + 16
else:
raise ValueError
min_ = lambda x1, x2: (x1 % 16) * 4 + (x2 // 64) # {x,x,x,X1,X2}For a year and a month, it was not possible to write a healthy working function, so I had to hardcode. Script:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128',
'2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0',
'2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128',
'2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0',
'2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128',
'2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0',
'2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192',
'2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64',
'2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192',
'2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64',
'2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192',
'2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64',
'2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0',
'2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128',
'2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0',
'2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128',
'2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0',
'2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128',
'2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64',
'2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192',
'2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64',
'2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192',
'2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64',
'2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192',
'2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128',
'2020, 3': '153, 165, 192','2020, 4': '153, 166, 0',
'2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128',
'2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0',
'2020, 9': '153, 167, 64','2020, 10': '153, 167, 128',
'2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'}
def year_month(x1, x2): # {x,X,X,x,x }
for key, value in ym_list.items():
key = [int(k) for k in key.replace("'", "").split(", ")]
value = [int(v) for v in value.split(", ")]
if x1 == value[1] and x2 // 64 == value[2] // 64:
return key
return 0, 0I am sure that if you spend n the number of time, then this misunderstanding can be corrected.
Next, the function returns a datetime object from a string. Script:
def find_data_time(val:str):
val = [int(v) for v in val.split(", ")]
day = day_(val[2])
hour = hour_(val[2], val[3])
minutes = min_(val[3], val[4])
year, month = year_month(val[1], val[2])
return datetime(year, month, day, hour, minutes)Удалось обнаружить часто повторяющиеся значения из int, int, datetime, datetime 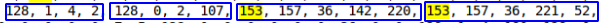 , похоже это то что нужно. Причём, такая последовательность дважды за строку не повторяется.
, похоже это то что нужно. Причём, такая последовательность дважды за строку не повторяется.
Используя регулярное выражение, находим необходимые данные:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)Обратите внимание, что при поиске по данному выражению, не удастся определить NULL значения в требуемых полях, но в моём случае это не критично. После в цикле перебираем найденное. Скрипт:
result = []
for val in fined:
pre_result = []
bd_int = re.findall(r"128, \d*, \d*, \d*", val)
bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val)
for it in bd_int:
pre_result.append(find_int(bd_int[it]))
for bd in bd_date:
pre_result.append(find_data_time(bd))
result.append(pre_result)Actually everything, data from the result array, this is the data we need. ### PS. ###
I understand that this method is not suitable for everyone, but the main goal of the article is to prompt action rather than solve all your problems. I think the most correct solution would be to start studying the source code of mariadb itself , but due to the limited time, the current method seemed the fastest.
In some cases, after analyzing the file, you can determine the approximate structure and restore one of the standard methods from the links above. It will be much more correct and cause less problems.