Web analytics black holes: how much data is lost in GA and why
- Transfer
If you ever compared the data of two analytical tools on the same site or compared analytics with reports and sales, you probably noticed that they do not always match. In this article, I will explain why there are no data in the statistics of web analytics platforms, and how large these losses can be.
In this article, we will focus on Google Analytics, as the most popular analytic service, although most of the analytic platforms implemented on-page have the same problems. Services that rely on server logs avoid some of these problems, but they are so rarely used that we will not cover them in this article.
Analytics test configurations in Distilled
At Distilled.net, we have a standard Google Analtics resource that works from an HTML tag in Google Tag Manager. In addition, over the past two years, I have used three additional parallel implementations of Google Analytics, designed to measure differences between different configurations.
Two of these additional implementations — one in GTM and the other on-page — manage locally stored, renamed copies of the Google Analytics JavaScript file (www.distilled.net/static/js/au3.js instead of www.google-analytics.com/ analytics.js ) to make them harder to detect for ad blockers.
I also used renamed JavaScript functions ("tcap" and "Buffoon" instead of the standard "ga") and renamed trackers ("FredTheUnblockable" and "AlbertTheImmutable") to avoid the problem of duplicate trackers (which can often lead to problems).
Finally, we have the “DianaTheIndefatigable” configuration, which has a renamed tracker, but uses standard code and is implemented at the page level.
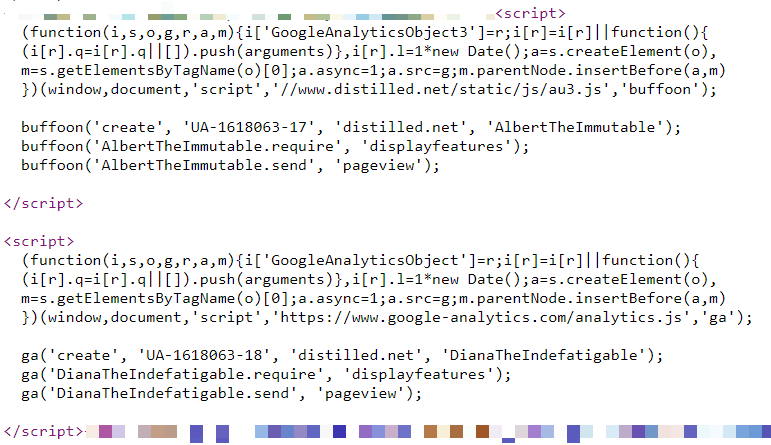
All our configurations are reflected in the table below:

I tested their functionality in different browsers and ad blockers, analyzing pageviews that appear in browser developer tools:
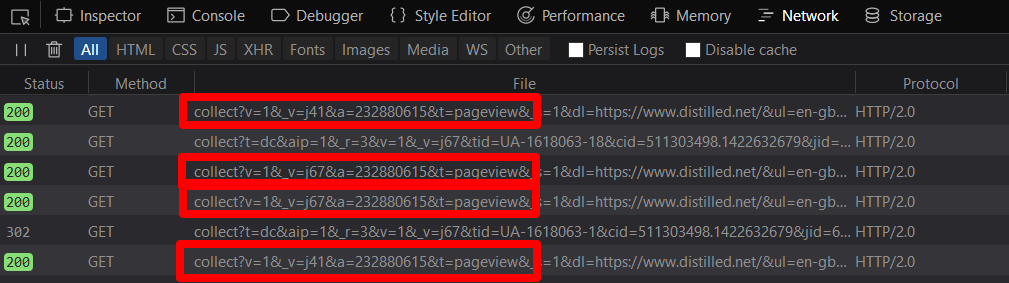
Reasons for data loss
1. Ad blockers
Ad blockers, mainly in the form of browser extensions, are becoming more common. Initially, the main reason for their use was to improve the performance and interaction experience on sites with a large amount of advertising. In recent years, the emphasis on data privacy has increased, which has also contributed to the popularity of ad blockers.
Impact of ad blockers
Some ad blockers block web analytics platforms by default; others may be further configured to perform this function. I tested the Distilled website with Adblock Plus and uBlock Origin, the two most popular desktop browser extensions for ad blocking, but it’s worth noting that ad blockers are also increasingly used on smartphones.
The following results were obtained (all figures relate to April 2018):
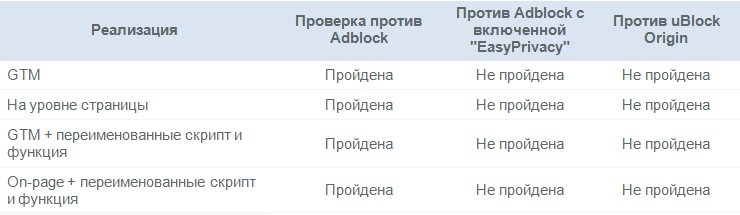
As can be seen from the table, the changed GA settings do not greatly help to resist blockers.
Data loss due to ad blockers: ~ 10%
Use of ad blockers may be at the level of 15-25% depending on the region, but many of these settings are AdBlock Plus with default settings, at which, as we saw above, tracking is not is blocked.
AdBlock Plus's share of the ad blocker market varies between 50-70%. According to recent estimates , this figure is closer to 50%. Therefore, if we assume that no more than 50% of installed ad blockers block analytics, then we will get data loss at the level of about 10%.
2. Do Not Track feature in browsers
This is another feature that is motivated by privacy protection. But this time it's not about the add-on, but about the function of the browsers themselves. The Do Not Track request is not required for sites and platforms, but, for example, Firefox offers a stronger function under the same set of parameters, which I also decided to test.
The Do Not Track Impact
Most browsers now offer the option to send a Do Not Track message. I tested the latest releases of Firefox and Chrome browsers for Windows 10.

Again, it seems that the changed settings here also do not help much.
Data loss due to "Do Not Track": <1%
Testing showed that only the Tracking Protection feature in the Firefox Quantum browser affects trackers. Firefox occupies 5% of the browser market, but tracking protection is not enabled by default. Therefore, the launch of this function did not affect the trends of Firefox traffic on Distilled.net.
3. Filters
Filters that you configure in the analytics system can intentionally or unintentionally underestimate the volume of received traffic in the reports.
For example, a filter that excludes certain screen resolutions, which may be bots or internal traffic, will obviously lead to some underestimation of traffic.
Loss of data due to filters: N / A
The impact of this factor is difficult to assess, since this setting varies depending on the site. But I highly recommend having a duplicate, “main” view (without filters) so that you can quickly see the loss of important information.
4. GTM vs on-page vs incorrectly located code
In recent years, Google Tag Manager has become an increasingly popular way to implement analytics because of its flexibility and ease of making changes. However, I have long noticed that this GA implementation method can lead to underestimation in comparison with the page-level setting.
I was also curious about what would happen if you did not follow Google’s recommendations for setting the on-page code.
Combining your own data with data from the siteof my colleague Dom Woodman, who uses the Drupal analytic extension, as well as GTM, I could see the difference between the Tag Manager and the code incorrectly located on the page (placed at the bottom of the tag). Then I matched this data with my own GTM data to see the full picture across all 5 configurations.
Effect of GTM and incorrectly located on-page code
Traffic as a percentage of the baseline (standard implementation using Tag Manager):
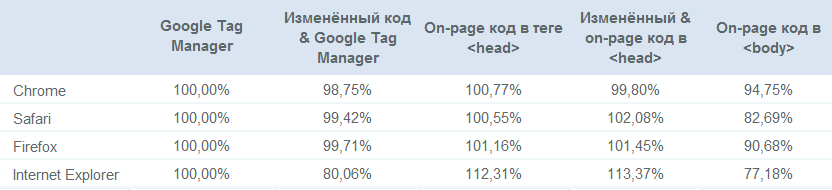
Main conclusions
- On-page code usually registers more traffic than GTM;
- The modified code is usually within the margin of error, except for the modified GTM code in Internet Explorer;
- An incorrectly located tracking code will cost you up to 30% of your traffic compared to correctly implemented on-page code, depending on the browser (!);
- Custom configurations designed to receive more traffic by avoiding ad blockers do not.
It is also worth noting that user implementations in fact receive less traffic than standard ones. In the case of on-page code, the losses are within the margin of error, but in the case of GTM there is another nuance that could affect the final data.
Since I used unfiltered profiles for comparison, there was a lot of bot spam in the main profile, which was mostly disguised as Internet Explorer.
Today, our main profile is the most spammed, but it is also used as the level chosen for comparison, so the difference between the on-page code and the Tag Manager is actually slightly larger.
GTM data loss: 1-5%
Losses associated with GTM vary depending on which browsers and devices are used by visitors to your site. On Distilled.net, the difference is about 1.7%, our audience actively uses desktops and is technically advanced, Internet Explorer is rarely used. Depending on the vertical, losses can reach 5%.
I also made a breakdown by device:

Data loss due to incorrectly located on-page code: ~ 10%
On Teflsearch.com due to incorrectly located code, about 7.5% of data was lost, against GTM. Given that the Tag Manager itself underestimates the data, the total loss could easily reach 10%.
Bonus: data loss from channels
Above, we examined areas in which you can lose data in general. However, there are other factors leading to incomplete data. We will consider them more briefly. The main problems here are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that is not really direct traffic.
And this is becoming an increasingly common situation.
Typical causes of dark traffic:
- Unmarked email marketing campaigns;
- Unmarked campaigns in applications (especially Facebook, Twitter, etc.);
- Distorted organic traffic;
- Data sent due to errors made during the tracking setup process (may also appear as self-referrals);
It is also worth noting a trend in the direction of growth of truly direct traffic, which has historically been organic. For example, in connection with the improvement of the autocomplete function in browsers, the synchronization of the search history on different devices, etc., people seem to “enter” the URL they were looking for earlier.
Attribution
In general, a session in Google Analytics (and on any other platform) is a rather arbitrary construct. You may find it obvious how a group of calls should be combined into one or more sessions, but in reality, this process relies on a number of rather dubious assumptions. In particular, it is worth noting that Google Analytics usually attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Conclusion
I was somewhat surprised by some of the results I received, but I'm sure that I did not cover everything, and there are other ways to lose data. So, research in this area can be continued further.
More such articles can be read on my telegram channel (proroas).