Not only processing: How we made a distributed database from Kafka Streams, and what came of it
- Transfer
Hello, Habr!
We remind you that after the book on Kafka we released an equally interesting work on the Kafka Streams API library .

So far, the community is only comprehending the limits of this powerful tool. So, an article has recently been published, with the translation of which we want to introduce you. On his own experience, the author tells how to make a distributed data warehouse out of Kafka Streams. Enjoy reading!
The Apache Kafka Streams library worldwide is used in the enterprise for distributed streaming processing on top of Apache Kafka. One of the underestimated aspects of this framework is that it allows you to store a local state based on streaming processing.
In this article, I will tell you how our company managed to use this opportunity to the advantage in developing a product for the security of cloud applications. Using Kafka Streams, we created shared-service microservices, each of which serves as a fault-tolerant and highly accessible source of reliable information about the state of objects in the system. For us, this is a step forward both in terms of reliability and ease of support.
If you are interested in an alternative approach that allows you to use a single central database to support the formal state of your objects - read it, it will be interesting ...
Why did we find it time to change our approaches to working with shared state
We needed to maintain the state of various objects based on agent reports (for example: was the site attacked)? Before moving to Kafka Streams, we often relied on a single central database (+ service API) to manage our state. This approach has its drawbacks: in data-intensive situations, support for consistency and synchronization turns into a real challenge. The database may become a bottleneck, or it may be in a race condition and suffer from unpredictability.
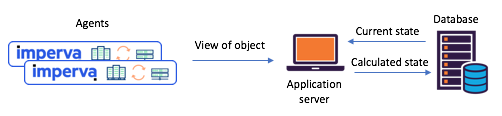
Figure 1: a typical scenario with state separation that occurred before the transition to
Kafka and Kafka Streams: agents communicate their views through the API, the updated state is calculated through a central database
Meet Kafka Streams - Now it’s just been easy to create shared-service microservices
About a year ago, we decided to thoroughly review our shared-state scenarios to deal with such problems. We immediately decided to try Kafka Streams - we know how scalable, highly available and fault-tolerant it is, how rich its streaming functionality is (transformations, including stateful ones). Just what we needed, not to mention how mature and reliable the messaging system was at Kafka.
Each of the state-preserving microservices that we created was built on the basis of the Kafka Streams instance with a fairly simple topology. It consisted of 1) a source 2) a processor with a permanent storage of keys and values 3) drain:

Figure 2: The default topology of our streaming instances for stateful microservices. Please note that there is also a repository that contains planning metadata.
With this new approach, agents compose messages that are submitted to the original topic, and consumers — say, a mail notification service — accept the calculated shared state through the stock (output topic).
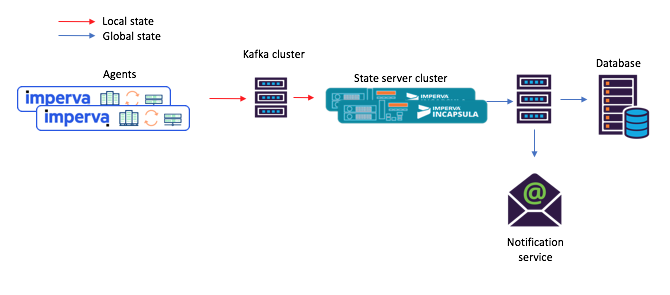
Figure 3: a new example of a task flow for a scenario with shared microservices: 1) the agent generates a message arriving in the original Kafka topic; 2) a microservice with a shared state (using Kafka Streams) processes it and writes the calculated state to the final Kafka topic; after which 3) consumers accept a new state
Hey, this built-in repository of keys and values is actually very useful!
As mentioned above, our shared-state topology contains a store of keys and values. We found several options for its use, and two of them are described below.
Option # 1: using the keystore and value store for calculations
Our first repository of keys and values contained auxiliary data that we needed for calculations. For example, in some cases, the shared state was determined on the basis of a “majority vote” principle. In the repository, you could keep all the latest agent reports on the state of a certain object. Then, receiving a new report from one or another agent, we could save it, extract reports from all other agents about the state of the same object from the repository, and repeat the calculation.
Figure 4 below shows how we opened access to the key and value store to the processing method of the processor, so that a new message could then be processed.
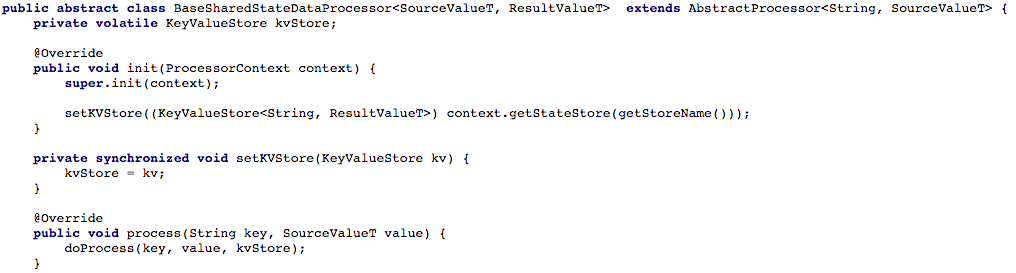
Figure 4: we open access to the key and value store for the processing method of the processor (after that, in each script working with a shared state, you must implement the method
Option # 2: creating a CRUD API on top of Kafka Streams
Having adjusted our basic task flow, we began to try to write RESTful CRUD API for our shared state microservices. We wanted to be able to retrieve the state of some or all of the objects, as well as set or delete the state of the object (this is useful with the support of the server side).
To support all Get State APIs, whenever we needed to recalculate the state during processing, we put it into the built-in repository of keys and values for a long time. In this case, it becomes quite simple to implement such an API using a single Kafka Streams instance, as shown in the listing below:
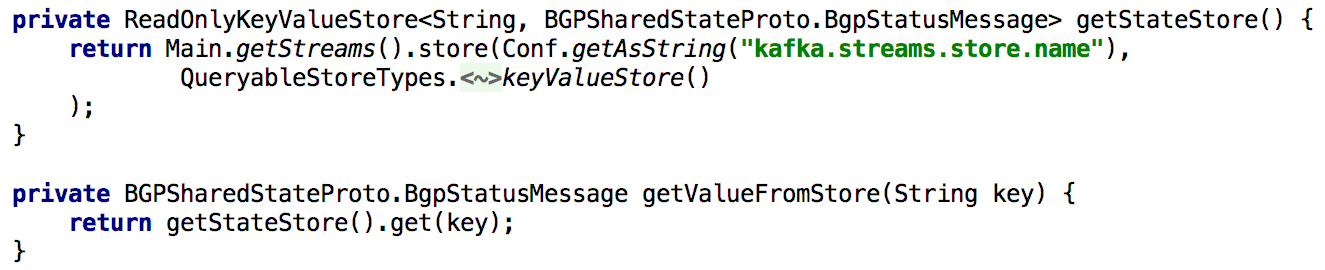
Figure 5: using the built-in storage of keys and values to obtain the pre-calculated state of the object
Updating the state of the object through the API is also easy to implement. In principle, for this you only need to create a producer Kafka, and with its help make a record in which a new state is made. This ensures that all messages generated through the API will be processed in the same way as received from other producers (e.g. agents).

Figure 6: You can set the state of an object using the Kafka producer.
A slight complication: Kafka has many partitions.
Next, we wanted to distribute the processing load and improve accessibility by providing a shared-service microservice cluster for each scenario. The setup was given to us as simple as possible: after we configured all the instances so that they worked with the same application ID (and with the same boot servers), almost everything else was done automatically. We also set that each source topic will consist of several partitions, so that each instance can be assigned a subset of such partitions.
I’ll also mention that it’s normal to make a backup copy of the state store so that, for example, in case of recovery after a failure, transfer this copy to another instance. For each state store in Kafka Streams, a replicated topic is created with a change log (in which local updates are tracked). Thus, Kafka constantly hedges the state store. Therefore, in the event of a failure of one or another Kafka Streams instance, the state store can be quickly restored on another instance, where the corresponding partitions will go. Our tests showed that this can be done in seconds even if there are millions of records in the repository.
Moving from one shared-service microservice to a cluster of microservices, it becomes less trivial to implement the Get State API. In the new situation, the state repository of each microservice contains only part of the overall picture (those objects whose keys were mapped to a particular partition). We had to determine on which instance the state of the object we needed was contained, and we did it based on the flow metadata, as shown below:
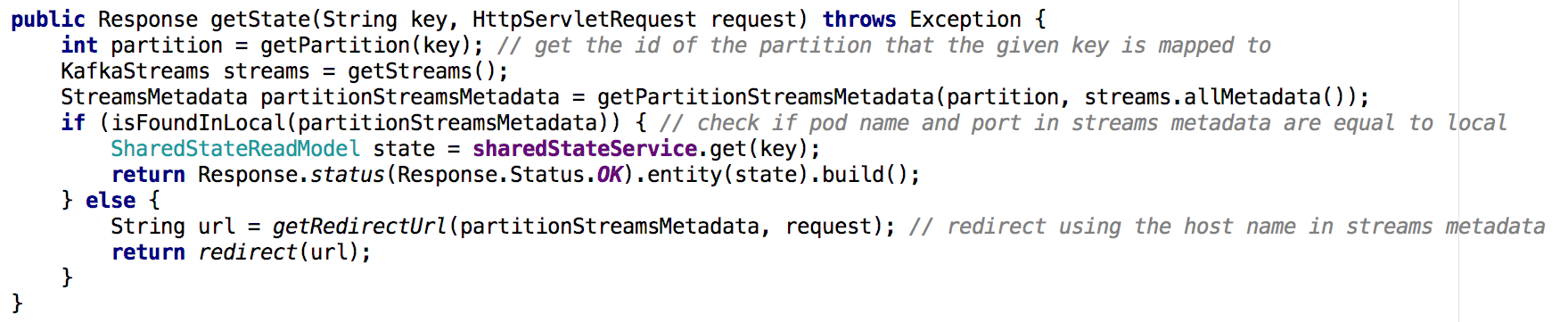
Figure 7: using the thread metadata, we determine from which instance to request the state of the desired object; a similar approach was used with the GET ALL API
Key findings
State stores in Kafka Streams can actually serve as a distributed database,
Thanks to these and other advantages, Kafka Streams is great for supporting global status in a distributed system like ours. Kafka Streams proved to be very reliable in production (from the moment of its deployment, we practically did not lose messages), and we are sure that this is not limited to its capabilities!
We remind you that after the book on Kafka we released an equally interesting work on the Kafka Streams API library .
So far, the community is only comprehending the limits of this powerful tool. So, an article has recently been published, with the translation of which we want to introduce you. On his own experience, the author tells how to make a distributed data warehouse out of Kafka Streams. Enjoy reading!
The Apache Kafka Streams library worldwide is used in the enterprise for distributed streaming processing on top of Apache Kafka. One of the underestimated aspects of this framework is that it allows you to store a local state based on streaming processing.
In this article, I will tell you how our company managed to use this opportunity to the advantage in developing a product for the security of cloud applications. Using Kafka Streams, we created shared-service microservices, each of which serves as a fault-tolerant and highly accessible source of reliable information about the state of objects in the system. For us, this is a step forward both in terms of reliability and ease of support.
If you are interested in an alternative approach that allows you to use a single central database to support the formal state of your objects - read it, it will be interesting ...
Why did we find it time to change our approaches to working with shared state
We needed to maintain the state of various objects based on agent reports (for example: was the site attacked)? Before moving to Kafka Streams, we often relied on a single central database (+ service API) to manage our state. This approach has its drawbacks: in data-intensive situations, support for consistency and synchronization turns into a real challenge. The database may become a bottleneck, or it may be in a race condition and suffer from unpredictability.
Figure 1: a typical scenario with state separation that occurred before the transition to
Kafka and Kafka Streams: agents communicate their views through the API, the updated state is calculated through a central database
Meet Kafka Streams - Now it’s just been easy to create shared-service microservices
About a year ago, we decided to thoroughly review our shared-state scenarios to deal with such problems. We immediately decided to try Kafka Streams - we know how scalable, highly available and fault-tolerant it is, how rich its streaming functionality is (transformations, including stateful ones). Just what we needed, not to mention how mature and reliable the messaging system was at Kafka.
Each of the state-preserving microservices that we created was built on the basis of the Kafka Streams instance with a fairly simple topology. It consisted of 1) a source 2) a processor with a permanent storage of keys and values 3) drain:
Figure 2: The default topology of our streaming instances for stateful microservices. Please note that there is also a repository that contains planning metadata.
With this new approach, agents compose messages that are submitted to the original topic, and consumers — say, a mail notification service — accept the calculated shared state through the stock (output topic).
Figure 3: a new example of a task flow for a scenario with shared microservices: 1) the agent generates a message arriving in the original Kafka topic; 2) a microservice with a shared state (using Kafka Streams) processes it and writes the calculated state to the final Kafka topic; after which 3) consumers accept a new state
Hey, this built-in repository of keys and values is actually very useful!
As mentioned above, our shared-state topology contains a store of keys and values. We found several options for its use, and two of them are described below.
Option # 1: using the keystore and value store for calculations
Our first repository of keys and values contained auxiliary data that we needed for calculations. For example, in some cases, the shared state was determined on the basis of a “majority vote” principle. In the repository, you could keep all the latest agent reports on the state of a certain object. Then, receiving a new report from one or another agent, we could save it, extract reports from all other agents about the state of the same object from the repository, and repeat the calculation.
Figure 4 below shows how we opened access to the key and value store to the processing method of the processor, so that a new message could then be processed.
Figure 4: we open access to the key and value store for the processing method of the processor (after that, in each script working with a shared state, you must implement the method
doProcess) Option # 2: creating a CRUD API on top of Kafka Streams
Having adjusted our basic task flow, we began to try to write RESTful CRUD API for our shared state microservices. We wanted to be able to retrieve the state of some or all of the objects, as well as set or delete the state of the object (this is useful with the support of the server side).
To support all Get State APIs, whenever we needed to recalculate the state during processing, we put it into the built-in repository of keys and values for a long time. In this case, it becomes quite simple to implement such an API using a single Kafka Streams instance, as shown in the listing below:
Figure 5: using the built-in storage of keys and values to obtain the pre-calculated state of the object
Updating the state of the object through the API is also easy to implement. In principle, for this you only need to create a producer Kafka, and with its help make a record in which a new state is made. This ensures that all messages generated through the API will be processed in the same way as received from other producers (e.g. agents).
Figure 6: You can set the state of an object using the Kafka producer.
A slight complication: Kafka has many partitions.
Next, we wanted to distribute the processing load and improve accessibility by providing a shared-service microservice cluster for each scenario. The setup was given to us as simple as possible: after we configured all the instances so that they worked with the same application ID (and with the same boot servers), almost everything else was done automatically. We also set that each source topic will consist of several partitions, so that each instance can be assigned a subset of such partitions.
I’ll also mention that it’s normal to make a backup copy of the state store so that, for example, in case of recovery after a failure, transfer this copy to another instance. For each state store in Kafka Streams, a replicated topic is created with a change log (in which local updates are tracked). Thus, Kafka constantly hedges the state store. Therefore, in the event of a failure of one or another Kafka Streams instance, the state store can be quickly restored on another instance, where the corresponding partitions will go. Our tests showed that this can be done in seconds even if there are millions of records in the repository.
Moving from one shared-service microservice to a cluster of microservices, it becomes less trivial to implement the Get State API. In the new situation, the state repository of each microservice contains only part of the overall picture (those objects whose keys were mapped to a particular partition). We had to determine on which instance the state of the object we needed was contained, and we did it based on the flow metadata, as shown below:
Figure 7: using the thread metadata, we determine from which instance to request the state of the desired object; a similar approach was used with the GET ALL API
Key findings
State stores in Kafka Streams can actually serve as a distributed database,
- continuously replicated in kafka
- On top of such a system is easily built CRUD API
- Processing multiple partitions is a bit more complicated
- It is also possible to add one or more state stores to the stream topology for storing auxiliary data. This option can be used for:
- Long-term storage of data needed for calculations in streaming processing
- Long-term storage of data that may be useful the next time the stream instance is initialized
- much more ...
Thanks to these and other advantages, Kafka Streams is great for supporting global status in a distributed system like ours. Kafka Streams proved to be very reliable in production (from the moment of its deployment, we practically did not lose messages), and we are sure that this is not limited to its capabilities!