The difficult principle of sole responsibility
- Transfer
Background
Over the past couple of years, I have participated in a large number of interviews. At each of them I asked the applicants about the principle of sole responsibility (hereinafter SRP). And most people do not know anything about the principle. And even of those who could read the definition, almost no one could say how they use this principle in their work. They could not say how SRP affects the code they write or the code review of colleagues. Some of them also had the misconception that SRP, like the whole SOLID, is relevant only to object-oriented programming. Also, often people could not identify obvious cases of violation of this principle, simply because the code was written in the style recommended by the well-known framework.
Redux is a prime example of a framework whose guideline violates SRP.
SRP matters
I want to start with the value of this principle, with the benefits that it brings. And also I want to note that the principle applies not only to OOP, but also to procedural programming, functional and even declarative. HTML, as a representative of the latter, can and should also be decomposed, especially now when it is controlled by UI frameworks such as React or Angular. In addition, the principle applies to other engineering areas. And not only engineering, there was such an expression in military subjects: “divide and conquer”, which by and large is the embodiment of the same principle. Complexity kills, divide it into parts and you will win.
Regarding other engineering areas, here on the hub, there was an interesting article about how the aircraft being developed failed engines, did not switch to reverse at the command of the pilot. The problem was that they misinterpreted the state of the chassis. Instead of relying on the systems controlling the chassis, the engine controller directly read the sensors, limit switches, etc. located in the chassis. It was also mentioned in the article that the engine must undergo lengthy certification before it is even put on a prototype aircraft. And violation of SRP in this case clearly led to the fact that when changing the design of the chassis, the code in the engine controller needed to be modified and re-certified. Even worse, a violation of this principle was almost worth the plane and the life of the pilot. Fortunately, our everyday programming does not threaten such consequences, however, you still should not neglect the principles of writing good code. And that's why:
- Decomposition of the code reduces its complexity. For example, if solving a problem requires you to write code with a cyclomatic complexity of four, then the method that is responsible for solving two such problems at the same time will require code with complexity 16. If it is divided into two methods, then the total complexity will be 8. Of course, this is not always comes down to the amount against the work, but the trend will be approximately the same anyway.
- Unit testing of decomposed code is simplified and more efficient.
- Decomposed code creates less resistance to change. When making changes, it is less likely to make a mistake.
- The code is getting better structured. Searching for something in code arranged in files and folders is much easier than in one big footcloth.
- Separation of boilerplate code from business logic leads to the fact that code generation can be applied in a project.
And all these signs go together, these are signs of the same code. You do not have to choose between, for example, well-tested code and well-structured code.
Existing definitions do not work
One of the definitions is: “there should be only one reason for changing the code (class or function)”. The problem with this definition is that it conflicts with the Open-Close principle, the second of the SOLID group of principles. Its definition: "the code must be open for extension and closed for change." One reason for change versus total ban on change. If we reveal in more detail what is meant here, it turns out that there is no conflict between the principles, but there is definitely a conflict between fuzzy definitions.
The second, more direct definition is: "the code should have only one responsibility." The problem with this definition is that it is human nature to generalize everything.
For example, there is a farm that grows chickens, and at that moment the farm has only one responsibility. And so the decision is made to breed ducks there too. Instinctively, we will call this a poultry farm, rather than admit that there are now two responsibilities. Add sheep there, and this is now a pet farm. Then we want to grow tomatoes or mushrooms there, and come up with the following even more generalized name. The same applies to the “one reason” for change. This reason can be as generalized as imagination suffices.
Another example is the space station manager class. He does nothing else, he only manages the space station. How do you like this class with one responsibility?
And, since I mentioned Redux when the job applicant is familiar with this technology, I also ask the question, does a typical SRP reducer violate?
The reducer, I recall, includes the switch statement, and it happens that it grows to tens or even hundreds of cases. And the sole responsibility of the reducer is to manage the state transitions of your application. That is, literally, some applicants answered. And no hints could move this opinion off the ground.
In total, if some kind of code seems to satisfy the SRP principle, but at the same time it smells unpleasant - know why this happens. Because the definition of “code must have one responsibility” simply does not work.
More appropriate definition
From trial and error, I came up with a better definition:
Code responsibility should not be too big
Yes, now we need to "measure" the responsibility of the class or function. And if it is too large, then you need to break this big responsibility into several smaller responsibilities. Returning to the farm example, even the responsibility for breeding chickens can be too big and it makes sense to somehow separate broilers from laying hens, for example.
But how to measure it, how to determine that the responsibility of this code is too big?
Unfortunately, I do not have mathematically accurate methods, only empirical ones. And most of all this comes with experience, novice developers are not at all able to decompose the code, more advanced ones are better at owning it, although they can’t always describe why they do it and how it falls on theories like SRP.
- Metric cyclomatic complexity. Unfortunately, there are ways to mask this metric, but if you collect it, then there is a chance that it will show the most vulnerable places in your application.
- The size of functions and classes. A 800-line function does not need to be read in order to understand that something is wrong with it.
- A lot of imports. Once I opened a file in the project of a neighboring team and saw a whole screen of imports, pressed page down and again there were only imports on the screen. Only after the second press I saw the beginning of the code. You can say that all modern IDEs can hide imports under the "plus sign", but I say that a good code does not need to hide the "smells". In addition, I needed to reuse a small piece of code and I removed it from this file to another, and a quarter or even a third of the imports moved behind this piece. This code clearly did not belong there.
- Unit tests. If you still have difficulty determining the amount of responsibility, force yourself to write tests. If two dozen tests need to be written for the main purpose of a function, not counting borderline cases, etc., then decomposition is needed.
- The same applies to too many preparatory steps at the beginning of the test and checks at the end. On the Internet, by the way, you can find the utopian statement that the so-called There should be only one assert in the test. I believe that any arbitrarily good idea, being raised to the absolute, can become absurdly impractical.
- Business logic should not directly depend on external tools. The Oracle driver, Express routes, it is desirable to separate all this from the business logic and / or hide behind the interfaces.
A couple of points:
Of course, as I already mentioned, there is a flip side to the coin, and 800 methods on one line may not be better than one method on 800 lines, there should be a balance in everything.
The second - I do not cover the question of where to put this or that code in accordance with its responsibility. For example, sometimes developers also have difficulties with pulling too much logic into the DAL layer.
Third, I do not propose any specific hard limits like “no more than 50 lines per function”. This approach involves only a direction for the development of developers, and maybe teams. He works for me, he must earn money for others.
And finally, if you go through TDD, this alone will surely make you decompose the code long before you write those 20 tests with 20 assertions each.
Separating business logic from boilerplate code
Talking about the rules of good code, you can not do without examples. The first example is about separating boilerplate code.
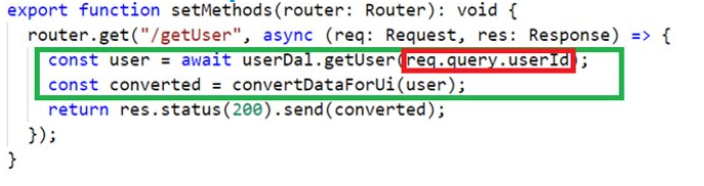
This example demonstrates how back-end code is usually written. People usually write logic inextricably with the code indicating parameters to the Web server Express such as URL, request method, etc.
I marked the business logic as the green marker, and the red interspersed code that interacts with query parameters (red).
I always share these two responsibilities in this way:

In this example, all interaction with Express is in a separate file.
At first glance, it might seem that the second example did not bring improvements, there were 2 files instead of one, additional lines appeared, which had not existed before - the class name and method signature. And then what does this separation of code give? First of all, the “application entry point” is no longer Express. Now this is a regular Typescript function. Or a javascript function, whether C #, who writes WebAPI on what.
This, in turn, allows you to perform various actions that are not available in the first example. For example, you can write behavior tests without having to raise Express, without using http requests inside the test. And even there is no need to make any kind of wetting, replace the Router object with your “test” object, now the application code can simply be called directly from the test.
Another interesting feature provided by this decomposition is that you can now write a code generator that will parse userApiService and generate code on its basis that connects this service with Express. In my future publications, I plan to indicate the following: code generation will not save time in the process of writing code. The costs of the code generator will not pay off by the fact that now you do not need to copy this boilerplate. Code generation will pay off by the fact that the code it produces does not need support, which will save time and, most importantly, the nerves of developers in the long term.
Divide and conquer
This method of writing code has existed for a long time, I did not invent it myself. I just came to the conclusion that it is very convenient when writing business logic. And for this, I came up with another fictitious example, showing how you can quickly and easily write code that is immediately well decomposed and also self-documented by naming methods.
Let's say you get a task from a business analyst to make a method that sends an employee report to an insurance company. For this:
- Data must be taken from the database
- Convert to desired format
- Send the resulting report
Such requirements are not always written explicitly, sometimes such a sequence may be implied or clarified from a conversation with the analyst. In the process of implementing the method, do not rush to open connections to the database or network, instead try translating this simple algorithm into the code "as is". Like that:
async function sendEmployeeReportToProvider(reportId){
const data = await dal.getEmployeeReportData(reportId);
const formatted = reportDataService.prepareEmployeeReport(data);
await networkService.sendReport(formatted);
}
With this approach, it turns out to be a fairly simple, easy to read and test code, although I believe that this code is trivial and does not need testing. And it was the responsibility of this method not to send a report, its responsibility was to split this complex task into three subtasks.
Next, we return to the requirements and find out that the report should consist of a salary section and a section with worked hours.
function prepareEmployeeReport(reportData){
const salarySection = prepareSalarySection(reportData);
const workHoursSection = prepareWorkHoursSection(reportData);
return { salarySection, workHoursSection };
}
And so on and on we continue to break up the task until the implementation of small methods that are close to trivial remains.
Interaction with the Open-Close Principle
At the beginning of the article I said that the definitions of the principles of SRP and Open-Close contradict each other. The first says that there must be one reason for the change, the second says that the code must be closed for the change. And the principles themselves, not only do not contradict each other, on the contrary, they work in synergy with each other. All 5 SOLID principles are aimed at one good goal - to tell the developer which code is “bad” and how to change it so that it becomes “good”. The irony - I just replaced 5 responsibilities with one more responsibility.
So, in addition to the previous example with sending the report to the insurance company, imagine that a business analyst comes to us and says that now we need to add a second functionality to the project. The same report must be printed.
Imagine that there is a developer who believes that SRP "is not about decomposition."
Accordingly, this principle did not indicate to him the need for decomposition, and he realized the entire first task in one function. After the task came to him, he combines the two responsibilities into one, because they have much in common and generalizes its name. Now this responsibility is called “service report.” The implementation of this looks something like this:
async function serveEmployeeReportToProvider(reportId, serveMethod){
/*
lots of code to read and convert the report
*/
switch(serveMethod) {
case sendToProvider:
/* implementation of sending */
case print:
/* implementation of printing */
default:
throw;
}
}
Reminds some code in your project? As I said, both direct definitions of SRP do not work. They do not transmit information to the developer that such code cannot be written. And what code can be written. There was still only one reason for the developer to change this code. He simply re-called the previous reason, added switch and is calm. And here the principle of Open-Close principle comes to the scene, which directly says that it was impossible to modify an existing file. It was necessary to write code so that when adding new functionality it was necessary to add a new file, and not edit an existing one. That is, such a code is bad from the point of view of two principles at once. And if the first did not help to see it, the second should help.
And how does the divide and conquer method solve the same problem:
async function printEmployeeReport(reportId){
const data = await dal.getEmployeeReportData(reportId);
const formatted = reportDataService.prepareEmployeeReport(data);
await printService.printReport(formatted);
}
Add a new function. I sometimes call them a “script function” because they do not carry implementations; they determine the sequence of calling decomposed pieces of our responsibility. Obviously, the first two lines, the first two decomposed responsibilities coincide with the first two lines of the previously implemented function. Just like the first two steps of two tasks described by a business analyst coincide.
Thus, to add new functionality to the project, we added a new script method and a new printService. Old files were not changed. That is, this method of writing code is good right from the point of view of two principles. And SRP and Open-Close
Alternative
I also wanted to mention an alternative, competing way to get a well decomposed code that looks something like this - first we write the code “on the forehead”, then refactor it using various techniques, for example, according to Fowler’s book “Refactoring”. These methods reminded me of the mathematical approach to the game of chess, where you do not understand what exactly you are doing in terms of strategy, you only calculate the "weight" of your position and try to maximize it by making moves. I did not like this approach for one small reason - to name methods and variables is already difficult, and when they do not have a business value, it becomes impossible. For example, if these techniques suggest that you need to select 6 identical lines from here and from there, then highlighting them, what should you call this method? someSixIdenticalLines ()?
I want to make a reservation - I do not think this method is bad, I just could not learn how to use it.
Total
In following the principle, you can find benefits.
The definition of “there must be one responsibility” does not work.
There is a better definition and a number of indirect features, the so-called code smells signaling the need to decompose.
The “divide and conquer” approach allows you to immediately write well-structured and self-documenting code.