NLP. The basics. Techniques. Self-development. Part 2: NER
The first part of the article on the basics of NLP can be read here . Today we’ll talk about one of the most popular NLP tasks - Named-Entity Recognition (NER) - and analyze in detail the architecture of solutions to this problem.
The task of NER is to highlight spans of entities in the text (span is a continuous fragment of text). Suppose there is a news text, and we want to highlight the entities in it (some pre-fixed set - for example, persons, locations, organizations, dates, and so on). The NER’s task is to understand that the portion of the text “ January 1, 1997 ” is the date, “ Kofi Annan ” is the person, and “ UN ” is the organization.

What are named entities? In the first, classic setting, which was formulated at the MUC-6 conference in 1995, these are persons, locations and organizations. Since then, several available packages have appeared, each of which has its own set of named entities. Typically, new entity types are added to persons, locations, and organizations. The most common of them are numerical (dates, monetary amounts), as well as Misc entities (from miscellaneous - other named entities; an example is iPhone 6).
It is easy to understand that, even if we are well able to identify people, locations, and organizations in the text, this is unlikely to cause great interest among customers. Although some practical application, of course, has the problem in the classical setting.
One of the scenarios when a solution to the problem in the classical formulation may still be needed is the structuring of unstructured data. Suppose you have some kind of text (or a set of texts), and the data from it must be entered into a database (table). Classic named entities can correspond to rows of such a table or serve as the content of some cells. Accordingly, in order to correctly fill out the table, you must first select in the text the data that you will enter into it (usually after this there is another step - identifying the entities in the text, when we understand that the UN and the United Nations spans”Refer to the same organization; however, the task of identification or entity linking is another task, and we will not talk about it in detail in this post).
However, there are several reasons why NER is one of the most popular NLP tasks.
First, extracting named entities is a step toward “understanding" the text. This can both have independent value, and help to better solve other NLP tasks.
So, if we know where the entities are highlighted in the text, then we can find fragments of the text that are important for some task. For example, we can select only those paragraphs where entities of a certain type are encountered, and then work only with them.
Suppose you receive a letter, and it would be nice to make a snippet only of that part where there is something useful, and not just “ Hello, Ivan Petrovich ”. If you can distinguish named entities, you can make the snippet smart by showing that part of the letter where the entities of interest to us are (and not just show the first sentence of the letter, as is often done). Or you can simply highlight in the text the necessary parts of the letter (or, directly, the entities that are important to us) for the convenience of analysts.
In addition, entities are rigid and reliable collocations; their selection can be important for many tasks. Suppose you have a name for a named entity and, whatever it is, most likely it is continuous, and all actions with it need to be performed as with a single block. For example, translate the name of an entity into the name of an entity. You want to translate “Pyaterochka Shop” into French in a single piece, and not split into several fragments that are not related to each other. The ability to detect collocations is also useful for many other tasks - for example, for syntactic parsing.
Without solving the NER problem, it’s hard to imagine the solution to many NLP problems, for example, resolving the pronoun anaphora or building question-answer systems. The pronoun anaphora allows us to understand to which element of the text the pronoun refers. For example, let us want to analyze the text “ Charming Galloped on a White Horse. The princess ran out to meet him and kissed him . " If we highlighted the essence of Persona on the word “Charming”, then the machine will be much easier to understand that the princess most likely kissed not the horse, but the prince of Charming.
Now we give an example of how the allocation of named entities can help in the construction of question-answer systems. If you ask the question “ Who played the role of Darth Vader in the movie“ The Empire Strikes Back ” in your favorite search engine", Then with a high probability you will get the right answer. This is done just by isolating named entities: we select the entities (film, role, etc.), understand what we are asked, and then look for the answer in the database.
Probably the most important consideration due to which the NER task is so popular: the problem statement is very flexible. In other words, no one forces us to single out locations, people, and organizations. We can select any continuous pieces of text we need that are somewhat different from the rest of the text. As a result, you can choose your own set of entities for a specific practical task coming from the customer, mark the body of texts with this set and train the model. Such a scenario is ubiquitous, and this makes NER one of the most frequently performed NLP tasks in the industry.
I’ll give a couple of examples of such cases from specific customers, in the solution of which I happened to take part.
Here is the first one: let you have a set of invoices (money transfers). Each invoice has a text description, which contains the necessary information about the transfer (who, whom, when, what, and for what reason sent). For example, company X transferred $ 10 to company Y on such and such a date for such and such. The text is quite formal, but written in living language. Banks have specially trained people who read this text and then enter the information contained in it into a database.
We can select a set of entities that correspond to the columns of the table in the database (company names, amount of transfer, its date, type of transfer, etc.) and learn how to automatically select them. After this, it remains only to enter the selected entities in the table, and people who previously read the texts and entered information into the database will be able to do more important and useful tasks.
The second user case is this: you need to analyze letters with orders from online stores. To do this, you need to know the order number (so that all letters related to this order can be marked or put in a separate folder), as well as other useful information - the name of the store, the list of goods that were ordered, the amount of the check, etc. All this - order numbers, store names, etc. - can be considered named entities, and it is also easy to learn how to distinguish them using the methods that we will now analyze.
Why is the NER task not always solved and commercial customers are still willing to pay not the smallest money for its solution? It would seem that everything is simple: to understand which piece of text to highlight, and highlight it.
But in life, everything is not so easy, various difficulties arise.
The classic complexity that prevents us from living in solving a variety of NLP problems is all sorts of ambiguities in the language. For example, polysemantic words and homonyms (see examples in part 1 ). There is a separate kind of homonymy that is directly related to the NER task - completely different entities can be called the same word. For example, let us have the word “ Washington ”" What is it? Person, city, state, store name, dog name, object, something else? To highlight this section of the text as a specific entity, one needs to take into account a lot - the local context (what the previous text was about), the global context (knowledge about the world). A person takes all this into account, but it is not easy to teach a machine to do this.
The second difficulty is technical, but do not underestimate it. No matter how you define an entity, most likely there will be some borderline and difficult cases - when you need to highlight an entity, when you do not need what to include in an entity, and what is not, etc. (of course, if our essence is not something slightly variable, such as an email; however, you can usually distinguish such trivial entities by trivial methods - write a regular expression and not think about any kind of machine learning).
Suppose, for example, we want to highlight the names of stores.
In the text “The Shop of Professional Metal Detectors Welcomes You ”, we almost certainly want to include the word “shop” in our essence - this is clearly part of the name.
Another example is “ You are welcomed by Volkhonka Prestige, your favorite brand store at affordable prices .” Probably, the word “store” should not be included in the annotation - this is clearly not part of the name, but simply its description. In addition, if you include this word in the name, you must also include the words “- your favorite,” and this, perhaps, I do not want to do at all.
Third example: “Nemo pet store writes to you". It is unclear whether the “pet store” is part of the name or not. In this example, it seems that any choice will be adequate. However, it is important that we need to make this choice and fix it in the instructions for markers, so that in all texts such examples are labeled the same way (if this is not done, machine learning will inevitably begin to make mistakes due to contradictions in the markup).
There are many such borderline examples, and if we want the marking to be consistent, all of them need to be included in the instructions for the markers. Even if the examples themselves are simple, they need to be taken into account and calculated, and this will make the instruction bigger and more complicated.
Well, the more complicated the instructions, there you need more qualified markers. It is one thing when the scribe needs to determine whether the letter is the text of the order or not (although there are subtleties and boundary cases here), and it is another thing when the scribe needs to read the 50-page instructions, find specific entities, understand what to include in annotation and what not.
Skilled markers are expensive, and they usually do not work very quickly. You will spend the money for sure, but it’s not at all a fact that you get the perfect markup, because if the instructions are complex, even a qualified person can make a mistake and misunderstand something. To combat this, multiple markup of the same text by different people is used, which further increases the markup price and the time for which it is prepared. Avoiding this process or even seriously reducing it will not work: in order to learn, you need to have a high-quality training set of reasonable sizes.
These are the two main reasons why NER has not yet conquered the world and why apple trees still do not grow on Mars.
I’ll tell you a little about the metrics that people use to evaluate the quality of their solution to the NER problem, and about standard cases.
The main metric for our task is a strict f-measure. Explain what it is.
Let us have a test markup (the result of the work of our system) and a standard (correct markup of the same texts). Then we can count two metrics - accuracy and completeness. Accuracy is the fraction of true positive entities (i.e. entities selected by us in the text, which are also present in the standard), relative to all entities selected by our system. And completeness is the fraction of true positive entities with respect to all entities present in the standard. An example of a very accurate, but incomplete classifier is a classifier that selects one correct object in the text and nothing else. An example of a very complete, but generally inaccurate classifier is a classifier that selects an entity on any segment of the text (thus, in addition to all standard entities, our classifier allocates a huge amount of garbage).
The F-measure is the harmonic mean of accuracy and completeness, a standard metric.
As we described in the previous section, creating markup is expensive. Therefore, there are not very many accessible buildings with a markup.
There is some variety for the English language - there are popular conferences where people compete in solving the NER problem (and markup is created for the competitions). Examples of such conferences at which their bodies with named entities were created are MUC, TAC, CoNLL. All of these cases consist almost exclusively of news texts.
The main body on which the quality of solving the NER problem is evaluated is the CoNLL 2003 case (here is a link to the case itself , here is an article about it) There are approximately 300 thousand tokens and up to 10 thousand entities. Now SOTA-systems (state of the art - that is, the best results at the moment) show on this case an f-measure of the order of 0.93.
For the Russian language, everything is much worse. There is one public body ( FactRuEval 2016 , here is an article about it , here is an article on Habré ), and it is very small - there are only 50 thousand tokens. In this case, the case is quite specific. In particular, the rather controversial essence of LocOrg (location in an organizational context) stands out in the case, which is confused with both organizations and locations, as a result of which the quality of the selection of the latter is lower than it could be.
Despite the fact that entities are often verbose, the NER task usually comes down to the classification problem at the token level, i.e., each token belongs to one of several possible classes. There are several standard ways to do this, but the most common one is called a BIOES scheme. The scheme is to add some prefix to the entity label (for example, PER for persons or ORG for organizations), which indicates the position of the token in the entity’s span. In more detail:
B - from the word beginning - the first token in the entity’s span, which consists of more than 1 word.
I - from the words inside - this is what is in the middle.
E - from the word ending, this is the last token of the entity, which consists of more than 1 element.
S is single. We add this prefix if the entity consists of one word.
Thus, we add one of 4 possible prefixes to each type of entity. If the token does not belong to any entity, it is marked with a special label, usually labeled OUT or O.
Here is an example. Let us have the text “ Karl Friedrich Jerome von Munchausen was born in Bodenwerder .” Here there is one verbose entity - the person “Karl Friedrich Jerome von Münhausen” and one one-word one - the location “Bodenwerder”.
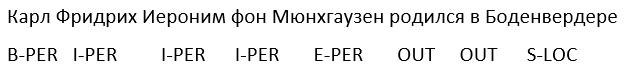
Thus, BIOES is a way to map projections of spans or annotations to the token level.
It is clear that by this markup we can unambiguously establish the boundaries of all entity annotations. Indeed, about each token, we know whether it is true that an entity begins with this token or ends on it, which means whether to end the entity's annotation on a given token, or expand it to the next tokens.
The vast majority of researchers use this method (or its variations with fewer labels - BIOE or BIO), but it has several significant drawbacks. The main one is that the scheme does not allow working with nested or intersecting entities. For example, the essence of “ Moscow State University named after M.V. Lomonosov”Is one organization. But Lomonosov himself is a person, and it would also be nice to ask in the markup. Using the markup method described above, we can never convey both of these facts at the same time (because we can only make one mark on one token). Accordingly, the “Lomonosov” token can be either part of the annotation of the organization, or part of the annotation of the person, but never both at the same time.
Another example of embedded entities: “ Department of Mathematical Logic and Algorithm Theory of the Mechanics and Mathematics Faculty of Moscow State University ”. Here, ideally, I would like to distinguish 3 nested organizations, but the above markup method allows you to select either 3 disjoint entities, or one entity that annotates the entire fragment.
In addition to the standard way to reduce the task to classification at the token level, there is also a standard data format in which it is convenient to store markup for the NER task (as well as for many other NLP tasks). This format is called CoNLL-U .
The main idea of the format is this: we store the data in the form of a table, where one row corresponds to one token, and the columns correspond to a specific type of token attributes (including the word itself, the word form). In a narrow sense, the CoNLL-U format defines which types of features (i.e. columns) are included in the table — a total of 10 types of features for each token. But researchers usually consider the format more broadly and include those types of features that are needed for a particular task and a method for solving it.
Below is an example of data in a CoNLL-U-like format, where 6 types of attributes are considered: number of the current sentence in the text, word form (i.e. the word itself), lemma (initial word form), POS tag (part of speech), morphological characteristics of the word and, finally, the label of the entity allocated on this token.

Strictly speaking, the problem can be solved without machine learning - with the help of rule-based systems (in the simplest version - with the help of regular expressions). This seems outdated and ineffective, but you need to understand if your subject area is limited and clearly defined and if the entity, by itself, does not have a lot of variability, then the NER problem is solved using rule-based methods fairly quickly and efficiently.
For example, if you need to highlight emails or numerical entities (dates, money or phone numbers), regular expressions can lead you to success faster than trying to solve a problem using machine learning.
However, as soon as linguistic ambiguities of various kinds come into play (we wrote about some of them above), such simple methods cease to work well. Therefore, it makes sense to use them only for limited domains and on entities that are simple and clearly separable from the rest of the text.
Despite all of the above, at the academic buildings until the end of the 2000s, SOTA showed systems based on classical methods of machine learning. Let's take a quick look at how they worked.
Before embeddings appeared, the main sign of the token was usually the word form - i.e., the index of the word in the dictionary. Thus, each token is assigned a Boolean vector of large dimension (dictionary dimension), where in the place of the word index in the dictionary is 1, and in the rest places are 0.
In addition to the word form, parts of speech (POS-tags) were often used as signs of the token , morphological characters (for languages without rich morphology - for example, English, morphological characters have practically no effect), prefixes (i.e., the first few characters of the word), suffixes (similarly, the last few characters of the token), the presence of special characters in token and the appearance of the token.
In classical settings, a very important sign of a token is the type of its capitalization, for example:
If the token has a non-standard capitalization, it is very likely that it can be concluded that the token is some kind of entity, and the type of this entity is hardly a person or location.
In addition to all this, newspapers - dictionaries of entities were actively used. We know that Petya, Elena, Akaki are the names, Ivanov, Rustaveli, von Goethe are the names, and Mytishchi, Barcelona, Sao Paulo are the cities. It is important to note that entity dictionaries alone do not solve the problem (“Moscow” can be part of the organization’s name, and “Elena” can be part of the location), but they can improve its solution. However, of course, despite the ambiguity, the token's belonging to a dictionary of entities of a certain type is a very good and significant attribute (so significant that usually the results of solving the NER problem are divided into 2 categories - with and without newspaper people).
If you are interested in how people solved the NER problem when the trees were large, I advise you to see the articleNadeau and Sekine (2007), A survey of Named Entity Recognition and Classification . The methods described there are, of course, outdated (even if you cannot use neural networks due to performance limitations, you probably will not use HMM, as described in the article, but, let’s say, gradient boosting), but look at the description of symptoms may make sense.
Interesting features include capitalization patterns (summarized pattern in the article above). They can still help with some NLP tasks. So, in 2018, there was a successful attempt to apply capitalization patterns (word shape) to neural network methods for solving the problem.
The first successful attempt to solve the NER problem using neural networks was made in 2011 .
At the time of the publication of this article, she showed a SOTA result on the CoNLL 2003 package. But you need to understand that the superiority of the model compared to systems based on classical machine learning algorithms was quite insignificant. In the next few years, methods based on classical ML showed results comparable to neural network methods.
In addition to describing the first successful attempt to solve the NER problem with the help of neural networks, the article describes in detail many points that most of the works on the topic of NLP are left out of the picture. Therefore, despite the fact that the architecture of the neural network described in the article is outdated, it makes sense to read the article. This will help to understand the basic approaches to neural networks used in solving the NER problem (and more broadly, many other NLP tasks).
We will tell you more about the architecture of the neural network described in the article.
The authors introduce two varieties of architecture that correspond to two different ways to take into account the context of the token:
In both cases, the used signs are embeddings of word forms, as well as some manual signs - capitalization, parts of speech, etc. We will tell you more about how they are calculated.
We got an input list of words from our sentence: for example, “ The cat sat on the mat ”.
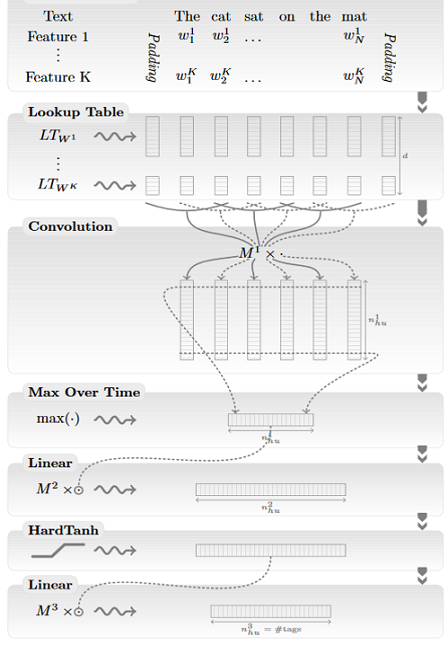
Suppose that there are K different signs for one token (for example, the word form, part of speech, capitalization, whether our token is the first or last in the sentence, etc., can act as such signs). We can consider all these signs categorical (for example, the word form corresponds to a Boolean vector of length of the dictionary dimension, where 1 is only on the coordinate of the corresponding index of the word in the dictionary). Let be a Boolean vector corresponding to the value of the ith attribute of the jth token in the sentence.
a Boolean vector corresponding to the value of the ith attribute of the jth token in the sentence.
It is important to note that in the sentence based approach, in addition to the categorical features determined by the words, the feature is used - a shift relative to the token, the label of which we are trying to determine. The value of this attribute for the token number i will be i-core, where core is the number of the token whose label we are trying to determine at the moment (this attribute is also considered categorical, and the vectors for it are calculated in the same way as for the others).
The next step in finding the signs of a token is to multiply eachby a matrix 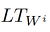 called the Lookup Table (in this way Boolean vectors “turn” into continuous ones). Recall that each of them is a Boolean vector in which there is 1 in one place and 0. in other places. Thus, when multiplied by, one of the rows in our matrix is selected. This line is the embedding of the corresponding token feature. Matrices (where i can take values from 1 to K) are the parameters of our network, which we train together with the rest of the layers of the neural network.
called the Lookup Table (in this way Boolean vectors “turn” into continuous ones). Recall that each of them is a Boolean vector in which there is 1 in one place and 0. in other places. Thus, when multiplied by, one of the rows in our matrix is selected. This line is the embedding of the corresponding token feature. Matrices (where i can take values from 1 to K) are the parameters of our network, which we train together with the rest of the layers of the neural network.
The difference between the method of working with categorical features described in this article and the word2vec that appeared later (we talked about how word2vec word-form embeddings are pre-trained in the previous part of our post) is that matrices are initialized randomly here, and in word2vec matrices are pre-trained on a large case on the task of determining a word by context (or context by word).
Thus, for each token, a continuous vector of features is obtained, which is a concatenation of the results of multiplying all kinds ofon .
Now we will understand how these signs are used in the sentence based approach (window based is ideologically simpler). It is important that we will launch our architecture separately for each token (that is, for the sentence “The cat sat on the mat” we will launch our network 6 times). The signs in each run are collected the same, with the exception of the sign responsible for the position of the token whose label we are trying to determine - the core token.
We take the resulting continuous vectors of each token and pass them through a one-dimensional convolution with filters of not very large dimension: 3-5. The dimension of the filter corresponds to the size of the context that the network simultaneously takes into account, and the number of channels corresponds to the dimension of the source continuous vectors (the sum of the dimensions of the embeddings of all the attributes). After applying the convolution, we get a matrix of dimension m by f, where m is the number of ways the filter can be applied to our data (i.e., the length of the sentence minus the length of the filter plus one), and f is the number of filters used.
As almost always when working with convolutions, after convolution we use pooling - in this case max pooling (i.e., for each filter we take the maximum of its value on the whole sentence), after which we get a vector of dimension f. Thus, all the information contained in the sentence, which we may need when determining the label of the core token, is compressed into one vector (max pooling was chosen because it is not the information average on the sentence that is important to us, but the values of attributes in its most important areas) . This “flattened context” allows us to collect the signs of our token throughout the sentence and use this information to determine which label the core token should receive.
Next, we pass the vector through a multilayer perceptron with some activation functions (in the article - HardTanh), and as the last layer we use a fully connected softmax of dimension d, where d is the number of possible token labels.
Thus, the convolutional layer allows us to collect the information contained in the filter dimension window, pooling - select the most characteristic information in the sentence (compressing it into one vector), and the softmax layer - allows you to determine which label has the core number token.
Now let's talk about the architecture of CharCNN-BLSTM-CRF, that is, about what was SOTA in the period 2016-2018 (in 2018 there were architectures based on embeddings on language models, after which the NLP world will never be the same; but this saga is not about this). As applied to the NER task, architecture was first described in articles by Lample et al (2016) and Ma & Hovy (2016) .
The first layers of the network are the same as in the NLP pipeline described in the previous part of our post .
First, a context-independent attribute of each token in the sentence is calculated. Symptoms are usually collected from three sources. The first is the word-form embedding of the token, the second is symbolic signs, the third is additional signs: information about capitalization, part of speech, etc. Concatenation of all these signs makes up a context-independent token sign.
We talked about word-form embeddings in detail in the previous part. We listed additional features, but we did not say exactly how they are embedded in the neural network. The answer is simple - for each category of additional features, we learn from scratch embedding is not very large. These are exactly the Lookup tables from the previous paragraph, and we teach them exactly the same way as described there.
Now we will tell how symbolic signs are arranged.
First answer the question, what is it. It's simple - we want for each token to get a vector of signs of constant size, which depends only on the symbols that make up the token (and does not depend on the meaning of the token and additional attributes, such as part of speech).
We now turn to the description of the CharCNN architecture (as well as the CharRNN architecture associated with it). We are given a token, which consists of some characters. For each symbol we will issue a vector of some not very large dimension (for example, 20) - symbol embedding. Symbolic embeddings can be pre-trained, but most often they learn from scratch - there are a lot of symbols even in a not very large case, and symbolic embeddings should be adequately trained.
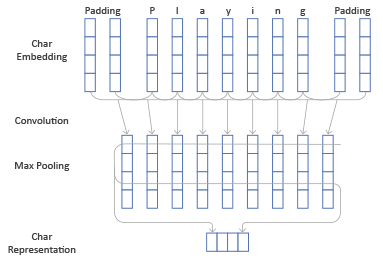
So, we have embeddings of all the symbols of our token, as well as additional symbols that indicate the borders of the token - paddings (usually embeddings of paddings are initialized with zeros). We would like to obtain from these vectors a single vector of some constant dimension, which is a symbolic sign of the entire token and reflects the interaction between these symbols.
There are 2 standard methods.
A slightly more popular of them is to use one-dimensional convolutions (therefore this part of the architecture is called CharCNN). We do this in the same way as we did with the words in the sentence based approach in the previous architecture.
So, we pass the embeddings of all the characters through a convolution with filters of not very large dimensions (for example, 3), we get a vector of dimension of the number of filters. We produce max pooling above these vectors, we get 1 vector of dimension of the number of filters. It contains information about the symbols of the word and their interaction and will be the vector of symbolic signs of the token.
The second way to turn symbolic embeddings into one vector is to feed them into a bilateral recurrent neural network (BLSTM or BiGRU; what it is, we described in the first part of our post ). Usually a symbolic sign of a token is simply a concatenation of the last states of the forward and reverse RNN.
So, let us be given a context-independent token feature vector. According to it, we want to get a context-sensitive attribute.
This is done using BLSTM or BiGRU. At the ith time moment, the layer produces a vector, which is a concatenation of the corresponding outputs of the forward and reverse RNN. This vector contains information both about previous tokens in the offer (it is in the direct RNN), and about the following (it is in the reverse RNN). Therefore, this vector is a context-sensitive sign of the token.
This architecture can be used in a wide variety of NLP tasks, and is therefore considered an important part of the NLP pipeline.
We return, however, to the NER problem. Having received context-sensitive signs of all tokens, we want to get the correct label for each token. This can be done in many ways.
A simpler and more obvious way is to use, as the last layer, a dimension d, fully connected with softmax, where d is the number of possible token labels. Thus, we get the probabilities of the token to have each of the possible labels (and we can choose the most probable of them).
This method works, however, it has a significant drawback - the token label is calculated independently of the labels of other tokens. We consider neighboring tokens themselves due to BiRNN, but the token label depends not only on neighboring tokens, but also on their labels. For example, regardless of tokens, the I-PER label occurs only after B-PER or I-PER.
The standard way to account for the interaction between label types is to use CRF (conditional random fields). We will not describe in detail what it is ( herea good description is given), but we mention that CRF optimizes the entire label chain as a whole, and not every element in this chain.
So, we described the CharCNN-BLSTM-CRF architecture, which was SOTA in the NER task until the advent of embeddings on language models in 2018.
In conclusion, let's talk a little about the significance of each element of architecture. For English, CharCNN gives an increase in f-measure by about 1%, CRF - by 1-1.5%, and additional signs of the token do not lead to quality improvement (unless you use more complex techniques such as multi-task learning, as in Wu et al (2018) ). BiRNN is the basis of architecture, which, however, can be replaced by a transformer .
We hope that we were able to give readers some idea of the NER problem. Although this is an important task, it is quite simple, which allowed us to describe its solution in a single post.
Ivan Smurov,
Head of NLP Advanced Research Group
The task of NER is to highlight spans of entities in the text (span is a continuous fragment of text). Suppose there is a news text, and we want to highlight the entities in it (some pre-fixed set - for example, persons, locations, organizations, dates, and so on). The NER’s task is to understand that the portion of the text “ January 1, 1997 ” is the date, “ Kofi Annan ” is the person, and “ UN ” is the organization.
What are named entities? In the first, classic setting, which was formulated at the MUC-6 conference in 1995, these are persons, locations and organizations. Since then, several available packages have appeared, each of which has its own set of named entities. Typically, new entity types are added to persons, locations, and organizations. The most common of them are numerical (dates, monetary amounts), as well as Misc entities (from miscellaneous - other named entities; an example is iPhone 6).
Why do you need to solve the NER problem
It is easy to understand that, even if we are well able to identify people, locations, and organizations in the text, this is unlikely to cause great interest among customers. Although some practical application, of course, has the problem in the classical setting.
One of the scenarios when a solution to the problem in the classical formulation may still be needed is the structuring of unstructured data. Suppose you have some kind of text (or a set of texts), and the data from it must be entered into a database (table). Classic named entities can correspond to rows of such a table or serve as the content of some cells. Accordingly, in order to correctly fill out the table, you must first select in the text the data that you will enter into it (usually after this there is another step - identifying the entities in the text, when we understand that the UN and the United Nations spans”Refer to the same organization; however, the task of identification or entity linking is another task, and we will not talk about it in detail in this post).
However, there are several reasons why NER is one of the most popular NLP tasks.
First, extracting named entities is a step toward “understanding" the text. This can both have independent value, and help to better solve other NLP tasks.
So, if we know where the entities are highlighted in the text, then we can find fragments of the text that are important for some task. For example, we can select only those paragraphs where entities of a certain type are encountered, and then work only with them.
Suppose you receive a letter, and it would be nice to make a snippet only of that part where there is something useful, and not just “ Hello, Ivan Petrovich ”. If you can distinguish named entities, you can make the snippet smart by showing that part of the letter where the entities of interest to us are (and not just show the first sentence of the letter, as is often done). Or you can simply highlight in the text the necessary parts of the letter (or, directly, the entities that are important to us) for the convenience of analysts.
In addition, entities are rigid and reliable collocations; their selection can be important for many tasks. Suppose you have a name for a named entity and, whatever it is, most likely it is continuous, and all actions with it need to be performed as with a single block. For example, translate the name of an entity into the name of an entity. You want to translate “Pyaterochka Shop” into French in a single piece, and not split into several fragments that are not related to each other. The ability to detect collocations is also useful for many other tasks - for example, for syntactic parsing.
Without solving the NER problem, it’s hard to imagine the solution to many NLP problems, for example, resolving the pronoun anaphora or building question-answer systems. The pronoun anaphora allows us to understand to which element of the text the pronoun refers. For example, let us want to analyze the text “ Charming Galloped on a White Horse. The princess ran out to meet him and kissed him . " If we highlighted the essence of Persona on the word “Charming”, then the machine will be much easier to understand that the princess most likely kissed not the horse, but the prince of Charming.
Now we give an example of how the allocation of named entities can help in the construction of question-answer systems. If you ask the question “ Who played the role of Darth Vader in the movie“ The Empire Strikes Back ” in your favorite search engine", Then with a high probability you will get the right answer. This is done just by isolating named entities: we select the entities (film, role, etc.), understand what we are asked, and then look for the answer in the database.
Probably the most important consideration due to which the NER task is so popular: the problem statement is very flexible. In other words, no one forces us to single out locations, people, and organizations. We can select any continuous pieces of text we need that are somewhat different from the rest of the text. As a result, you can choose your own set of entities for a specific practical task coming from the customer, mark the body of texts with this set and train the model. Such a scenario is ubiquitous, and this makes NER one of the most frequently performed NLP tasks in the industry.
I’ll give a couple of examples of such cases from specific customers, in the solution of which I happened to take part.
Here is the first one: let you have a set of invoices (money transfers). Each invoice has a text description, which contains the necessary information about the transfer (who, whom, when, what, and for what reason sent). For example, company X transferred $ 10 to company Y on such and such a date for such and such. The text is quite formal, but written in living language. Banks have specially trained people who read this text and then enter the information contained in it into a database.
We can select a set of entities that correspond to the columns of the table in the database (company names, amount of transfer, its date, type of transfer, etc.) and learn how to automatically select them. After this, it remains only to enter the selected entities in the table, and people who previously read the texts and entered information into the database will be able to do more important and useful tasks.
The second user case is this: you need to analyze letters with orders from online stores. To do this, you need to know the order number (so that all letters related to this order can be marked or put in a separate folder), as well as other useful information - the name of the store, the list of goods that were ordered, the amount of the check, etc. All this - order numbers, store names, etc. - can be considered named entities, and it is also easy to learn how to distinguish them using the methods that we will now analyze.
If NER is so useful, why isn’t it used everywhere?
Why is the NER task not always solved and commercial customers are still willing to pay not the smallest money for its solution? It would seem that everything is simple: to understand which piece of text to highlight, and highlight it.
But in life, everything is not so easy, various difficulties arise.
The classic complexity that prevents us from living in solving a variety of NLP problems is all sorts of ambiguities in the language. For example, polysemantic words and homonyms (see examples in part 1 ). There is a separate kind of homonymy that is directly related to the NER task - completely different entities can be called the same word. For example, let us have the word “ Washington ”" What is it? Person, city, state, store name, dog name, object, something else? To highlight this section of the text as a specific entity, one needs to take into account a lot - the local context (what the previous text was about), the global context (knowledge about the world). A person takes all this into account, but it is not easy to teach a machine to do this.
The second difficulty is technical, but do not underestimate it. No matter how you define an entity, most likely there will be some borderline and difficult cases - when you need to highlight an entity, when you do not need what to include in an entity, and what is not, etc. (of course, if our essence is not something slightly variable, such as an email; however, you can usually distinguish such trivial entities by trivial methods - write a regular expression and not think about any kind of machine learning).
Suppose, for example, we want to highlight the names of stores.
In the text “The Shop of Professional Metal Detectors Welcomes You ”, we almost certainly want to include the word “shop” in our essence - this is clearly part of the name.
Another example is “ You are welcomed by Volkhonka Prestige, your favorite brand store at affordable prices .” Probably, the word “store” should not be included in the annotation - this is clearly not part of the name, but simply its description. In addition, if you include this word in the name, you must also include the words “- your favorite,” and this, perhaps, I do not want to do at all.
Third example: “Nemo pet store writes to you". It is unclear whether the “pet store” is part of the name or not. In this example, it seems that any choice will be adequate. However, it is important that we need to make this choice and fix it in the instructions for markers, so that in all texts such examples are labeled the same way (if this is not done, machine learning will inevitably begin to make mistakes due to contradictions in the markup).
There are many such borderline examples, and if we want the marking to be consistent, all of them need to be included in the instructions for the markers. Even if the examples themselves are simple, they need to be taken into account and calculated, and this will make the instruction bigger and more complicated.
Well, the more complicated the instructions, there you need more qualified markers. It is one thing when the scribe needs to determine whether the letter is the text of the order or not (although there are subtleties and boundary cases here), and it is another thing when the scribe needs to read the 50-page instructions, find specific entities, understand what to include in annotation and what not.
Skilled markers are expensive, and they usually do not work very quickly. You will spend the money for sure, but it’s not at all a fact that you get the perfect markup, because if the instructions are complex, even a qualified person can make a mistake and misunderstand something. To combat this, multiple markup of the same text by different people is used, which further increases the markup price and the time for which it is prepared. Avoiding this process or even seriously reducing it will not work: in order to learn, you need to have a high-quality training set of reasonable sizes.
These are the two main reasons why NER has not yet conquered the world and why apple trees still do not grow on Mars.
How to understand whether the NER problem has been solved in a quality manner
I’ll tell you a little about the metrics that people use to evaluate the quality of their solution to the NER problem, and about standard cases.
The main metric for our task is a strict f-measure. Explain what it is.
Let us have a test markup (the result of the work of our system) and a standard (correct markup of the same texts). Then we can count two metrics - accuracy and completeness. Accuracy is the fraction of true positive entities (i.e. entities selected by us in the text, which are also present in the standard), relative to all entities selected by our system. And completeness is the fraction of true positive entities with respect to all entities present in the standard. An example of a very accurate, but incomplete classifier is a classifier that selects one correct object in the text and nothing else. An example of a very complete, but generally inaccurate classifier is a classifier that selects an entity on any segment of the text (thus, in addition to all standard entities, our classifier allocates a huge amount of garbage).
The F-measure is the harmonic mean of accuracy and completeness, a standard metric.
As we described in the previous section, creating markup is expensive. Therefore, there are not very many accessible buildings with a markup.
There is some variety for the English language - there are popular conferences where people compete in solving the NER problem (and markup is created for the competitions). Examples of such conferences at which their bodies with named entities were created are MUC, TAC, CoNLL. All of these cases consist almost exclusively of news texts.
The main body on which the quality of solving the NER problem is evaluated is the CoNLL 2003 case (here is a link to the case itself , here is an article about it) There are approximately 300 thousand tokens and up to 10 thousand entities. Now SOTA-systems (state of the art - that is, the best results at the moment) show on this case an f-measure of the order of 0.93.
For the Russian language, everything is much worse. There is one public body ( FactRuEval 2016 , here is an article about it , here is an article on Habré ), and it is very small - there are only 50 thousand tokens. In this case, the case is quite specific. In particular, the rather controversial essence of LocOrg (location in an organizational context) stands out in the case, which is confused with both organizations and locations, as a result of which the quality of the selection of the latter is lower than it could be.
How to solve the NER problem
Reduction of the NER problem to the classification problem
Despite the fact that entities are often verbose, the NER task usually comes down to the classification problem at the token level, i.e., each token belongs to one of several possible classes. There are several standard ways to do this, but the most common one is called a BIOES scheme. The scheme is to add some prefix to the entity label (for example, PER for persons or ORG for organizations), which indicates the position of the token in the entity’s span. In more detail:
B - from the word beginning - the first token in the entity’s span, which consists of more than 1 word.
I - from the words inside - this is what is in the middle.
E - from the word ending, this is the last token of the entity, which consists of more than 1 element.
S is single. We add this prefix if the entity consists of one word.
Thus, we add one of 4 possible prefixes to each type of entity. If the token does not belong to any entity, it is marked with a special label, usually labeled OUT or O.
Here is an example. Let us have the text “ Karl Friedrich Jerome von Munchausen was born in Bodenwerder .” Here there is one verbose entity - the person “Karl Friedrich Jerome von Münhausen” and one one-word one - the location “Bodenwerder”.
Thus, BIOES is a way to map projections of spans or annotations to the token level.
It is clear that by this markup we can unambiguously establish the boundaries of all entity annotations. Indeed, about each token, we know whether it is true that an entity begins with this token or ends on it, which means whether to end the entity's annotation on a given token, or expand it to the next tokens.
The vast majority of researchers use this method (or its variations with fewer labels - BIOE or BIO), but it has several significant drawbacks. The main one is that the scheme does not allow working with nested or intersecting entities. For example, the essence of “ Moscow State University named after M.V. Lomonosov”Is one organization. But Lomonosov himself is a person, and it would also be nice to ask in the markup. Using the markup method described above, we can never convey both of these facts at the same time (because we can only make one mark on one token). Accordingly, the “Lomonosov” token can be either part of the annotation of the organization, or part of the annotation of the person, but never both at the same time.
Another example of embedded entities: “ Department of Mathematical Logic and Algorithm Theory of the Mechanics and Mathematics Faculty of Moscow State University ”. Here, ideally, I would like to distinguish 3 nested organizations, but the above markup method allows you to select either 3 disjoint entities, or one entity that annotates the entire fragment.
In addition to the standard way to reduce the task to classification at the token level, there is also a standard data format in which it is convenient to store markup for the NER task (as well as for many other NLP tasks). This format is called CoNLL-U .
The main idea of the format is this: we store the data in the form of a table, where one row corresponds to one token, and the columns correspond to a specific type of token attributes (including the word itself, the word form). In a narrow sense, the CoNLL-U format defines which types of features (i.e. columns) are included in the table — a total of 10 types of features for each token. But researchers usually consider the format more broadly and include those types of features that are needed for a particular task and a method for solving it.
Below is an example of data in a CoNLL-U-like format, where 6 types of attributes are considered: number of the current sentence in the text, word form (i.e. the word itself), lemma (initial word form), POS tag (part of speech), morphological characteristics of the word and, finally, the label of the entity allocated on this token.
How did you solve the NER problem before?
Strictly speaking, the problem can be solved without machine learning - with the help of rule-based systems (in the simplest version - with the help of regular expressions). This seems outdated and ineffective, but you need to understand if your subject area is limited and clearly defined and if the entity, by itself, does not have a lot of variability, then the NER problem is solved using rule-based methods fairly quickly and efficiently.
For example, if you need to highlight emails or numerical entities (dates, money or phone numbers), regular expressions can lead you to success faster than trying to solve a problem using machine learning.
However, as soon as linguistic ambiguities of various kinds come into play (we wrote about some of them above), such simple methods cease to work well. Therefore, it makes sense to use them only for limited domains and on entities that are simple and clearly separable from the rest of the text.
Despite all of the above, at the academic buildings until the end of the 2000s, SOTA showed systems based on classical methods of machine learning. Let's take a quick look at how they worked.
Signs
Before embeddings appeared, the main sign of the token was usually the word form - i.e., the index of the word in the dictionary. Thus, each token is assigned a Boolean vector of large dimension (dictionary dimension), where in the place of the word index in the dictionary is 1, and in the rest places are 0.
In addition to the word form, parts of speech (POS-tags) were often used as signs of the token , morphological characters (for languages without rich morphology - for example, English, morphological characters have practically no effect), prefixes (i.e., the first few characters of the word), suffixes (similarly, the last few characters of the token), the presence of special characters in token and the appearance of the token.
In classical settings, a very important sign of a token is the type of its capitalization, for example:
- “The first letter is large, the rest are small”,
- “All letters are small”,
- “All letters are large”,
- or generally “non-standard capitalization” (observed, in particular, for the “iPhone” token).
If the token has a non-standard capitalization, it is very likely that it can be concluded that the token is some kind of entity, and the type of this entity is hardly a person or location.
In addition to all this, newspapers - dictionaries of entities were actively used. We know that Petya, Elena, Akaki are the names, Ivanov, Rustaveli, von Goethe are the names, and Mytishchi, Barcelona, Sao Paulo are the cities. It is important to note that entity dictionaries alone do not solve the problem (“Moscow” can be part of the organization’s name, and “Elena” can be part of the location), but they can improve its solution. However, of course, despite the ambiguity, the token's belonging to a dictionary of entities of a certain type is a very good and significant attribute (so significant that usually the results of solving the NER problem are divided into 2 categories - with and without newspaper people).
If you are interested in how people solved the NER problem when the trees were large, I advise you to see the articleNadeau and Sekine (2007), A survey of Named Entity Recognition and Classification . The methods described there are, of course, outdated (even if you cannot use neural networks due to performance limitations, you probably will not use HMM, as described in the article, but, let’s say, gradient boosting), but look at the description of symptoms may make sense.
Interesting features include capitalization patterns (summarized pattern in the article above). They can still help with some NLP tasks. So, in 2018, there was a successful attempt to apply capitalization patterns (word shape) to neural network methods for solving the problem.
How to solve the NER problem using neural networks?
NLP almost from scratch
The first successful attempt to solve the NER problem using neural networks was made in 2011 .
At the time of the publication of this article, she showed a SOTA result on the CoNLL 2003 package. But you need to understand that the superiority of the model compared to systems based on classical machine learning algorithms was quite insignificant. In the next few years, methods based on classical ML showed results comparable to neural network methods.
In addition to describing the first successful attempt to solve the NER problem with the help of neural networks, the article describes in detail many points that most of the works on the topic of NLP are left out of the picture. Therefore, despite the fact that the architecture of the neural network described in the article is outdated, it makes sense to read the article. This will help to understand the basic approaches to neural networks used in solving the NER problem (and more broadly, many other NLP tasks).
We will tell you more about the architecture of the neural network described in the article.
The authors introduce two varieties of architecture that correspond to two different ways to take into account the context of the token:
- either use a “window” of a given width (window based approach),
- or consider the sentence based approach as context.
In both cases, the used signs are embeddings of word forms, as well as some manual signs - capitalization, parts of speech, etc. We will tell you more about how they are calculated.
We got an input list of words from our sentence: for example, “ The cat sat on the mat ”.
Suppose that there are K different signs for one token (for example, the word form, part of speech, capitalization, whether our token is the first or last in the sentence, etc., can act as such signs). We can consider all these signs categorical (for example, the word form corresponds to a Boolean vector of length of the dictionary dimension, where 1 is only on the coordinate of the corresponding index of the word in the dictionary). Let be
a Boolean vector corresponding to the value of the ith attribute of the jth token in the sentence.It is important to note that in the sentence based approach, in addition to the categorical features determined by the words, the feature is used - a shift relative to the token, the label of which we are trying to determine. The value of this attribute for the token number i will be i-core, where core is the number of the token whose label we are trying to determine at the moment (this attribute is also considered categorical, and the vectors for it are calculated in the same way as for the others).
The next step in finding the signs of a token is to multiply each
by a matrix called the Lookup Table (in this way Boolean vectors “turn” into continuous ones). Recall that each of them is a Boolean vector in which there is 1 in one place and 0. in other places. Thus, when multiplied by, one of the rows in our matrix is selected. This line is the embedding of the corresponding token feature. Matrices (where i can take values from 1 to K) are the parameters of our network, which we train together with the rest of the layers of the neural network. The difference between the method of working with categorical features described in this article and the word2vec that appeared later (we talked about how word2vec word-form embeddings are pre-trained in the previous part of our post) is that matrices are initialized randomly here, and in word2vec matrices are pre-trained on a large case on the task of determining a word by context (or context by word).
Thus, for each token, a continuous vector of features is obtained, which is a concatenation of the results of multiplying all kinds of
on . Now we will understand how these signs are used in the sentence based approach (window based is ideologically simpler). It is important that we will launch our architecture separately for each token (that is, for the sentence “The cat sat on the mat” we will launch our network 6 times). The signs in each run are collected the same, with the exception of the sign responsible for the position of the token whose label we are trying to determine - the core token.
We take the resulting continuous vectors of each token and pass them through a one-dimensional convolution with filters of not very large dimension: 3-5. The dimension of the filter corresponds to the size of the context that the network simultaneously takes into account, and the number of channels corresponds to the dimension of the source continuous vectors (the sum of the dimensions of the embeddings of all the attributes). After applying the convolution, we get a matrix of dimension m by f, where m is the number of ways the filter can be applied to our data (i.e., the length of the sentence minus the length of the filter plus one), and f is the number of filters used.
As almost always when working with convolutions, after convolution we use pooling - in this case max pooling (i.e., for each filter we take the maximum of its value on the whole sentence), after which we get a vector of dimension f. Thus, all the information contained in the sentence, which we may need when determining the label of the core token, is compressed into one vector (max pooling was chosen because it is not the information average on the sentence that is important to us, but the values of attributes in its most important areas) . This “flattened context” allows us to collect the signs of our token throughout the sentence and use this information to determine which label the core token should receive.
Next, we pass the vector through a multilayer perceptron with some activation functions (in the article - HardTanh), and as the last layer we use a fully connected softmax of dimension d, where d is the number of possible token labels.
Thus, the convolutional layer allows us to collect the information contained in the filter dimension window, pooling - select the most characteristic information in the sentence (compressing it into one vector), and the softmax layer - allows you to determine which label has the core number token.
CharCNN-BLSTM-CRF
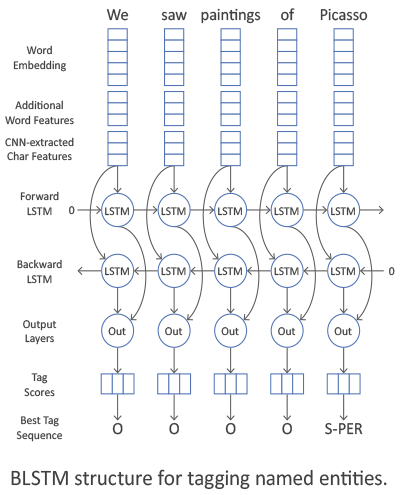
Now let's talk about the architecture of CharCNN-BLSTM-CRF, that is, about what was SOTA in the period 2016-2018 (in 2018 there were architectures based on embeddings on language models, after which the NLP world will never be the same; but this saga is not about this). As applied to the NER task, architecture was first described in articles by Lample et al (2016) and Ma & Hovy (2016) .
The first layers of the network are the same as in the NLP pipeline described in the previous part of our post .
First, a context-independent attribute of each token in the sentence is calculated. Symptoms are usually collected from three sources. The first is the word-form embedding of the token, the second is symbolic signs, the third is additional signs: information about capitalization, part of speech, etc. Concatenation of all these signs makes up a context-independent token sign.
We talked about word-form embeddings in detail in the previous part. We listed additional features, but we did not say exactly how they are embedded in the neural network. The answer is simple - for each category of additional features, we learn from scratch embedding is not very large. These are exactly the Lookup tables from the previous paragraph, and we teach them exactly the same way as described there.
Now we will tell how symbolic signs are arranged.
First answer the question, what is it. It's simple - we want for each token to get a vector of signs of constant size, which depends only on the symbols that make up the token (and does not depend on the meaning of the token and additional attributes, such as part of speech).
We now turn to the description of the CharCNN architecture (as well as the CharRNN architecture associated with it). We are given a token, which consists of some characters. For each symbol we will issue a vector of some not very large dimension (for example, 20) - symbol embedding. Symbolic embeddings can be pre-trained, but most often they learn from scratch - there are a lot of symbols even in a not very large case, and symbolic embeddings should be adequately trained.
So, we have embeddings of all the symbols of our token, as well as additional symbols that indicate the borders of the token - paddings (usually embeddings of paddings are initialized with zeros). We would like to obtain from these vectors a single vector of some constant dimension, which is a symbolic sign of the entire token and reflects the interaction between these symbols.
There are 2 standard methods.
A slightly more popular of them is to use one-dimensional convolutions (therefore this part of the architecture is called CharCNN). We do this in the same way as we did with the words in the sentence based approach in the previous architecture.
So, we pass the embeddings of all the characters through a convolution with filters of not very large dimensions (for example, 3), we get a vector of dimension of the number of filters. We produce max pooling above these vectors, we get 1 vector of dimension of the number of filters. It contains information about the symbols of the word and their interaction and will be the vector of symbolic signs of the token.
The second way to turn symbolic embeddings into one vector is to feed them into a bilateral recurrent neural network (BLSTM or BiGRU; what it is, we described in the first part of our post ). Usually a symbolic sign of a token is simply a concatenation of the last states of the forward and reverse RNN.
So, let us be given a context-independent token feature vector. According to it, we want to get a context-sensitive attribute.
This is done using BLSTM or BiGRU. At the ith time moment, the layer produces a vector, which is a concatenation of the corresponding outputs of the forward and reverse RNN. This vector contains information both about previous tokens in the offer (it is in the direct RNN), and about the following (it is in the reverse RNN). Therefore, this vector is a context-sensitive sign of the token.
This architecture can be used in a wide variety of NLP tasks, and is therefore considered an important part of the NLP pipeline.
We return, however, to the NER problem. Having received context-sensitive signs of all tokens, we want to get the correct label for each token. This can be done in many ways.
A simpler and more obvious way is to use, as the last layer, a dimension d, fully connected with softmax, where d is the number of possible token labels. Thus, we get the probabilities of the token to have each of the possible labels (and we can choose the most probable of them).
This method works, however, it has a significant drawback - the token label is calculated independently of the labels of other tokens. We consider neighboring tokens themselves due to BiRNN, but the token label depends not only on neighboring tokens, but also on their labels. For example, regardless of tokens, the I-PER label occurs only after B-PER or I-PER.
The standard way to account for the interaction between label types is to use CRF (conditional random fields). We will not describe in detail what it is ( herea good description is given), but we mention that CRF optimizes the entire label chain as a whole, and not every element in this chain.
So, we described the CharCNN-BLSTM-CRF architecture, which was SOTA in the NER task until the advent of embeddings on language models in 2018.
In conclusion, let's talk a little about the significance of each element of architecture. For English, CharCNN gives an increase in f-measure by about 1%, CRF - by 1-1.5%, and additional signs of the token do not lead to quality improvement (unless you use more complex techniques such as multi-task learning, as in Wu et al (2018) ). BiRNN is the basis of architecture, which, however, can be replaced by a transformer .
We hope that we were able to give readers some idea of the NER problem. Although this is an important task, it is quite simple, which allowed us to describe its solution in a single post.
Ivan Smurov,
Head of NLP Advanced Research Group