Speeding up the performance of neural networks using hashing
- Transfer
The industry has focused on accelerating matrix multiplication, but improving the search algorithm can lead to a more serious increase in performance

In recent years, the computer industry has been busy trying to speed up the calculations required for artificial neural networks - both for training and for drawing conclusions from its work. In particular, quite a lot of effort was put into the development of special iron on which these calculations can be performed. Google developed the Tensor Processing Unit , or TPU, first introduced to the public in 2016. Nvidia later introduced the V100 Graphics Processing Unit, describing it as a chip specifically designed for training and using AI, as well as for other high-performance computing needs. Full of other startups, concentrating on other types of hardware accelerators .
Perhaps they all make a grand mistake.
This idea was voiced in the work , which appeared in mid-March on the site arXiv. In it, its authors, Beidi Chen , Tarun Medini and Anshumali Srivastava from Rice University, argue that perhaps the special equipment developed for the operation of neural networks is being optimized for the wrong algorithm.
The thing is that the work of neural networks usually depends on how quickly the equipment can perform the multiplication of matrices used to determine the output parameters of each artificial neutron - its “activation” - for a given set of input values. Matrices are used because each input value for a neuron is multiplied by the corresponding weight parameter, and then they are all summed - and this multiplication with addition is the basic operation of matrix multiplication.
Researchers at Rice University, like some other scientists, realized that the activation of many neurons in a particular layer of the neural network is too small, and does not affect the output value calculated by subsequent layers. Therefore, if you know what these neurons are, you can simply ignore them.
It may seem that the only way to find out which neurons in a layer are not activated is to first perform all the operations of matrix multiplication for this layer. But the researchers realized that you can actually decide on this more efficient way if you look at the problem from a different angle. “We approach this issue as a solution to the search problem,” says Srivastava.
That is, instead of calculating matrix multiplications and looking at which neurons were activated for a given input, you can just see what kind of neurons are in the database. The advantage of this approach in the problem is that you can use a generalized strategy that has long been improved by computer scientists to speed up the search for data in the database: hashing.
Hashing allows you to quickly check if there is a value in the database table, without having to go through each row in a row. You use a hash, easily calculated by applying a hash function to the desired value, indicating where this value should be stored in the database. Then you can check only one place to find out if this value is stored there.
The researchers did something similar for calculations related to neural networks. The following example will help illustrate their approach:
Suppose we have created a neural network that recognizes handwritten input of numbers. Suppose the input is gray pixels in a 16x16 array, that is, a total of 256 numbers. We feed this data to one hidden layer of 512 neurons, the activation results of which are fed by the output layer of 10 neurons, one for each of the possible numbers.
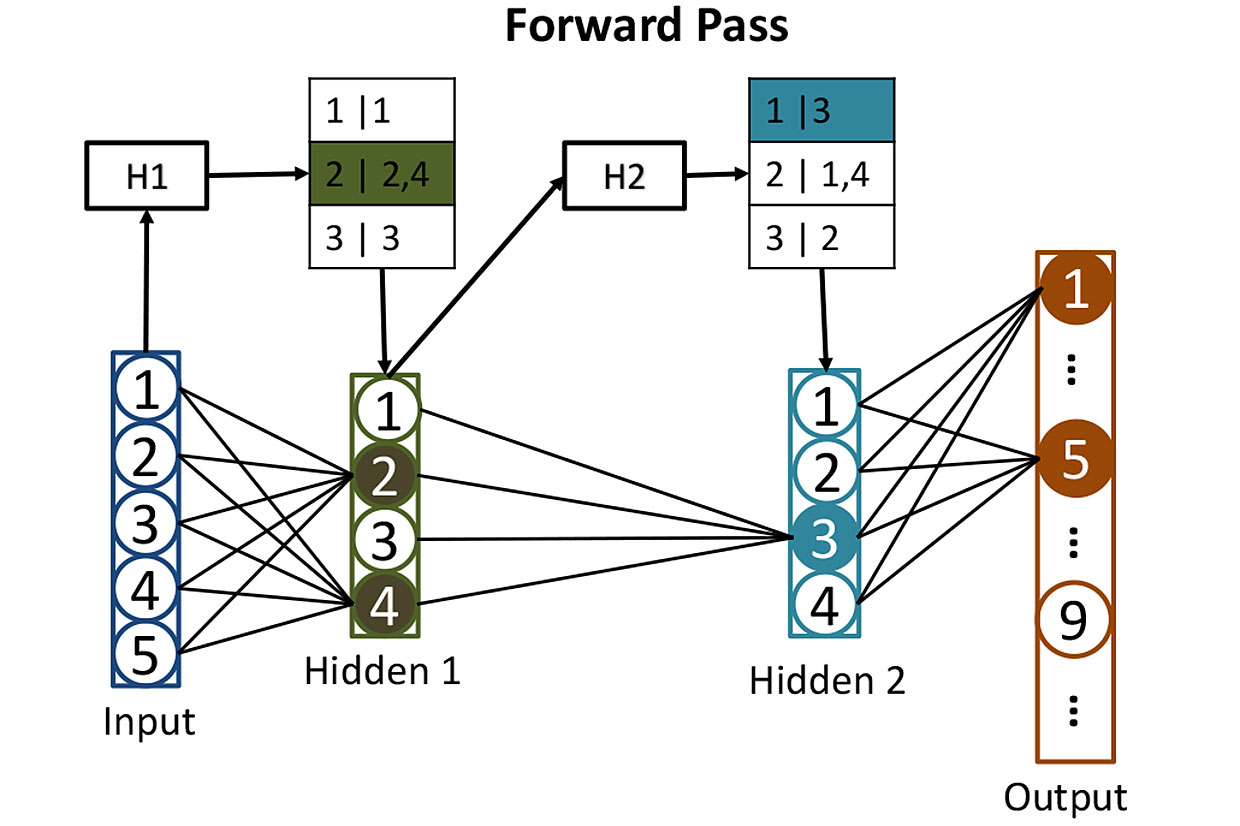
Tables from networks: before calculating the activation of neurons in hidden layers, we use hashes to help us determine which neurons will be activated. Here, the hash of the input values H1 is used to search for the corresponding neurons in the first hidden layer - in this case it will be neurons 2 and 4. The second hash H2 shows which neurons from the second hidden layer will contribute. Such a strategy reduces the number of activations that need to be calculated.
It’s quite difficult to train such a network, but for now let’s omit this moment and imagine that we have already adjusted all the weights of each neuron so that the neural network recognizes handwritten numbers perfectly. When a legibly written number arrives at her input, the activation of one of the output neurons (corresponding to this number) will be close to 1. The activation of the remaining nine will be close to 0. Classically, the operation of such a network requires one matrix multiplication for each of 512 hidden neurons, and one more for each weekend - which gives us a lot of multiplications.
Researchers take a different approach. The first step is to hash the weights of each of the 512 neurons in the hidden layer using "locality sensitive hashing", one of the properties of which is that similar input data give similar hash values. You can then group neurons with similar hashes, which would mean that these neurons have similar sets of weights. Each group can be stored in a database, and determined by the hash of the input values that will lead to the activation of this group of neurons.
After all this hashing, it turns out to be easy to determine which of the hidden neurons will be activated by some new input. You need to run 256 input values through easily calculated hash functions, and use the result to search the database for those neurons that will be activated. In this way, you will have to calculate the activation values for only a few neurons that matter. It is not necessary to calculate the activation of all other neurons in the layer just to find out that they do not contribute to the result.
The input of such a neural network of data can be represented as the execution of a search query to a database that asks to find all the neurons that would be activated by direct counting. You get the answer quickly because you use hashes to search. And then you can simply calculate the activation of a small number of neurons that really matter.
Researchers have used this technique, which they called SLIDE (Sub-LInear Deep learning Engine), to train a neural network — for a process that has more computational requests than it does for its intended purpose. They then compared the performance of the learning algorithm with a more traditional approach using a powerful GPU - specifically, the Nvidia V100 GPU. As a result, they got something amazing: "Our results show that on average CPU SLIDE technology can work orders of magnitude faster than the best possible alternative, implemented on the best equipment and with any accuracy."
It is too early to draw conclusions about whether these results (which experts have not yet evaluated) will withstand the tests and whether they will force chip manufacturers to take a different look at the development of special equipment for deep learning. But the work definitely emphasizes the danger of the entrainment of a certain type of iron in cases where there is the possibility of a new and better algorithm for the operation of neural networks.