Linux virtual file systems: why are they needed and how do they work? Part 2
- Transfer
Hello everyone, we are sharing with you the second part of the publication “Virtual file systems in Linux: why are they needed and how do they work?” The first part can be read here . Recall that this series of publications is dedicated to the launch of a new thread at the Linux Administrator course , which will start very soon.
How to watch VFS using the eBPF and bcc tools
The easiest way to understand how the kernel operates on files

Fortunately, starting to use eBPF is easy enough with the bcc tools , which are available as packages from the general Linux distribution and are documented in detail by Bernard Gregg . Tools
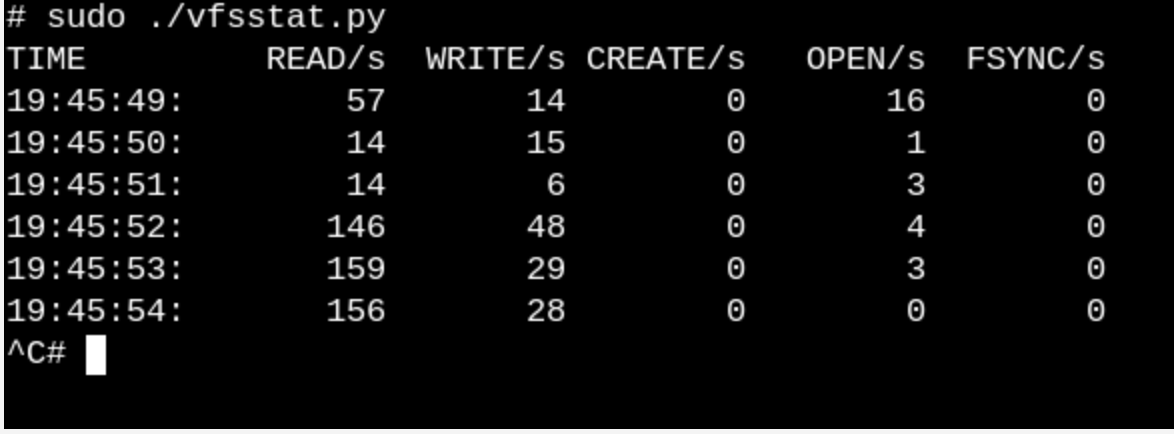
To get even a superficial idea of what kind of work VFS does on a running system, try
We give a more trivial example and see what happens when we insert a USB flash drive into a computer and the system detects it.
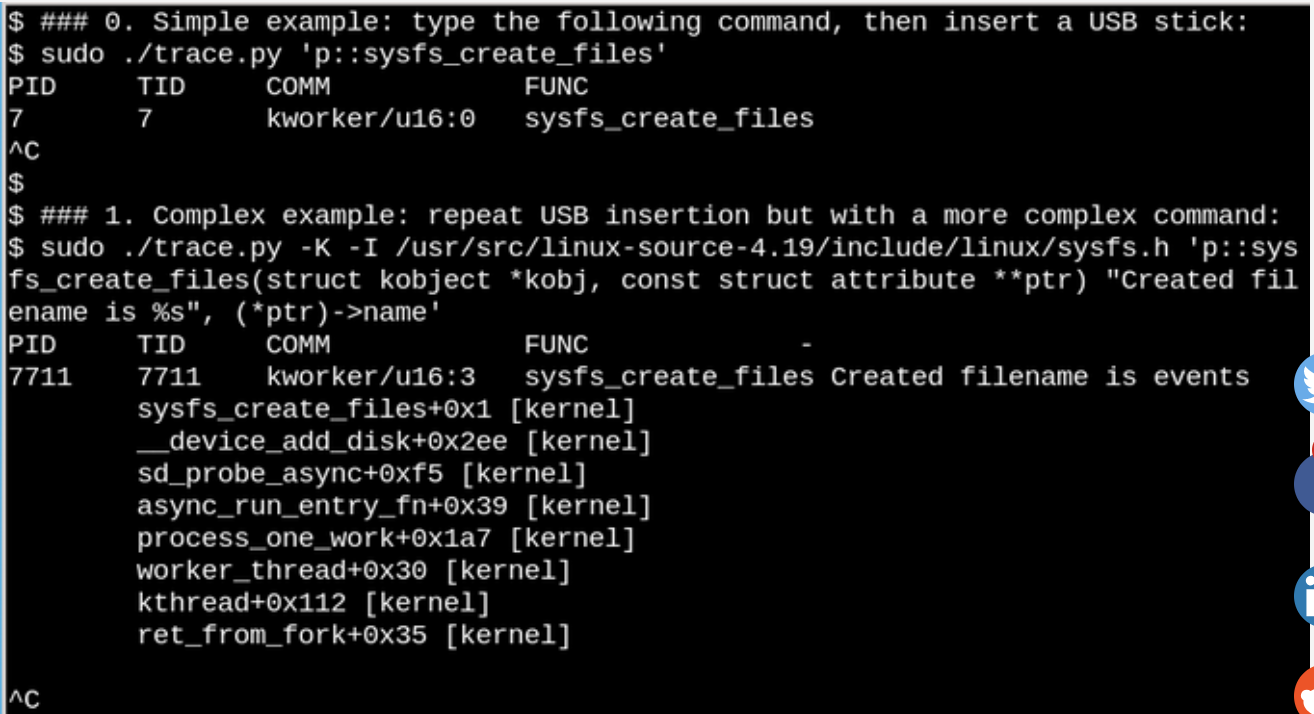
In the example shown above, the trace.py
When a USB drive is inserted, a kernel traceback will show that PID 7711 is the stream
So what is the meaning of the events file? Using cscope to search for __device_add_disk () shows that it calls
Read-only root file systems enable embedded devices
Of course, no one turns off the server or their computer, pulling the plug from the outlet. But why? And all because mounted file systems on physical storage devices may have pending records, and data structures recording their status may not be synchronized with records in the storage. When this happens, system owners have to wait for the next boot to run the utility
However, we all know that many IoT devices, as well as routers, thermostats, and cars are now running Linux. Many of these devices have virtually no user interface, and there is no way to turn them off "cleanly." Imagine starting a car with a discharged battery when the control device is powered onLinux constantly jumps up and down. How is it that the system boots without a long
Creature
Linkable and overlapping mounts, using them with containers
Running a command
Based on the description of superimposed and linked mounts, no one is surprised that Linux containers actively use them. Let's observe what happens when we use systemd-nspawn to launch a container using the

The call
Let's see what happened:
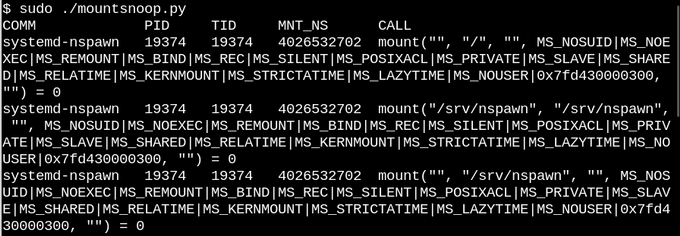
Launch
It
Conclusion
Understanding the internal structure of Linux may seem like an impossible task, since the kernel itself contains a huge amount of code, leaving aside the Linux user space applications and system call interfaces in C libraries, such as
make kernel research easier than ever.
Friends, write this article was useful to you? Perhaps you have any comments or comments? And those who are interested in the Linux Administrator course, we invite you to open house day , which will take place on April 18.
First part.
How to watch VFS using the eBPF and bcc tools
The easiest way to understand how the kernel operates on files
sysfsis to look at it in practice, and the easiest way to watch ARM64 is to use eBPF. eBPF (short for Berkeley Packet Filter) consists of a virtual machine running in the kernel that privileged users can request (query) from the command line. The kernel sources tell the reader what the kernel can do; running eBPF tools on a busy system shows what the kernel actually does. Fortunately, starting to use eBPF is easy enough with the bcc tools , which are available as packages from the general Linux distribution and are documented in detail by Bernard Gregg . Tools
bccare Python scripts with small C code inserts, which means that anyone who is familiar with both languages can easily modify them. There bcc/toolsare 80 Python scripts, which means that most likely the developer or system administrator will be able to choose something suitable for solving the problem.To get even a superficial idea of what kind of work VFS does on a running system, try
vfscountor vfsstat. This will show, for example, that dozens of calls vfs_open()and “his friends” occur literally every second.vfsstat.py Is a Python script with C code inserts that simply counts VFS function calls.We give a more trivial example and see what happens when we insert a USB flash drive into a computer and the system detects it.
Using eBPF, you can see what happens /syswhen a USB flash drive is inserted. A simple and complex example is shown here.In the example shown above, the trace.py
bcc tool displays a message when the command is run . We see that it was launched using the stream in response to the fact that the flash drive was inserted, but which file was created in this case? The second example shows the full power of eBPF. This displays the kernel backtrace (-K option) and the name of the file that was created . The single statement insertion is C code that includes an easily recognizable format string provided by a Python script that runs the LLVM just-in-time compiler . He compiles and executes this line in a virtual machine inside the kernel. Full Function Signaturesysfs_create_files()sysfs_create_files()kworkertrace.pysysfs_create_files()sysfs_create_files ()must be reproduced in the second command so that the format string can refer to one of the parameters. Errors in this C code fragment result in recognizable C compiler errors. For example, if you omit the -l option, you will see “Failed to compile BPF text.” Developers who are familiar with C and Python will find the tools bcceasy to expand and modify. When a USB drive is inserted, a kernel traceback will show that PID 7711 is the stream
kworkerthat created the file «events»in sysfs. Accordingly, a call with sysfs_remove_files()will show that deleting the drive led to the deletion of the file events, which corresponds to the general concept of link counting. At the same time, viewing sysfs_create_link ()from eBPF while inserting a USB drive will show that at least 48 symbolic links have been created.So what is the meaning of the events file? Using cscope to search for __device_add_disk () shows that it calls
disk_add_events (), and either "media_change", or "eject_request"can be written to the event file. Here, the kernel block layer informs userspace of the appearance and extraction of the “disk”. Please note how informative this research method is by the example of inserting a USB drive compared to trying to figure out how everything works, exclusively from the source. Read-only root file systems enable embedded devices
Of course, no one turns off the server or their computer, pulling the plug from the outlet. But why? And all because mounted file systems on physical storage devices may have pending records, and data structures recording their status may not be synchronized with records in the storage. When this happens, system owners have to wait for the next boot to run the utility
fsck filesystem-recoveryand, in the worst case, lose data. However, we all know that many IoT devices, as well as routers, thermostats, and cars are now running Linux. Many of these devices have virtually no user interface, and there is no way to turn them off "cleanly." Imagine starting a car with a discharged battery when the control device is powered onLinux constantly jumps up and down. How is it that the system boots without a long
fsckone when the engine finally starts to work? And the answer is simple. Embedded devices rely on the root file system read-only (abbreviated ro-rootfs(read-only root fileystem)) . ro-rootfsoffer many benefits that are less obvious than genuine. One advantage is that malware cannot write to /usror/libif no Linux process can write there. Another is that a largely immutable file system is critical for field support for remote devices, as support staff uses local systems that are nominally identical to the local systems. Perhaps the most important (but also the most insidious) advantage is that ro-rootfs forces developers to decide which system objects will be unchanged, even at the stage of system design. Working with ro-rootfs can be uncomfortable and painful, as is often the case with const variables in programming languages, but their benefits can easily cover the extra overhead. Creature
rootfsread-only requires some extra effort for embedded developers, and that is where VFS comes onto the scene. Linux requires files to /varbe writable, and in addition, many popular applications that run embedded systems will try to create configuration files dot-filesin $HOME. One solution for configuration files in the home directory is usually to pre-generate and build them in rootfs. For /varone of the possible approaches, it is to mount it in a separate section that is writable, while it is /mounted only for reading. Another popular alternative is to use bind or overlay mounts.Linkable and overlapping mounts, using them with containers
Running a command
man mountis the best way to learn about linkable and overlapping mounts, which give developers and system administrators the ability to create a file system in one way and then provide it to applications in another. For embedded systems, this means the ability to store files in a /varread-only flash drive, but overlaying or linking the path from tmpfsto /varat boot will allow applications to write notes there (scrawl). The next time you turn on, the changes to /varwill be lost. An overlay mount creates a union between tmpfsand the underlying file system and allows you to supposedly make changes to existing files inro-tootfwhereas linked mounts can make new empty tmpfsfolders visible as writable in ro-rootfspaths. While overlayfsthis is the correct ( proper) type of file system, mountable bindings are implemented in the VFS namespace . Based on the description of superimposed and linked mounts, no one is surprised that Linux containers actively use them. Let's observe what happens when we use systemd-nspawn to launch a container using the
mountsnoopfrom tool bcc. The call
system-nspawnlaunches the container during operation mountsnoop.py. Let's see what happened:
Launch
mountsnoopduring the “loading” of the container shows that the container runtime is highly dependent on the mount being connected (Only the beginning of a long output is displayed). It
systemd-nspawnprovides the selected files in procfsand the sysfshost in the container as paths to it rootfs. In addition to the MS_BINDflag that sets the binding mount, some other flags in the mounted system determine the relationship between changes in the host namespace and the container. For example, a linked mount can either skip changes to /procand /sysinto the container, or hide them depending on the call. Conclusion
Understanding the internal structure of Linux may seem like an impossible task, since the kernel itself contains a huge amount of code, leaving aside the Linux user space applications and system call interfaces in C libraries, such as
glibc. One way to make progress is to read the source code of one kernel subsystem with an emphasis on understanding system calls and headers facing the user space, as well as the main internal kernel interfaces, for example, a table file_operations. File operations provide the principle of “everything is a file”, so managing them is especially nice. C kernel source files in the top-level directoryfs/represent the implementation of virtual file systems, which are a shell layer that provides wide and relatively simple compatibility of popular file systems and storage devices. Mounting with binding and overlaying through Linux namespaces is VFS magic that makes it possible to create read-only containers and root file systems. Combined with source code research, the eBPF core tool and its interface bccmake kernel research easier than ever.
Friends, write this article was useful to you? Perhaps you have any comments or comments? And those who are interested in the Linux Administrator course, we invite you to open house day , which will take place on April 18.
First part.









