Monitoring Kubernetes Cluster Resources
- Transfer
I created Kube Eagle - an exporter of Prometheus. It turned out to be a cool thing that helps to better understand the resources of small and medium clusters. As a result, I saved more than one hundred dollars, because I selected the right types of machines and configured application resource limits for workloads.
I will talk about the advantages of the Kube Eagle , but first I will explain why the fuss came out and why high-quality monitoring was needed.
I managed several clusters of 4-50 nodes. In each cluster - up to 200 microservices and applications. To make better use of the available hardware, most deployments were configured with burstable-RAM and CPU resources. So pods can take available resources, if necessary, and at the same time do not interfere with other applications on this node. Well, isn't it great?
And although the cluster consumed relatively little CPU (8%) and RAM (40%), we constantly had problems with crowding out hearths when they tried to allocate more memory than is available on the node. Then we had only one dashboard for monitoring Kubernetes resources. Here is one:
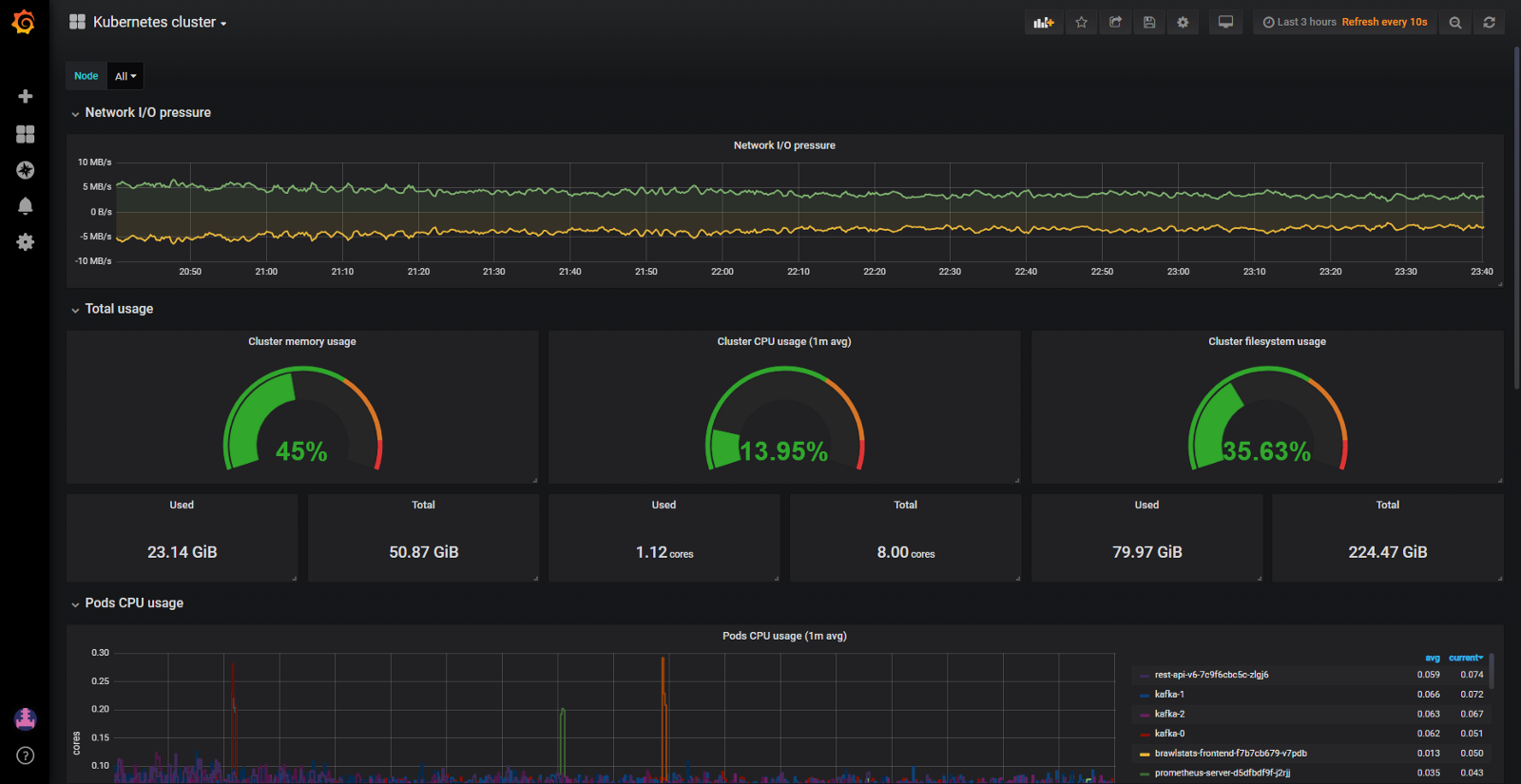
Grafana dashboard with cAdvisor metrics only
With such a panel, the nodes that eat a lot of memory and CPU are not a problem. The problem is to figure out the reason. To keep the pods in place, you could, of course, configure guaranteed resources on all pods (the requested resources are equal to the limit). But this is not the smartest use of iron. There were several hundred gigabytes of memory on the cluster, while some nodes were starving, while others had 4-10 GB in reserve.
It turns out that the Kubernetes scheduler distributed workloads across available resources unevenly. The Kubernetes Scheduler takes into account different configurations: affinity, taints and tolerations rules, node selectors that can limit the available nodes. But in my case there was nothing like that, and the pods were planned depending on the requested resources on each node.
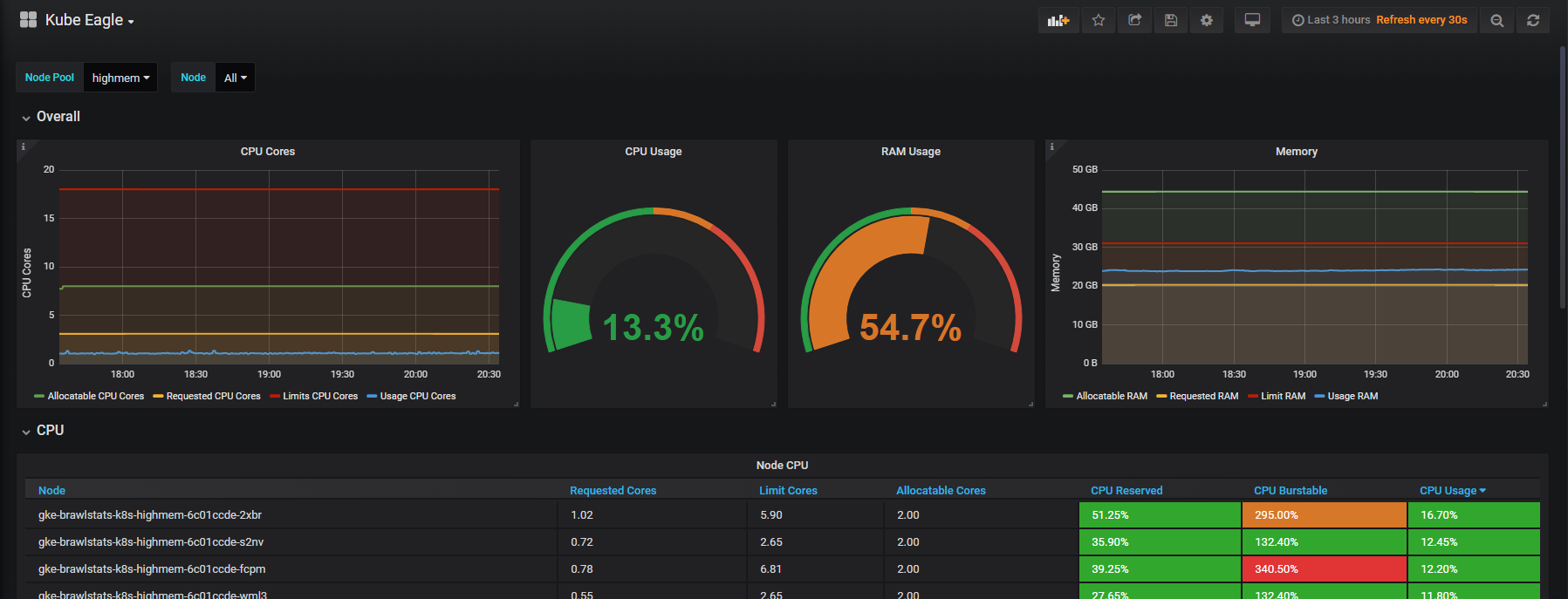
For the hearth, a node was selected that has the most free resources and which satisfies the request conditions. It turned out that the requested resources on the nodes do not match the actual use, and here Kube Eagle and its ability to monitor resources came to the rescue.
I have almost all Kubernetes clusters tracked only with Node exporter and Kube State Metrics . Node Exporter provides statistics on I / O and disk, CPU and RAM usage, and Kube State Metrics displays Kubernetes object metrics, such as requests and limits on CPU and memory resources.
We need to combine the usage metrics with the request and limit metrics in Grafana, and then we get all the information about the problem. It sounds simple, but in fact in these two tools the labels are called differently, and some metrics do not have metadata labels at all. Kube Eagle does everything by itself and the panel looks like this:
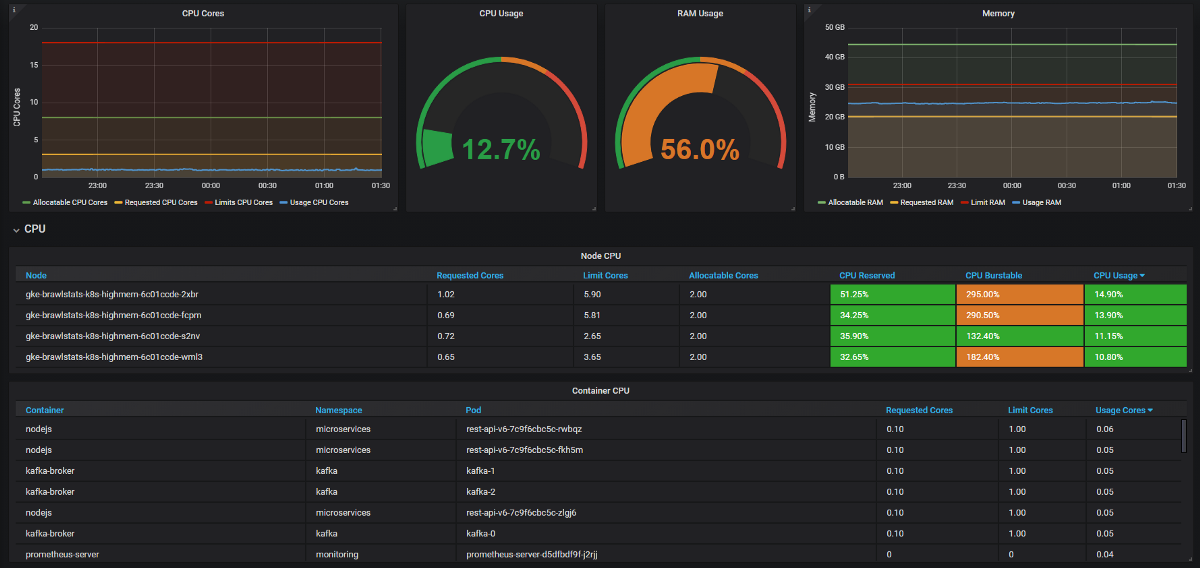
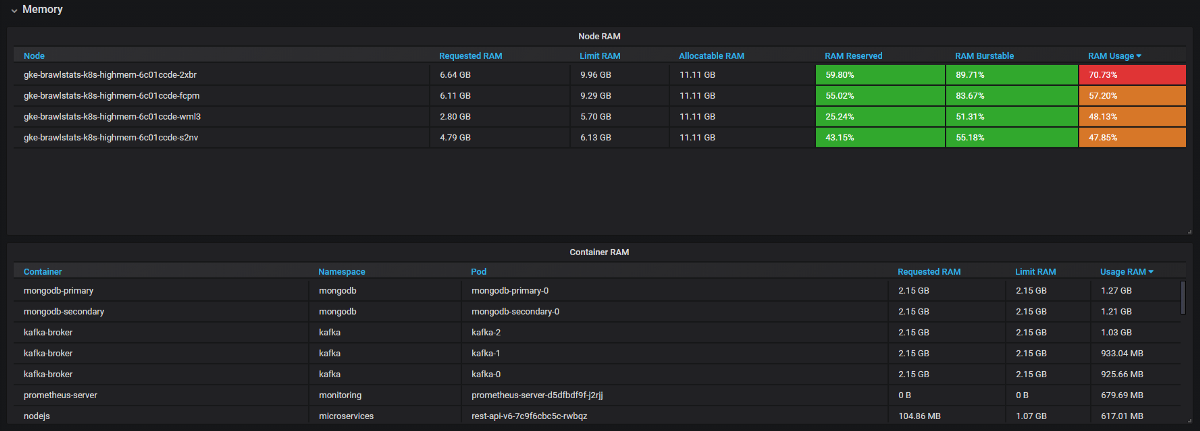
We managed to solve many problems with resources and save equipment:
- Some developers did not know how many resources microservices needed (or simply did not bother). We had nothing to find the wrong requests for resources - for this we need to know the consumption plus requests and limits. Now they see Prometheus metrics, monitor actual usage and fine-tune queries and limits.
- JVM applications take as much RAM as they take. The garbage collector frees memory only if more than 75% is involved. And since most services have burstable memory, the JVM has always occupied it. Therefore, all of these Java services consumed much more RAM than expected.
- Some applications requested too much memory, and the Kubernetes scheduler did not give these nodes to other applications, although in fact they were freer than other nodes. One developer accidentally added an extra digit in the request and grabbed a large piece of RAM: 20 GB instead of 2. No one noticed. The application had 3 replicas, so 3 nodes were affected.
- We introduced resource limits, re-planned the pods with the correct requests, and got the perfect balance of using iron across all nodes. A couple of nodes could generally be closed. And then we saw that we had the wrong machines (CPU-oriented, not memory-oriented). We changed the type and deleted a few more nodes.
Summary
With burstable resources in a cluster, you use existing hardware more efficiently, but the Kubernetes scheduler schedules pods on resource requests, which is fraught. To kill two birds with one stone: to avoid problems, and to use resources to the fullest, good monitoring is needed. Kube Eagle (Prometheus exporter and Grafana dashboard) is useful for this .