Two percent "cat" or who photographed Master Yoda?
In 2016, because of the old dream of video games and the “HYIP” around AI, I began to learn Python.
Computer Science is Fun because only a week ago I trained the first recognition model, but without using Python (there are many temptations in computer science). As predicted by Andrey Sebrant (Yandex), the new technological revolution has come true. Why? Make an image recognition application easier than a computer game. Enough for an hour or two.

I went the “hard” way - I didn’t choose from the four models I had already trained, but I trained my own. Apple's Core ML library allows you to do this with 6 lines of code or through playgrounds.
Most of the time was spent collecting and filtering data for training, with 70 photos of dogs, cats and people, but a quickly written script made the process semi-automatic.
Before, I just read about machine learning. When I tried it myself, I encountered three expected problems / conclusions:
The experiment with the recognition of "cats-people" prompted the idea that the classification algorithm will cope with the "style".
I chose four photographers and about a hundred photos from each. I did not try to carefully select examples, but simply copied from my collection the first or last hundred images of Evgeny Mokhorev and Oleg Videnin . There were not enough photographs of Maxim Shumilin , therefore not only portraits were included in the sample. But the photos of Yegor Voinov are chosen more carefully, since I downloaded two sections devoted to the portrait on his website.
I started training the algorithm and, on average, got 80% recognition accuracy (test results during creation).
There was one strange moment. I doubled the number of photographs of Oleg Videnin and the system learned only 30%, and the recognition accuracy decreased to 20%.
It was necessary to check the system in order to somehow avoid bias, I asked Egor Voinov to send photos that are not on the site. As a result, the algorithm confirmed that 20 of the 26 photos are similar to the way Yegor Voinov takes a portrait.
This confirmed 77% of the recognition accuracy obtained when creating a classifier.

And then fun begins.
First, the system can be trained by re-adding “errors” to the training set. Results vary, but the system does not remember the photos, but finds common signs for a particular author. Some photos after the “work on the bugs” system recognized as a photo of Egor Voinov, and some did not.
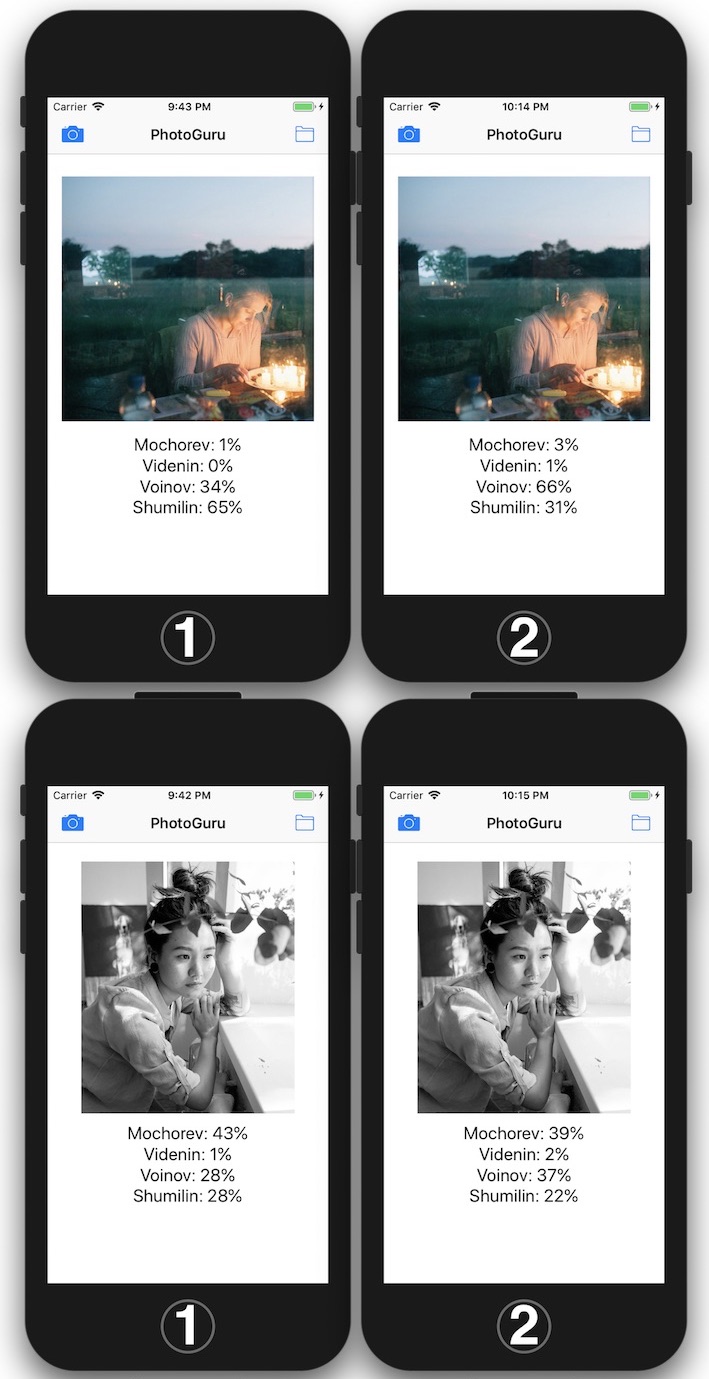
Secondly, the system is inclined to attribute “nude” to the photographs of Evgeny Mokhorev, because he writes under rare “nude” from Oleg Videnin that these are photographs of Mokhorev. And as soon as you show “dressed Mokhorev”, the system can “see Voinov”. And recognize the photo of Yegor Voinov as a photo of Oleg Videnin.

The selection of photos of Maxim Shumilin was very heterogeneous. Therefore, the system relates small figures and portraits with a pronounced “blurring” to Maxim’s photographs.

Thirdly, the system can be given to look at the photo of Master Yoda.

And you can just take a quick picture and find out in whose “style” the photo was taken.

And here is the moment of truth. I uploaded my portraits to find out how much Mokhorev, Videnin, Voinov and Shumilin are in me.

Draft application PhotoGuru ready. While it seems to me that this is a fun toy, but I will work on the design and expand the training samples.
In short, you need to choose a framework for further study of ML.
Computer Science is Fun because only a week ago I trained the first recognition model, but without using Python (there are many temptations in computer science). As predicted by Andrey Sebrant (Yandex), the new technological revolution has come true. Why? Make an image recognition application easier than a computer game. Enough for an hour or two.
I went the “hard” way - I didn’t choose from the four models I had already trained, but I trained my own. Apple's Core ML library allows you to do this with 6 lines of code or through playgrounds.
import CreateMLUI
let builder = MLImageClassifierBuilder()
builder.showInLiveView()
Most of the time was spent collecting and filtering data for training, with 70 photos of dogs, cats and people, but a quickly written script made the process semi-automatic.
Before, I just read about machine learning. When I tried it myself, I encountered three expected problems / conclusions:
- Data is the most important part.
- Convenient interface (CoreML). Everything just works and does not really want to go into the source code to understand the details. Machine learning is available to any user, but Apple engineers tried to hide the complex details.
- The model is a “black box”. I do not know the rules by which the model believes that the photograph is two percent "cat."
The experiment with the recognition of "cats-people" prompted the idea that the classification algorithm will cope with the "style".
I chose four photographers and about a hundred photos from each. I did not try to carefully select examples, but simply copied from my collection the first or last hundred images of Evgeny Mokhorev and Oleg Videnin . There were not enough photographs of Maxim Shumilin , therefore not only portraits were included in the sample. But the photos of Yegor Voinov are chosen more carefully, since I downloaded two sections devoted to the portrait on his website.
I started training the algorithm and, on average, got 80% recognition accuracy (test results during creation).
There was one strange moment. I doubled the number of photographs of Oleg Videnin and the system learned only 30%, and the recognition accuracy decreased to 20%.
It was necessary to check the system in order to somehow avoid bias, I asked Egor Voinov to send photos that are not on the site. As a result, the algorithm confirmed that 20 of the 26 photos are similar to the way Yegor Voinov takes a portrait.
This confirmed 77% of the recognition accuracy obtained when creating a classifier.
And then fun begins.
First, the system can be trained by re-adding “errors” to the training set. Results vary, but the system does not remember the photos, but finds common signs for a particular author. Some photos after the “work on the bugs” system recognized as a photo of Egor Voinov, and some did not.
Secondly, the system is inclined to attribute “nude” to the photographs of Evgeny Mokhorev, because he writes under rare “nude” from Oleg Videnin that these are photographs of Mokhorev. And as soon as you show “dressed Mokhorev”, the system can “see Voinov”. And recognize the photo of Yegor Voinov as a photo of Oleg Videnin.
The selection of photos of Maxim Shumilin was very heterogeneous. Therefore, the system relates small figures and portraits with a pronounced “blurring” to Maxim’s photographs.
Thirdly, the system can be given to look at the photo of Master Yoda.
And you can just take a quick picture and find out in whose “style” the photo was taken.
And here is the moment of truth. I uploaded my portraits to find out how much Mokhorev, Videnin, Voinov and Shumilin are in me.
Draft application PhotoGuru ready. While it seems to me that this is a fun toy, but I will work on the design and expand the training samples.
In short, you need to choose a framework for further study of ML.