1600bit / s speech coding with neural vocoder LPCNet
- Transfer
This is a continuation of the first article on LPCNet . In the first demo, we presented an architecture that combines signal processing and deep learning to enhance the effectiveness of neural speech synthesis. This time we will turn LPCNet into a neural speech codec with a very low bitrate (see the scientific article ). It can be used on current equipment and even on phones.
For the first time, a neural vocoder works in real time on one processor core of the phone, and not on a high-speed GPU. The final bitrate of 1600 bps is about ten times less than that of ordinary broadband codecs. The quality is much better than existing vocoders with a very low bitrate and comparable to more traditional codecs that use a higher bitrate.
Waveform Encoders and Vocoders
There are two large types of speech codecs: waveform coders and vocoders. Waveform encoders include Opus, AMR / AMR-WB, and all codecs that can be used for music. They try to provide a decoded waveform as close to the original as possible - usually taking into account some perceptual features. Vocoders, on the other hand, are actually synthesizers. The encoder extracts information about the pitch and shape of the speech path, passes this information to the decoder, and he re-synthesizes the speech. It is almost like speech recognition followed by reading text in a speech synthesizer, except that the text encoder is much simpler / faster than speech recognition (and conveys a bit more information).
Vocoders have existed since the 70s, but since their decoders perform speech synthesis, they cannot be much better than conventional speech synthesis systems, which until recently sounded simply awful. This is why vocoders were typically used at speeds below 3 kB / s. In addition, waveform encoders simply provide the best quality. This continued until recently, when neural speech synthesis systems such as WaveNet appeared . Suddenly, the synthesis began to sound much better, and, of course, there were people who wanted to make a vocoder from WaveNet .
LPCNet Overview
WaveNet produces very high-quality speech, but requires hundreds of gigaflops of computing power. LPCNet significantly reduced the computational complexity. The vocoder is based on WaveRNN, which improves WaveNet using a recurrent neural network (RNN) and sparse matrices. LPCNet further enhances WaveRNN with linear prediction (LPC), which performed well in older vocoders. It predicts a sample from a linear combination of previous samples and, most importantly, makes it many times faster than a neural network. Of course, it is not universal (otherwise vocoders of the 70s would sound great), but it can seriously reduce the load on the neural network. This allows you to use a smaller network than WaveRNN without sacrificing quality.
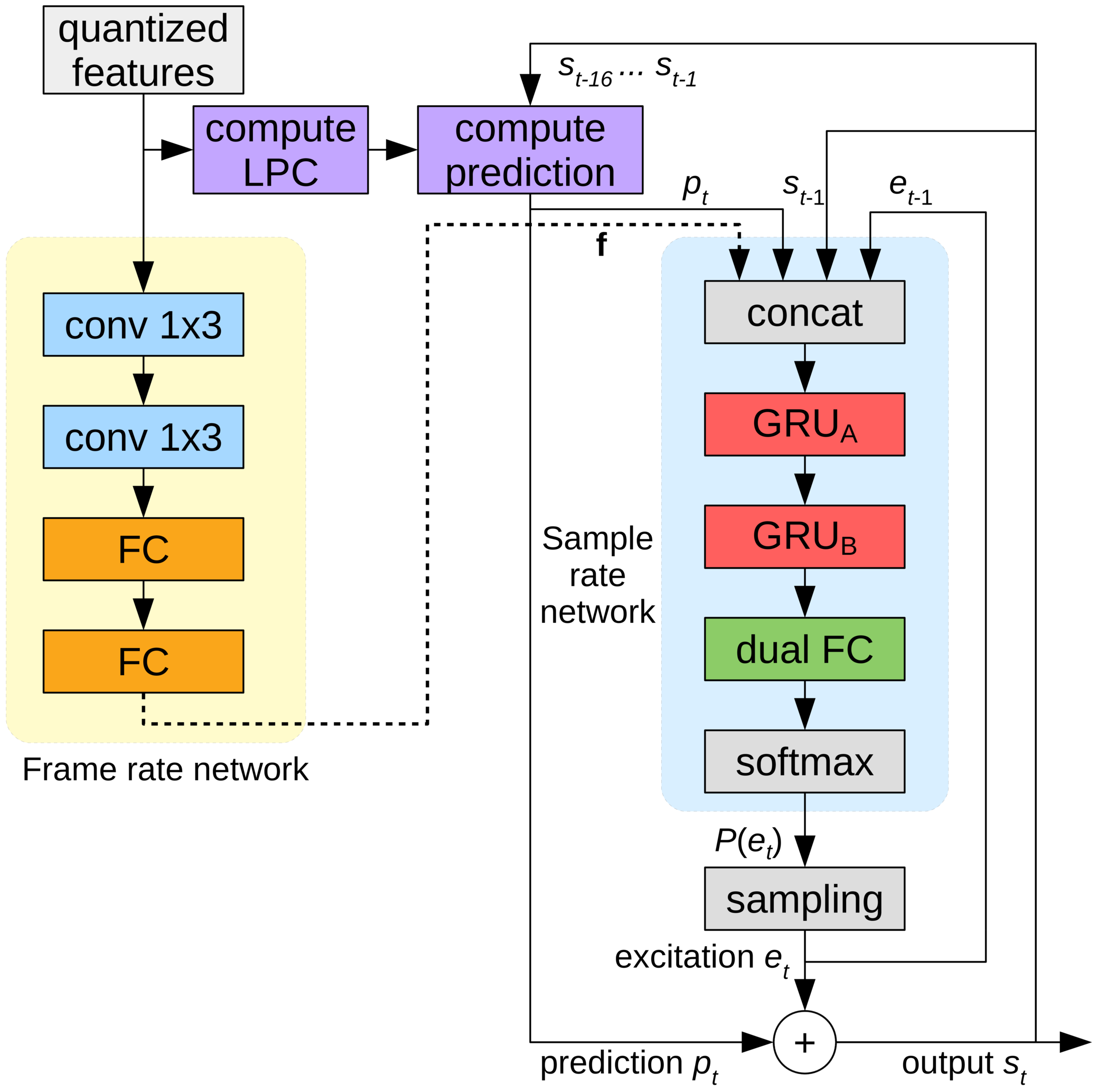
Let's take a closer look at LPCNet. The yellow part on the left is calculated once per frame, and its output is used for the network sampling frequency on the right (blue). The computing unit predicts a sample at time t based on previous samples and linear prediction coefficients
Compression characteristics
LPCNet synthesizes speech from vectors of 20 characters per frame for 10 ms. Of these, 18 signs are cepstral coefficients representing the shape of the spectrum. The two remaining ones describe the height: one parameter for the pitch step (pitch period), and the other for the strength (how much the signal correlates with itself, if you introduce a delay by the pitch). If you store the parameters in the form of floating point values, then all this information takes up to 64 kbit / s during storage or transmission. This is too much, because even the Opus codec provides very high-quality speech coding at only 16 kbit / s (for 16 kHz mono). Obviously, you need to apply strong compression here.
Height
All codecs rely heavily on pitch, but unlike waveform encoders, where pitch “just” helps reduce redundancy, vocoders have no fallback. If you choose the wrong height, they will begin to generate poor-sounding (or even illegible) speech. Without going into details (see the scientific article), the LPCNet encoder is struggling not to make a mistake in height. The search begins with a search for time correlations in a speech signal. See below how a typical search works.

The pitch is the period during which the pitch is repeated. The animation searches for the step that corresponds to the maximum correlation between the signal x (n) and its copy x (nT) with a delay. T value with maximum correlation is a pitch of height
This information needs to be encoded with as few bits as possible without degrading the result too much. Since we perceive frequency by nature on a logarithmic scale (for example, each musical octave doubles the previous frequency), it makes sense in logarithmic coding. The height of the speech signal in most people (we are not trying to cover the soprano here) is between 62.5 and 500 Hz. With seven bits (128 possible values) we get a resolution of about a quarter tone (the difference between and before and re is one tone).
So, with the height finished? Well, not so fast. People do not speak like robots from 1960s films. Voice pitch can vary even within a 40-millisecond packet. You need to take this into account, leaving the bits for the parameter for changing the height: 3 bits to encode the difference up to 2.5 semitones between the beginning and end of the packet. Finally, you need to code the correlation of the pitch steps, distinguishing between vowels and consonants (for example, s and f). Two bits are enough for correlation.
Cepstrum
While pitch contains the external characteristics of speech (prosody, emotion, emphasis, ...), the spectral characteristic determines what was said (except for tonal languages such as Chinese, where pitch is important for meaning). The vocal cords produce approximately the same sound for any vowel, but the shape of the vocal tract determines which sound will be spoken. The voice path acts as a filter, and the task of the encoder is to evaluate this filter and pass it to the decoder. This can be effectively done if you convert the spectrum to a cepstrum (yes, this is a “spectrum” with a changed order of letters, these are we funny guys in digital signal processing).
For an input signal at 16 kHz, the cepstrum basically represents a vector of 18 numbers every 10 ms, which need to be compressed as much as possible. Since we have four such vectors in a 40 ms packet and they are usually similar to each other, we want to eliminate redundancy as much as possible. This can be done using neighboring vectors as predictors and conveying only the difference between the prediction and the real value. At the same time, we don’t want to depend too much on previous packages if one of them disappears. It seems that the problem has already been solved ...
If you have only a hammer, everything looks like a nail - Abraham Maslow.
If you worked a lot with video codecs, then probably met with the concept of B-frames. Unlike video codecs, which divide a frame into many packets, we, on the contrary, have many frames in one packet. We start by encoding the key frame , i.e., the independent vector, and the end of the packet. This vector is encoded without prediction, occupying 37 bits: 7 for total energy (first cepstral coefficient) and 30 bits for other parameters using vector quantization(Vq). Then come the (hierarchical) B-frames. Of the two keywords (one from the current package and one from the previous one), a cepstrum between them is predicted. As a predictor for coding the difference between the real value and the prediction, you can choose either of two key frames or their average value. We use VQ again and encode this vector using a total of 13 bits, including the choice of predictor. Now we have only two vectors left and very few bits. Use the last 3 bits to simply select the predictor for the remaining vectors. Of course, all this is much easier to understand in the figure:

Cepstrum prediction and quantization for package k. Green vectors are quantized independently, blue vectors are predicted, and red vectors use prediction without residual quantization. Prediction is shown by arrows.
Putting it all together
Adding all of the above, we get 64 bits per 40-millisecond packet or 1600 bits per second. If you want to calculate the compression ratio, then uncompressed broadband speech is 256 kbps (16 kHz at 16 bits per sample), which means a compression ratio of 160 times! Of course, you can always play with quantizers and get a lower or higher bitrate (with a corresponding effect on quality), but you need to start somewhere. Here is a table with the layout where these bits go.
| Bit allocation | |
| Parameter | Bit |
| Pitch pitch | 6 |
| Height modulation | 3 |
| Altitude correlation | 2 |
| Energy | 7 |
| Independent Cepstrum VQ (40 ms) | thirty |
| Predicted VQ Cepstrum (20 ms) | thirteen |
| Cepstrum interpolation (10 ms) | 3 |
| Total | 64 |
At 64 bits per packet 40 ms, at 25 packets per second, 1600 bps is obtained.
Implementation
LPCNet source code is available under the BSD license. It includes a library that simplifies the use of the codec. Please note that the development is not finished: both the format and the API are bound to change. The repository also has a demo application
lpcnet_demoin which it is easy to test the codec from the command line. See the README.md file for complete instructions. Who wants to dig deeper, there is an option to train new models and / or use LPCNet as a building block for other applications, such as speech synthesis (LPCNet is only one component of the synthesizer, it does not perform synthesis on its own).
Performance
Neural speech synthesis requires a lot of resources. At last year’s ICASSP conference, Bastian Klein and colleagues from Google / DeepMind presented a 2400 bps codec based on WaveNet , receiving a bitstream from codec2. Although it sounds amazing, the computational complexity of hundreds of gigaflops means that it cannot be launched in real time without an expensive GPU and serious effort.
On the contrary, our 1600 bit / s codec produces only 3 gigaflops and is designed to work in real time on much more affordable equipment. In fact, it can be used today in real applications. Optimization required writing some code for the AVX2 / FMA and Neon instruction sets (embedded code only, without assembler). Thanks to this, we can now encode (and especially decode) speech in real time not only on a PC, but also on more or less modern phones. Below is the performance on x86 and ARM processors.
| Performance | |||
| CPU | Frequency | % of one core | To real time |
| AMD 2990WX (Threadripper) | 3.0 GHz * | 14% | 7.0x |
| Intel Xeon E5-2640 v4 (Broadwell) | 2.4 GHz * | 20% | 5.0x |
| Snapdragon 855 (Cortex-A76 on Galaxy S10 ) | 2.82 GHz | 31% | 3.2x |
| Snapdragon 845 (Cortex-A75 on Pixel 3 ) | 2.5 GHz | 68% | 1.47x |
| AMD A1100 (Cortex-A57) | 1.7 GHz | 102% | 0.98x |
| BCM2837 (Cortex-A53 on Raspberry Pi 3) | 1.2 GHz | 310% | 0.32x |
| * turbo mode | |||
The numbers are pretty interesting. Although only Broadwell and Threadripper are shown, on the x86 platform, Haswell and Skylake processors have similar performance (taking into account the clock frequency). However, ARM processors are noticeably different from each other. Even taking into account the difference in frequency A76 is five to six times faster than A53: it is quite expected, since A53 is mainly used for energy efficiency (for example, in big.LITTLE systems). Nevertheless, LPCNet may well work in real time on a modern phone, using only one core. Although it would be nice to run it in real time on the Raspberry Pi 3. Now this is far, but nothing is impossible.
On x86, the reason for the performance limitation is five times the theoretical maximum. As you know, operations of matrix-vector multiplication are less efficient than matrix-matrix operations because there are more downloads per operation - specifically, one matrix download for each FMA operation. On the one hand, performance is related to the L2 cache, which provides only 16 bits per cycle. On the other hand, Intel claims that L2 can give up to 32 bits per cycle on Broadwell and 64 bits per cycle on Skylake.
results
We conducted MUSHRA-style audio tests to compare coding quality. Testing conditions:
- Sample : original (if you get a better result than the original, there is clearly something wrong with your test)
- 1600 bps LPCNet : our demo
- Uncompressed LPNet : “LPNet with 122 Equivalent Units” from the first article
- Opus 9000 bps wideband : lowest bitrate at which Opus 1.3 encodes broadband audio
- MELP at 2400 bps : a well-known vocoder with a low bit rate (similar in quality to codec2)
- Speex 4000 bps : this broadband vocoder should never be used, but it is a good reference for the bottom
In the first test (set 1), we have eight speech fragments of statements from two men and two women. Files in the first set belong to the same database (i.e., the same recording conditions) that was used for training, but these specific people were excluded from the training set. In the second test (set 2), we used some files from the Opus test (uncompressed), recording sound under different conditions, to make sure that LPCNet goes to some generalization. In both tests, 100 participants each, so the errors are quite small. See the results below.

Subjective quality (MUSHRA) in two tests.
In general, LPCNet at 1600 bps looks good - much better than MELP at 2400 bps, and not far behind Opus at 9000 bps. At the same time, uncompressed LPCNet is slightly better in quality than Opus at 9000 bps. This means that it is possible to provide better quality than Opus at bit rates in the range of 2000-6000 bps.
Listen to yourself
Here are samples from the audio test:
Woman (set 1)
Man (set 1)
Mixed (set 2)
Where can this be used?
We believe that this is a cool technology in itself, but it also has practical applications. Here are just a few options.
VoIP in poorly connected countries
Not everyone always has a high-speed connection. In some countries, communication is very slow and unreliable. A 1600-bit speech codec works normally under such conditions, even transmitting packets several times for reliability. Of course, due to the overhead of packet headers (40 bytes for IP + UDP + RTP), it is better to make larger packets: 40, 80, or 120 ms.
Amateur / HF Radio
For ten years now, David Rowe has been working on speech coding for radio communications. He developed Codec2 , which transmits voice at speeds from 700 to 3200 bps. Over the past year, David and I discussed how to improve Codec2 using neural synthesis, and now we finally do it. In his blog, David wrote about his own implementation of the LPCNet-based codec for integration with FreeDV .
Increased Reliability in Packet Loss
The ability to encode a decent quality bitstream in a small number of bits is useful for providing redundancy on an unreliable channel. Opus has a forward error correction (FEC) mechanism known as LBRR, which encodes a previous frame with a lower bitrate and sends it in the current frame. It works well, but adds significant overhead. 1600 bit / s stream duplication is much more efficient.
Plans
There are many more possibilities to use LPCNet. For example, improving existing codecs (the same Opus). As in other codecs, Opus quality degrades quite quickly at very low bitrates (below 8000 bps), because the waveform codec does not have enough bits to match the original. But the transmitted linear prediction information is enough for LPCNet to synthesize decent-sounding speech - better than Opus can do at this bitrate. In addition, the rest of the information transmitted by Opus (residual forecast) helps LPCNet synthesize an even better result. In a sense, LPCNet can be used as a fancy post-filter to improve the quality of Opus (or any other codec) without changing the bitstream (i.e., while maintaining full compatibility).
Additional Resources
- J.-M. Valin, J. Skoglund, 1.6 Kbps wideband neural vocoder using LPCNet , Sent to Interspeech 2019 , arXiv: 1903.12087 .
- J.-M. Valin, J. Skoglund, LPCNet: Advanced Neural Speech Synthesis Through Linear Prediction , Proc. ICASSP, 2019 , arXiv: 1810.11846 .
- A. van den Oord, S. Dileman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalkhbrenner, E. Senor, K. Kavukuglu, WaveNet: generative model for unprocessed sound , 2016.
- N. Karlhbrenner, E. Elsen, C. Simonyan, S. Nouri, N. Casagrande, E. Lockhart, F. Stimberg, A. van den Oord, S. Dileman, K. Kavukuglu, Effective neural sound synthesis , 2018.
- V.B.Klein, F.S.K. Lim, A.Lyubs, J.Skoglund, F. Stimberg, K. Wang, T.S. Walters, Low-bitrate speech coding based on Wavenet , 2018
- The source code of LPCNet.
- Codec for FreeDV based on LPCNet by David Rowe.
- Join the discussion on development on #opus at irc.freenode.net (→ web interface )