OS1: a primitive kernel on Rust for x86. Part 3. Memory card, Page fault exception, heap and allocations
The topic of today's conversation is working with memory. I will talk about initializing the page directory, mapping physical memory, managing virtual and my organization heap for allocator.
As I said in the first article, I decided to use 4 MB pages to simplify my life and not have to deal with hierarchical tables. In the future, I hope to go to 4 KB pages, like most modern systems. I could use a ready-made one (for example, such a block allocator ), but writing my own was a little more interesting and I wanted to understand a little more how memory lives, so I have something to tell you.
The last time I settled on the architecture-dependent setup_pd method and wanted to continue with it, however, there was one more detail that I did not cover in the previous article - VGA output using Rust and the standard println macro. Since its implementation is trivial, I will remove it under the spoiler. The code is in the debug package.
#[macro_export]
macro_rules! print {
($($arg:tt)*) => ($crate::debug::_print(format_args!($($arg)*)));
}
#[macro_export]
macro_rules! println {
() => ($crate::print!("\n"));
($($arg:tt)*) => ($crate::print!("{}\n", format_args!($($arg)*)));
}
#[cfg(target_arch = "x86")]
pub fn _print(args: core::fmt::Arguments) {
use core::fmt::Write;
use super::arch::vga;
vga::VGA_WRITER.lock().write_fmt(args).unwrap();
}
#[cfg(target_arch = "x86_64")]
pub fn _print(args: core::fmt::Arguments) {
use core::fmt::Write;
use super::arch::vga;
// vga::VGA_WRITER.lock().write_fmt(args).unwrap();
}Now, with a clear conscience, I return to memory.
Page Directory Initialization
Our kmain method took three arguments as input, one of which is the virtual address of the page table. To use it later for allocation and memory management, you need to designate the structure of records and directories. For x86, the Page directory and Page table are described quite well, so I will limit myself to a small introductory one. The Page directory entry is a pointer size structure, for us it is 4 bytes. The value contains a 4KB physical address of the page. The least significant byte of the record is reserved for flags. The mechanism for converting a virtual address into a physical one looks like this (in the case of my 4 MB granularity, the shift occurs by 22 bits. For other granularities, the shift will be different and hierarchical tables will be used!):
Virtual address 0xC010A110 -> Get the index in the directory by moving the address 22 bits to the right -> index 0x300 -> Get the physical address of the page by index 0x300, check the flags and status -> 0x1000000 -> Take the bottom 22 bits of the virtual address as an offset, add to the physical address of the page -> 0x1000000 + 0x10A110 = physical address in memory 0x110A110
To speed up access, the processor uses TLB - translation lookaside buffer, which caches page addresses.
So, here is how my directory and its entries are described, and the very setup_pd method is implemented. To write a page, the “constructor" method is implemented, which guarantees alignment by 4 KB and setting flags, and a method for obtaining the physical address of the page. A directory is just an array of 1024 four-byte entries. The directory can associate a virtual address with a page using the set_by_addr method.
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub struct PDirectoryEntry(u32);
impl PDirectoryEntry {
pub fn by_phys_address(address: usize, flags: PDEntryFlags) -> Self {
PDirectoryEntry((address as u32) & ADDRESS_MASK | flags.bits())
}
pub fn flags(&self) -> PDEntryFlags {
PDEntryFlags::from_bits_truncate(self.0)
}
pub fn phys_address(&self) -> u32 {
self.0 & ADDRESS_MASK
}
pub fn dbg(&self) -> u32 {
self.0
}
}
pub struct PDirectory {
entries: [PDirectoryEntry; 1024]
}
impl PDirectory {
pub fn at(&self, idx: usize) -> PDirectoryEntry {
self.entries[idx]
}
pub fn set_by_addr(&mut self, logical_addr: usize, entry: PDirectoryEntry) {
self.set(PDirectory::to_idx(logical_addr), entry);
}
pub fn set(&mut self, idx: usize, entry: PDirectoryEntry) {
self.entries[idx] = entry;
unsafe {
invalidate_page(idx);
}
}
pub fn to_logical_addr(idx: usize) -> usize {
(idx << 22)
}
pub fn to_idx(logical_addr: usize) -> usize {
(logical_addr >> 22)
}
}
use lazy_static::lazy_static;
use spin::Mutex;
lazy_static! {
static ref PAGE_DIRECTORY: Mutex<&'static mut PDirectory> = Mutex::new(
unsafe { &mut *(0xC0000000 as *mut PDirectory) }
);
}
pub unsafe fn setup_pd(pd: usize) {
let mut data = PAGE_DIRECTORY.lock();
*data = &mut *(pd as *mut PDirectory);
}I very awkwardly made the initial static initialization a nonexistent address, so I would be grateful if you would write to me how it is customary in the Rust community to do such initializations with link reassignment.
Now that we can manage pages from high-level code, we can move on to compiling memory initialization. This will happen in two stages: through processing the physical memory card and initializing the virtual manager
match mb_magic {
0x2BADB002 => {
println!("multibooted v1, yeah, reading mb info");
boot::init_with_mb1(mb_pointer);
},
. . . . . .
}
memory::init();GRUB memory card and OS1 physical memory card
In order to get a memory card from GRUB, at the boot stage I set the corresponding flag in the header, and GRUB gave me the physical address of the structure. I ported it from the official documentation to the Rust notation, and also added methods to comfortably iterate over the memory card. Most of the GRUB structure will not be filled, and at this stage it is not very interesting to me. The main thing is that I do not want to determine the amount of available memory manually.
When initializing through Multiboot, we first convert the physical address to virtual. Theoretically, GRUB can position the structure anywhere, so if the address extends beyond the page, you need to allocate a virtual page in the Page directory. In practice, the structure almost always lies next to the first megabyte, which we have already allocated at the boot stage. Just in case, we check the flag that the memory card is present and proceed to its analysis.
pub mod multiboot2;
pub mod multiboot;
use super::arch;
unsafe fn process_pointer(mb_pointer: usize) -> usize {
//if in first 4 MB - map to kernel address space
if mb_pointer < 0x400000 {
arch::KERNEL_BASE | mb_pointer
} else {
arch::paging::allocate_page(mb_pointer, arch::MB_INFO_BASE,
arch::paging::PDEntryFlags::PRESENT |
arch::paging::PDEntryFlags::WRITABLE |
arch::paging::PDEntryFlags::HUGE_PAGE
);
arch::MB_INFO_BASE | mb_pointer
}
}
pub fn init_with_mb1(mb_pointer: usize) {
let ln_pointer = unsafe { process_pointer(mb_pointer) };
println!("mb pointer 0x{:X}", ln_pointer);
let mb_info = multiboot::from_ptr(ln_pointer);
println!("mb flags: {:?}", mb_info.flags().unwrap());
if mb_info.flags().unwrap().contains(multiboot::MBInfoFlags::MEM_MAP) {
multiboot::parse_mmap(mb_info);
println!("Multiboot memory map parsed, physical memory map has been built");
} else {
panic!("MB mmap is not presented");
}
}A memory card is a linked list for which the initial physical address is specified in the basic structure (do not forget to translate everything into virtual ones) and the size of the array in bytes. You have to iterate through the list based on the size of each element, since theoretically their sizes can differ. This is what the iteration looks like:
impl MultibootInfo {
. . . . . .
pub unsafe fn get_mmap(&self, index: usize) -> Option<*const MemMapEntry> {
use crate::arch::get_mb_pointer_base;
let base: usize = get_mb_pointer_base(self.mmap_addr as usize);
let mut iter: *const MemMapEntry = (base as u32 + self.mmap_addr) as *const MemMapEntry;
for _i in 0..index {
iter = ((iter as usize) + ((*iter).size as usize) + 4) as *const MemMapEntry;
if ((iter as usize) - base) >= (self.mmap_addr + self.mmap_lenght) as usize {
return None
} else {}
}
Some(iter)
}
}When parsing a memory card, we iterate through the GRUB structure and convert it to a bitmap, which OS1 will work with to manage physical memory. I decided to confine myself to a small set of available values for control - free, busy, reserved, unavailable, although GRUB and BIOS provide more options. So, we iterate over the map entries and convert their state from GRUB / BIOS values to values for OS1:
pub fn parse_mmap(mbi: &MultibootInfo) {
unsafe {
let mut mmap_opt = mbi.get_mmap(0);
let mut i: usize = 1;
loop {
let mmap = mmap_opt.unwrap();
crate::memory::physical::map((*mmap).addr as usize, (*mmap).len as usize, translate_multiboot_mem_to_os1(&(*mmap).mtype));
mmap_opt = mbi.get_mmap(i);
match mmap_opt {
None => break,
_ => i += 1,
}
}
}
}
pub fn translate_multiboot_mem_to_os1(mtype: &u32) -> usize {
use crate::memory::physical::{RESERVED, UNUSABLE, USABLE};
match mtype {
&MULTIBOOT_MEMORY_AVAILABLE => USABLE,
&MULTIBOOT_MEMORY_RESERVED => UNUSABLE,
&MULTIBOOT_MEMORY_ACPI_RECLAIMABLE => RESERVED,
&MULTIBOOT_MEMORY_NVS => UNUSABLE,
&MULTIBOOT_MEMORY_BADRAM => UNUSABLE,
_ => UNUSABLE
}
}Physical memory is managed in the memory :: physical module, for which we call the map method above, passing it the region's address, its length and state. All 4 GB of memory potentially available to the system and divided into four megabyte pages is represented by two bits in a bitmap, which allows you to store 4 states for 1024 pages. In total, this construction takes 256 bytes. A bitmap leads to terrible memory fragmentation, but it’s understandable and easy to implement, which is the main thing for my purpose.
I will remove the bitmap implementation under the spoiler so as not to clutter up the article. The structure is able to count the number of classes and free memory, mark pages by index and address, and also search for free pages (this will be needed in the future to implement the heap). The card itself is an array of 64 u32 elements, to isolate the necessary two bits (blocks), conversion to the so-called chunk (index in the array, packing of 16 blocks) and block (bit position in the chunk) is used.
pub const USABLE: usize = 0;
pub const USED: usize = 1;
pub const RESERVED: usize = 2;
pub const UNUSABLE: usize = 3;
pub const DEAD: usize = 0xDEAD;
struct PhysMemoryInfo {
pub total: usize,
used: usize,
reserved: usize,
chunks: [u32; 64],
}
impl PhysMemoryInfo {
// returns (chunk, page)
pub fn find_free(&self) -> (usize, usize) {
for chunk in 0..64 {
for page in 0.. 16 {
if ((self.chunks[chunk] >> page * 2) & 3) ^ 3 == 3 {
return (chunk, page)
} else {}
}
}
(DEAD, 0)
}
// marks page to given flag and returns its address
pub fn mark(&mut self, chunk: usize, block: usize, flag: usize) -> usize {
self.chunks[chunk] = self.chunks[chunk] ^ (3 << (block * 2));
let mask = (0xFFFFFFFC ^ flag).rotate_left(block as u32 * 2);
self.chunks[chunk] = self.chunks[chunk] & (mask as u32);
if flag == USED {
self.used += 1;
} else if flag == UNUSABLE || flag == RESERVED {
self.reserved += 1;
} else {
if self.used > 0 {
self.used -= 1;
}
}
(chunk * 16 + block) << 22
}
pub fn mark_by_addr(&mut self, addr: usize, flag: usize) {
let block_num = addr >> 22;
let chunk: usize = (block_num / 16) as usize;
let block: usize = block_num - chunk * 16;
self.mark(chunk, block, flag);
}
pub fn count_total(& mut self) {
let mut count: usize = 0;
for i in 0..64 {
let mut chunk = self.chunks[i];
for _j in 0..16 {
if chunk & 0b11 != 0b11 {
count += 1;
}
chunk = chunk >> 2;
}
}
self.total = count;
}
pub fn get_total(&self) -> usize {
self.total
}
pub fn get_used(&self) -> usize {
self.used
}
pub fn get_reserved(&self) -> usize {
self.reserved
}
pub fn get_free(&self) -> usize {
self.total - self.used - self.reserved
}
}And now we got to the analysis of one element of the map. If a map element describes a memory area less than one page of 4 MB or equal to it, we mark this page as a whole. If more - beat into pieces of 4 MB and mark each piece separately through recursion. At the stage of initialization of the bitmap, we consider all sections of memory inaccessible, so that when the card runs out, for example, 128 MB, the remaining sections are marked as inaccessible.
use lazy_static::lazy_static;
use spin::Mutex;
lazy_static! {
static ref RAM_INFO: Mutex =
Mutex::new(PhysMemoryInfo {
total: 0,
used: 0,
reserved: 0,
chunks: [0xFFFFFFFF; 64]
});
}
pub fn map(addr: usize, len: usize, flag: usize) {
// if len <= 4MiB then mark whole page with flag
if len <= 4 * 1024 * 1024 {
RAM_INFO.lock().mark_by_addr(addr, flag);
} else {
let pages: usize = len >> 22;
for map_page in 0..(pages - 1) {
map(addr + map_page << 22, 4 * 1024 * 1024, flag);
}
map(addr + (pages << 22), len - (pages << 22), flag);
}
} Heap and managing her
Virtual memory management is currently limited only to heap management, since the kernel doesn’t know much more. In the future, of course, it will be necessary to manage the entire memory, and this small manager will be rewritten. However, at the moment, all I need is static memory, which contains the executable code and the stack, and dynamic heap memory, where I will allocate the structures for multithreading. We allocate static memory at the boot stage (and so far we have limited 4 MB, because the kernel fits in them) and in general there are no problems with it now. Also, at this stage, I do not have DMA devices, so everything is extremely simple, but understandable.
I gave 512 MB of the topmost kernel memory space (0xE0000000) to the heap, I store the heap usage map (0xDFC00000) 4 MB lower. I use a bitmap to describe the state, just like for physical memory, but there are only 2 states in it - busy / free. The size of the memory block is 64 bytes - this is a lot for small variables like u32, u8, but, perhaps, it is optimal for storing data structures. Still, it is unlikely that we need to store single variables on the heap, now its main purpose is to store context structures for multitasking.
Blocks of 64 bytes are grouped into structures that describe the state of an entire 4 MB page, so we can allocate both small and large amounts of memory to several pages. I use the following terms: chunk - 64 bytes, pack - 2 KB (one u32 - 64 bytes * 32 bits per package), page - 4 MB.
#[repr(packed)]
#[derive(Copy, Clone)]
struct HeapPageInfo {
//every bit represents 64 bytes chunk of memory. 0 is free, 1 is busy
//u32 size is 4 bytes, so page information total size is 8KiB
pub _4mb_by_64b: [u32; 2048],
}
#[repr(packed)]
#[derive(Copy, Clone)]
struct HeapInfo {
//Here we can know state of any 64 bit chunk in any of 128 4-MiB pages
//Page information total size is 8KiB, so information about 128 pages requires 1MiB reserved data
pub _512mb_by_4mb: [HeapPageInfo; 128],
}When requesting memory from an allocator, I consider three cases, depending on the granularity:
- A request for memory less than 2 KB came from the allocator. You need to find a pack in which it will be free [size / 64, any non-zero remainder adds one] chunks in a row, mark these chunks as busy, return the address of the first chunk.
- A request came from the allocator for memory less than 4 MB, but more than 2 KB. You need to find a page that has free [size / 2048, any nonzero remainder adds one] packs in a row. Mark [size / 2048] packs as busy; if there is a remainder, mark [remainder] chunks in the last pack as busy.
- A request for a memory of more than 4 MB came from the allocator. Find [size / 4 Mi, any nonzero balance adds one] pages in a row, mark [size / 4 Mi] pages as busy, if there is a balance - mark [balance] packs as busy. In the last pack, mark the remainder of the chunks as busy.
The search for free areas also depends on the granularity - an array is selected for iteration or bit masks. Whenever you go abroad, OOM happens. When deallocation, a similar algorithm is used, only for marking released. The freed memory is not reset. The whole code is big, I'll put it under the spoiler.
//512 MiB should be enough for kernel heap. If not - ooops...
pub const KHEAP_START: usize = 0xE0000000;
//I will keep 1MiB info about my heap in separate 4MiB page before heap at this point
pub const KHEAP_INFO_ADDR: usize = 0xDFC00000;
pub const KHEAP_CHUNK_SIZE: usize = 64;
pub fn init() {
KHEAP_INFO.lock().init();
}
#[repr(packed)]
#[derive(Copy, Clone)]
struct HeapPageInfo {
//every bit represents 64 bytes chunk of memory. 0 is free, 1 is busy
//u32 size is 4 bytes, so page information total size is 8KiB
pub _4mb_by_64b: [u32; 2048],
}
impl HeapPageInfo {
pub fn init(&mut self) {
for i in 0..2048 {
self._4mb_by_64b[i] = 0;
}
}
pub fn mark_chunks_used(&mut self, _32pack: usize, chunk: usize, n: usize) {
let mask: u32 = 0xFFFFFFFF >> (32 - n) << chunk;
self._4mb_by_64b[_32pack] = self._4mb_by_64b[_32pack] | mask;
}
pub fn mark_chunks_free(&mut self, _32pack: usize, chunk: usize, n: usize) {
let mask: u32 = 0xFFFFFFFF >> (32 - n) << chunk;
self._4mb_by_64b[_32pack] = self._4mb_by_64b[_32pack] ^ mask;
}
pub fn empty(&self) -> bool {
for i in 0..2048 {
if self._4mb_by_64b[i] != 0 {
return false
}
}
true
}
}
#[repr(packed)]
#[derive(Copy, Clone)]
struct HeapInfo {
//Here we can know state of any 64 bit chunk in any of 128 4-MiB pages
//Page information total size is 8KiB, so information about 128 pages requires 1MiB reserved data
pub _512mb_by_4mb: [HeapPageInfo; 128],
}
impl HeapInfo {
pub fn init(&mut self) {
for i in 0..128 {
self._512mb_by_4mb[i].init();
}
}
// returns page number
pub fn find_free_pages_of_size(&self, n: usize) -> usize {
if n >= 128 {
0xFFFFFFFF
} else {
let mut start_page: usize = 0xFFFFFFFF;
let mut current_page: usize = 0xFFFFFFFF;
for page in 0..128 {
if self._512mb_by_4mb[page].empty() {
if current_page - start_page == n {
return start_page
}
if start_page == 0xFFFFFFFF {
start_page = page;
}
current_page = page;
} else {
start_page = 0xFFFFFFFF;
current_page = 0xFFFFFFFF;
}
}
0xFFFFFFFF
}
}
// returns (page number, 32pack number)
pub fn find_free_packs_of_size(&self, n: usize) -> (usize, usize) {
if n < 2048 {
for page in 0..128 {
let mut start_pack: usize = 0xFFFFFFFF;
let mut current_pack: usize = 0xFFFFFFFF;
for _32pack in 0..2048 {
let _32pack_info = self._512mb_by_4mb[page]._4mb_by_64b[_32pack];
if _32pack_info == 0 {
if current_pack - start_pack == n {
return (page, start_pack)
}
if start_pack == 0xFFFFFFFF {
start_pack = _32pack;
}
current_pack = _32pack;
} else {
start_pack = 0xFFFFFFFF;
current_pack = 0xFFFFFFFF;
}
}
}
(0xFFFFFFFF, 0xFFFFFFFF)
} else {
(0xFFFFFFFF, 0xFFFFFFFF)
}
}
// returns (page number, 32pack number, chunk number)
pub fn find_free_chunks_of_size(&self, n: usize) -> (usize, usize, usize) {
if n < 32 {
for page in 0..128 {
for _32pack in 0..2048 {
let _32pack_info = self._512mb_by_4mb[page]._4mb_by_64b[_32pack];
let mask: u32 = 0xFFFFFFFF >> (32 - n);
for chunk in 0..(32-n) {
if ((_32pack_info >> chunk) & mask) ^ mask == mask {
return (page, _32pack, chunk)
}
}
}
}
(0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF)
} else {
(0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF)
}
}
fn mark_chunks_used(&mut self, page: usize, _32pack: usize, chunk: usize, n: usize) {
self._512mb_by_4mb[page].mark_chunks_used(_32pack, chunk, n);
}
fn mark_chunks_free(&mut self, page: usize, _32pack: usize, chunk: usize, n: usize) {
self._512mb_by_4mb[page].mark_chunks_free(_32pack, chunk, n);
}
fn mark_packs_used(&mut self, page: usize, _32pack:usize, n: usize) {
for i in _32pack..(_32pack + n) {
self._512mb_by_4mb[page]._4mb_by_64b[i] = 0xFFFFFFFF;
}
}
fn mark_packs_free(&mut self, page: usize, _32pack:usize, n: usize) {
for i in _32pack..(_32pack + n) {
self._512mb_by_4mb[page]._4mb_by_64b[i] = 0;
}
}
}
use lazy_static::lazy_static;
use spin::Mutex;
lazy_static! {
static ref KHEAP_INFO: Mutex<&'static mut HeapInfo> =
Mutex::new(unsafe { &mut *(KHEAP_INFO_ADDR as *mut HeapInfo) });
}
fn allocate_n_chunks_less_than_pack(n: usize, align: usize) -> *mut u8 {
let mut heap_info = KHEAP_INFO.lock();
let (page, _32pack, chunk) = heap_info.find_free_chunks_of_size(n);
if page == 0xFFFFFFFF {
core::ptr::null_mut()
} else {
let tptr: usize = KHEAP_START + 0x400000 * page + _32pack * 32 * 64 + chunk * 64;
let res = tptr % align;
let uptr = if res == 0 { tptr } else { tptr + align - res };
//check bounds: more than start and less than 4GiB - 64B
//but according to chunks error should never happen
if uptr >= KHEAP_START && uptr <= 0xFFFFFFFF - 64 * n {
heap_info.mark_chunks_used(page, _32pack, chunk, n);
uptr as *mut u8
} else {
core::ptr::null_mut()
}
}
}
fn allocate_n_chunks_less_than_page(n: usize, align: usize) -> *mut u8 {
let mut heap_info = KHEAP_INFO.lock();
let packs_n: usize = n / 32;
let lost_chunks = n - packs_n * 32;
let mut packs_to_alloc = packs_n;
if lost_chunks != 0 {
packs_to_alloc += 1;
}
let (page, pack) = heap_info.find_free_packs_of_size(packs_to_alloc);
if page == 0xFFFFFFFF {
core::ptr::null_mut()
} else {
let tptr: usize = KHEAP_START + 0x400000 * page + pack * 32 * 64;
let res = tptr % align;
let uptr = if res == 0 { tptr } else { tptr + align - res };
//check bounds: more than start and less than 4GiB - 64B
//but according to chunks error should never happen
if uptr >= KHEAP_START && uptr <= 0xFFFFFFFF - 64 * n {
heap_info.mark_packs_used(page, pack, packs_n);
if lost_chunks != 0 {
heap_info.mark_chunks_used(page, pack + packs_to_alloc, 0, lost_chunks);
}
uptr as *mut u8
} else {
core::ptr::null_mut()
}
}
}
//unsupported yet
fn allocate_n_chunks_more_than_page(n: usize, align: usize) -> *mut u8 {
let mut heap_info = KHEAP_INFO.lock();
let packs_n: usize = n / 32;
let lost_chunks = n - packs_n * 32;
let mut packs_to_alloc = packs_n;
if lost_chunks != 0 {
packs_to_alloc += 1;
}
let pages_n: usize = packs_to_alloc / 2048;
let mut lost_packs = packs_to_alloc - pages_n * 2048;
let mut pages_to_alloc = pages_n;
if lost_packs != 0 {
pages_to_alloc += 1;
}
if lost_chunks != 0 {
lost_packs -= 1;
}
let page = heap_info.find_free_pages_of_size(pages_to_alloc);
if page == 0xFFFFFFFF {
core::ptr::null_mut()
} else {
let tptr: usize = KHEAP_START + 0x400000 * page;
let res = tptr % align;
let uptr = if res == 0 { tptr } else { tptr + align - res };
//check bounds: more than start and less than 4GiB - 64B * n
//but according to chunks error should never happen
if uptr >= KHEAP_START && uptr <= 0xFFFFFFFF - 64 * n {
for i in page..(page + pages_n) {
heap_info.mark_packs_used(i, 0, 2048);
}
if lost_packs != 0 {
heap_info.mark_packs_used(page + pages_to_alloc, 0, lost_packs);
}
if lost_chunks != 0 {
heap_info.mark_chunks_used(page + pages_to_alloc, lost_packs, 0, lost_chunks);
}
uptr as *mut u8
} else {
core::ptr::null_mut()
}
}
}
// returns pointer
pub fn allocate_n_chunks(n: usize, align: usize) -> *mut u8 {
if n < 32 {
allocate_n_chunks_less_than_pack(n, align)
} else if n < 32 * 2048 {
allocate_n_chunks_less_than_page(n, align)
} else {
allocate_n_chunks_more_than_page(n, align)
}
}
pub fn free_chunks(ptr: usize, n: usize) {
let page: usize = (ptr - KHEAP_START) / 0x400000;
let _32pack: usize = ((ptr - KHEAP_START) - (page * 0x400000)) / (32 * 64);
let chunk: usize = ((ptr - KHEAP_START) - (page * 0x400000) - (_32pack * (32 * 64))) / 64;
let mut heap_info = KHEAP_INFO.lock();
if n < 32 {
heap_info.mark_chunks_free(page, _32pack, chunk, n);
} else if n < 32 * 2048 {
let packs_n: usize = n / 32;
let lost_chunks = n - packs_n * 32;
heap_info.mark_packs_free(page, _32pack, packs_n);
if lost_chunks != 0 {
heap_info.mark_chunks_free(page, _32pack + packs_n, 0, lost_chunks);
}
} else {
let packs_n: usize = n / 32;
let pages_n: usize = packs_n / 2048;
let lost_packs: usize = packs_n - pages_n * 2048;
let lost_chunks = n - packs_n * 32;
for i in page..(page + pages_n) {
heap_info.mark_packs_free(i, 0, 2048);
}
if lost_packs != 0 {
heap_info.mark_packs_free(page + pages_n, 0, lost_packs);
}
if lost_chunks != 0 {
heap_info.mark_chunks_free(page + pages_n, packs_n, 0, lost_chunks);
}
}
}Allocation and Page fault
In order to use the heap, you need an allocator. Adding it will open for us a vector, trees, hash tables, boxes and more, without which it is next to impossible to live on. As soon as we plug in the alloc module and declare a global allocator, life will immediately become easier.
The implementation of the allocator is very simple - it simply refers to the mechanism described above.
use alloc::alloc::{GlobalAlloc, Layout};
pub struct Os1Allocator;
unsafe impl Sync for Os1Allocator {}
unsafe impl GlobalAlloc for Os1Allocator {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
use super::logical::{KHEAP_CHUNK_SIZE, allocate_n_chunks};
let size = layout.size();
let mut chunk_count: usize = 1;
if size > KHEAP_CHUNK_SIZE {
chunk_count = size / KHEAP_CHUNK_SIZE;
if KHEAP_CHUNK_SIZE * chunk_count != size {
chunk_count += 1;
}
}
allocate_n_chunks(chunk_count, layout.align())
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
use super::logical::{KHEAP_CHUNK_SIZE, free_chunks};
let size = layout.size();
let mut chunk_count: usize = 1;
if size > KHEAP_CHUNK_SIZE {
chunk_count = size / KHEAP_CHUNK_SIZE;
if KHEAP_CHUNK_SIZE * chunk_count != size {
chunk_count += 1;
}
}
free_chunks(ptr as usize, chunk_count);
}
}The allocator in lib.rs is turned on as follows:
#![feature(alloc, alloc_error_handler)]
extern crate alloc;
#[global_allocator]
static ALLOCATOR: memory::allocate::Os1Allocator = memory::allocate::Os1Allocator;И при попытке просто так аллоцироваться мы получим Page fault exception, ведь мы еще не проработали выделение виртуальной памяти. Ну как же так! Что ж, придется возвращаться к материалу предыдущей статьи и дописывать исключения. Я решил реализовать ленивую аллокацию виртуальной памяти, то есть чтобы страница выделялась не в момент запроса памяти, а в момент попытки обращения к ней. Благо, процессор x86 разрешает и даже поощряет это. После обработки Page fault он возвращается к той инструкции, которая вызвала исключение, и выполняет ее повторно, а еще предоставляет в обработчик исключения всю необходимую информацию — в стеке будет находиться код ошибки, по которому можно восстановить картину, а в регистре CR2 — виртуальный адрес, по которому отсутствует страница.
Сначала сохраним состояние процессора, а то мало ли что случится. Достанем код ошибки из стека со смещением 32 (мы сложили все регистры в стек, чтобы позже восстановить состояние процессора, поэтому нужно смещение в 32 байта), передадим как второй аргумент. Виртуальный адрес передадим как первый аргумент и вызовем обработчик в Rust. После обработки главное не забыть восстановить состояние и очистить код ошибки, чтобы указатель стека стоял на значении адреса возврата. К сожалению, нигде не написано, что перед iret нужно чистить код ошибки, поэтому я долго думал, почему у меня после Page fault сразу возникает Protection fault. Так что если вы столкнулись с непонятным Protection fault — вероятно, у вас в стеке еще лежит код ошибки.
eE_page_fault:
pushad
mov eax, [esp + 32]
push eax
mov eax, cr2
push eax
call kE_page_fault
pop eax
pop eax
popad
add esp, 4
iretв Rust обработчик разбирает код ошибки и преобразует его во флаги, которые необходимы таблице страниц. Я делаю это для простоты, чтобы не отслеживать адресное пространство. Также обработчик запрашивает свободную и доступную физическую страницу у менеджера физической памяти. Полученный адрес передается в менеджер виртуальной памяти для аллокации с нужными флагами.
bitflags! {
struct PFErrorCode: usize {
const PROTECTION = 1; //1 - protection caused, 0 - not present page caused
const WRITE = 1 << 1; //1 - write caused, 0 - read caused
const USER_MODE = 1 << 2; //1 - from user mode, 0 - from kernel
const RESERVED = 1 << 3; //1 - reserved page (PAE/PSE), 0 - not
const INSTRUCTION = 1 << 4; //1 - instruction fetch caused, 0 - not
}
}
impl PFErrorCode {
pub fn to_pd_flags(&self) -> super::super::paging::PDEntryFlags {
use super::super::paging;
let mut flags = paging::PDEntryFlags::empty();
if self.contains(PFErrorCode::WRITE) {
flags.set(paging::PDEntryFlags::WRITABLE, true);
}
if self.contains(PFErrorCode::USER_MODE) {
flags.set(paging::PDEntryFlags::USER_ACCESSIBLE, true);
}
flags
}
}
#[no_mangle]
pub unsafe extern fn kE_page_fault(ptr: usize, code: usize) {
use super::super::paging;
println!("Page fault occured at addr 0x{:X}, code {:X}", ptr, code);
let phys_address = crate::memory::physical::alloc_page();
let code_flags: PFErrorCode = PFErrorCode::from_bits(code).unwrap();
if !code_flags.contains(PFErrorCode::PROTECTION) {
//page not presented, we need to allocate the new one
let mut flags: paging::PDEntryFlags = code_flags.to_pd_flags();
flags.set(paging::PDEntryFlags::HUGE_PAGE, true);
paging::allocate_page(phys_address, ptr, flags);
println!("Page frame allocated at Paddr {:#X} Laddr {:#X}", phys_address, ptr);
} else {
panic!("Protection error occured, cannot handle yet");
}
}Возврата физической памяти на данный момент не происходит, только возврат виртуальной. Что ж, теперь можно проверить как работает наша куча. Для этого я создам вектор большого размера и заполню его числами. После этого я создам второй вектор меньшего размера и проверю, какие виртуальные адреса занимают оба вектора. Если все произойдет правильно, то второй вектор должен занять память, освобожденную при переаллокации первого вектора с его ростом:
println!("memory: total {} used {} reserved {} free {}", memory::physical::total(), memory::physical::used(), memory::physical::reserved(), memory::physical::free());
use alloc::vec::Vec;
let mut vec: Vec = Vec::new();
for i in 0..1000000 {
vec.push(i);
}
println!("vec len {}, ptr is {:?}", vec.len(), vec.as_ptr());
println!("Still works, check reusage!");
let mut vec2: Vec = Vec::new();
for i in 0..10 {
vec2.push(i);
}
println!("vec2 len {}, ptr is {:?}, vec is still here? {}", vec2.len(), vec2.as_ptr(), vec.get(1000).unwrap());
println!("Still works!");
println!("memory: total {} used {} reserved {} free {}", memory::physical::total(), memory::physical::used(), memory::physical::reserved(), memory::physical::free()); Вот что получилось в результате: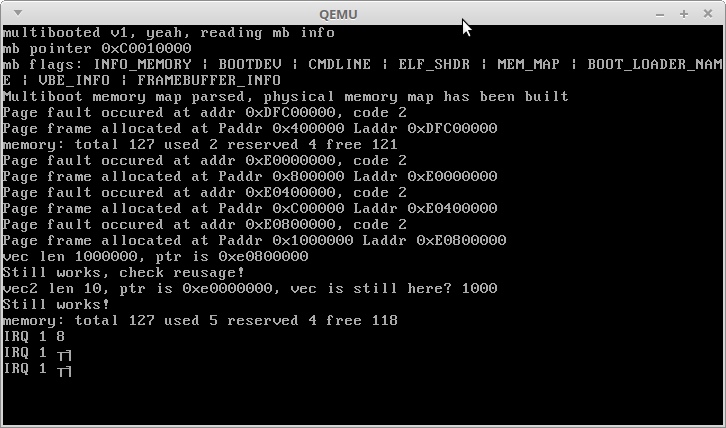
As you can see, memory allocation works out, although of course a millionth cycle with a large number of realizations takes a long time. A vector with a million integers after all allocations occupies an address of 3.5 GB + 3 MB, as expected. The first megabyte of the heap was freed and a second small vector was placed at its 3.5 GB address.
IRQ 1 and incomprehensible characters - the reaction of my kernel to interrupts from the Alt + PrntScrn keys :)
So, we got a working bunch, and therefore Rust data structures - now we can create as many objects as we like, which means we can store the state of the tasks that our processor performs!
In the next article, I will talk about how to implement basic multitasking and run two silly functions in parallel threads on the same processor.
Thanks for attention!