SIEM Depths: Out-of-Box Correlation. Part 5. Methodology for developing correlation rules
We conclude the series of articles devoted to the correlation rules that work out of the box. We set a goal to formulate an approach that would allow us to create correlation rules that can work “out of the box” with a minimum amount of false positives.

Image: Software Marketing
All key points of the article are available in the conclusion , in the same place this methodology is presented in the form of a graphic diagram .
Briefly about what was in the previous articles: they described what a set of fields of a normalized event should look like - a diagram ; which event categorization system to use; how to unify the process of normalization of events using a categorization system and a scheme . We also examined the context of the implementation of correlation rules and examined what SIEM should know about the Automated System (AS) that it is monitoring, and why.
All the above approaches and reasoning are the blocks from which the methodology for developing correlation rules is built. It's time to put them together and see the whole picture.
The entire methodology for developing correlation rules consists of four blocks:
Correlation rules operate on events that generate sources. In this regard, it is extremely important that the sources required for the correlation rules are present in the speakers and are correctly configured.
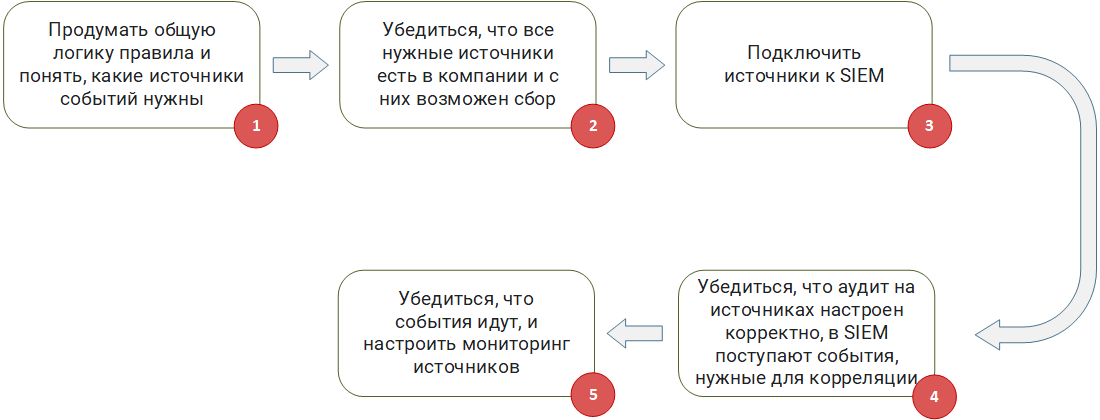
Preparing sources and environments
Step 1 : To think over the general logic of the rule and understand what sources of events are needed. If you are developing from scratch or taking a ready-made Sigma correlation rule , you need to understand based on events from which sources it will work.
Step 2 : Make sure that all the necessary sources are in the company and they can be collected.A situation is possible when a rule operates on a chain of events from several sources of the form (event A from source 1) - (event B from source 2) - (event C from source 3) for 5 minutes. If your company does not have at least one source, such a rule becomes useless, as it will never work. You need to understand whether, in principle, it is possible to collect events from the necessary sources and whether your SIEM can provide it. For example, the source writes events to a file, but the file is encrypted, or a non-standard database is used on the source for storage, access to which cannot be ensured through the standard ODBC / JDBC driver.
Step 3 : Connect sources to SIEM. No matter how trite it may sound, but at this step it is necessary to implement the collection of events.There are often many problems. For example, organizational problems, when IT management categorically prohibits connecting to mission critical systems. Or technical, when without additional settings, the SIEM agent (SmartConnector, Universal Forwarder) simply “kills” the source when collecting events, leading to a denial of service. This can often be observed when connecting highly loaded DBMSs to SIEM.
Step 4 : Make sure that the audit on the sources is configured correctly, the events necessary for correlation are received in SIEM.Correlation rules expect certain types of events. They must be generated by the source. It often happens that in order to generate the events necessary for the rules, the source must be additionally configured: advanced audit is enabled and log output in a specific format is configured.
Enabling extended auditing often affects the amount of event flow (EPS) received by the SIEM from the source. Due to the fact that the source and SIEM are in the area of responsibility of different departments, there is always a risk that the extended audit may be disabled and, as a result, the necessary types of events will stop coming to SIEM. This problem can be partially detected by monitoring the flow of events for each source, or rather, monitoring the change in Events per Second (EPS).
Step 5 :Make sure events are on and set up source monitoring.In any infrastructure, sooner or later, failures in the network or the source itself appear. At this point, SIEM loses contact with the source and cannot receive events. If the source is passive and writes its logs to a file or database, events will not be lost in the event of a failure and SIEM will be able to receive them when communication is restored. If the source is active and sends events to SIEM, for example, via syslog, without saving them anywhere else, then if the failure fails, the events will be lost, and your correlation rule simply will not work, because the desired event will not wait. Digging deeper, you can see that even when working with a passive source, when restoring communication after a failure there is no guarantee that the correlation rules will work, especially those that operate with time windows. Consider the rule example described above: (event A from source 1) - (event B from source 2) - (event C from source 3) for 5 minutes. If the failure occurs after event B and the connection is restored in an hour, the correlation will not work, since event C will not arrive in the expected 5 minutes.
Keeping these features in mind, you should configure monitoring of the sources from which events are collected. This monitoring should monitor the availability of sources, the timeliness of the arrival of events from them, the power of the flow of collected events (EPS).
The triggering of the monitoring system is the first bell that speaks of the appearance of a negative factor affecting the performance of all or part of the correlation rules.
Collecting the events necessary for correlation is not enough. Events arriving at SIEM must be normalized strictly in accordance with accepted rules. We wrote about the problems of normalization and the formation of a normalization methodology in a separate article . In general, this block can be characterized as a fight against garbage in, garbage out ( GIGO ).

Normalization and enrichment of events
Step 6 and Step 7 : Categorization of events and normalization of events in accordance with the category, based on the methodology. We will not dwell on them in detail, since we considered these steps in detail in the article “Methodology for normalizing events” .
Step 8 :Enrichment of events with missing and additional information, in accordance with the category. Often, incoming events do not always contain information to the extent necessary for the correlation rules to work. For example, an event contains only the IP address of the host, but there is no information about its FQDN or Hostname. Another example: an event contains a user ID, but there is no username in the event. In this case, the necessary information should be extracted from external sources - databases, domain controllers or other directories and added to the event.
It is important to note that the categorization of events occurs at the very beginning - before normalization. In addition to the fact that the category determines the rules for normalizing the event, it also sets the list of data that must be sought in external sources if they are not in the event itself.
After you have prepared the input data (events) and proceeded to the development of correlation rules, it is necessary to take into account the specifics of the incoming events, the AS itself and its variability. More about this was in the article “System Model as a Context of Correlation Rules” .
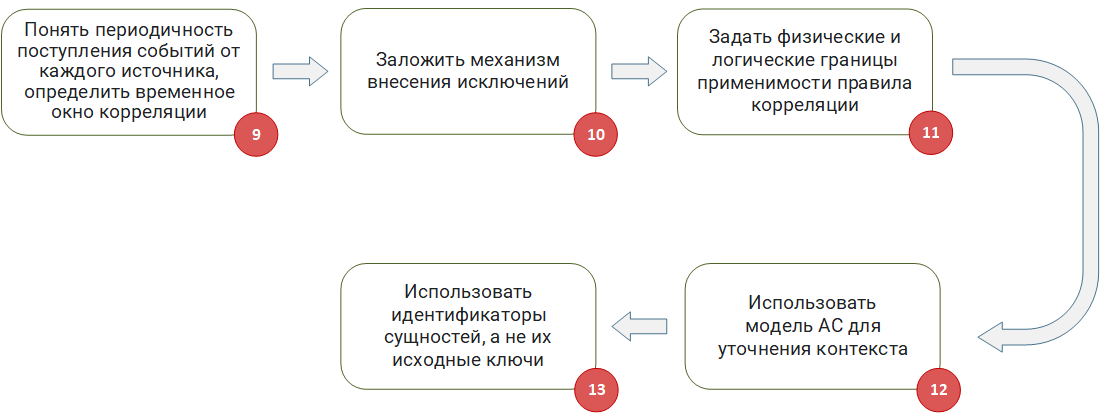
Adaptation of correlation rules to the AS context
Step 9 : Understand the frequency of events from each source, determine the time window for correlation. Quite often, correlation rules use time windows when it is necessary to expect the arrival of a certain event within a given time interval. When developing such rules, it is important to consider the delay in receiving events. They are usually caused by two factors.
First of all, the source itself may not immediately write events to the database, to a file or send it via syslog. The time of this delay must be estimated and taken into account in the rule.
Secondly , there is a delay in the delivery of events to SIEM. For example, the collection of events from the database is configured so that the request for events is performed once every 10 minutes, naturally, a correlation window of 5 minutes is not the best solution in this situation.
The problem is compounded when it is necessary to develop a correlation rule that works with events from several sources at once. In this case, it is important to understand that they may have different delivery times. In the worst case, events will come in random order with a violation of the chronology. In such a situation, the developer of the correlation rules needs to clearly understand at what time the SIEM realizes the correlation (in the event time or when the event arrived in SIEM). I note that the correlation in the time of arrival of events is the most technically simple and common option for processing events in pseudo-real-time mode. However, this option only exacerbates the above problems, and does not solve them.
If your SIEM provides a correlation in the event time, then most likely there are mechanisms for reordering events that can restore the actual chronology of events.
In the event that you understand that the time window is too large to do correlation on the stream, you must use the retro correlation mechanism, in which already saved events are selected from the SIEM database according to the schedule and run through the correlation rules.
Step 10 : Establish an Exception Mechanism.In the real world, there will always be an object with special behavior that should not be handled by a specific correlation rule, since this leads to a false positive. Therefore, at the stage of development of the rules, mechanisms should be put in place to add such objects to exceptions. For example, if your rule works with the IP addresses of machines, you need a table list where you can add addresses for which the rule will not work. Similarly, if a rule works with user logins or process names, it is necessary to preliminarily work with table exception lists in the rule logic.
This approach will allow you to automatically or manually add objects to exceptions without rewriting the body of the rule.
Step 11 :Define the physical and logical boundaries of applicability of the correlation rule. When developing a correlation rule, it is important to initially understand the limits of applicability (scope) of the rule, and whether they exist at all. When working out the logic and debugging the rule, it is necessary to focus on the specifics of this area. If a rule starts working with data that goes beyond the scope of this area, the probability of false positives increases.
Two types of scope can be distinguished: physical and logical. The physical scope is the company’s and adjacent networks, and the logical area is the parts of the AS, business applications, or business processes. Examples of the physical area: DMZ segment, internal and external subnets, remote access networks. Examples of the logical scope of the rules: APCS, accounting, PCI DSS segment, PDN segment or just specific equipment roles - domain controllers, access switches, core routers.
You can set scopes for correlation rules through table lists. They can be filled either manually or automatically. If in your company you find time for Asset management, then all the necessary data may already be contained in the AS model created in SIEM. The automatic generation of such tabular lists allows you to dynamically include in the scope new assets that appear in the company. For example, if you had a rule that worked exclusively with domain controllers, adding a new controller to the domain forest will be fixed in the model and will fall into the scope of your rule.
In general, the table lists used for exceptions can be considered as black lists, and the lists responsible for the scope of the rules as white lists.
Step 12: Use the AC model to clarify the context. In the process of developing a correlation rule that identifies malicious actions, it is important to make sure that they can actually be implemented. If this is not taken into account, the operation of the rule that revealed the potential attack will turn out to be false, since this type of attack may simply not be applicable to your infrastructure. I will explain with an example:
During the investigation, you quickly find out that on myserver.local 3389 it is closed and has never been opened by any service and Linux is there. This is a false positive that took you time to investigate.
Another example: IPS sends a signature triggering event when an attempt is made to exploit the vulnerability CVE-2017-0144, but during the investigation it turns out that the corresponding patch is installed on the attacked machine and there is no need to respond to such an incident with the highest priority.
Using data from the speaker model will help level this problem.
Step 13 : Use entity identifiers, not their source keys. As already described in the article “System Model as a Context of Correlation Rules”The IP address, FQDN, and even the MAC asset may vary. Thus, if you use the source identifiers of the asset in the correlation rule or table list, then after a while there is a high chance of receiving false positives for a completely banal reason, for example, the DHCP server simply issued this IP to another machine.
If your SIEM has a mechanism for identifying assets, tracking their changes and allowing you to operate with their identifiers, you should use identifiers, not the source keys of the asset.
Approaching the final block of creating the correlation rule, we recall that the result of the rule is an incident brought up in SIEM. Responsible professionals must respond to such an incident. Although the purpose of this series of articles does not include consideration of the incident response process, it should be noted that part of the information on the incident is generated already at the stage of creating the corresponding correlation rule.
Next, we consider the basic points that must be taken into account when configuring the parameters for triggering the correlation rule and generating an incident.

Formation of a trip agreement
Step 14 : Determine the conditions for aggregation and shutdown in the case of a large number of false positives.At the debugging stage, and in the process of its functioning, if you do not adhere to this technique :), false alarms of the rules may occur. It’s good if there are one or two trips per day, but what if one rule has thousands or tens of thousands of trips? Of course, this suggests that the rule needs to be further developed. However, it is necessary to ensure that in such situations such a massive false positive:
Problems of this kind can be solved if, when creating a correlation rule at the level of the entire system as a whole or for each rule separately, conditions for aggregating incidents and conditions for emergency shutdown of the rule can be set.
The incident aggregation mechanism will allow not to create millions of identical incidents, but to “glue” new incidents to one, provided they are identical. In extreme cases, when even the aggregation of incidents gives a significant load, it is recommended to configure automatic deactivation of the correlation rule when exceeding a given number of operations per unit time (minute, hour, day).
Step 15 : Define the rules for generating the name of the incident.This item is often neglected, especially if they are not developing rules for their company, for example, if a third-party company is responsible for implementing SIEM and developing rules. The name of the correlation rule, as well as the incident it generated, should be short and clearly reflect the essence of a particular rule.
If more than one person works with incidents and correlation rules in your company, it is recommended that you develop naming rules. They must be understood and accepted by the entire team working with SIEM.
Step 16 : Define the rules for shaping the importance of the incident. Most SIEM solutions at the last stage of creating an incident allow you to set its importance and significance. Some decisions even calculate the importance automatically, based on the context of the incident and the objects involved in it.
In the event that your SIEM operates exclusively automatic calculation of the importance of incidents, it is worthwhile to figure out on the basis of what and by what formula it is calculated. For example, if importance is calculated on the basis of the importance of the assets involved in the incident, you need to take seriously the issues of asset management (Asset Management) in a company.
If you set the importance of an incident manually, it is recommended that you develop a calculation formula that takes into account at least the following:
Also, as in naming incidents, it is important that all interested parties clearly and equally understand the rules by which the importance of an incident is formed.
Summing up the results of our series of articles, I note that it is possible, in my opinion, to create correlation rules that work out of the box. The solution may be a fusion of organizational and technical approaches. SIEM itself must be able to do something, but specialists who operate it must do and know something.
To summarize:
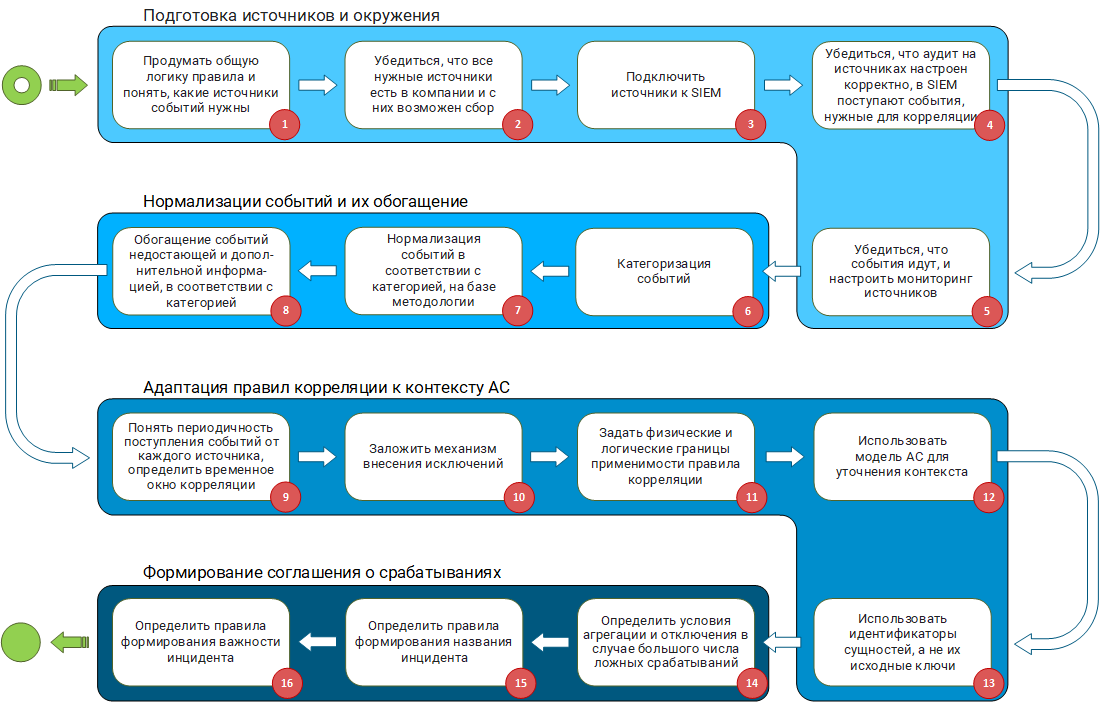
Methodology for developing correlation rules working out of the box
Many thanks to everyone who mastered the entire series of articles, or at least read through to these lines. If you have any questions - write in a personal or ask them in the comments. I will be glad to discuss.
Series of articles:
SIEM Depths: Out of the Box correlations. Part 1: Pure marketing or an unsolvable problem?
SIEM Depths: Out-of-Box Correlation. Part 2. Data schema as a reflection of the “world” model of the
SIEM Depth: “out of the box” correlations. Part 3.1. Categorization of
SIEM Depth Events : Out-of-Box Correlations. Part 3.2.
SIEM Depth Events Normalization Methodology : Out-of-Box Correlations. Part 4. System model as a context of SIEM
Depth correlation rules : out-of-box correlations. Part 5. Methodology for the development of correlation rules ( This article )
Image: Software Marketing
All key points of the article are available in the conclusion , in the same place this methodology is presented in the form of a graphic diagram .
Briefly about what was in the previous articles: they described what a set of fields of a normalized event should look like - a diagram ; which event categorization system to use; how to unify the process of normalization of events using a categorization system and a scheme . We also examined the context of the implementation of correlation rules and examined what SIEM should know about the Automated System (AS) that it is monitoring, and why.
All the above approaches and reasoning are the blocks from which the methodology for developing correlation rules is built. It's time to put them together and see the whole picture.
The entire methodology for developing correlation rules consists of four blocks:
- preparation of sources and surroundings;
- normalization of events and their enrichment;
- adaptation of correlation rules to the context of AS;
- formation of an agreement on positives.
Preparing sources and environments
Correlation rules operate on events that generate sources. In this regard, it is extremely important that the sources required for the correlation rules are present in the speakers and are correctly configured.
Preparing sources and environments
Step 1 : To think over the general logic of the rule and understand what sources of events are needed. If you are developing from scratch or taking a ready-made Sigma correlation rule , you need to understand based on events from which sources it will work.
Step 2 : Make sure that all the necessary sources are in the company and they can be collected.A situation is possible when a rule operates on a chain of events from several sources of the form (event A from source 1) - (event B from source 2) - (event C from source 3) for 5 minutes. If your company does not have at least one source, such a rule becomes useless, as it will never work. You need to understand whether, in principle, it is possible to collect events from the necessary sources and whether your SIEM can provide it. For example, the source writes events to a file, but the file is encrypted, or a non-standard database is used on the source for storage, access to which cannot be ensured through the standard ODBC / JDBC driver.
Step 3 : Connect sources to SIEM. No matter how trite it may sound, but at this step it is necessary to implement the collection of events.There are often many problems. For example, organizational problems, when IT management categorically prohibits connecting to mission critical systems. Or technical, when without additional settings, the SIEM agent (SmartConnector, Universal Forwarder) simply “kills” the source when collecting events, leading to a denial of service. This can often be observed when connecting highly loaded DBMSs to SIEM.
Step 4 : Make sure that the audit on the sources is configured correctly, the events necessary for correlation are received in SIEM.Correlation rules expect certain types of events. They must be generated by the source. It often happens that in order to generate the events necessary for the rules, the source must be additionally configured: advanced audit is enabled and log output in a specific format is configured.
Enabling extended auditing often affects the amount of event flow (EPS) received by the SIEM from the source. Due to the fact that the source and SIEM are in the area of responsibility of different departments, there is always a risk that the extended audit may be disabled and, as a result, the necessary types of events will stop coming to SIEM. This problem can be partially detected by monitoring the flow of events for each source, or rather, monitoring the change in Events per Second (EPS).
Step 5 :Make sure events are on and set up source monitoring.In any infrastructure, sooner or later, failures in the network or the source itself appear. At this point, SIEM loses contact with the source and cannot receive events. If the source is passive and writes its logs to a file or database, events will not be lost in the event of a failure and SIEM will be able to receive them when communication is restored. If the source is active and sends events to SIEM, for example, via syslog, without saving them anywhere else, then if the failure fails, the events will be lost, and your correlation rule simply will not work, because the desired event will not wait. Digging deeper, you can see that even when working with a passive source, when restoring communication after a failure there is no guarantee that the correlation rules will work, especially those that operate with time windows. Consider the rule example described above: (event A from source 1) - (event B from source 2) - (event C from source 3) for 5 minutes. If the failure occurs after event B and the connection is restored in an hour, the correlation will not work, since event C will not arrive in the expected 5 minutes.
Keeping these features in mind, you should configure monitoring of the sources from which events are collected. This monitoring should monitor the availability of sources, the timeliness of the arrival of events from them, the power of the flow of collected events (EPS).
The triggering of the monitoring system is the first bell that speaks of the appearance of a negative factor affecting the performance of all or part of the correlation rules.
Normalization of events and their enrichment
Collecting the events necessary for correlation is not enough. Events arriving at SIEM must be normalized strictly in accordance with accepted rules. We wrote about the problems of normalization and the formation of a normalization methodology in a separate article . In general, this block can be characterized as a fight against garbage in, garbage out ( GIGO ).
Normalization and enrichment of events
Step 6 and Step 7 : Categorization of events and normalization of events in accordance with the category, based on the methodology. We will not dwell on them in detail, since we considered these steps in detail in the article “Methodology for normalizing events” .
Step 8 :Enrichment of events with missing and additional information, in accordance with the category. Often, incoming events do not always contain information to the extent necessary for the correlation rules to work. For example, an event contains only the IP address of the host, but there is no information about its FQDN or Hostname. Another example: an event contains a user ID, but there is no username in the event. In this case, the necessary information should be extracted from external sources - databases, domain controllers or other directories and added to the event.
It is important to note that the categorization of events occurs at the very beginning - before normalization. In addition to the fact that the category determines the rules for normalizing the event, it also sets the list of data that must be sought in external sources if they are not in the event itself.
Adapting correlation rules to AS context
After you have prepared the input data (events) and proceeded to the development of correlation rules, it is necessary to take into account the specifics of the incoming events, the AS itself and its variability. More about this was in the article “System Model as a Context of Correlation Rules” .
Adaptation of correlation rules to the AS context
Step 9 : Understand the frequency of events from each source, determine the time window for correlation. Quite often, correlation rules use time windows when it is necessary to expect the arrival of a certain event within a given time interval. When developing such rules, it is important to consider the delay in receiving events. They are usually caused by two factors.
First of all, the source itself may not immediately write events to the database, to a file or send it via syslog. The time of this delay must be estimated and taken into account in the rule.
Secondly , there is a delay in the delivery of events to SIEM. For example, the collection of events from the database is configured so that the request for events is performed once every 10 minutes, naturally, a correlation window of 5 minutes is not the best solution in this situation.
The problem is compounded when it is necessary to develop a correlation rule that works with events from several sources at once. In this case, it is important to understand that they may have different delivery times. In the worst case, events will come in random order with a violation of the chronology. In such a situation, the developer of the correlation rules needs to clearly understand at what time the SIEM realizes the correlation (in the event time or when the event arrived in SIEM). I note that the correlation in the time of arrival of events is the most technically simple and common option for processing events in pseudo-real-time mode. However, this option only exacerbates the above problems, and does not solve them.
If your SIEM provides a correlation in the event time, then most likely there are mechanisms for reordering events that can restore the actual chronology of events.
In the event that you understand that the time window is too large to do correlation on the stream, you must use the retro correlation mechanism, in which already saved events are selected from the SIEM database according to the schedule and run through the correlation rules.
Step 10 : Establish an Exception Mechanism.In the real world, there will always be an object with special behavior that should not be handled by a specific correlation rule, since this leads to a false positive. Therefore, at the stage of development of the rules, mechanisms should be put in place to add such objects to exceptions. For example, if your rule works with the IP addresses of machines, you need a table list where you can add addresses for which the rule will not work. Similarly, if a rule works with user logins or process names, it is necessary to preliminarily work with table exception lists in the rule logic.
This approach will allow you to automatically or manually add objects to exceptions without rewriting the body of the rule.
Step 11 :Define the physical and logical boundaries of applicability of the correlation rule. When developing a correlation rule, it is important to initially understand the limits of applicability (scope) of the rule, and whether they exist at all. When working out the logic and debugging the rule, it is necessary to focus on the specifics of this area. If a rule starts working with data that goes beyond the scope of this area, the probability of false positives increases.
Two types of scope can be distinguished: physical and logical. The physical scope is the company’s and adjacent networks, and the logical area is the parts of the AS, business applications, or business processes. Examples of the physical area: DMZ segment, internal and external subnets, remote access networks. Examples of the logical scope of the rules: APCS, accounting, PCI DSS segment, PDN segment or just specific equipment roles - domain controllers, access switches, core routers.
You can set scopes for correlation rules through table lists. They can be filled either manually or automatically. If in your company you find time for Asset management, then all the necessary data may already be contained in the AS model created in SIEM. The automatic generation of such tabular lists allows you to dynamically include in the scope new assets that appear in the company. For example, if you had a rule that worked exclusively with domain controllers, adding a new controller to the domain forest will be fixed in the model and will fall into the scope of your rule.
In general, the table lists used for exceptions can be considered as black lists, and the lists responsible for the scope of the rules as white lists.
Step 12: Use the AC model to clarify the context. In the process of developing a correlation rule that identifies malicious actions, it is important to make sure that they can actually be implemented. If this is not taken into account, the operation of the rule that revealed the potential attack will turn out to be false, since this type of attack may simply not be applicable to your infrastructure. I will explain with an example:
- Suppose we have a correlation rule that detects remote RDP connections to servers.
- The firewall brings up an attempt to connect to myserver.local server TCP port 3389.
- The rule is triggered, and you begin to analyze a potential incident with a high priority.
During the investigation, you quickly find out that on myserver.local 3389 it is closed and has never been opened by any service and Linux is there. This is a false positive that took you time to investigate.
Another example: IPS sends a signature triggering event when an attempt is made to exploit the vulnerability CVE-2017-0144, but during the investigation it turns out that the corresponding patch is installed on the attacked machine and there is no need to respond to such an incident with the highest priority.
Using data from the speaker model will help level this problem.
Step 13 : Use entity identifiers, not their source keys. As already described in the article “System Model as a Context of Correlation Rules”The IP address, FQDN, and even the MAC asset may vary. Thus, if you use the source identifiers of the asset in the correlation rule or table list, then after a while there is a high chance of receiving false positives for a completely banal reason, for example, the DHCP server simply issued this IP to another machine.
If your SIEM has a mechanism for identifying assets, tracking their changes and allowing you to operate with their identifiers, you should use identifiers, not the source keys of the asset.
Formation of a positive agreement
Approaching the final block of creating the correlation rule, we recall that the result of the rule is an incident brought up in SIEM. Responsible professionals must respond to such an incident. Although the purpose of this series of articles does not include consideration of the incident response process, it should be noted that part of the information on the incident is generated already at the stage of creating the corresponding correlation rule.
Next, we consider the basic points that must be taken into account when configuring the parameters for triggering the correlation rule and generating an incident.
Formation of a trip agreement
Step 14 : Determine the conditions for aggregation and shutdown in the case of a large number of false positives.At the debugging stage, and in the process of its functioning, if you do not adhere to this technique :), false alarms of the rules may occur. It’s good if there are one or two trips per day, but what if one rule has thousands or tens of thousands of trips? Of course, this suggests that the rule needs to be further developed. However, it is necessary to ensure that in such situations such a massive false positive:
- It did not affect SIEM performance.
- Among the mass of false positives, really important incidents were not lost. There is even a separate type of attack aimed at hiding the main malicious activity behind a lot of false activities .
Problems of this kind can be solved if, when creating a correlation rule at the level of the entire system as a whole or for each rule separately, conditions for aggregating incidents and conditions for emergency shutdown of the rule can be set.
The incident aggregation mechanism will allow not to create millions of identical incidents, but to “glue” new incidents to one, provided they are identical. In extreme cases, when even the aggregation of incidents gives a significant load, it is recommended to configure automatic deactivation of the correlation rule when exceeding a given number of operations per unit time (minute, hour, day).
Step 15 : Define the rules for generating the name of the incident.This item is often neglected, especially if they are not developing rules for their company, for example, if a third-party company is responsible for implementing SIEM and developing rules. The name of the correlation rule, as well as the incident it generated, should be short and clearly reflect the essence of a particular rule.
If more than one person works with incidents and correlation rules in your company, it is recommended that you develop naming rules. They must be understood and accepted by the entire team working with SIEM.
Step 16 : Define the rules for shaping the importance of the incident. Most SIEM solutions at the last stage of creating an incident allow you to set its importance and significance. Some decisions even calculate the importance automatically, based on the context of the incident and the objects involved in it.
In the event that your SIEM operates exclusively automatic calculation of the importance of incidents, it is worthwhile to figure out on the basis of what and by what formula it is calculated. For example, if importance is calculated on the basis of the importance of the assets involved in the incident, you need to take seriously the issues of asset management (Asset Management) in a company.
If you set the importance of an incident manually, it is recommended that you develop a calculation formula that takes into account at least the following:
- The importance of the scope in which the rule works. For example, an incident in the Mission critical systems zone may be more critical than if the exact same incident occurred in the Business critical systems zone.
- The importance of the assets and user accounts involved in the incident.
- The recurrence of this incident in the company.
Also, as in naming incidents, it is important that all interested parties clearly and equally understand the rules by which the importance of an incident is formed.
findings
Summing up the results of our series of articles, I note that it is possible, in my opinion, to create correlation rules that work out of the box. The solution may be a fusion of organizational and technical approaches. SIEM itself must be able to do something, but specialists who operate it must do and know something.
To summarize:
- The method consists of the following blocks:
- Preparing sources and environments.
- Normalization of events and their enrichment.
- Adaptation of correlation rules to AS context.
- Formation of an agreement on positives.
- Each unit has organizational and technical components.
- From a technical point of view, the described blocks affect almost all basic SIEM functions, from the collection of events to the generation of an incident.
- Almost the entire technical component of this methodology can be provided by existing foreign, as well as some domestic SIEM solutions.
- A more detailed consideration and justification of the steps of this methodology was given in previous articles of the cycle. Links to them are given at the end of the article.
Methodology for developing correlation rules working out of the box
Many thanks to everyone who mastered the entire series of articles, or at least read through to these lines. If you have any questions - write in a personal or ask them in the comments. I will be glad to discuss.
Series of articles:
SIEM Depths: Out of the Box correlations. Part 1: Pure marketing or an unsolvable problem?
SIEM Depths: Out-of-Box Correlation. Part 2. Data schema as a reflection of the “world” model of the
SIEM Depth: “out of the box” correlations. Part 3.1. Categorization of
SIEM Depth Events : Out-of-Box Correlations. Part 3.2.
SIEM Depth Events Normalization Methodology : Out-of-Box Correlations. Part 4. System model as a context of SIEM
Depth correlation rules : out-of-box correlations. Part 5. Methodology for the development of correlation rules ( This article )