How we made PHP 7 twice as fast as PHP 5. Part 2: optimizing bytecode in PHP 7.1
In the first part of the story, based on a presentation by Dmitry Stogov from Zend Technologies on HighLoad ++, we understood the internal structure of PHP. We learned in detail and first-hand what changes in the basic data structures allowed PHP 7 to accelerate more than twice. This could have been stopped, but already in version 7.1, the developers went much further, since they still had many ideas for optimization.
The accumulated experience working on JIT before the seven can now be interpreted, looking at the results in 7.0 without JIT and at the results of HHVM with JIT. In PHP 7.1, it was decided not to work with JIT, but again to turn to the interpreter. If earlier the optimization concerned the interpreter, then in this article we will look at the optimization of the bytecode, using the type inference that was implemented for our JIT.
Under the cut, Dmitry Stogov will show how this all works, using a simple example.
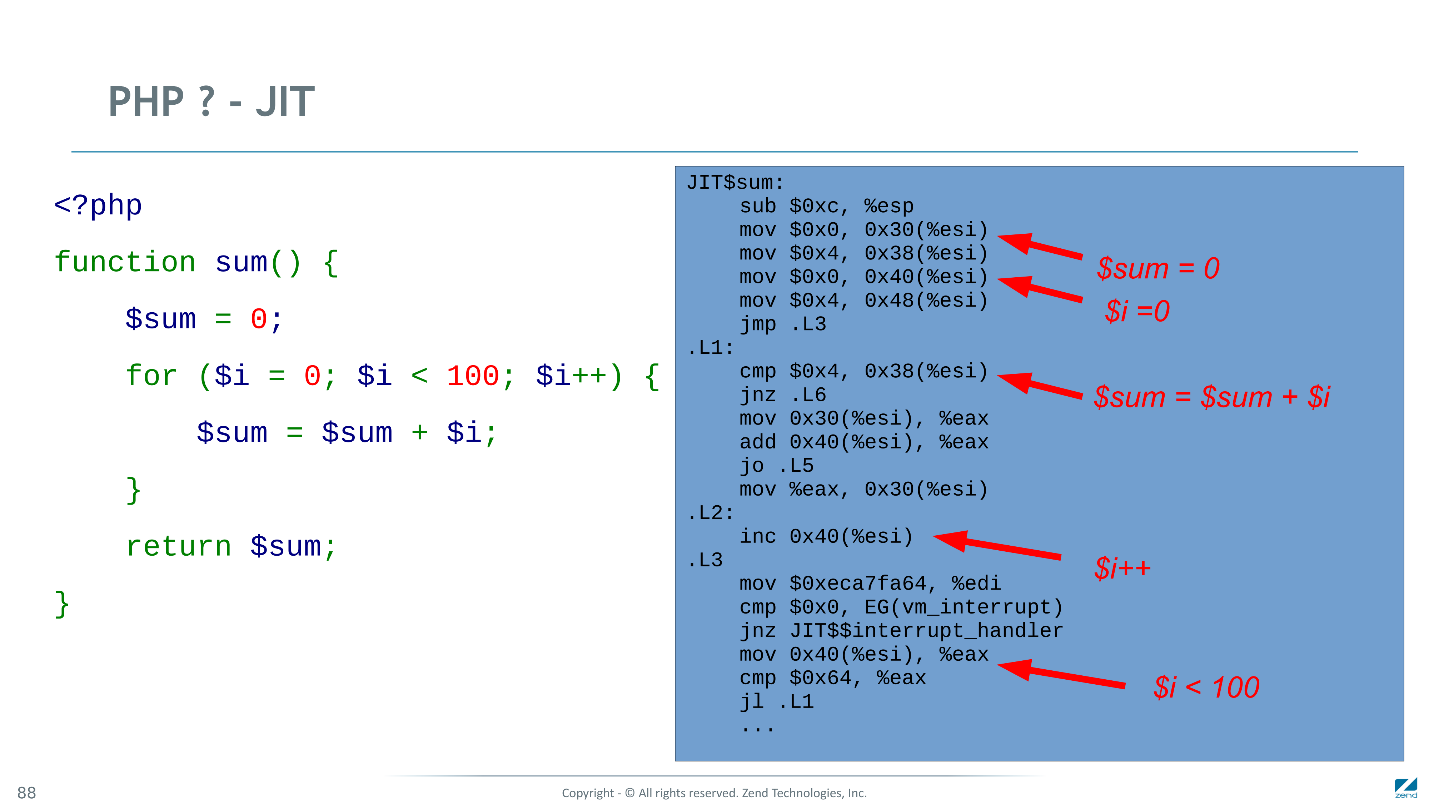
Below is the bytecode into which the standard PHP compiler compiles the function. It is single-pass - fast and dumb, but able to do its job on every HTTP request again (if OPcache is not connected).

With the advent of OPcache, we began to optimize it. Some optimization methods have long been built into OPcache , for example, methods of slit optimization - when we look at the code through the peephole, look for familiar patterns, and replace them with heuristics. These methods continue to be used in 7.0. For example, we have two operations: addition and assignment.

They can be combined in a single operation compound assignment, which performs addition directly on the result:

It may not be a scalar value and must be removed. For this, the following instruction is used

At the end there are two operators
There are only four instructions left in the loop. It seems that there is nothing further to optimize, but not for us.
Look at the code
But a person, just looking at the PHP code, will see that the variable

To do this, you need to deduce types, and to enter types, you must first build a formal representation of the data streams that the computer understands. But we will start by building a Control Flow Graph, a control dependency graph. Initially, we break the code into basic blocks - a set of instructions with one input and one output. Therefore, we cut the code in the places where the transition occurs, that is, the labels L0, L1. We also cut it after the conditional and unconditional branch operators, and then connect it with arcs that show the dependencies for control.

So we got CFG.
Well, now we need a data dependency. To do this, we use the Static Single Assignment Form - a popular representation in the world of optimizing compilers. It implies that the value of each variable can only be assigned once.

For each variable, we add an index, or reincarnation number. In every place where the assignment takes place, we put a new index, and where we use them - until the question marks, because it is not always known everywhere. For example, in the instruction
To solve this problem, the SSA introduces the pseudo-function Phi, which, if necessary, is inserted at the beginning of basic-> block, it takes all kinds of indices of one variable, which came to the basic-block from different places, and creates a new reincarnation of the variable. It is such variables that are later used to eliminate ambiguity.

Replacing all the question marks in this way, we will build the SSA.
Now we deduce types - as if trying to execute this code directly on management.

In the first block, the variables are assigned constant values - zeros, and we know for sure that these variables will be of type long. Next up is the Phi function. Long arrives at the input, and we do not know the values of other variables that came from other branches.

We believe that the output phi () we will have long.

We distribute further. We come to specific functions, for example,

These values again fall into the Phi function, the union of the sets of possible types arriving on different branches occurs. Well and so on, we continue to spread until we come to a fixed point and everything settles down.

We got a possible set of type values at every point in the program. This is already good. The computer already knows that it
In the instructions,
This output of the ranges is made in a similar, but slightly more complex way. As a result, we get a fixed range of variables

By combining these two results, we can say for sure that a double variable can

All we got is not optimization yet, this is information for optimization! Consider the instruction

For pre-increment operations, we know for sure that the operand is always long, and that overflows cannot occur. We use a highly specialized handler for this instruction, which will perform only the necessary actions without any checks.

Now compare the variable at the end of the loop. We know that the value of the variable will be only long - you can immediately check this value by comparing it with a hundred. If earlier we recorded the result of the verification in a temporary variable, and then once again checked the temporary variable for true / false, now this can be done with one instruction, that is, simplified.

Bytecode result compared to the original.

There are only 3 instructions left in the cycle, and two of them are highly specialized. As a result, the code on the right is 3 times faster than the original.
Any PHP crawl handler is just a C function . On the left is a standard handler, and at the top right is a highly specialized one. The left one checks: the type of the operand, if an overflow has occurred, if an exception has occurred. The right one just adds one and that's it. It translates into 4 machine instructions. If we went further and did JIT, then we would only need a one-time instruction

We continue to increase the speed of PHP branch 7 without JIT. PHP 7.1 will again be 60% faster on typical synthetic tests, but on real applications this almost does not give a win - only 1-2% on WordPress. This is not particularly interesting. Since August 2016, when the 7.1 branch was frozen for significant changes, we again began to work on JIT for PHP 7.2 or rather PHP 8.
In a new attempt, we use DynAsm to generate code , which was developed by Mike Paul for LuaJIT-2 . It is good because it generates code very quickly : the fact that minutes were compiled in the JIT version on LLVM now happens in 0.1-0.2 s. Already today, acceleration on bench.php on JIT is 75 times faster than PHP 5.
There is no acceleration on real applications, and this is the next challenge for us. In part, we got the optimal code, but after compiling too many PHP scripts, we clogged the processor cache, so it did not work faster. Yes, and not the speed of the code was a bottleneck in real applications ...
Perhaps DynAsm can be used to compile only certain functions, which will be selected either by the programmer or by heuristics based on counters - how many times the function has been called, how many times cycles are repeated in it, and so on. .d.
Below is the machine code that our JIT generates for the same example. Many instructions are optimally compiled: increment into one CPU instruction, variable initialization to constants into two. Where the types are not hatched, you have to bother a little more.
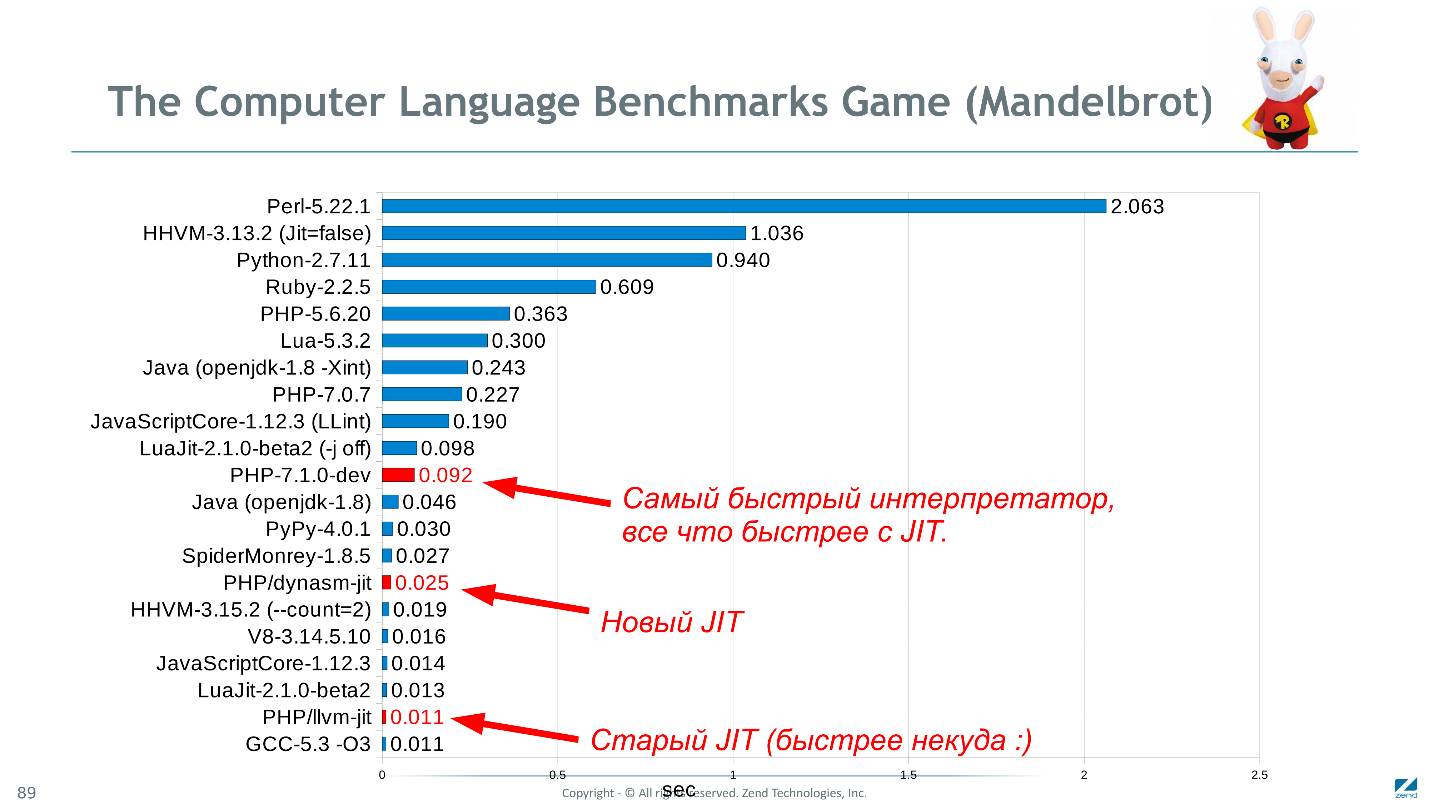
Returning to the title picture, PHP, in comparison with similar languages in the Mandelbrot test, shows very good results (although the data is relevant at the end of 2016).
The diagram shows the execution time in seconds, less is better.
Perhaps Mandelbrot is not the best test. It is computational, but simple and implemented equally in all languages. It would be nice to know how fast Wordpress would work in C ++, but there is hardly any oddity ready to rewrite it just to check, and even repeat all the perversions of the PHP code. If you have ideas for a more adequate set of benchmarks - suggest.
The accumulated experience working on JIT before the seven can now be interpreted, looking at the results in 7.0 without JIT and at the results of HHVM with JIT. In PHP 7.1, it was decided not to work with JIT, but again to turn to the interpreter. If earlier the optimization concerned the interpreter, then in this article we will look at the optimization of the bytecode, using the type inference that was implemented for our JIT.
Under the cut, Dmitry Stogov will show how this all works, using a simple example.
Bytecode optimization
Below is the bytecode into which the standard PHP compiler compiles the function. It is single-pass - fast and dumb, but able to do its job on every HTTP request again (if OPcache is not connected).
OPcache Optimizations
With the advent of OPcache, we began to optimize it. Some optimization methods have long been built into OPcache , for example, methods of slit optimization - when we look at the code through the peephole, look for familiar patterns, and replace them with heuristics. These methods continue to be used in 7.0. For example, we have two operations: addition and assignment.
They can be combined in a single operation compound assignment, which performs addition directly on the result:
ASSIGN_ADD $sum, $i. Another example is a post-increment variable that could theoretically return some kind of result. It may not be a scalar value and must be removed. For this, the following instruction is used
FREE. But if you change it to a pre-increment, then the instructionsFREEnot required. At the end there are two operators
RETURN: the first is a direct reflection of the RETURN operator in the source text, and the second is added by a dumb compiler with a closing bracket. This code will never be reached and can be deleted. There are only four instructions left in the loop. It seems that there is nothing further to optimize, but not for us.
Look at the code
$i++and its corresponding instruction - pre-increment PRE_INC. Each time it is executed:- need to check what type of variable came;
is_longwhether it is;- perform increment;
- check for overflow;
- go to the next;
- maybe check the exception.
But a person, just looking at the PHP code, will see that the variable
$ilies in the range from 0 to 100, and there can be no overflow, type checks are not necessary, and there can be no exceptions either. In PHP 7.1, we tried to teach the compiler to understand this .Optimization of Control Flow Graph
To do this, you need to deduce types, and to enter types, you must first build a formal representation of the data streams that the computer understands. But we will start by building a Control Flow Graph, a control dependency graph. Initially, we break the code into basic blocks - a set of instructions with one input and one output. Therefore, we cut the code in the places where the transition occurs, that is, the labels L0, L1. We also cut it after the conditional and unconditional branch operators, and then connect it with arcs that show the dependencies for control.
So we got CFG.
Optimization of Static Single Assignment Form
Well, now we need a data dependency. To do this, we use the Static Single Assignment Form - a popular representation in the world of optimizing compilers. It implies that the value of each variable can only be assigned once.
For each variable, we add an index, or reincarnation number. In every place where the assignment takes place, we put a new index, and where we use them - until the question marks, because it is not always known everywhere. For example, in the instruction
IS_SMALLER$ i it can come from either block L0 with number 4 or the first block with number 2. To solve this problem, the SSA introduces the pseudo-function Phi, which, if necessary, is inserted at the beginning of basic-> block, it takes all kinds of indices of one variable, which came to the basic-block from different places, and creates a new reincarnation of the variable. It is such variables that are later used to eliminate ambiguity.
Replacing all the question marks in this way, we will build the SSA.
Type optimization
Now we deduce types - as if trying to execute this code directly on management.
In the first block, the variables are assigned constant values - zeros, and we know for sure that these variables will be of type long. Next up is the Phi function. Long arrives at the input, and we do not know the values of other variables that came from other branches.
We believe that the output phi () we will have long.
We distribute further. We come to specific functions, for example,
ASSIGN_ADDand PRE_INC. Add up two long. The result can be either long or double if overflow occurs.These values again fall into the Phi function, the union of the sets of possible types arriving on different branches occurs. Well and so on, we continue to spread until we come to a fixed point and everything settles down.
We got a possible set of type values at every point in the program. This is already good. The computer already knows that it
$ican only be long or double, and can exclude some unnecessary checks. But we know that double $icannot be. How do we know? And we see a condition that limits growth $iin the cycle to a possible overflow. We will teach the computer to see this.Range Propagation Optimization
In the instructions,
PRE_INCwe never found out that i can only be an integer - it costs long or double. This happens because we did not try to infer possible ranges. Then we could answer the question whether overflow will occur or not. This output of the ranges is made in a similar, but slightly more complex way. As a result, we get a fixed range of variables
$iwith indices 2, 4, 6 7, and now we can confidently say that the increment $iwill not lead to overflow. By combining these two results, we can say for sure that a double variable can
$inever become. All we got is not optimization yet, this is information for optimization! Consider the instruction
ASSIGN_ADD. In general terms, the old value of the sum that came to this instruction could be, for example, an object. Then, after addition, the old value should have been removed. But in our case, we know for sure that there is long or double, that is, a scalar value. No destruction is required, we can replace ASSIGN_ADDwith ADD - simpler instructions. ADDuses a variable sumas both an argument and a value. For pre-increment operations, we know for sure that the operand is always long, and that overflows cannot occur. We use a highly specialized handler for this instruction, which will perform only the necessary actions without any checks.
Now compare the variable at the end of the loop. We know that the value of the variable will be only long - you can immediately check this value by comparing it with a hundred. If earlier we recorded the result of the verification in a temporary variable, and then once again checked the temporary variable for true / false, now this can be done with one instruction, that is, simplified.
Bytecode result compared to the original.
There are only 3 instructions left in the cycle, and two of them are highly specialized. As a result, the code on the right is 3 times faster than the original.
Highly specialized handlers
Any PHP crawl handler is just a C function . On the left is a standard handler, and at the top right is a highly specialized one. The left one checks: the type of the operand, if an overflow has occurred, if an exception has occurred. The right one just adds one and that's it. It translates into 4 machine instructions. If we went further and did JIT, then we would only need a one-time instruction
incl.What's next?
We continue to increase the speed of PHP branch 7 without JIT. PHP 7.1 will again be 60% faster on typical synthetic tests, but on real applications this almost does not give a win - only 1-2% on WordPress. This is not particularly interesting. Since August 2016, when the 7.1 branch was frozen for significant changes, we again began to work on JIT for PHP 7.2 or rather PHP 8.
In a new attempt, we use DynAsm to generate code , which was developed by Mike Paul for LuaJIT-2 . It is good because it generates code very quickly : the fact that minutes were compiled in the JIT version on LLVM now happens in 0.1-0.2 s. Already today, acceleration on bench.php on JIT is 75 times faster than PHP 5.
There is no acceleration on real applications, and this is the next challenge for us. In part, we got the optimal code, but after compiling too many PHP scripts, we clogged the processor cache, so it did not work faster. Yes, and not the speed of the code was a bottleneck in real applications ...
Perhaps DynAsm can be used to compile only certain functions, which will be selected either by the programmer or by heuristics based on counters - how many times the function has been called, how many times cycles are repeated in it, and so on. .d.
Below is the machine code that our JIT generates for the same example. Many instructions are optimally compiled: increment into one CPU instruction, variable initialization to constants into two. Where the types are not hatched, you have to bother a little more.
Returning to the title picture, PHP, in comparison with similar languages in the Mandelbrot test, shows very good results (although the data is relevant at the end of 2016).
The diagram shows the execution time in seconds, less is better.
Perhaps Mandelbrot is not the best test. It is computational, but simple and implemented equally in all languages. It would be nice to know how fast Wordpress would work in C ++, but there is hardly any oddity ready to rewrite it just to check, and even repeat all the perversions of the PHP code. If you have ideas for a more adequate set of benchmarks - suggest.
We will meet at PHP Russia on May 17 , we will discuss the prospects and development of the ecosystem and the experience of using PHP for really complex and cool projects. Already with us:
- Nikita Popov , one of the most prominent developers of the PHP kernel, will tell what awaits us in the upcoming release of PHP 7.4.
- Dmitry Stogov will talk about grandiose plans in PHP 8 .
- Anton Titov , author of the RoadRunner application server, will present the topic “ Developing Hybrid PHP / Go Applications Using RoadRunner ”.
Of course, this is far from all. And Call for Papers is still closed, until April 1, we are waiting for applications from those who can apply modern approaches and best practices to implement cool PHP services. Do not be afraid of competition with eminent speakers - we are looking for experience in using what they do in real projects and will help show the benefits of your cases.