Specialized chips will not save us from the “deadlock accelerators”
- Transfer

Improvements in CPU speed are slowing, and we are seeing the semiconductor industry switch to accelerator cards so that the results continue to improve markedly. Nvidia has benefited the most from this transition, however, it is part of the same trend, fueling research into neural network accelerators, FPGAs, and products such as Google’s TPUs. These accelerators have incredibly increased the speed of electronics in recent years, and many began to hope that they represent a new path of development, in connection with the slowdown of Moore's law. But a new scientific work suggests that in fact, everything is not as rosy as some would like.
Special architectures such as GPUs, TPUs, FPGAs, and ASICs, even if they work quite differently from general-purpose CPUs, still use the same functional nodes as x86, ARM, or POWER processors. And this means that the increase in speed of these accelerators also to some extent depends on the improvements associated with the scaling of transistors. But what proportion of these improvements depended on the improvement of production technologies and the increase in density associated with Moore’s law, and which part on improvements in the target areas for which these processors are intended? What percentage of improvements is only related to transistors?
Princeton University Associate Professor of Electrical Engineering David Wenzlaf and his graduate student Adi Fuchs have created a model that allows them to measure the speed of improvement. Their model uses the characteristics of 1612 CPUs and 1001 GPUs of various capacities, made on the basis of various functional units, to numerically evaluate the benefits associated with improvements to the units. Wenzlaf and Fuchs have created a metric for improving performance related to CMOS (CMOS-Driven return, CDR) progress, which can be compared to improvements acquired through chip specialization return (CSR).
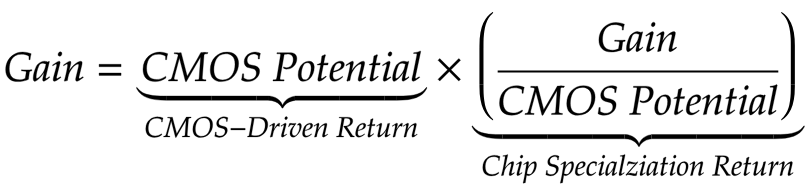
The team came to a discouraging conclusion. The advantages obtained due to the specialization of chips are fundamentally related to the number of transistors placed in a millimeter of silicon in the long term, as well as to the improvements of these transistors associated with each new functional unit. Worse, there are fundamental limitations on how much speed we can extract from improving the accelerator circuit without improving the CMOS scale.
It is important that all of the above apply in the long run. A study by Wenzlaf and Fuchs shows that speed often increases dramatically when accelerators are first commissioned. Over time, when optimal acceleration methods turn out to be studied, and best practices described, researchers come to the most optimal approach. Moreover, on accelerators, well-defined tasks from a well-studied area that can be parallelized (GPU) are well solved. However, this also means that the same properties, due to which the task can be adapted for accelerators, limit the advantage gained from this acceleration in the long run. The team called this problem "deadlock accelerators."
And the high-performance computing market has probably felt this for some time. In 2013, we wrote about the difficult road to ex-scale supercomputers. And even then, Top500 predicted that accelerators would give a one-time leap in performance ratings, but would not increase the speed of speed increase.

However, the consequences of these discoveries go beyond the high-performance computing market. For example, having studied the GPU, Wenzlaf and Fuchs found that the benefits that could not be attributed to improved CMOS were very small.
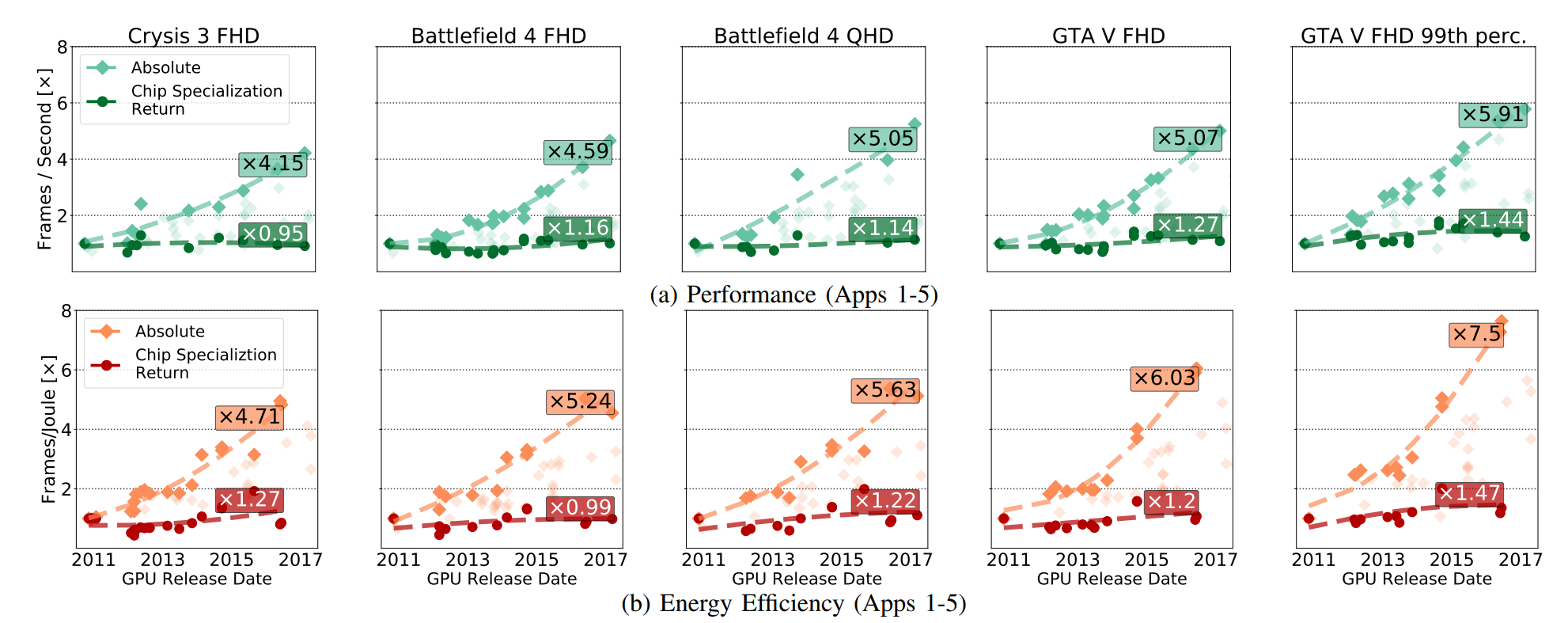
In fig. GPU absolute performance growth has been shown (including the benefits gained from the development of CMOS), and these benefits have emerged solely from the development of CSR. CSRs are about those improvements that remain if you remove all breakthroughs in CMOS technology from the GPU circuit.
The following figure clarifies the relationship of values:
Decreasing CSR does not mean slowing the GPU in absolute numbers. As Fuchs wrote:
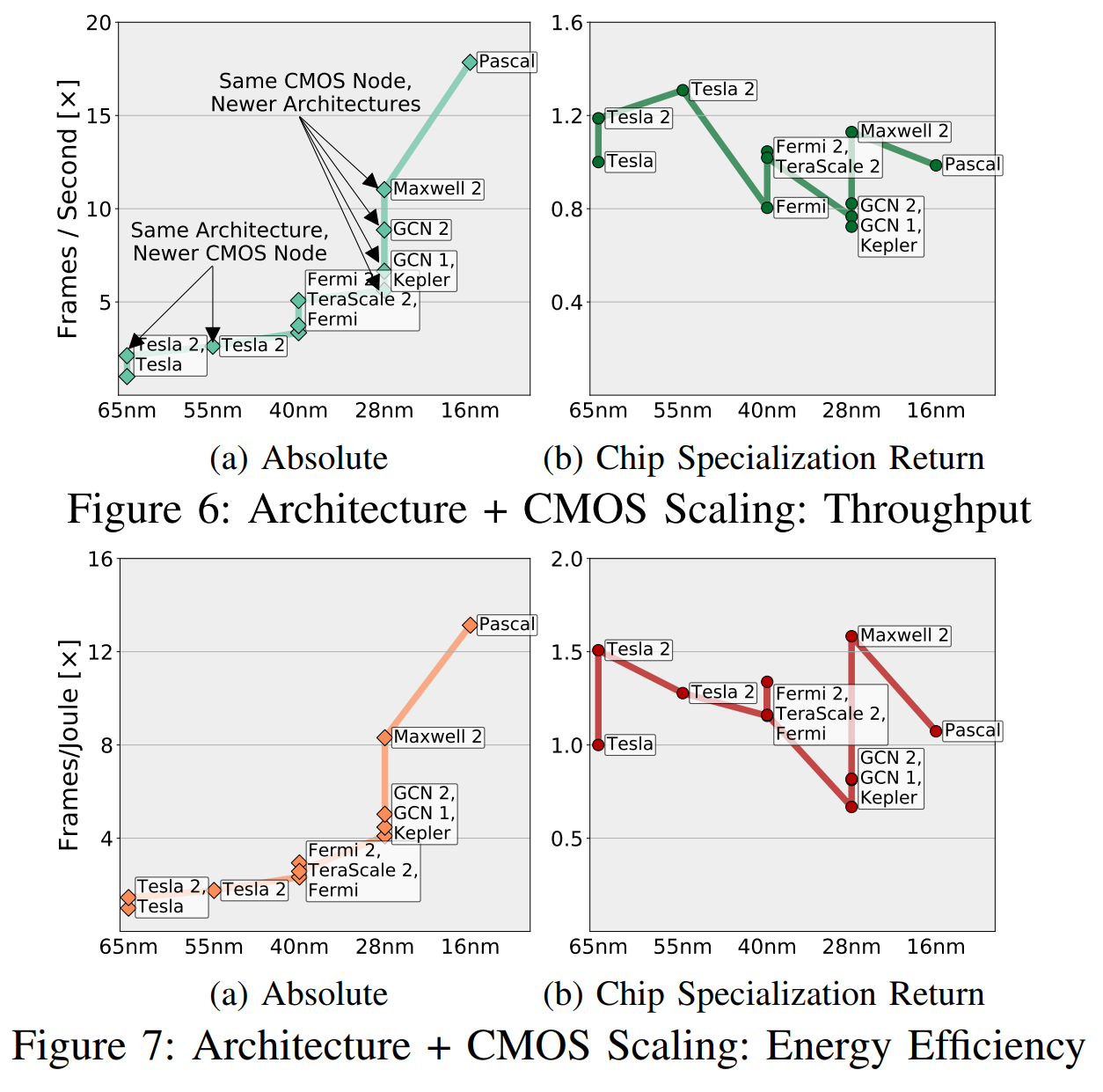
CSR normalizes the profit “based on the potential of CMOS”, and this “potential” takes into account the number of transistors and the difference in speed, efficiency in the use of energy, area, etc. (in different generations of CMOS). In fig. 6, we gave an approximate comparison of the “architecture + CMOS nodes” combinations, by triangulating the measured speeds of all applications on different combinations, and using transitive relationships between those combinations that do not have enough common applications (less than five).
Intuitively, these graphs can be understood as in Fig. 6a shows what “engineers and managers see,” and fig. 6b is "what we see, excluding the potential of CMOS." I’ll venture to suggest that you are more concerned with whether your new chip is ahead of the previous one than if it does it because of better transistors or because of better specialization.
The GPU market is well defined, designed and specialized, and both AMD and Nvidia have every reason to get ahead of each other, improving the circuitry. But, despite this, we see that for the most part, accelerations are due to factors related to CMOS, and not due to CSR.
The FPGAs and special boards for processing video codecs, studied by scientists, also fall under such characteristics, even if the relative improvement over time became more or less due to the growing market. The same characteristics that allow you to actively respond to acceleration, ultimately limit the ability of accelerators to improve their efficiency. Fuchs and Wenzlaf write about the GPU: “Although the frame rate of GPU graphics has increased by 16 times, we assume that further improvements in speed and energy efficiency will follow 1.4–2.4 times and 1.4–1.7 times, respectively” . AMD and Nvidia do not have a special space for maneuver in which you can increase speed by improving CMOS.
The implications of this work are important. She says that specific to their areas of architecture will no longer give significant improvements in speed when Moore’s law ceases to work. And even if chip developers can concentrate on improving performance in a fixed number of transistors, these improvements will be limited by the fact that well-studied processes have almost nowhere to improve.
The work indicates the need to develop a fundamentally new approach to computing. One potential alternative is Intel Meso architecture . Fuchs and Wenzlaf also proposed use alternative materials and other solutions that are beyond the scope of CMOS, including research into the possibility of using non-volatile memory as accelerators.