Random databases. Oracle Enterprise Data Quality - Enterprise Storage Shield and Sword
1. The concept of a random database.
The very first business connections of a person are described by formal and informal documents such as an application, a declaration, an employment contract, an application for placement, an application for a resource. These documents create logical connections between business processes, but, as a rule, are a product of the thinking of office managers and are poorly formalized.
The task of any at least some complicated optimization is not only to understand the formal and informal rules, but, often, bring disparate knowledge to a common information base.
Definition A random database is a set of facts, documents, manual notes, formal documents that are processed by a person for a specific business process, but cannot be fully automatically processed due to the strong influence of the human factor.
Example. The secretary formally receives the call. The caller is interested in a product or service. The caller is not known for CRM. Question: what should the caller say in order to be heard by a specialist?
To put it more precisely: how much do the secretary’s business instructions allow a formal dialogue about the business if the responsible specialist is not ready for this type of activity?
It turns out that we again come to the definition of a random database.
Maybe it contains more facts than the secretary can know. But the information received in it cannot be superfluous. In general, when random facts of a random database arrive at the input of a formalized system, then such a thing as information overload arises - and all information overload can affect the performance of not only the secretary, but the whole company.
If it is used for processing purposes, then a machine that reads the state of this information comes on the basis of logical conclusions to the state opposite to the person - information overload. Human logic is more flexible.
2. Application of the definition to real tasks.
Imagine a store in which the price tags for random goods are noticeably high or low. When you leave this store in the head of an inexperienced shopping list will remain the price of 5-7 (or even 3) of the most popular goods, the price of which can affect the size of the total check. It turns out that if it were possible to know the list of goods, the price of which buyers most often recall, then the rest of the prices could be varied in a relatively wide range.
Have you ever wondered why, before Lent, the meat at first becomes sharply cheaper, and then it can sharply rise in price, and then disappear? The price of a product, the demand for which may fall to zero, is first artificially heated, then, passing a certain level of demand, it begins to be fixed, and after a while it rises forcefully, as greed does not allow giving away illiquid goods at a fair price.
An almost similar situation exists in the data market. The most useful information is almost always hidden by secondary hypotheses about its applicability and extractability.
It is enough to lay out any information that is interesting to 5000-7000 people on any relatively unprotected resource, there are surely copy-paste sites.
Or the famous game with phone codes “Who called me?”. About a thousand sites in Runet consist only of the phone numbers of various operators in order to be a little higher in the search results, trying to somehow sell the domain name and advertising more expensive.
3. The price of the issue when working with "dirty" data.
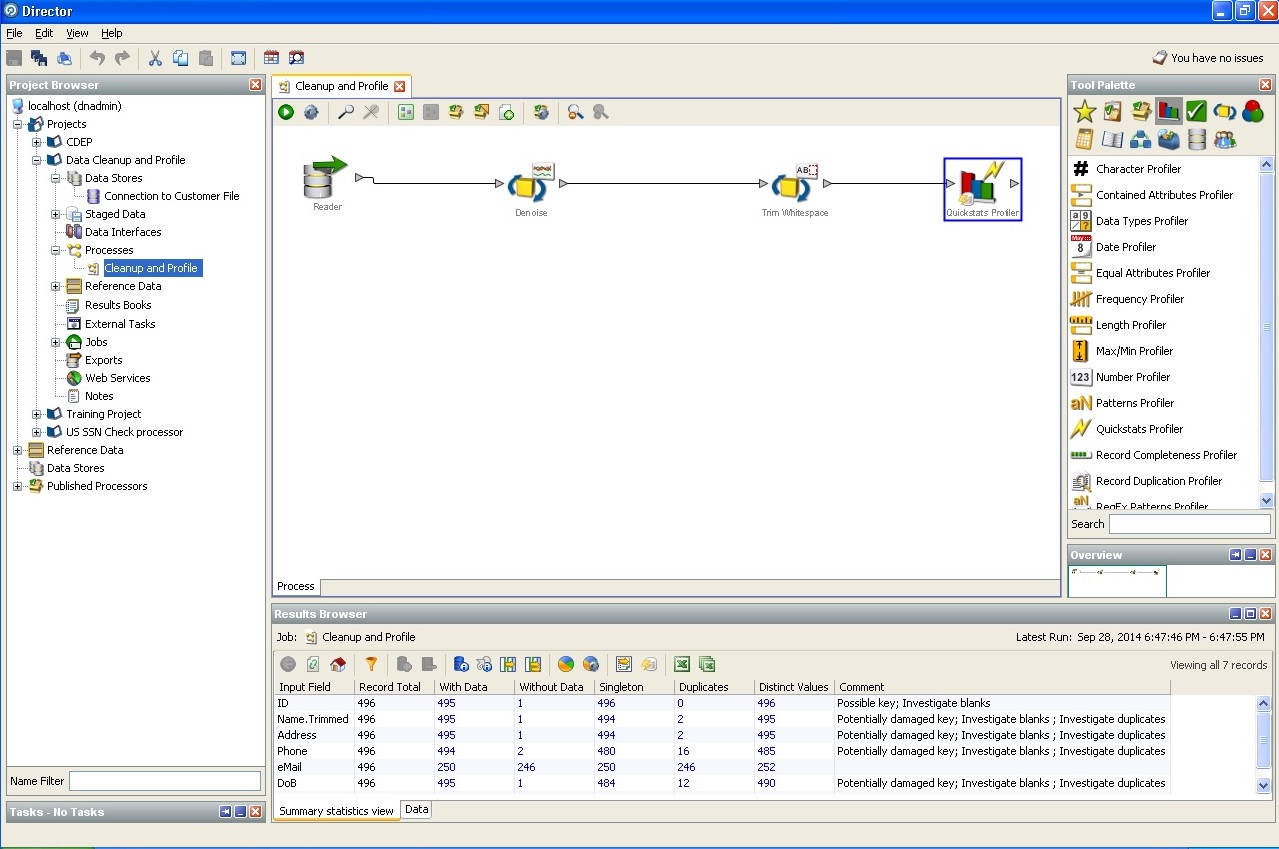
According to the research of the author of the article, up to 10% of the labor resources of each project is diverted to writing certain data cleaning procedures. If you don’t dwell on completely banal type and length, that is, unique identifiers, database integrity rules and business integrity rules, quantitative and qualitative unit scales, labor unit systems and any other states, influences, transitions, the preparation of which requires as usual statistical both logical and serious business analysis. Formalization of requirements comes to the need to formalize the fact-dimension relationship both for building repositories and for resolving issues on the front-end.
Agree, if ETL processes occupy 70% of the operating time of any storage, then saving 5-7% of resources on the correct cleaning of data on a conditional storage of 200,000 customers is already a good bonus?
We will cover a bit the issues of "dirty" data in ready-made systems. Let's say you send congratulations on a national holiday to 10,000 customers through the mail. How many people will throw your letter with the best postcard in the mailbox, if you make a mistake in the name, surname, or fill in the form incorrectly in the form? The price of your efforts can reduce the mood of any user to zero!
4. Oracle Enterprise Data Quality - the shield and sword of corporate storage.
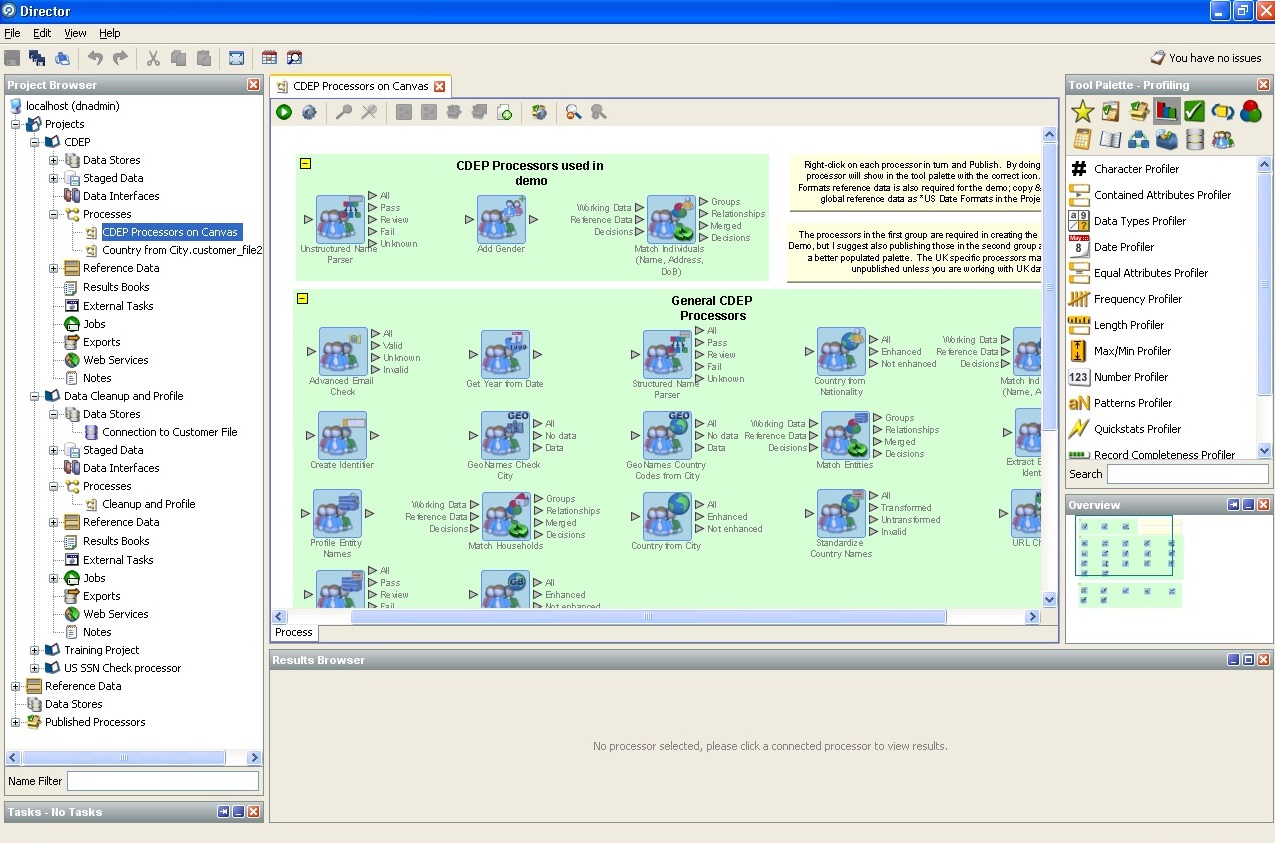
The screenshots we provide describe the features of Oracle Enterprise Data Quality.
So, let someone spill water onto your database or text document.
Here is a list of standard processors (logical units that allow
one or another hypothesis to be applied to the data, or search for the required one):
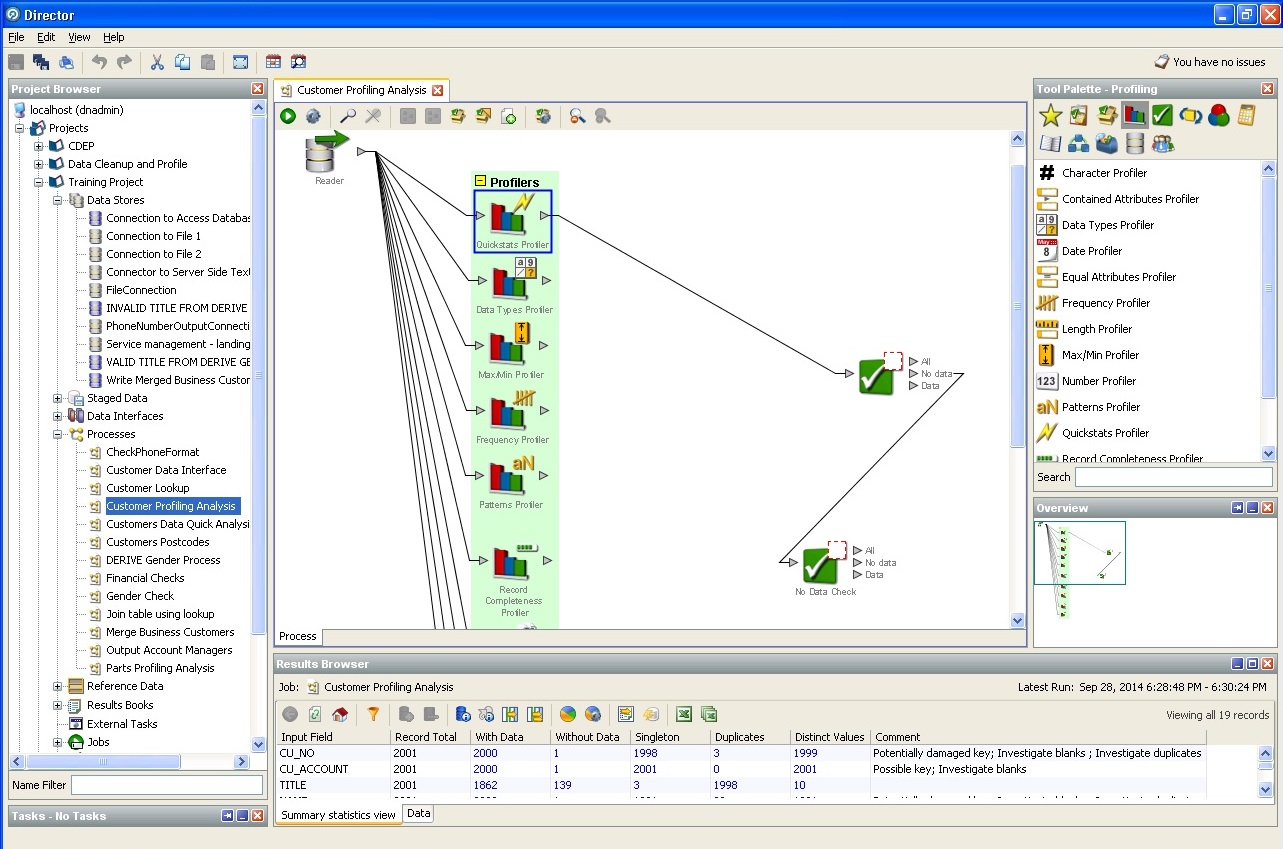
Random database profiler action:
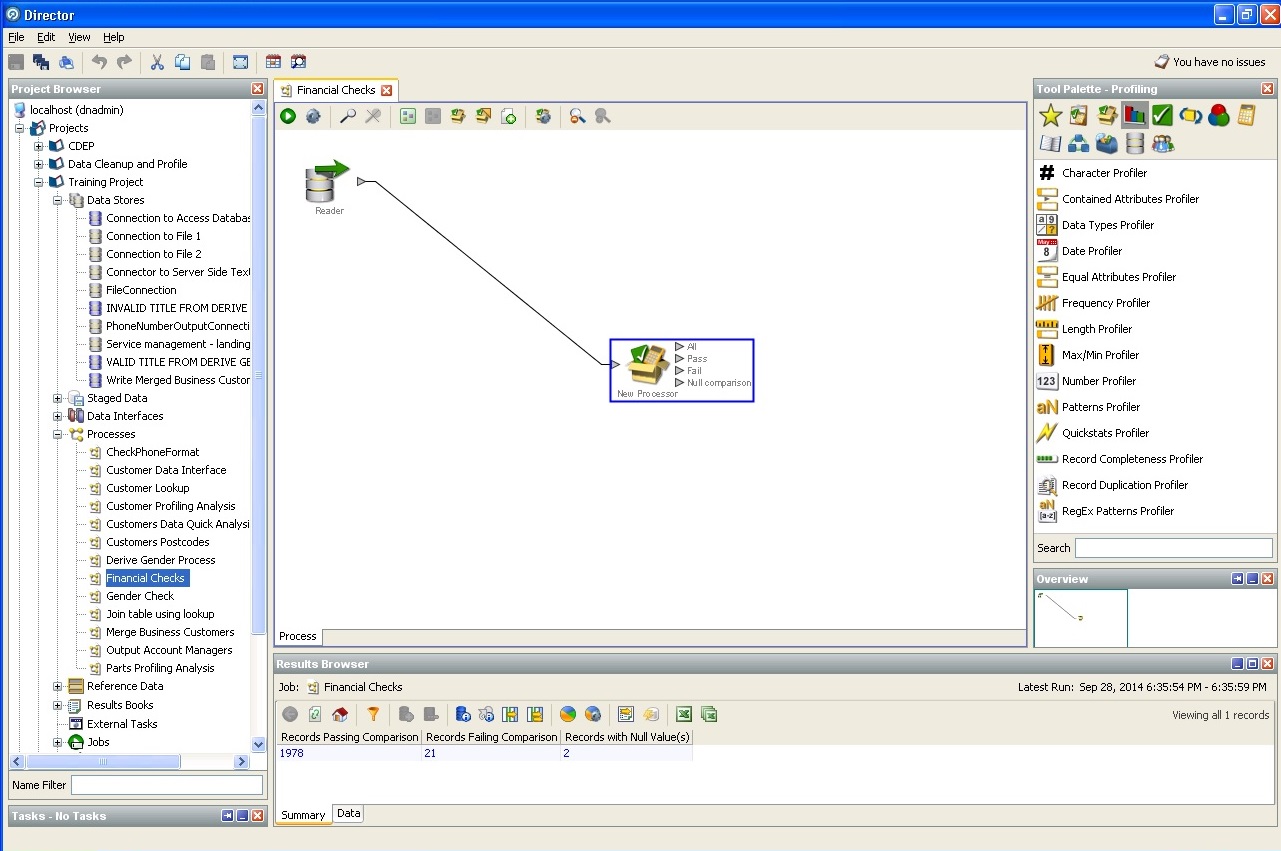
Elementary check of financial solvency:
Working with a postal code:
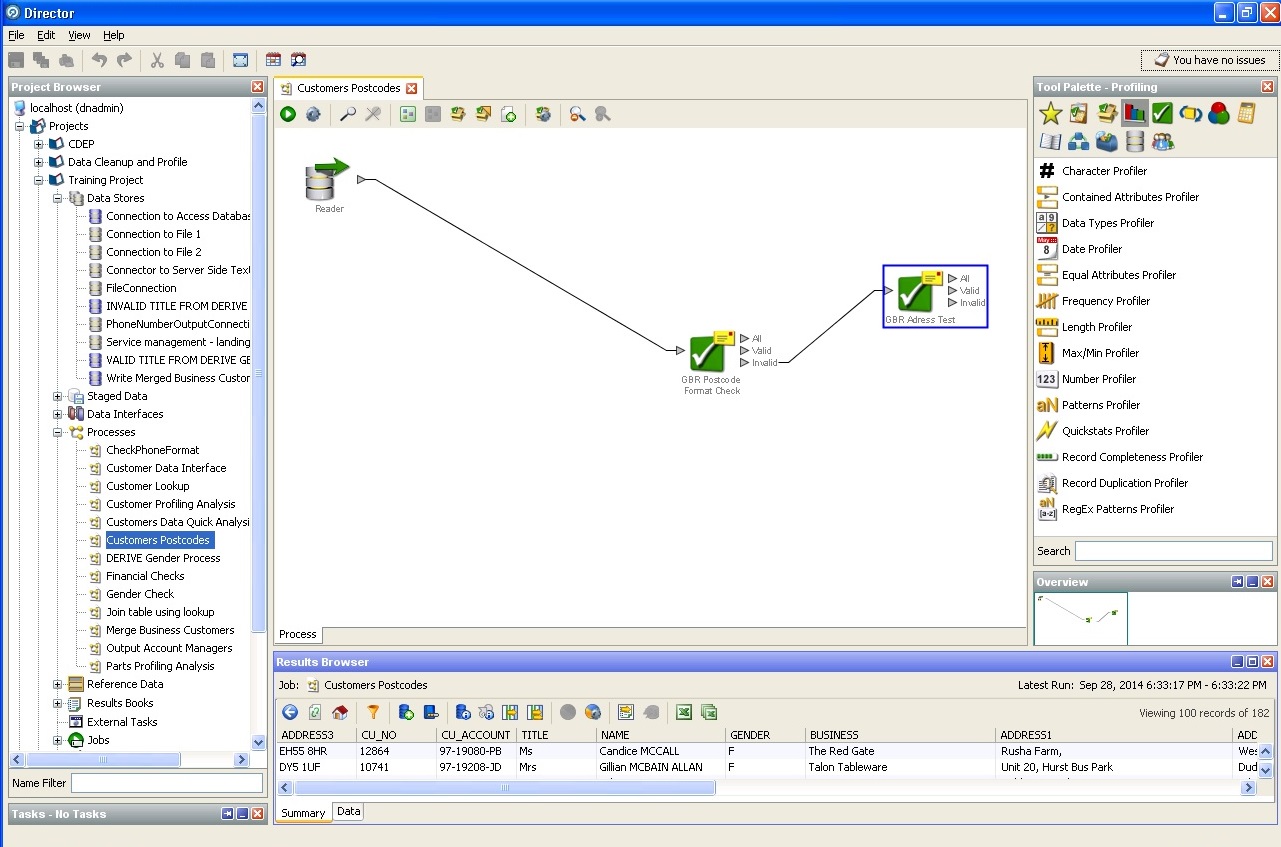
Cleaning the mailing address:
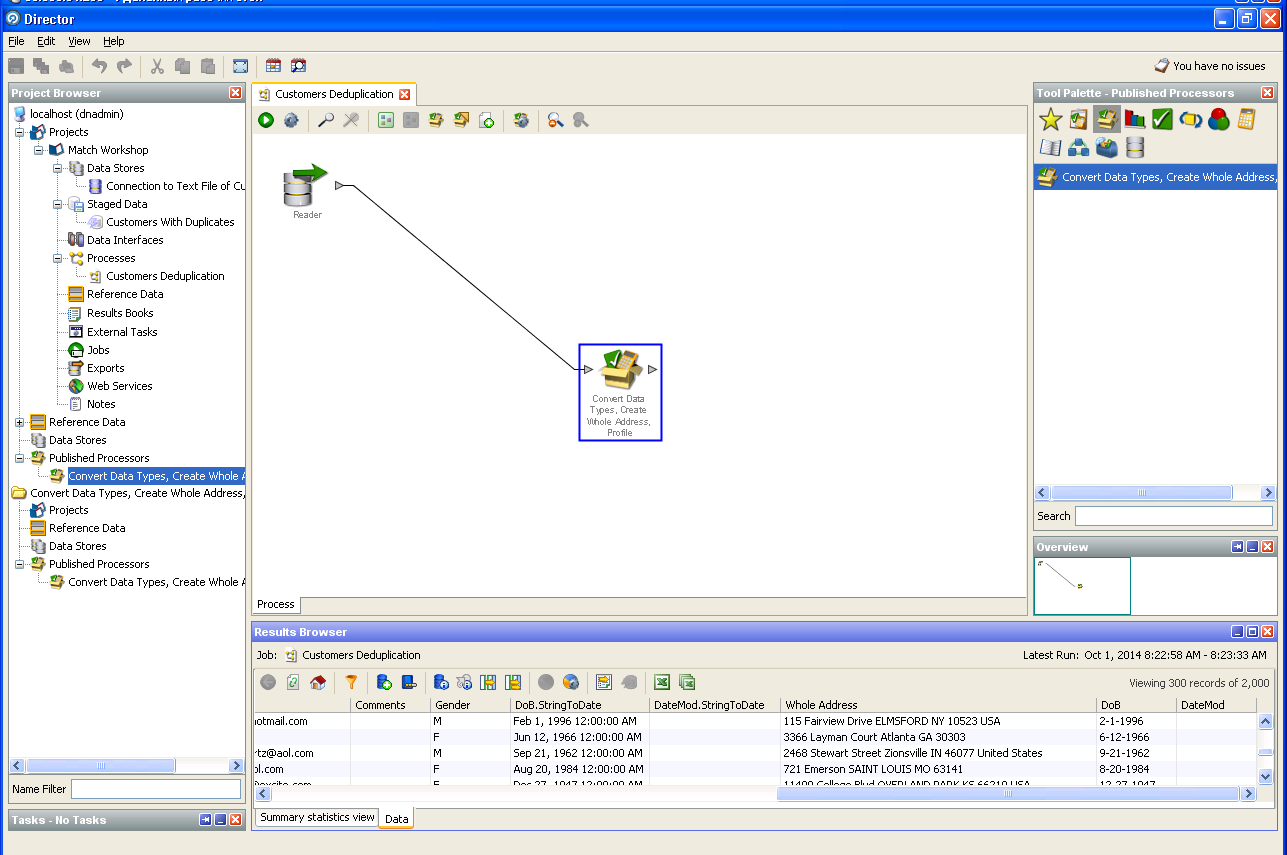
Clearing user data:
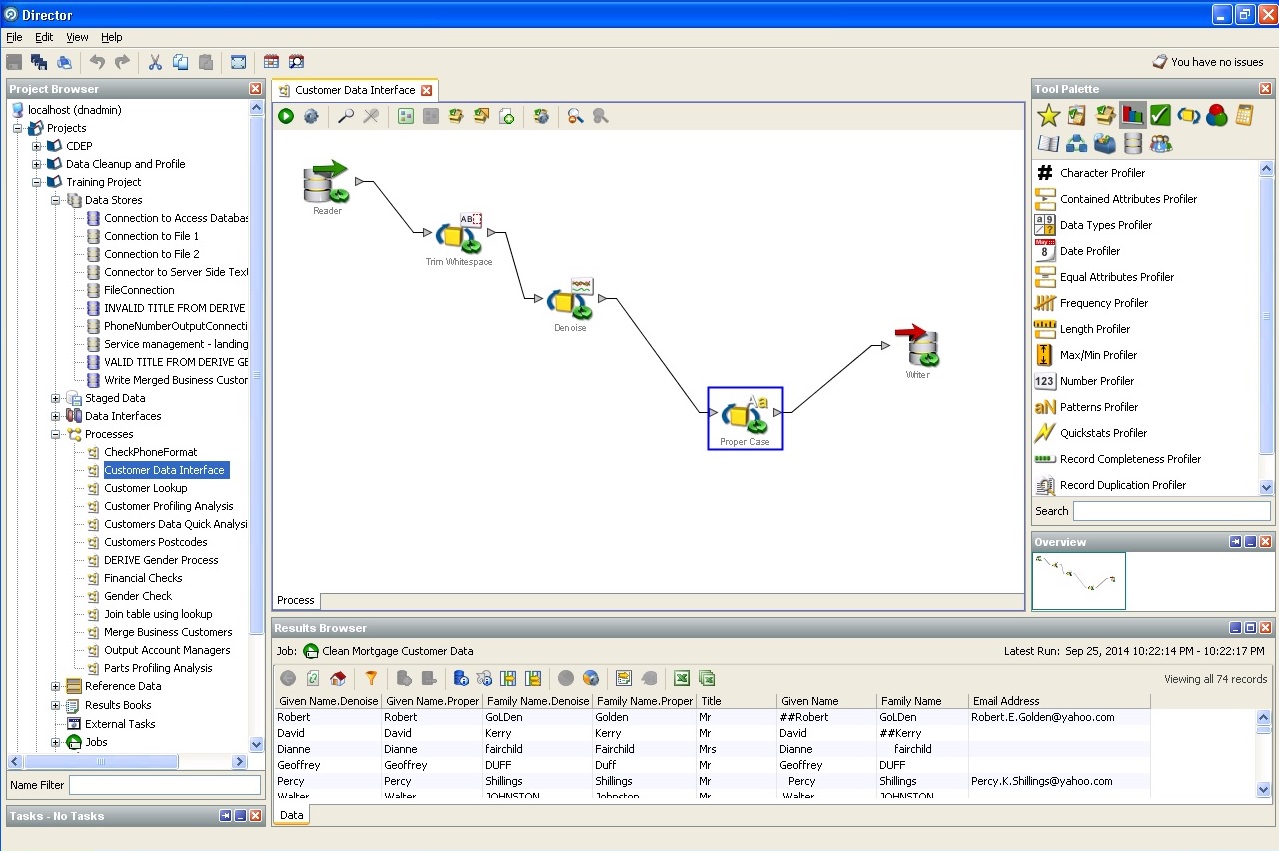
Assigning entry to a particular confidence interval:
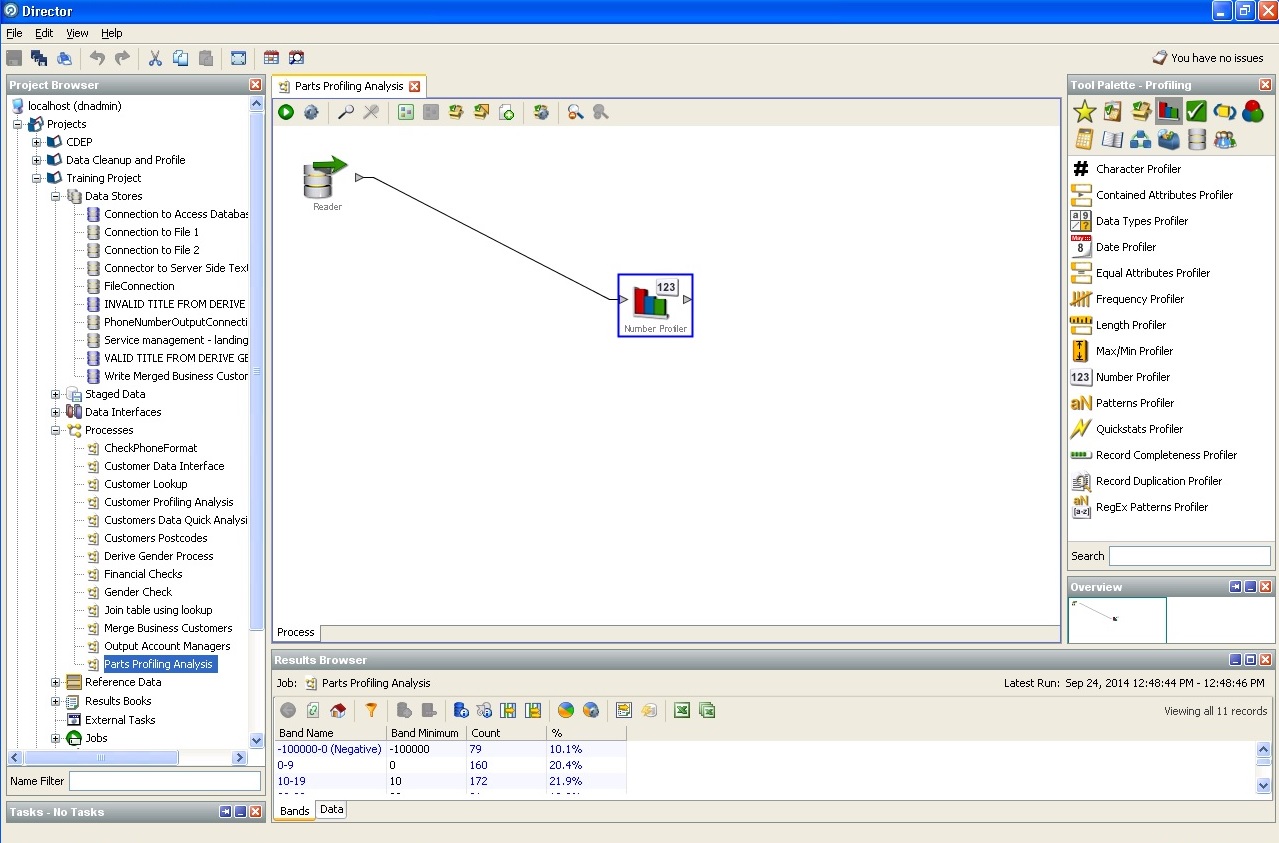
Define user sex of circumstantial evidence:
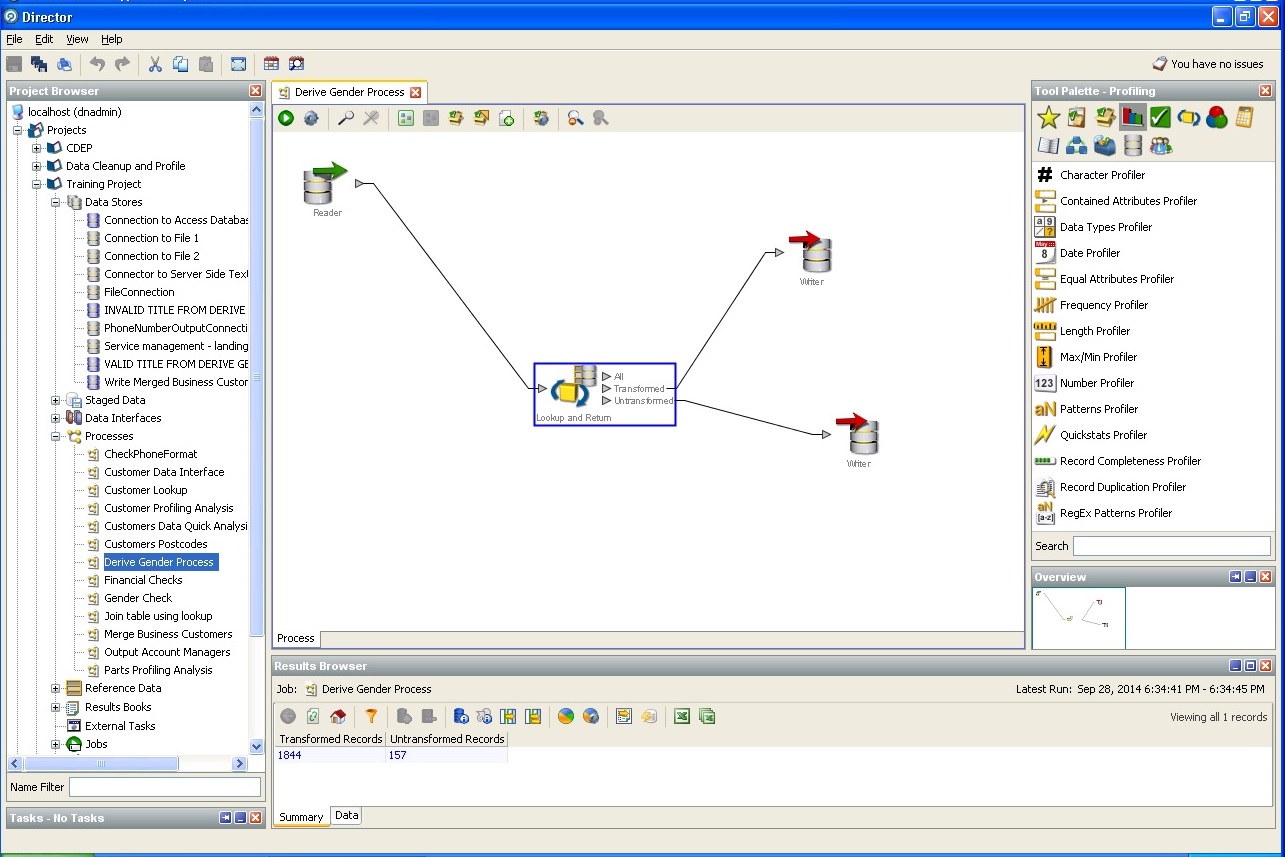
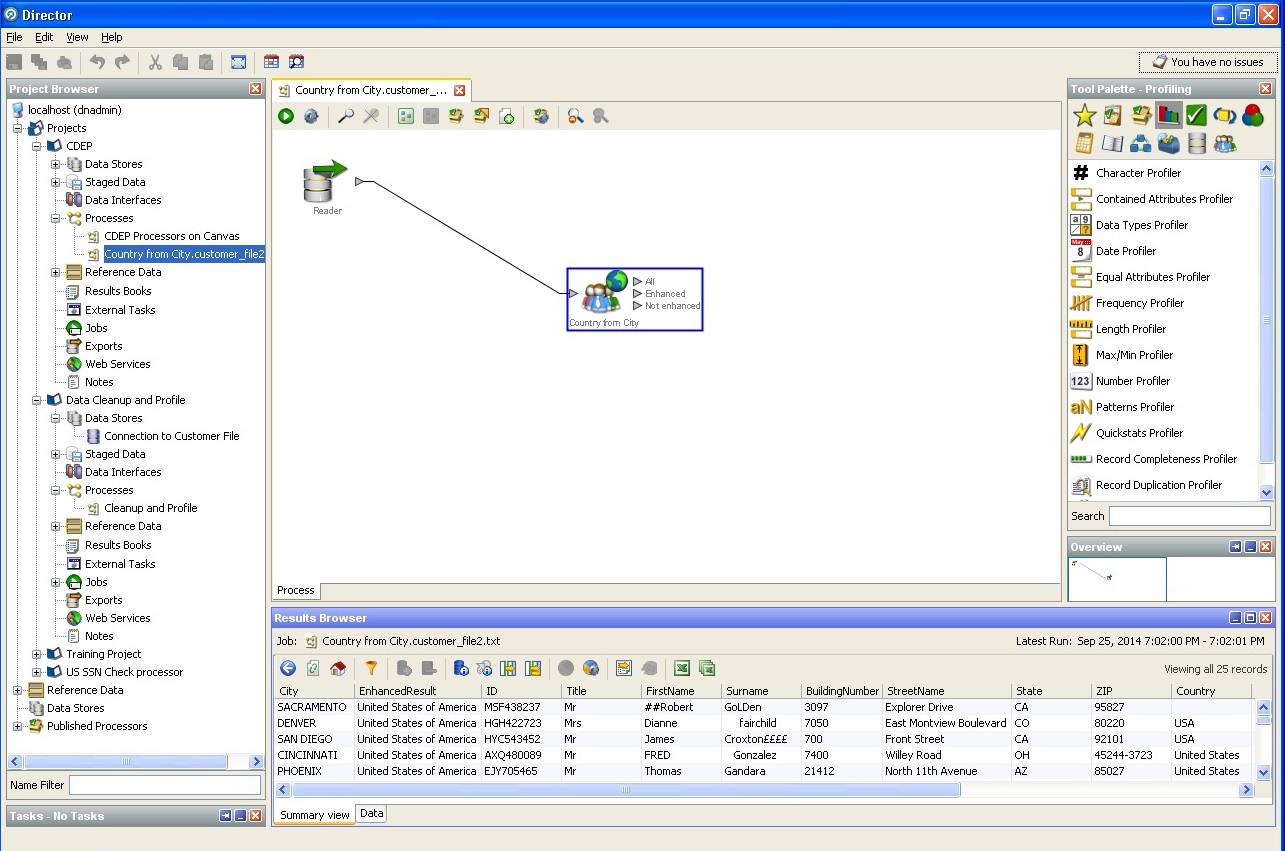
Determination of the city and the country, state:
Simple search keys in a random database:
deduplication OF DATA User:

5. Funny observations made on the results of work on Oracle EDQ.
One of the principles of comparing the contributions of writers and poets to literature is to compare their poetic and literary dictionaries. We give a number of dictionaries compiled in free time for tests of ready-made solutions on Oracle EDQ, Python, Java. We will be grateful if the philologists in the comments post their results.
Number p.p. | Word | Frequency of occurrence | |||
Leo
| I.
| I.
| N.
| ||
one. | and | 10351 | at | at | and |
3. | at | 5185 | and | and | in |
four. | not | 4292 | not | not | not |
five. | what | 3845 | at | at | i |
6. | he | 3730 | like | like | from |
7. | on | 3305 | from | from | at |
eight. | with | 3030 | what | what | like |
9. | as | 2097 | to | And | what |
ten. | I | 1896 | from | i | he is |
eleven. | him | 1882 | out of | to | you |
12. | to | 1771 | i'm | from | but |
13. | then | 1600 | where | all | a |
14. | she is | 1564 | than | to | so |
15. | but | 1234 | for | you | to |
sixteen. | this | 1208 | of | B | all |
17. | said | 1135 | But | for | for |
18. | It was | 1125 | not | out of | i am |
nineteen. | So | 1032 | would | but | yes |
20. | the prince | 1012 | then | he is | its |
21. | behind | 985 | you | But | then |
22. | but | 962 | about | then | was |
23. | his | 918 | but | about | to |
24. | everything | 908 | there are | it's | no |
25. | by | 895 | I'm | I am | neither |
26. | her | 885 |
| a | about |
27. | of | 845 |
| where | their |
28. |
|
|
| than | out of |
29. |
|
|
| A | from |
thirty. |
|
|
| same | we are |
Conclusion: the statistics of the Russian language over the past hundred years in terms of the frequency of individual words has not changed much, among poets - words are more “melodious”. By the way, Daria Dontsova’s statistics largely coincides with Leo Tolstoy in the field of the frequency dictionary of the complete works.
6. Several formal calculations as a conclusion.
About 60 thousand Ivanov Ivanov Ivanovich live in our country. Assuming that somewhere, hypothetically, 100 tables are stored in the average database, 10 key fields in each table, and each key can take 60 thousand values, we get that the total number of unique key states inside the database is about 60 million. Even if two keys get mixed up in one table, they can generate up to 20 unique states in one table. In total, up to several thousand can run into the base of unique states. Agree that spending 10% of development time and 5-7% of ETL execution time to catch such trifles is an impermissible luxury?
UPD1If you are tired of dragging the control system for each more or less important directory in your work, then MDM (Master Data Management) systems will come to your aid. Of course, we deliver such systems to the market, including a version on free software.
UPD2 Very often at conferences the question is asked: “How to create a cheaper data quality management system”. I ask you to consider this article a small introduction to this issue, with some simplification of EDQ functionality. Yes, and yet, you can take a bunch of ODI + EDQ and do it very well, but this is the subject of further narration.