Emulating Amazon web services in a JVM process. Avoiding Roskomnadzor and speeding up development and testing
Why might you need to emulate the Amazon web services infrastructure?
First of all, it is saving - saving time for development and debugging, and what is equally important - saving money from the project budget. It is clear that the emulator will not be 100% identical to the original environment that we are trying to emulate. But for the purpose of accelerating the development and automation of the process, the existing similarities should suffice. The most topical thing that happened in 2018 with AWS was the blocking by IP providers of the IP addresses of AWS subnets in the Russian Federation. And these locks affected our infrastructure located in the Amazon cloud. If you plan to use AWS technology and place the project in this cloud, then for development and testing emulation more than pays off.
In the publication I’ll tell you how we managed to accomplish such a trick with S3, SQS, RDS PostgreSQL and Redshift services when migrating an existing data warehouse to AWS for many years.
This is only part of my last year’s meeting on the map , consistent with the themes of AWS and Java hubs. The second part relates to PostgreSQL, Redshift and column databases, and its text version may be published in the corresponding hubs, videos and slides are on the conference website .
When developing an application for AWS during blocking of AWS subnets, the team practically did not notice them in the daily process of developing new functionality. Tests also worked and you can debug the application. And only when trying to look at the application logs in logentries, metrics in SignalFX or data analysis in Redshift / PostgreSQL RDS was disappointed - the services were not available through the network of the Russian provider. AWS emulation helped us not notice this and avoid much greater delays when working with the Amazon cloud through a VPN network.
Each cloud provider “under the hood” has a lot of dragons and you should not give in to advertising. You need to understand why all this is needed by the service provider. Of course, the existing infrastructure of Amazon, Microsoft and Google have advantages. And when they tell you that everything is done only to make it convenient for you to develop, they are most likely trying to put you on your needle and give the first dose for free. So that later they do not get off the infrastructure and specific technology. Therefore, we will try to avoid vendor lock-in. It is clear that it is not always possible to completely abstract from specific decisions and I think that quite often it is possible to abstract almost 90% in a project. But the remaining 10% of the project, tied to a provider of technologies that are very important, is either optimizing application performance, or unique features that aren’t anywhere else. They should always remember the advantages and disadvantages of technologies and protect themselves as much as possible, not "sit down" on a specific API of a cloud infrastructure provider.
Amazon writes about message processing on its website . The essence and abstraction of message exchange technologies is the same everywhere, although there are nuances - message passing through queues or through topics. So, AWS recommends using the Apache ActiveMQ provided and managed by them to migrate applications from an existing messaging broker, and for new Amazon SQS / SNS applications. This is an example of binding to their own API, instead of the standardized JMS API and the protocols AMQP, MMQT, STOMP. It is clear that this provider with its solution may have higher performance, it supports scalability, etc. From my point of view, if you use their libraries, and not standardized APIs, then there will be much more problems.
AWS has a Redshift database. It is a distributed database with a massive parallel architecture. You can upload a large amount of your data to tables on multiple Redshft sites in Amazon and perform analytic queries on large datasets. This is not an OLTP system where it is important for you to perform small requests on a small number of records often enough with ACID guarantees. When working with Redshift, it is assumed that you do not have a large number of queries per unit of time, but they can read aggregates on a very large amount of data. This system is positioned by the vendor to upgrade your data warehouse (warehouse) on AWS and promise a simple data loading. Which is not at all true.
Excerpt from the documentation about what types it supportsAmazon Redshift It’s a rather meager set and if you need something to store and process data that is not listed here, it will be difficult for you to work. For example a GUID.
The question from the audience is “A JSON?”
- JSON can only be written as VARCHAR and there are several functions for working with JSON.
Comment from the audience: “Postgres has normal JSON support.”
- Yes, it has support for this type of data and functions. But Redshift is basedon PostgreSQL 8.0.2. There was a ParAccel project, if I am not mistaken, this technology of 2005 is a fork of postgres which has a scheduler for distributed requests based on a massive-parallel architecture. 5-6 years passed and this project was licensed for the Amazon Web Servces platform and named Redshift. Something has been removed from the original Postgres, a lot has been added. They added that related to authentication / authorization in AWS, with roles, security in Amazon works fine. But if you need, for example, to connect from Redshift to another database using Foreign Data Source, then you will not find this. There are no functions for working with XML, functions for working with JSON two times and miscalculated.
When developing an application, try not to depend on specific implementationsand the application code depends only on abstractions. You can create these facades and abstractions yourself, but in this case there are many ready-made libraries - facades. Which abstract the code from specific implementations, from specific frameworks. It is clear that they may not support all the functionality as a “common denominator” for technologies. It is better to develop software based on abstractions to simplify testing.
To emulate AWS, I’ll mention two options. The first is more honest and correct, but it works more slowly. The second is dirty and fast. I’ll tell you about the hack option — we’re trying to create the entire infrastructure in one process — the tests and the cross-platform option will work faster with work in Windows (where docker is not always able to make money from you).
The first method is perfect if you are developing on linux / macos and you have docker, it would be better to use atlassian localstack . It is convenient to use testcontainers to integrate localstack into the JVM .
What stopped me from using lockalstack in docker on the project was that development was under Windows and no one vouched for the alpha version of docker when this project started ... It is also possible that they will not be allowed to install a virtual machine with linux and docker in any company that is serious about to information security. I'm not talking about working in a protected environment in investment banks and prohibiting almost all traffic firewalls there.
Let's consider options how to emulate Simple storage S3. This is not a regular file system from Amazon, but rather a distributed repository of objects. In which you put your data as a BLOB, without the possibility of modification and addition of data. There are similar full-fledged distributed storages from other manufacturers. For example, Ceph distributed object storage allows you to work with its functionality using the S3 REST protocol and the existing client with minimal modification. But this is a rather heavyweight solution for the development and testing of java applications.
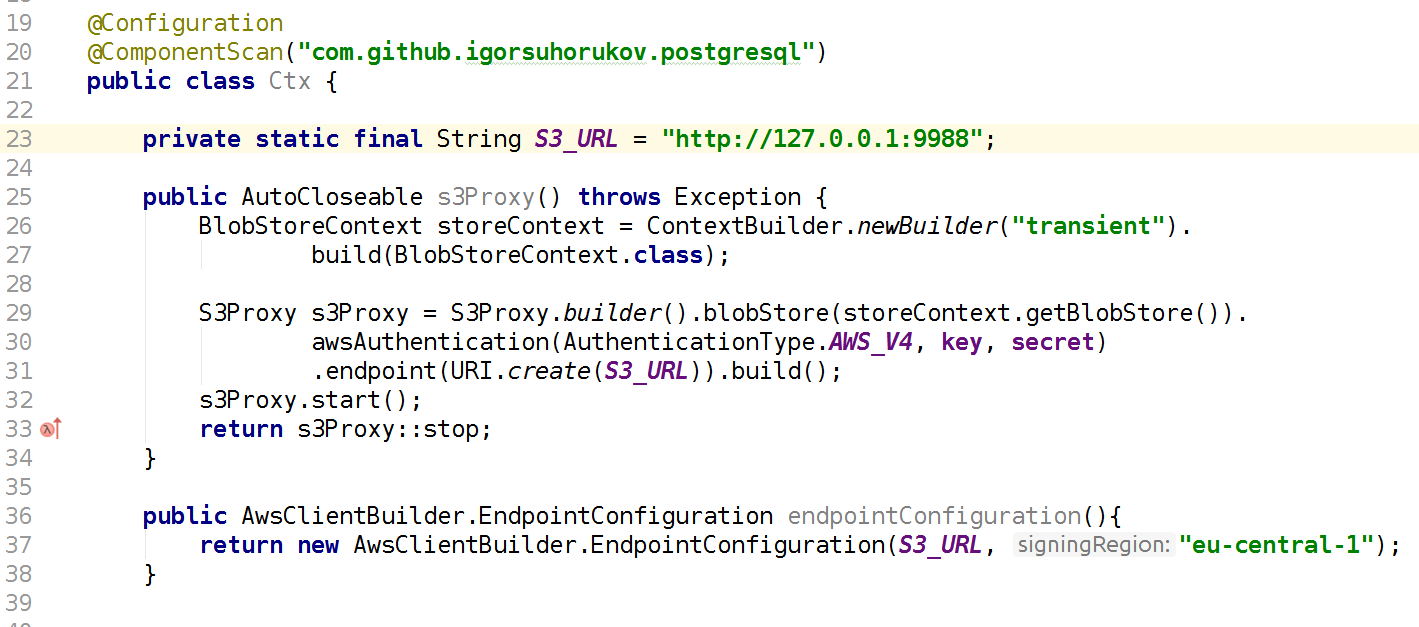
A faster and more suitable project is the s3proxy java library . It emulates the S3 REST protocol and translates into the corresponding jcloud callsAPI and allows you to use many implementations for real reading and storage of data. It can broadcast calls to the Google App Engine API, Microsoft Azure API, but for tests it is more convenient to use jcloud transient storage in RAM. It is also necessary to configure the version of the authentication protocol AWS S3 and specify the key and secret values, also configure the endpoint - the port and interface on which this S3 Proxy will listen. Accordingly, your code using the AWS SDK client should be connected in tests to the S3 AWS endpoint, not the AWS region. Again, remember that s3proxy does not support all the features of the S3 API, but all of our usage scenarios emulate perfectly! Even Multipart upload for large files is supported by s3proxy.
Amazon Simple Queue Service is a queuing service. There is an elasticmq queue service that is written in scala and it can be presented to your application using the Amazon SQS protocol. I did not use it in the project, so I will give the initialization code, trusting information from its developers.

In the project, I went the other way and the code depends on spring-jms abstractions of JmsTemplate and JmsListener and the project dependencies specify the JMS driver for SQS com.amazonaws: amazon-sqs-java-messaging-lib. This is what concerns the main application code.

In tests, we connect Artemis-jms-server as an embedded JMS server for tests, and in the test Spring context, instead of the SQS connection factory, we use the Artemis connection factory. Artemis is the next version of Apache ActiveMQ, a full-fledged, modern Message Oriented Middleware - not only a test solution. Perhaps we will move on to its use in the future, not only in autotests. Thus, using JMS abstractions in conjunction with Spring, we have simplified both the application code and the ability to easily test it. You just need to add the dependencies org.springframework.boot: spring-boot-starter-artemis and org.apache.activemq: artemis-jms-server.

In some tests, PostgreSQL can be emulated by replacing it with H2Database . This will work if the tests are not acceptance and do not use specific PG functions. At the same time, H2 can emulate a subset of the PostgreSQL protocol wire without support for data types and functions. In our project, we use Foreing Data Wrapper, so this method does not work for us.
You can run real PostgreSQL. postgresql-embedded downloads the real distribution, or rather the archive with binary files for the platform with which we run, unpacks it. In linux on tempfs in RAM, in windows in% TEMP%, the postgresql server process starts, configures server settings and database parameters. Due to distribution distribution features, versions older than PG 11 do not work under Linux. I made for myselfa wrapper library that allows you to get PostgreSQL binary assemblies not only from the HTTP server but also from the maven repository. Which can be very useful when working in isolated networks and building on a CI server without Internet access. Another convenience in working with my wrapper is the annotation of the CDI component, which makes it easy to use the component in the Spring context for example. The implementation of the AutoClosable server interface appeared earlier than in the original project. No need to remember to stop the server, it will stop when the Spring context is closed automatically.
At startup, you can create a database based on scripts, supplementing the Spring context with appropriate properties. We are now creating a database schema using flywayscripts for database schema migration, which are launched each time the database is created in tests.
To verify the data after running the tests, we use the spring-test-dbunit library. In annotations to the test methods, we indicate with which unloadings to compare the state of the database. This eliminates the need to write code to work with dbunit, you just need to add the library listener to the test code. You can specify in which order the data from the tables is deleted after the test method is completed, if the database context is reused between the tests. In 2019, there is a more modern approach implemented in database-rider that works with junit5. You can see an example of use, for example here .
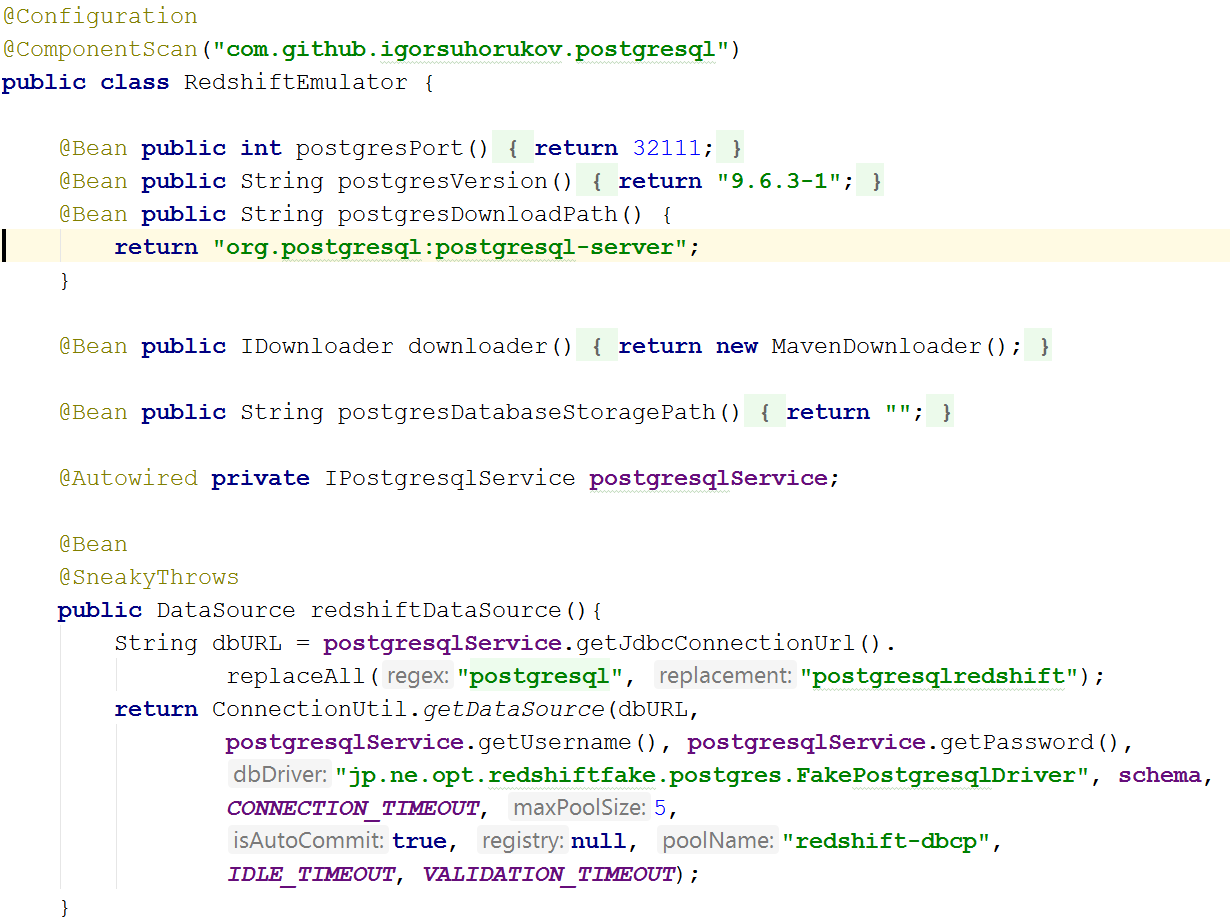
The hardest thing was emulating Amazon Redshift. There is a redshift-fake-driver projectThe project is focused on emulating batch data loading into the analytic database from AWS. In the jdbc: postgresqlredshift protocol emulator, the COPY, UNLOAD commands were implemented; all other commands were delegated to the regular JDBC PostgreSQL driver.
Therefore, the tests will not work in the same way as in Redshift, the update operation, which uses a different table as a data source for updating (the syntax differs in Redshift and PostgreSQL 9+. I also noticed a different interpretation of line quoting in SQL commands between these databases.
Due to the architecture of a real Redshift database, the operations of inserting, updating, and deleting data are rather slow and “expensive” in terms of I / O. It is possible to insert data with acceptable performance only in large "packets" and the COPY command just allows you to download data from a distributed S3 file system. This command in the database supports several data formats AVRO, CSV, JSON, Parquet, ORC and TXT. And the emulator project focuses on CSV, TXT, JSON.
So, to emulate Redshift in the tests, you will need to start the PostgreSQL database as described earlier and run the emulation of the S3 repository, and when creating a connection to the postgres, you just need to add redshift-fake-driver in the classpath and specify the driver class jp.ne.opt.redshiftfake.postgres. FakePostgresqlDriver. After that, you can use the same flyway to migrate the database schema, and dbunit is already familiar for comparing data after running the tests.
I wonder how many readers use AWS and Redshift in their work? Write in the comments about your experience.
Using only Open Source projects, the team managed to accelerate development in the AWS environment, save money from the project budget and not stop the team from working when the AWS subnets were blocked by Roskomnadzor.
First of all, it is saving - saving time for development and debugging, and what is equally important - saving money from the project budget. It is clear that the emulator will not be 100% identical to the original environment that we are trying to emulate. But for the purpose of accelerating the development and automation of the process, the existing similarities should suffice. The most topical thing that happened in 2018 with AWS was the blocking by IP providers of the IP addresses of AWS subnets in the Russian Federation. And these locks affected our infrastructure located in the Amazon cloud. If you plan to use AWS technology and place the project in this cloud, then for development and testing emulation more than pays off.
In the publication I’ll tell you how we managed to accomplish such a trick with S3, SQS, RDS PostgreSQL and Redshift services when migrating an existing data warehouse to AWS for many years.
This is only part of my last year’s meeting on the map , consistent with the themes of AWS and Java hubs. The second part relates to PostgreSQL, Redshift and column databases, and its text version may be published in the corresponding hubs, videos and slides are on the conference website .
When developing an application for AWS during blocking of AWS subnets, the team practically did not notice them in the daily process of developing new functionality. Tests also worked and you can debug the application. And only when trying to look at the application logs in logentries, metrics in SignalFX or data analysis in Redshift / PostgreSQL RDS was disappointed - the services were not available through the network of the Russian provider. AWS emulation helped us not notice this and avoid much greater delays when working with the Amazon cloud through a VPN network.
Each cloud provider “under the hood” has a lot of dragons and you should not give in to advertising. You need to understand why all this is needed by the service provider. Of course, the existing infrastructure of Amazon, Microsoft and Google have advantages. And when they tell you that everything is done only to make it convenient for you to develop, they are most likely trying to put you on your needle and give the first dose for free. So that later they do not get off the infrastructure and specific technology. Therefore, we will try to avoid vendor lock-in. It is clear that it is not always possible to completely abstract from specific decisions and I think that quite often it is possible to abstract almost 90% in a project. But the remaining 10% of the project, tied to a provider of technologies that are very important, is either optimizing application performance, or unique features that aren’t anywhere else. They should always remember the advantages and disadvantages of technologies and protect themselves as much as possible, not "sit down" on a specific API of a cloud infrastructure provider.
Amazon writes about message processing on its website . The essence and abstraction of message exchange technologies is the same everywhere, although there are nuances - message passing through queues or through topics. So, AWS recommends using the Apache ActiveMQ provided and managed by them to migrate applications from an existing messaging broker, and for new Amazon SQS / SNS applications. This is an example of binding to their own API, instead of the standardized JMS API and the protocols AMQP, MMQT, STOMP. It is clear that this provider with its solution may have higher performance, it supports scalability, etc. From my point of view, if you use their libraries, and not standardized APIs, then there will be much more problems.
AWS has a Redshift database. It is a distributed database with a massive parallel architecture. You can upload a large amount of your data to tables on multiple Redshft sites in Amazon and perform analytic queries on large datasets. This is not an OLTP system where it is important for you to perform small requests on a small number of records often enough with ACID guarantees. When working with Redshift, it is assumed that you do not have a large number of queries per unit of time, but they can read aggregates on a very large amount of data. This system is positioned by the vendor to upgrade your data warehouse (warehouse) on AWS and promise a simple data loading. Which is not at all true.
Excerpt from the documentation about what types it supportsAmazon Redshift It’s a rather meager set and if you need something to store and process data that is not listed here, it will be difficult for you to work. For example a GUID.
The question from the audience is “A JSON?”
- JSON can only be written as VARCHAR and there are several functions for working with JSON.
Comment from the audience: “Postgres has normal JSON support.”
- Yes, it has support for this type of data and functions. But Redshift is basedon PostgreSQL 8.0.2. There was a ParAccel project, if I am not mistaken, this technology of 2005 is a fork of postgres which has a scheduler for distributed requests based on a massive-parallel architecture. 5-6 years passed and this project was licensed for the Amazon Web Servces platform and named Redshift. Something has been removed from the original Postgres, a lot has been added. They added that related to authentication / authorization in AWS, with roles, security in Amazon works fine. But if you need, for example, to connect from Redshift to another database using Foreign Data Source, then you will not find this. There are no functions for working with XML, functions for working with JSON two times and miscalculated.
When developing an application, try not to depend on specific implementationsand the application code depends only on abstractions. You can create these facades and abstractions yourself, but in this case there are many ready-made libraries - facades. Which abstract the code from specific implementations, from specific frameworks. It is clear that they may not support all the functionality as a “common denominator” for technologies. It is better to develop software based on abstractions to simplify testing.
To emulate AWS, I’ll mention two options. The first is more honest and correct, but it works more slowly. The second is dirty and fast. I’ll tell you about the hack option — we’re trying to create the entire infrastructure in one process — the tests and the cross-platform option will work faster with work in Windows (where docker is not always able to make money from you).
The first method is perfect if you are developing on linux / macos and you have docker, it would be better to use atlassian localstack . It is convenient to use testcontainers to integrate localstack into the JVM .
What stopped me from using lockalstack in docker on the project was that development was under Windows and no one vouched for the alpha version of docker when this project started ... It is also possible that they will not be allowed to install a virtual machine with linux and docker in any company that is serious about to information security. I'm not talking about working in a protected environment in investment banks and prohibiting almost all traffic firewalls there.
Let's consider options how to emulate Simple storage S3. This is not a regular file system from Amazon, but rather a distributed repository of objects. In which you put your data as a BLOB, without the possibility of modification and addition of data. There are similar full-fledged distributed storages from other manufacturers. For example, Ceph distributed object storage allows you to work with its functionality using the S3 REST protocol and the existing client with minimal modification. But this is a rather heavyweight solution for the development and testing of java applications.
A faster and more suitable project is the s3proxy java library . It emulates the S3 REST protocol and translates into the corresponding jcloud callsAPI and allows you to use many implementations for real reading and storage of data. It can broadcast calls to the Google App Engine API, Microsoft Azure API, but for tests it is more convenient to use jcloud transient storage in RAM. It is also necessary to configure the version of the authentication protocol AWS S3 and specify the key and secret values, also configure the endpoint - the port and interface on which this S3 Proxy will listen. Accordingly, your code using the AWS SDK client should be connected in tests to the S3 AWS endpoint, not the AWS region. Again, remember that s3proxy does not support all the features of the S3 API, but all of our usage scenarios emulate perfectly! Even Multipart upload for large files is supported by s3proxy.
Amazon Simple Queue Service is a queuing service. There is an elasticmq queue service that is written in scala and it can be presented to your application using the Amazon SQS protocol. I did not use it in the project, so I will give the initialization code, trusting information from its developers.
In the project, I went the other way and the code depends on spring-jms abstractions of JmsTemplate and JmsListener and the project dependencies specify the JMS driver for SQS com.amazonaws: amazon-sqs-java-messaging-lib. This is what concerns the main application code.
In tests, we connect Artemis-jms-server as an embedded JMS server for tests, and in the test Spring context, instead of the SQS connection factory, we use the Artemis connection factory. Artemis is the next version of Apache ActiveMQ, a full-fledged, modern Message Oriented Middleware - not only a test solution. Perhaps we will move on to its use in the future, not only in autotests. Thus, using JMS abstractions in conjunction with Spring, we have simplified both the application code and the ability to easily test it. You just need to add the dependencies org.springframework.boot: spring-boot-starter-artemis and org.apache.activemq: artemis-jms-server.
In some tests, PostgreSQL can be emulated by replacing it with H2Database . This will work if the tests are not acceptance and do not use specific PG functions. At the same time, H2 can emulate a subset of the PostgreSQL protocol wire without support for data types and functions. In our project, we use Foreing Data Wrapper, so this method does not work for us.
You can run real PostgreSQL. postgresql-embedded downloads the real distribution, or rather the archive with binary files for the platform with which we run, unpacks it. In linux on tempfs in RAM, in windows in% TEMP%, the postgresql server process starts, configures server settings and database parameters. Due to distribution distribution features, versions older than PG 11 do not work under Linux. I made for myselfa wrapper library that allows you to get PostgreSQL binary assemblies not only from the HTTP server but also from the maven repository. Which can be very useful when working in isolated networks and building on a CI server without Internet access. Another convenience in working with my wrapper is the annotation of the CDI component, which makes it easy to use the component in the Spring context for example. The implementation of the AutoClosable server interface appeared earlier than in the original project. No need to remember to stop the server, it will stop when the Spring context is closed automatically.
At startup, you can create a database based on scripts, supplementing the Spring context with appropriate properties. We are now creating a database schema using flywayscripts for database schema migration, which are launched each time the database is created in tests.
To verify the data after running the tests, we use the spring-test-dbunit library. In annotations to the test methods, we indicate with which unloadings to compare the state of the database. This eliminates the need to write code to work with dbunit, you just need to add the library listener to the test code. You can specify in which order the data from the tables is deleted after the test method is completed, if the database context is reused between the tests. In 2019, there is a more modern approach implemented in database-rider that works with junit5. You can see an example of use, for example here .
The hardest thing was emulating Amazon Redshift. There is a redshift-fake-driver projectThe project is focused on emulating batch data loading into the analytic database from AWS. In the jdbc: postgresqlredshift protocol emulator, the COPY, UNLOAD commands were implemented; all other commands were delegated to the regular JDBC PostgreSQL driver.
Therefore, the tests will not work in the same way as in Redshift, the update operation, which uses a different table as a data source for updating (the syntax differs in Redshift and PostgreSQL 9+. I also noticed a different interpretation of line quoting in SQL commands between these databases.
Due to the architecture of a real Redshift database, the operations of inserting, updating, and deleting data are rather slow and “expensive” in terms of I / O. It is possible to insert data with acceptable performance only in large "packets" and the COPY command just allows you to download data from a distributed S3 file system. This command in the database supports several data formats AVRO, CSV, JSON, Parquet, ORC and TXT. And the emulator project focuses on CSV, TXT, JSON.
So, to emulate Redshift in the tests, you will need to start the PostgreSQL database as described earlier and run the emulation of the S3 repository, and when creating a connection to the postgres, you just need to add redshift-fake-driver in the classpath and specify the driver class jp.ne.opt.redshiftfake.postgres. FakePostgresqlDriver. After that, you can use the same flyway to migrate the database schema, and dbunit is already familiar for comparing data after running the tests.
I wonder how many readers use AWS and Redshift in their work? Write in the comments about your experience.
Using only Open Source projects, the team managed to accelerate development in the AWS environment, save money from the project budget and not stop the team from working when the AWS subnets were blocked by Roskomnadzor.