He speaks and shows: is the rhetoric of popular Ukrainian politicians different?
Is it possible to determine by quote which of the politicians is its author? Ukrainian NGO Vox Ukraine is making the VoxCheck project , within the framework of which it verifies the statements of the most rated politicians. Recently, they posted the entire database of verified quotes . I’m just listening to NLP courses and decided to check how accurately the author can be identified by the text of the quote.
Disclaimer . This article is written out of interest in the topic and the desire to try out the material studied in practice, without claiming the most accurate and detailed analysis.
For analysis, python was used, the code is available on github .
The database now contains 1952 quotes with the following distribution by policy:
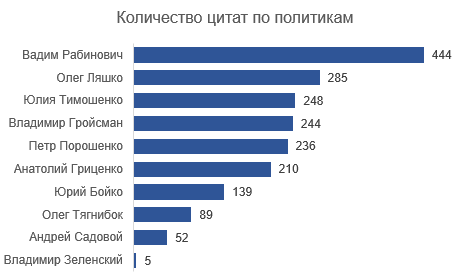
For the purposes of analysis, I selected people with> 200 quotes. Accordingly, Yuri Boyko, Oleg Tyagnibok, Andrey Sadovoy and Vladimir Zelensky fell out of the analysis. There are 1,667 citations left in the array. Of the six remaining speakers, four (except Groysman and Rabinovich) are registered candidates for the next presidential election.
Quotations vary from short, about 30 characters ( “I have already submitted 112 bills.” ) To long ones, about 1,200 characters. The average length of a quote is about 200 characters (for example, “Soon we will have to give a cow a little less for a museum and a dinosaur for children in nature science - for the result of political politics, for yak to conduct a novice’s stay. Livestock less than 2 months . ”)
First, let's see which words are more characteristic of certain speakers. Here are the top 10 words with the highest TF-IDF for each candidate:

Those words that I would like to comment on for each speaker to give a little context are highlighted in green.
Oleg Lyashko:
Poroshenko and Gritsenko talk a lot about the military conflict, which is quite logical: Poroshenko is the president and, accordingly, the supreme commander in chief, and Gritsenko is military and was the defense minister.
Groisman is the prime minister, and mainly talks about the economy, including on public debt. Vadim Rabinovich’s
quotes do not show specific topics, perhaps because he speaks a lot (444 from 1952, all the others have less than 300 quotes). Yulia Tymoshenko talks a lot about the gas transmission system of Ukraine, about the liquidation of banks, as well as about the country's low economic indicators.
So, we get 6 classes (speakers). For classification, I used the naive Bayesian classifier. Stop words of Russian and Ukrainian languages are excluded from the text (using the stopwords package). N-grams up to 2 are included (options with a length of up to 3 were also tested, but showed overfitting). The test sample is taken in a proportion of 20% of the total.
The total accuracy of the model (the proportion of correctly classified citations) in the training sample was 74.8% , in the test sample 75.7%.
Cross-authors: The

highest accuracy for Vadim Rabinovich (97%) is most likely because he is the only Russian speaker out of six. High accuracy of classification of Groisman and Lyashko (78% and 77%).
Slightly higher than 60% are the accuracy indicators for quoting Poroshenko and Tymoshenko. The model more often defines both of them as Groysman. Groysman, as prime minister, often talks about the economy in the form of a “progress report,” and the incorrectly classified quotes from Poroshenko and Tymoshenko are also about this (only Poroshenko as a representative of the government is positive, but Tymoshenko has the opposite).
For example, here is Poroshenko’s quote, defined by the model as Groysman’s quote:
5 billion UAH, (tobto) 4 billion UAH of that rock ’and 1 billion UAH of that rock straight for medicine
, as well as Tymoshenko’s quote, defined as Groysman’s quote:
In the offensive budget for jail time We saw more and more pennies, less on science, like working in the Ukrainian Academy of Sciences.
The lowest accuracy (57%) in quotes by Anatoly Gritsenko. His model is often defined as Poroshenko (which is logical, given the military topics of their quotes), as well as Lyashko. In the case of Lyashko, the wrong classification is quotes criticizing the authorities, including, for example, about migration: I don’t think about those who are the same member of your order, Volodimira Borisovich, pan Klimkin saying that they will leave the country.
In general, it seems to me that the result is not bad for such short quotes of a similar format (oral statements by politicians) and topics (Ukrainian politics). By the way, on the same data I tried to make a model that defines the category of quotation (true / false / manipulation), but the accuracy was very low. Which, in principle, is logical: looking at a quote like “So much money was spent on this, but in such a country they spend so much”, it’s difficult to determine the veracity of the data contained in it :)
Disclaimer . This article is written out of interest in the topic and the desire to try out the material studied in practice, without claiming the most accurate and detailed analysis.
For analysis, python was used, the code is available on github .
Data
The database now contains 1952 quotes with the following distribution by policy:
For the purposes of analysis, I selected people with> 200 quotes. Accordingly, Yuri Boyko, Oleg Tyagnibok, Andrey Sadovoy and Vladimir Zelensky fell out of the analysis. There are 1,667 citations left in the array. Of the six remaining speakers, four (except Groysman and Rabinovich) are registered candidates for the next presidential election.
Quotations vary from short, about 30 characters ( “I have already submitted 112 bills.” ) To long ones, about 1,200 characters. The average length of a quote is about 200 characters (for example, “Soon we will have to give a cow a little less for a museum and a dinosaur for children in nature science - for the result of political politics, for yak to conduct a novice’s stay. Livestock less than 2 months . ”)
TF-IDF
First, let's see which words are more characteristic of certain speakers. Here are the top 10 words with the highest TF-IDF for each candidate:
Briefly about TF-IDF
TF-IDF (term frequency - inverse document frequency) is an indicator that evaluates the importance of a word in the context of a document. TF-IDF words are proportional to the frequency of use of this word in the document and inversely proportional to the frequency of use of the word in all documents of the collection. In the context of our data, a high TF-IDF means that a politician often uses this word, while other politicians use it relatively less.
To count TF-IDF, stemming was used - bringing the word to the base.
To count TF-IDF, stemming was used - bringing the word to the base.
Those words that I would like to comment on for each speaker to give a little context are highlighted in green.
Oleg Lyashko:
- Poland: Lyashko often mentions Poland in connection with the working migration of Ukrainians there, and also compares incomes in Poland and Ukraine
- Cereals: Lyashko says that Ukraine exports grain and loses on it, because it could be more expensive to export flour
- Oncology, medicines: Lyashko is an ardent opponent of the current medical reform and often says that the cost of oncology is almost not covered by the state
Poroshenko and Gritsenko talk a lot about the military conflict, which is quite logical: Poroshenko is the president and, accordingly, the supreme commander in chief, and Gritsenko is military and was the defense minister.
Groisman is the prime minister, and mainly talks about the economy, including on public debt. Vadim Rabinovich’s
quotes do not show specific topics, perhaps because he speaks a lot (444 from 1952, all the others have less than 300 quotes). Yulia Tymoshenko talks a lot about the gas transmission system of Ukraine, about the liquidation of banks, as well as about the country's low economic indicators.
Quote classification
So, we get 6 classes (speakers). For classification, I used the naive Bayesian classifier. Stop words of Russian and Ukrainian languages are excluded from the text (using the stopwords package). N-grams up to 2 are included (options with a length of up to 3 were also tested, but showed overfitting). The test sample is taken in a proportion of 20% of the total.
The total accuracy of the model (the proportion of correctly classified citations) in the training sample was 74.8% , in the test sample 75.7%.
Cross-authors: The
highest accuracy for Vadim Rabinovich (97%) is most likely because he is the only Russian speaker out of six. High accuracy of classification of Groisman and Lyashko (78% and 77%).
Slightly higher than 60% are the accuracy indicators for quoting Poroshenko and Tymoshenko. The model more often defines both of them as Groysman. Groysman, as prime minister, often talks about the economy in the form of a “progress report,” and the incorrectly classified quotes from Poroshenko and Tymoshenko are also about this (only Poroshenko as a representative of the government is positive, but Tymoshenko has the opposite).
For example, here is Poroshenko’s quote, defined by the model as Groysman’s quote:
5 billion UAH, (tobto) 4 billion UAH of that rock ’and 1 billion UAH of that rock straight for medicine
, as well as Tymoshenko’s quote, defined as Groysman’s quote:
In the offensive budget for jail time We saw more and more pennies, less on science, like working in the Ukrainian Academy of Sciences.
The lowest accuracy (57%) in quotes by Anatoly Gritsenko. His model is often defined as Poroshenko (which is logical, given the military topics of their quotes), as well as Lyashko. In the case of Lyashko, the wrong classification is quotes criticizing the authorities, including, for example, about migration: I don’t think about those who are the same member of your order, Volodimira Borisovich, pan Klimkin saying that they will leave the country.
In general, it seems to me that the result is not bad for such short quotes of a similar format (oral statements by politicians) and topics (Ukrainian politics). By the way, on the same data I tried to make a model that defines the category of quotation (true / false / manipulation), but the accuracy was very low. Which, in principle, is logical: looking at a quote like “So much money was spent on this, but in such a country they spend so much”, it’s difficult to determine the veracity of the data contained in it :)