How we overcome incompatibility when migrating data from Greenplum 4 to Greenplum 5
When we chose a tool for processing big data, we considered various options, both proprietary and open source. Evaluated opportunities for rapid adaptation, availability and flexibility of technology. Including migration between versions. As a result, we chose the open source solution Greenplum, which best met our requirements, but required the solution of one important issue.

The fact is that Greenplum database files of versions 4 and 5 are not compatible with each other, and therefore a simple upgrade from one version to another is impossible. Data migration can be performed only through uploading and downloading data. In this post I will talk about possible options for this migration.
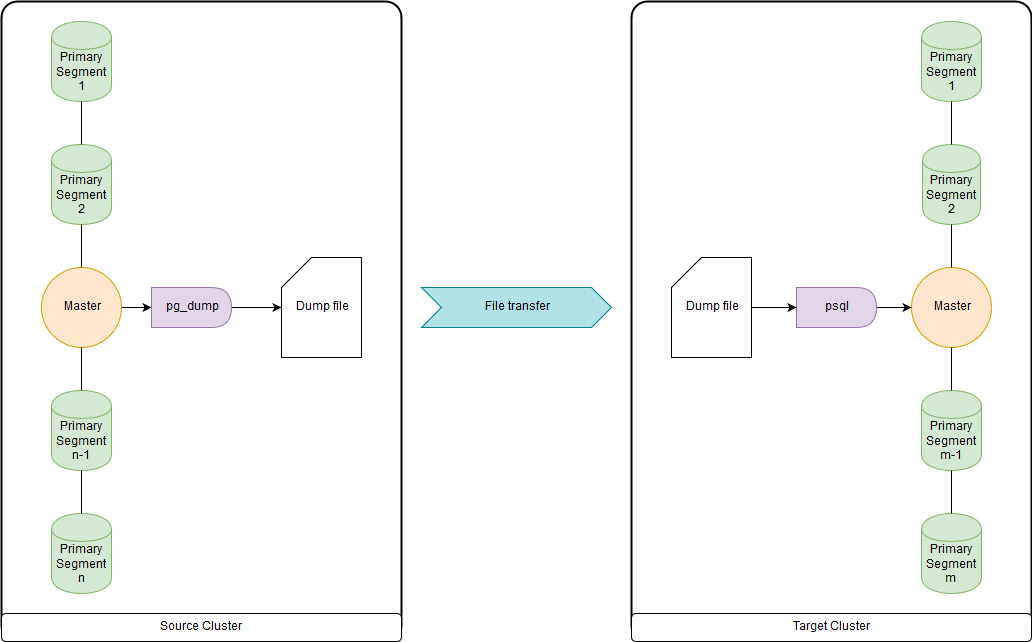
This is too slow when it comes to dozens of terabytes, since all data is uploaded and loaded through master nodes. But fast enough to migrate DDL and small tables. It is possible to upload both to a file and to run pg_dump and psql simultaneously via a pipeline (pipe) both on the source cluster and on the receiving cluster. pg_dump simply unloads into a single file containing both DDL commands and COPY commands with data. The obtained data can be conveniently processed, which will be shown below.
Requires version Greenplum 4.2 or newer. It is necessary that both the source cluster and the destination cluster work simultaneously. The fastest way to transfer tables with large amounts of data for the open source version. But this method is very slow for transferring empty and small tables due to high overhead.
gptransfer uses pg_dump to transfer the DDL and gpfdist to transfer data. The number of primary segments on the receiving cluster must be no less than the segment of hosts on the source cluster. This is important to consider when creating sandbox clusters, if data from the main clusters will be transferred to them, and the use of the gptransfer utility is planned. Even if the segment-hosts is small, on each of them you can deploy the required number of segments. The number of segments on the receiving cluster may be less than on the source cluster, but this will adversely affect the speed of data transfer. Between clusters ssh authorization must be configured for certificates.
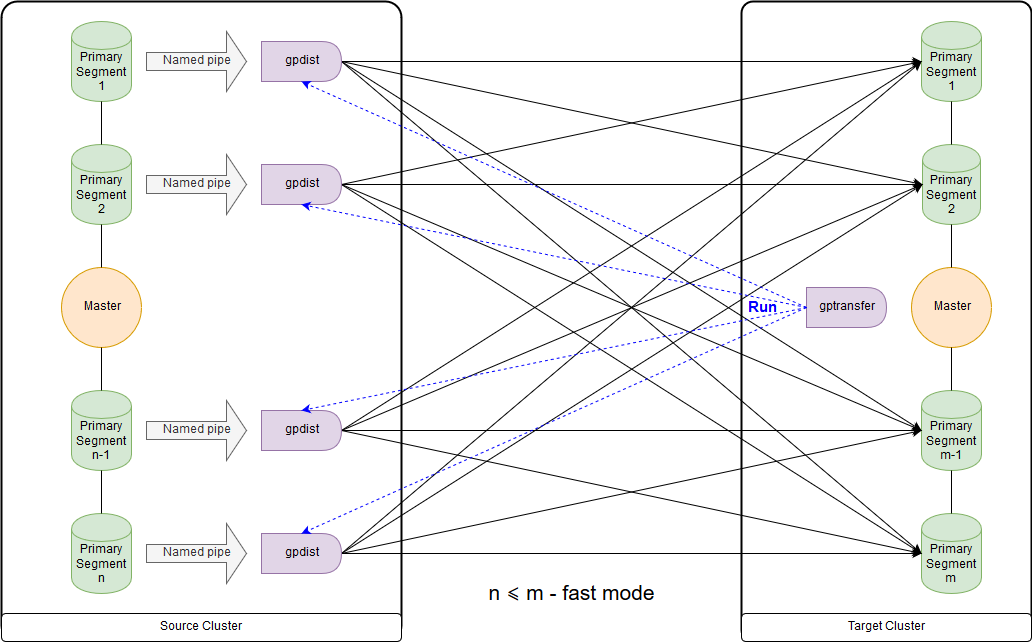
This is the scheme for the fast mode when the number of segments on the receiving cluster is greater than or equal to the number on the source cluster. The launch of the utility itself is shown in the diagram on the master node of the receiving cluster. In this mode, an external table is created on the source cluster for a record that writes data on each segment in a named pipe. INSERT INTO command is executed writable_external_table SELECT * FROM source_table. The data from the named pipe is read by gpfdist. An external table is also created on the receiving cluster, just for reading only. The table indicates the data that provide gpfdist over the same protocol . The INSERT INTO command target_table SELECT * FROM external_gpfdist_table is executed. The data is automatically redistributed between the segments of the cluster-receiver.
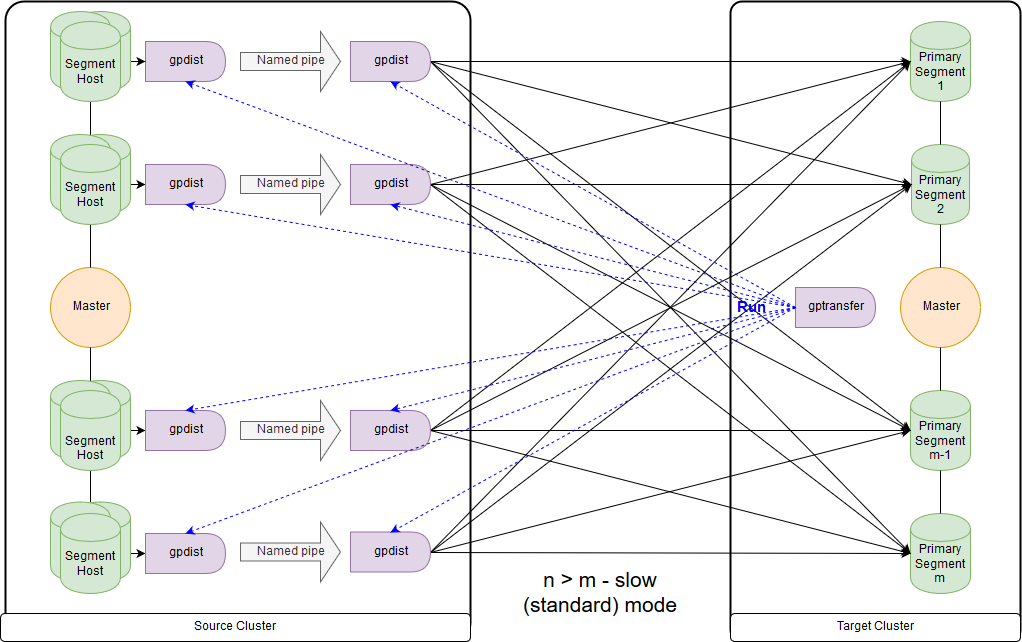
And this is the scheme for the slow mode, or, as gptransfer itself issues, standard mode. The main difference is that on each source cluster segment, a pair of gpfdist is launched for all segments of this host segment. The external table for the record refers to gpfdist, acting as a data sink. At the same time, if several values are specified in the LOCATION parameter in the external table, then the segments will be distributed evenly along gpfdist when writing data. Data between gpfdist on a segment-host is transmitted via a named pipe. Because of this, the data transfer rate is lower, but it still turns out faster than when transferring data only through the master node.
When migrating data from Greenplum 4 to Greenplum 5, you need to run gptransfer at the master node of the receiving cluster. If we run gptransfer on the source cluster, we get an error of the absence of a field
You also need to check the GPHOME variables so that they match at the source cluster and the destination cluster. Otherwise, we get a rather strange error (gptransfer utility).
You can simply create the corresponding symlink and override the GPHOME variable in the session in which gptransfer runs.
When running gptransfer on the receiving cluster, the option “--source-map-file” should point to a file containing a list of hosts and their ip-addresses with primary segments of the source cluster. For example:
With the option "--full" you can transfer not only the tables, but the entire database, but user databases should not be created on the receiving cluster. It should also be remembered that there are problems due to syntax changes when transferring external tables.
Let's estimate the additional overhead, for example, by copying 10 empty tables (tables from big_db.public.test_table_2 to big_db.public.test_table_11) using gptarnsfer:
As a result, the transfer of 10 empty tables took about 16 seconds (14: 40-15: 02), that is, one table - 1.6 seconds. During this time, in our case, you can load using pg_dump & psql about 100 MB of data.
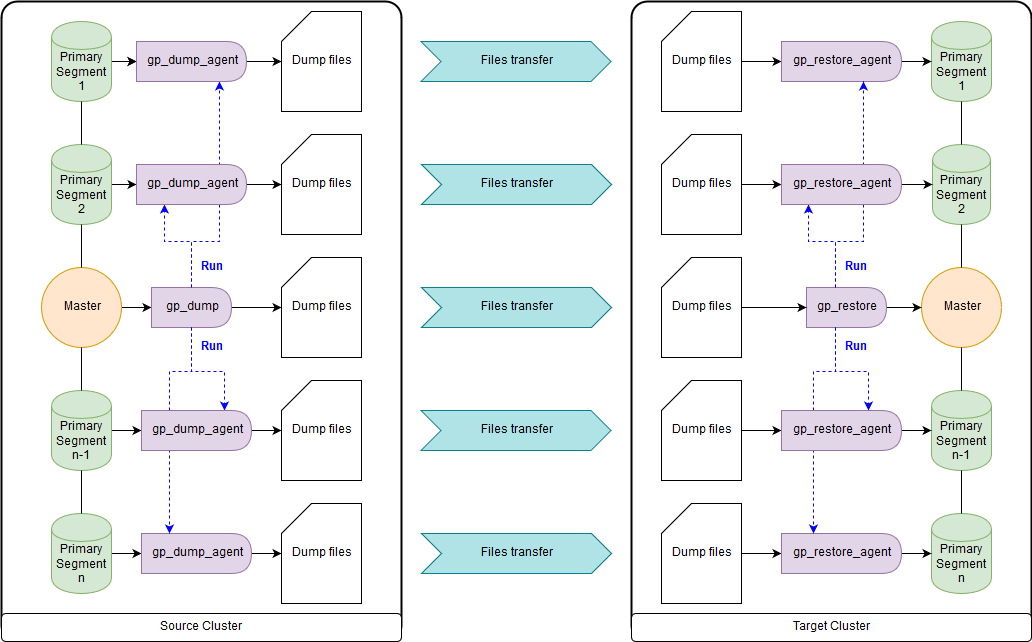
As an option: use add-ons above them, gpcrondump & gpdbrestore, since gp_dump & gp_restore is declared deprecated. Although gpcrondump & gpdbrestore themselves in their work use gp_dump & gp_restore. This is the most universal way, but not the fastest. Backup files created with gp_dump represent a set of DDL commands on the master node, and on the primary segments, mainly a set of COPY commands and data. Suitable for cases where it is impossible to ensure simultaneous operation of the receiving cluster and the source cluster. There are both old versions of Greenplum and new ones: gp_dump , gp_restore .
Created as a replacement for gp_dump & gp_restore. For their work, Greenplum version minimum 4.3.17 is required ( const MINIMUM_GPDB4_VERSION = "4.3.17" ). The scheme of work is similar to gpbackup & gprestore, while the speed is much faster. The fastest way to get DDL commands for large databases. By default, it transfers global objects; to restore, you need to specify "gprestore --with-globals". The optional "--jobs" parameter can set the number of jobs (and sessions to the database) when creating a backup. Due to the fact that several sessions are created, it is important to ensure data consistency until all locks are acquired. There is also a useful option "--with-stats", which allows you to transfer statistics on objects used to build execution plans. More information here..
To copy the database there is a utility gpcopy - replacement gptansfer. But it is included only in the proprietary version of Greenplum from Pivotal, starting from 4.3.26 - in the open source version of this utility there is no. During the work on the source cluster, the COPY source_table TO PROGRAM 'gpcopy_helper ...' ON SEGMENT CSV IGNORE EXTERNAL PARTITIONS command is executed. A temporary external table is created on the side of the receiving cluster: CREATE EXTERNAL WEB TEMP TABLE external_temp_table (LIKE target_table) EXECUTE '... gpcopy_helper –listen ...' and the command INSERT INTO target_table SELECT * FROM external_temp_table is executed. As a result, on each segment of the receiving cluster, gpcopy_helper is launched with the –listen parameter, which receives data from gpcopy_helper's from the source cluster segments. Due to this data transfer scheme, as well as compression, the transfer speed is much higher. Between clusters, certificate authorization for ssh should also be configured. I also want to point out
To determine the transfer strategy, we need to determine what is more important to us: transfer data quickly, but with more labor and perhaps less reliably (gpbackup, gptransfer or a combination of them) or with less labor, but slower (gpbackup or gptransfer without combination).
The fastest way to transfer data — when there is a source cluster and a destination cluster — is the following:
This method was in our measurements at least 2 times faster than gp_dump & gp_restore. Alternative methods: transfer all databases using gptransfer –full, gpbackup & gprestore, or gp_dump & gp_restore.
The sizes of the tables can be obtained by the following request:
Backup files in Greenplum versions 4 and 5 are also not fully compatible. So, in Greenplum 5, due to the syntax change in the CREATE EXTERNAL TABLE and COPY commands, the INTO ERROR TABLE parameter is missing, and the SET gp_ignore_error_table parameter must be set to true so that recovery of the backup does not complete by mistake. With the parameter set we just get a warning.
In addition, in the fifth version, another protocol appeared for interacting with external pxf tables, and to use it, you need to change the LOCATION parameter and also configure the pxf service.
Also note that in the backup gp_dump & gp_restore files both on the master node and on each primary segment, the SET parameter gp_strict_xml_parse is set to false. There is no such parameter in Greenplum 5, and as a result, we get an error message.
If the gphdfs protocol was used for external tables, you should check the list of sources in the backup files in the LOCATION parameter for external tables on the line 'gphdfs: //'. For example, there should be only 'gphdfs: //hadoop.local: 8020'. If there are other lines, they need to be added to the replacement script on the master node by analogy.
We make replacements on the master node (by the example of the gp_dump data file):
In recent versions, the profile name of hdfsTextSimple is declared deprecated , the new name is hdfs: text.
Beyond the article remains a need for an explicit conversion to text ( Implicit Casting the Text ), a new management mechanism of the cluster the Resource the Groups , which replaced the Resource Queues, optimizer GPORCA , which is enabled by default in Greenplum 5, minor problems with customers.
I look forward to the release of the sixth version of Greenplum, which is scheduled for spring 2019: compatibility level with PostgreSQL 9.4, Full Text Search, GIN Index Support, Range Types, JSONB, zStd Compression. Preliminary plans for Greenplum 7 have also become known: PostgreSQL compatibility level at least 9.6, Row Level Security, Automated Master Failover. Also, the developers promise the availability of database upgrade utilities for upgrading between major versions, so it will be easier to live.
The article was prepared by the data management team of Rostelecom.
The fact is that Greenplum database files of versions 4 and 5 are not compatible with each other, and therefore a simple upgrade from one version to another is impossible. Data migration can be performed only through uploading and downloading data. In this post I will talk about possible options for this migration.
Evaluate migration options
pg_dump & psql (or pg_restore)
This is too slow when it comes to dozens of terabytes, since all data is uploaded and loaded through master nodes. But fast enough to migrate DDL and small tables. It is possible to upload both to a file and to run pg_dump and psql simultaneously via a pipeline (pipe) both on the source cluster and on the receiving cluster. pg_dump simply unloads into a single file containing both DDL commands and COPY commands with data. The obtained data can be conveniently processed, which will be shown below.
gptransfer
Requires version Greenplum 4.2 or newer. It is necessary that both the source cluster and the destination cluster work simultaneously. The fastest way to transfer tables with large amounts of data for the open source version. But this method is very slow for transferring empty and small tables due to high overhead.
gptransfer uses pg_dump to transfer the DDL and gpfdist to transfer data. The number of primary segments on the receiving cluster must be no less than the segment of hosts on the source cluster. This is important to consider when creating sandbox clusters, if data from the main clusters will be transferred to them, and the use of the gptransfer utility is planned. Even if the segment-hosts is small, on each of them you can deploy the required number of segments. The number of segments on the receiving cluster may be less than on the source cluster, but this will adversely affect the speed of data transfer. Between clusters ssh authorization must be configured for certificates.
This is the scheme for the fast mode when the number of segments on the receiving cluster is greater than or equal to the number on the source cluster. The launch of the utility itself is shown in the diagram on the master node of the receiving cluster. In this mode, an external table is created on the source cluster for a record that writes data on each segment in a named pipe. INSERT INTO command is executed writable_external_table SELECT * FROM source_table. The data from the named pipe is read by gpfdist. An external table is also created on the receiving cluster, just for reading only. The table indicates the data that provide gpfdist over the same protocol . The INSERT INTO command target_table SELECT * FROM external_gpfdist_table is executed. The data is automatically redistributed between the segments of the cluster-receiver.
And this is the scheme for the slow mode, or, as gptransfer itself issues, standard mode. The main difference is that on each source cluster segment, a pair of gpfdist is launched for all segments of this host segment. The external table for the record refers to gpfdist, acting as a data sink. At the same time, if several values are specified in the LOCATION parameter in the external table, then the segments will be distributed evenly along gpfdist when writing data. Data between gpfdist on a segment-host is transmitted via a named pipe. Because of this, the data transfer rate is lower, but it still turns out faster than when transferring data only through the master node.
When migrating data from Greenplum 4 to Greenplum 5, you need to run gptransfer at the master node of the receiving cluster. If we run gptransfer on the source cluster, we get an error of the absence of a field
san_mountsin the table pg_catalog.gp_segment_configuration:gptransfer -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate
20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate
20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Validating options...
20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database...
20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database...
20190109:12:46:14:010893 gptransfer:gpdb-source-master.local:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist
LINE 2: ... SELECT dbid, content, status, unnest(san_mounts...
^
' in '
SELECT dbid, content, status, unnest(san_mounts)
FROM pg_catalog.gp_segment_configuration
WHERE content >= 0
ORDER BY content, dbid
'') exiting...You also need to check the GPHOME variables so that they match at the source cluster and the destination cluster. Otherwise, we get a rather strange error (gptransfer utility).
gptransfer -t big_db.public.test_table --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate
20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --source-host=gpdb-spurce-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate
20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Validating options...
20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[ERROR]:-gptransfer: error: GPHOME directory does not exist on gpdb-source-master.localYou can simply create the corresponding symlink and override the GPHOME variable in the session in which gptransfer runs.
When running gptransfer on the receiving cluster, the option “--source-map-file” should point to a file containing a list of hosts and their ip-addresses with primary segments of the source cluster. For example:
sdw1,192.0.2.1
sdw2,192.0.2.2
sdw3,192.0.2.3
sdw4,192.0.2.4With the option "--full" you can transfer not only the tables, but the entire database, but user databases should not be created on the receiving cluster. It should also be remembered that there are problems due to syntax changes when transferring external tables.
Let's estimate the additional overhead, for example, by copying 10 empty tables (tables from big_db.public.test_table_2 to big_db.public.test_table_11) using gptarnsfer:
gptransfer -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-ba tch-size=50 --truncate
20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-batch-size=50 --truncate
20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating options...
20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database...
20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database...
20190118:06:14:09:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving source tables...
20190118:06:14:12:031521 gptransfer:mdw:gpadmin-[INFO]:-Checking for gptransfer schemas...
20190118:06:14:22:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving list of destination tables...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Reading source host map file...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Building list of source tables to transfer...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Number of tables to transfer: 10
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-gptransfer will use "standard" mode for transfer.
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating source host map...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating transfer table set...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-The following tables on the destination system will be truncated:
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_2
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_3
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_4
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_5
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_6
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_7
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_8
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_9
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_10
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_11
…
20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using batch size of 10
20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using sub-batch size of 16
20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_31521'
20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating schema public in database edw_prod...
20190118:06:14:40:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting transfer of big_db.public.test_table_5 to big_db.public.test_table_5...
…
20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Validation of big_db.public.test_table_4 successful
20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Removing work directories...
20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Finished.As a result, the transfer of 10 empty tables took about 16 seconds (14: 40-15: 02), that is, one table - 1.6 seconds. During this time, in our case, you can load using pg_dump & psql about 100 MB of data.
gp_dump & gp_restore
As an option: use add-ons above them, gpcrondump & gpdbrestore, since gp_dump & gp_restore is declared deprecated. Although gpcrondump & gpdbrestore themselves in their work use gp_dump & gp_restore. This is the most universal way, but not the fastest. Backup files created with gp_dump represent a set of DDL commands on the master node, and on the primary segments, mainly a set of COPY commands and data. Suitable for cases where it is impossible to ensure simultaneous operation of the receiving cluster and the source cluster. There are both old versions of Greenplum and new ones: gp_dump , gp_restore .
Gpbackup & gprestore utilities
Created as a replacement for gp_dump & gp_restore. For their work, Greenplum version minimum 4.3.17 is required ( const MINIMUM_GPDB4_VERSION = "4.3.17" ). The scheme of work is similar to gpbackup & gprestore, while the speed is much faster. The fastest way to get DDL commands for large databases. By default, it transfers global objects; to restore, you need to specify "gprestore --with-globals". The optional "--jobs" parameter can set the number of jobs (and sessions to the database) when creating a backup. Due to the fact that several sessions are created, it is important to ensure data consistency until all locks are acquired. There is also a useful option "--with-stats", which allows you to transfer statistics on objects used to build execution plans. More information here..
Gpcopy utility
To copy the database there is a utility gpcopy - replacement gptansfer. But it is included only in the proprietary version of Greenplum from Pivotal, starting from 4.3.26 - in the open source version of this utility there is no. During the work on the source cluster, the COPY source_table TO PROGRAM 'gpcopy_helper ...' ON SEGMENT CSV IGNORE EXTERNAL PARTITIONS command is executed. A temporary external table is created on the side of the receiving cluster: CREATE EXTERNAL WEB TEMP TABLE external_temp_table (LIKE target_table) EXECUTE '... gpcopy_helper –listen ...' and the command INSERT INTO target_table SELECT * FROM external_temp_table is executed. As a result, on each segment of the receiving cluster, gpcopy_helper is launched with the –listen parameter, which receives data from gpcopy_helper's from the source cluster segments. Due to this data transfer scheme, as well as compression, the transfer speed is much higher. Between clusters, certificate authorization for ssh should also be configured. I also want to point out
Data transfer strategy
To determine the transfer strategy, we need to determine what is more important to us: transfer data quickly, but with more labor and perhaps less reliably (gpbackup, gptransfer or a combination of them) or with less labor, but slower (gpbackup or gptransfer without combination).
The fastest way to transfer data — when there is a source cluster and a destination cluster — is the following:
- Get the DDL using gpbackup --metadata-only, transform and load through the pipeline using psql
- Remove indexes
- Transfer tables with a size of 100 MB or more using gptransfer
- Transfer tables with a size less than 100 MB using pg_dump | psql, as in the first paragraph
- Create back previously deleted indexes
This method was in our measurements at least 2 times faster than gp_dump & gp_restore. Alternative methods: transfer all databases using gptransfer –full, gpbackup & gprestore, or gp_dump & gp_restore.
The sizes of the tables can be obtained by the following request:
SELECT
nspname AS "schema",
coalesce(tablename, relname) AS "name",
SUM(pg_total_relation_size(class.oid)) AS "size"
FROM pg_class class
JOIN pg_namespace namespace ON namespace.oid = class.relnamespace
LEFT JOIN pg_partitions parts ON class.relname = parts.partitiontablename
AND namespace.nspname = parts.schemaname
WHERE nspname NOT IN ('pg_catalog', 'information_schema', 'pg_toast', 'pg_bitmapindex', 'pg_aoseg', 'gp_toolkit')
GROUP BY nspname, relkind, coalesce(tablename, relname), pg_get_userbyid(class.relowner)
ORDER BY 1,2;
Necessary conversions
Backup files in Greenplum versions 4 and 5 are also not fully compatible. So, in Greenplum 5, due to the syntax change in the CREATE EXTERNAL TABLE and COPY commands, the INTO ERROR TABLE parameter is missing, and the SET gp_ignore_error_table parameter must be set to true so that recovery of the backup does not complete by mistake. With the parameter set we just get a warning.
In addition, in the fifth version, another protocol appeared for interacting with external pxf tables, and to use it, you need to change the LOCATION parameter and also configure the pxf service.
Also note that in the backup gp_dump & gp_restore files both on the master node and on each primary segment, the SET parameter gp_strict_xml_parse is set to false. There is no such parameter in Greenplum 5, and as a result, we get an error message.
If the gphdfs protocol was used for external tables, you should check the list of sources in the backup files in the LOCATION parameter for external tables on the line 'gphdfs: //'. For example, there should be only 'gphdfs: //hadoop.local: 8020'. If there are other lines, they need to be added to the replacement script on the master node by analogy.
grep -o gphdfs\:\/\/.*\/ /data1/master/gpseg-1/db_dumps/20181206/gp_dump_-1_1_20181206122002.gz | cut -d/ -f1-3 | sort | uniq
gphdfs://hadoop.local:8020We make replacements on the master node (by the example of the gp_dump data file):
mv /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz
gunzip -c /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz | sed "s#'gphdfs://hadoop.local:8020#'pxf:/#g" | sed "s/\(^.*pxf\:\/\/.*'\)/\1\\&\&\?PROFILE=HdfsTextSimple'/" |sed "s#'&#g" | sed 's/SET gp_strict_xml_parse = false;/SET gp_ignore_error_table = true;/g' | gzip -1 > /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz
netsIn recent versions, the profile name of hdfsTextSimple is declared deprecated , the new name is hdfs: text.
Results
Beyond the article remains a need for an explicit conversion to text ( Implicit Casting the Text ), a new management mechanism of the cluster the Resource the Groups , which replaced the Resource Queues, optimizer GPORCA , which is enabled by default in Greenplum 5, minor problems with customers.
I look forward to the release of the sixth version of Greenplum, which is scheduled for spring 2019: compatibility level with PostgreSQL 9.4, Full Text Search, GIN Index Support, Range Types, JSONB, zStd Compression. Preliminary plans for Greenplum 7 have also become known: PostgreSQL compatibility level at least 9.6, Row Level Security, Automated Master Failover. Also, the developers promise the availability of database upgrade utilities for upgrading between major versions, so it will be easier to live.
The article was prepared by the data management team of Rostelecom.