Kibana User Guide. Visualization. Part 2
- Transfer
The second part of the translation of the official documentation for data visualization in Kibana.
Link to the original material: Kibana User Guide [6.6] »Visualize
Link to 1 part: Kibana User Guide . Visualization. Part 1
Content:
Warning. This feature is experimental and may be changed or removed in a future release. Elastic will do its best to fix any problems, but experimental functions are not supported by SLA official GA functions.
Visualization of the controls allows you to add interactive input to the Kibana dashboards. You can create two types of incoming information: a drop-down list or a one-of-many radio button.
To initialize the visualization of the controls, open the Visualization tab and click the + button . Scroll to the Others section and select Controls .
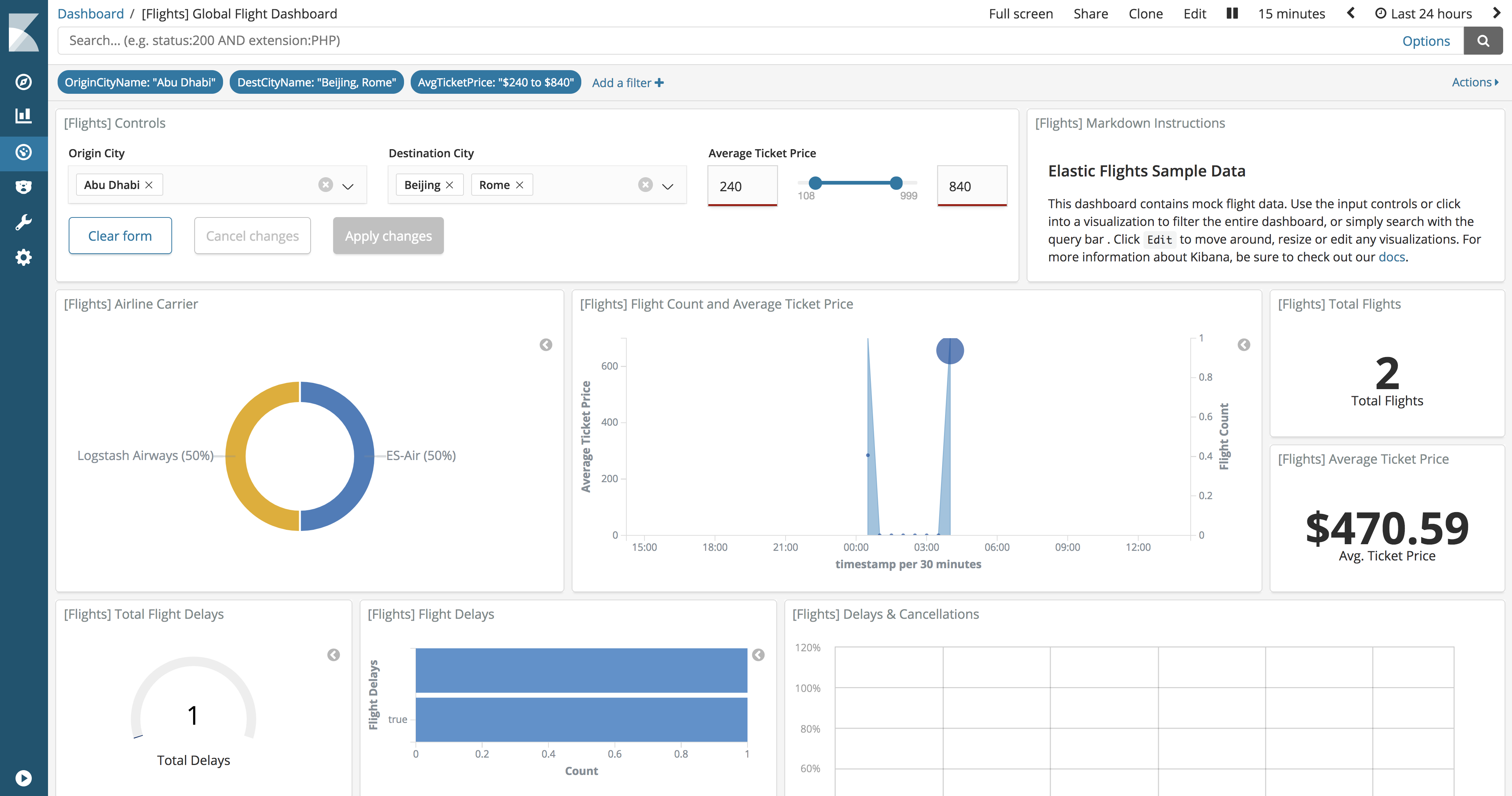
A drop-down menu allows users to filter content by selecting one or more options from the list. The drop-down menu is dynamically populated with the results of aggregation of values (terms, approx. Per.).
Control Label. Signature for the drop-down list. By default, the signature is the name of the field.
Index Pattern. An index template that contains a dataset for visualization.
Field The field is used to populate the list of options and is filtered when users interact with input. The list of available fields is obtained from the specified index template.
Parent control.A control for creating chains of drop-down menus such that selecting in the first menu filters the values in the second menu. Available only when creating multiple drop-down lists.
Multiselect. When enabled, a drop-down menu allows users to select multiple options.
Size The number of options to include in the list.
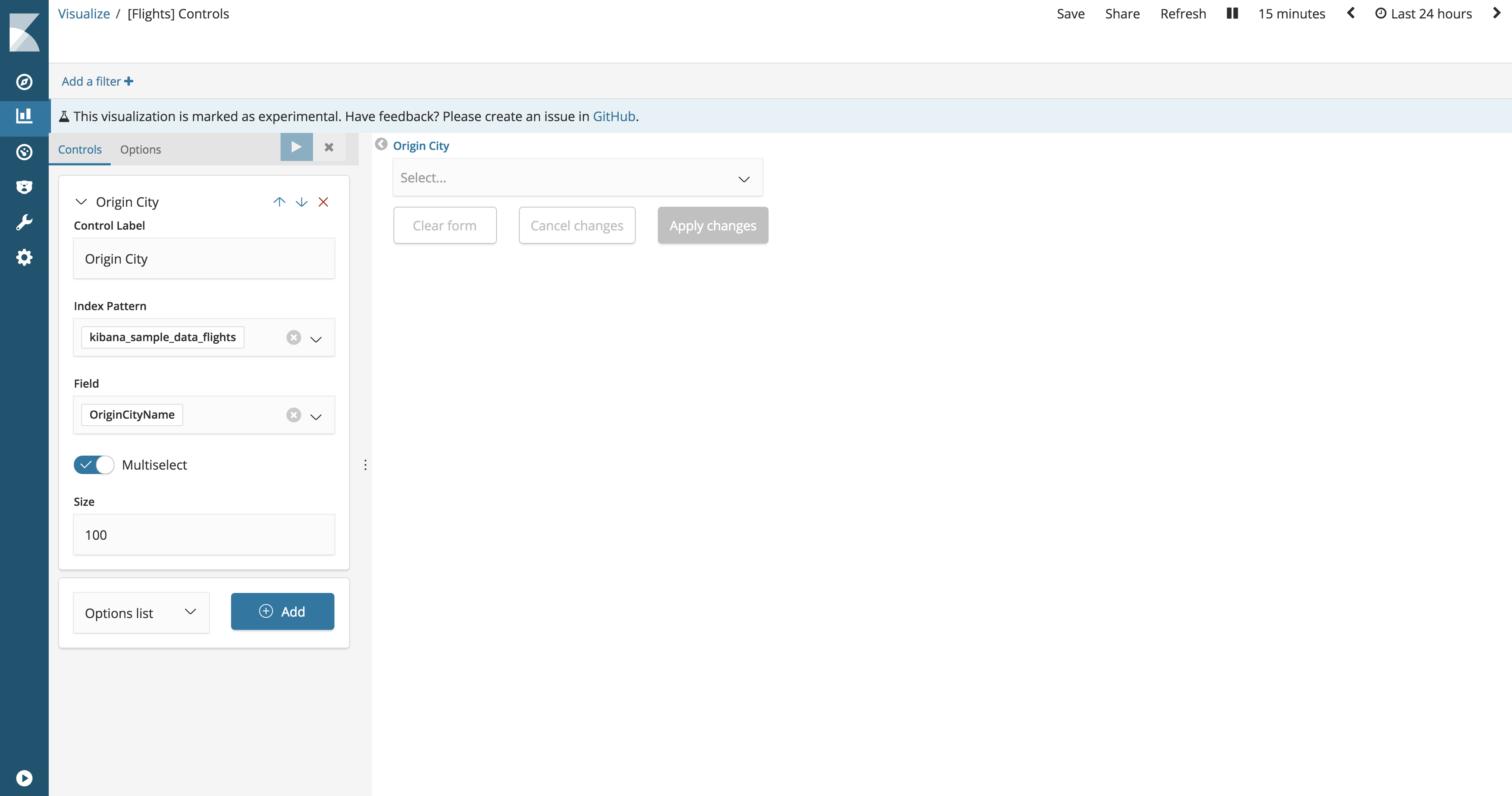
An adjustable range allows users to filter content within a range of numbers. The minimum and maximum values of the adjustable range are dynamically determined by the minimum and maximum values of aggregation.
Control Label. Signature adjustable range. By default, the signature is the name of the field.
Index Pattern. An index template that contains a dataset for visualization.
Field The field is used to fill the adjustable range and filter it when users interact with incoming data. The list of available fields is populated from a specific index template.
Step size. Increases / decreases the size of the slider.
Decimal Places. The number of decimal places.
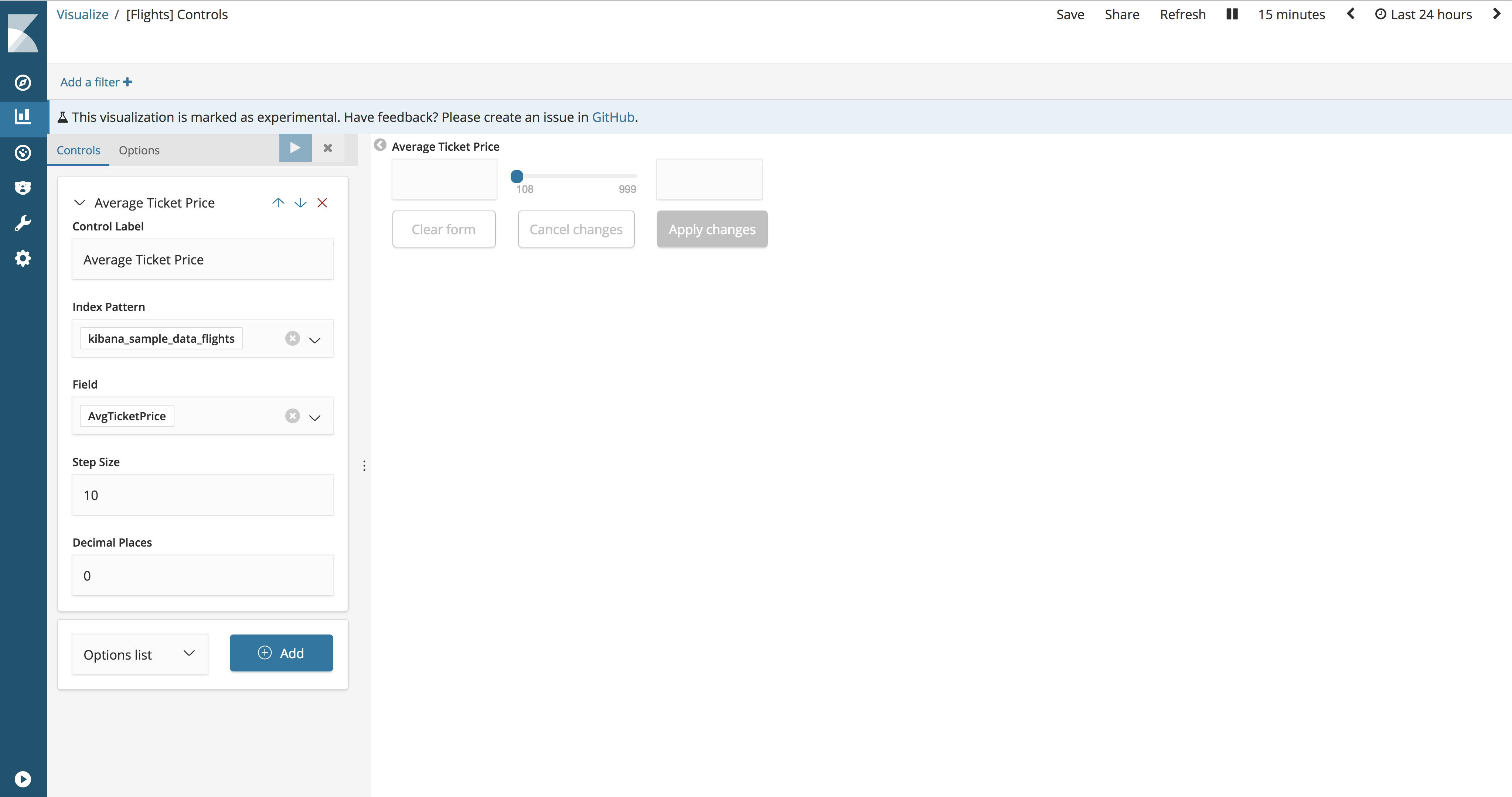
Click the Options tab to configure the settings that apply to all input controls in the Controls visualization.
Update Kibana filters on each change. When turned on, all inbound interactions instantly create filters that cause the dashboard to update. When off, Kibana filters are created when the user clicks Apply changes .
.
Use time filter. When enabled, the aggregations that are used to generate a drop-down list of options and a minimum-maximum range are tied to Kibana global time .
Pin filters to global state. When enabled, all filters created by interacting with the input data are automatically pinned.
Metric Aggregations:
Count. Count aggregation returns a net count of the elements in the selected index template.
Average This aggregation returns the average value over a numerical field. Select a field from the drop-down list.
Sum. Returns the total amount of a number field. Select a field from the drop-down list.
Min. Returns the minimum value by a numeric field. Select a field from the drop-down list.
Max Returns the maximum value by a numeric field. Select a field from the drop-down list.
Unique Count. Cardinal aggregation returns the number of unique values in a field. Select a field from the drop-down list.
Standard Deviation.Aggregation of general statistics returns the standard deviation of data in a numeric field. Select a field from the drop-down list.
Top hit. Aggregation of top values returns one or more top values from a special field in your document. Select a field from the drop-down list, type of sorting of documents, number of values to be returned.
Percentiles. Percentage aggregation divides the values of a number field into specified ranges. Select a field from the drop-down list, then define one or more areas in the Percentiles fields . Click X to remove the percent field. Click + Add to add a percentage field.
Percentile Rank.Percentage aggregation returns the percentage ranking for the selected number field. Select a field from the drop-down list, then specify one or more values of the percentage rank in the Values fields . Click X to delete the value field. Click + Add to add a value field.
Aggregations of the parent data sources:
For each aggregation of the parent information source, you must determine the metric for which the aggregation is calculated. This may be one of the existing metrics or a new one. You can also invest in these aggregations (for example, to get a third derivative).
Derivative. Derivative aggregation counts the derivative of certain metrics.
Cumulative sum.The cumulative aggregation aggregates the cumulative sum of certain metrics in the parent histogram.
Moving Average. Moving average aggregation will insert a window through the data and write the average value of this window.
Serial Diff. Sequential differentiation is a method where values in a time series are subtracted from themselves in another time period or delay.
Aggregations of a related source:
As in the case of aggregations of parent sources, you need to specify the metric by which the aggregation of a related source will be calculated. In addition, you need to provide for segment aggregation, which will determine on which segments the aggregation will start.
Average bucketThe segment average calculates the average of certain metrics in the aggregation of related sources.
Sum Bucket Calculates the sum of the values of a specific metric in the aggregation of a related source.
Min Bucket Returns the minimum value of a specific metric in an aggregation of a related source.
Max bucket Returns the maximum value of a specific metric in an aggregation of a related source.
You can create aggregation by clicking on the + Add Metrics button .
Enter a string in the Custom Label field to change the signature.
Rows of data tables are called segments. You can define segments for breaking a table into rows or for breaking into additional tables.
Each type of segment supports the following aggregations:
Date Histogram. The temporary histogram is built on the basis of a numerical field and is organized by date. You can define time frames for intervals in seconds, minutes, hours, days, weeks, months, or years. You can also define the default interval by selecting Custom as the interval and specifying the number and unit of time in the text box. The default time interval units are: s for seconds, m for minutes, h for hours, d for days, w for weeks, yfor years. Different units support different levels of accuracy, up to one second. Intervals are signed at the beginning of the interval using the date key that is returned from Elasticsearch. For example, the tooltip for the monthly interval will display the first day of the month.
Histogram. The standard histogram is built on the basis of a numerical field. Define an integer interval for this field. Select the Show empty buckets check box to include empty spacing in the histogram.
Range With the help of rank aggregation, you can define the ranks for the values of a number field. Click Add Range to add a set of rank endpoints. Click the red symbol (x) to remove the rank.
Date Range Aggregation of the time rank reports values that are in the specified date range. You can specify date ranges using mathematical date expressions. Click Add Range to add a set of rank endpoints. Click the red symbol (x) to remove the rank.
IPv4 Range. IPv4 rank aggregation allows you to define ranges of IPv4 addresses. Click Add Range to add a set of rank endpoints. Click the red symbol (x) to remove the rank.
Terms. Aggregating values allows you to define the top or bottom n elements of a given field to display, sorted by quantity or user metric.
Filters.You can define a set of filters for data. It is possible to specify the filter as a query string or in JSON format, as well as in the Discover search tab. Click Add Filter to add another filter. Click the label button to open the signature field where you can type a name for display on the visualization.
Significant Terms. Displays the results of experimental aggregation of signed values. The value of the Size parameter determines the number of inputs that this aggregation returns.
Geohash. Geo-hash aggregation displays points based on geographic coordinates.
Once you have determined the type of segment aggregation, you can define aggregation subgroups to improve visualization. Click on+ Add sub-buckets to create a nested segment, then select Split Rows or Split Table , then select aggregation from the list of types.
You can use the up / down arrows to the right of the aggregation type to change the aggregation priority.
Enter a line in the Custom Label field to change the signature.
You can click on the Advanced link to display more options for your metrics or segment aggregation:
Exclude Pattern. Specify a template in this field to exclude from the results.
Include Pattern. Specify a template in this field to include in the results.
JSON Input.A text field where you can add specific properties in JSON format to merge with a specific aggregation, as in the following example:
Note. In Elasticsearch 1.4.3 and later, this functionality needs Groovy dynamic scripting enabled .
The availability of these options depends on the aggregation you select.
Select the Options tab to change the following aspects of the table:
Per Page. This field controls the pagination of the table. By default, the value is ten lines per page.
Enable / disable flags are available for the following actions:
Show metrics for every bucket / level.Check this box to display intermediate results for each segment aggregation.
Show partial rows. Mark this position to display the line even if there is no result.
Note. Enabling these options can seriously affect performance.
The Markdown widget is a text input field that accepts Markdown's github-encoded text. Kibana executes the text that you enter in this field and displays the results in the dashboard. You can click the Help link to go to the GitHub-assisted Markdown help page . Click Apply to display the executable text in the preview panel or Discard to return to the previous version.
Metric visualization displays one number for each selected aggregation.
Metric Aggregations:
Count. Count aggregation returns a net count of the elements in the selected index template.
Average This aggregation returns the average value over a numerical field. Select a field from the drop-down list.
Sum. Returns the total amount of a number field. Select a field from the drop-down list.
Min. Returns the minimum value by a numeric field. Select a field from the drop-down list.
Max Returns the maximum value by a numeric field. Select a field from the drop-down list.
Unique Count.Cardinal aggregation returns the number of unique values in a field. Select a field from the drop-down list.
Standard Deviation. Aggregation of general statistics returns the standard deviation of data in a numeric field. Select a field from the drop-down list.
Top hit. Aggregation of top values returns one or more top values from a special field in your document. Select a field from the drop-down list, type of sorting of documents, number of values to be returned.
Percentiles. Percentage aggregation divides the values of a number field into specified ranges. Select a field from the drop-down list, then define one or more areas in the Percentiles fields . Click X to remove the percent field. Click on+ Add to add a percentage field.
Percentile Rank. Percentage aggregation returns the percentage ranking for the selected number field. Select a field from the drop-down list, then specify one or more values of the percentage rank in the Values fields . Click X to delete the value field. Click + Add to add a value field.
Aggregations of the parent data sources:
For each aggregation of the parent information source, you must determine the metric for which the aggregation is calculated. This may be one of the existing metrics or a new one. You can also invest in these aggregations (for example, to get a third derivative).
Derivative.Derivative aggregation counts the derivative of certain metrics.
Cumulative sum. The cumulative aggregation aggregates the cumulative sum of certain metrics in the parent histogram.
Moving Average. Moving average aggregation will insert a window through the data and write the average value of this window.
Serial Diff. Sequential differentiation is a method where values in a time series are subtracted from themselves in another time period or delay.
Aggregations of a related source:
As in the case of aggregations of parent sources, you need to specify the metric by which aggregation of the related source will be calculated. In addition, you need to provide for segment aggregation, which will determine on which segments the aggregation will start.
Average bucket The segment average calculates the average of certain metrics in the aggregation of related sources.
Sum Bucket Calculates the sum of the values of a specific metric in the aggregation of a related source.
Min Bucket Returns the minimum value of a specific metric in an aggregation of a related source.
Max bucket Returns the maximum value of a specific metric in an aggregation of a related source.
You can create aggregation by clicking on the + Add Metrics button .
Enter a string in the Custom Label field to change the signature.
You can click on the Advanced link to display more options:
JSON Input. A text field where you can add specific properties in JSON format to merge with a specific aggregation, as in the following example:
Note. In Elasticsearch 1.4.3 and later, this functionality needs Groovy dynamic scripting enabled .
The availability of these options depends on the aggregation you select.
Click the Options tab to display the font size slider.
The third part.
Link to the original material: Kibana User Guide [6.6] »Visualize
Link to 1 part: Kibana User Guide . Visualization. Part 1
Content:
- Controls Visualization
- Data table
- Markdown widget
- Metric
Controls Visualization
Warning. This feature is experimental and may be changed or removed in a future release. Elastic will do its best to fix any problems, but experimental functions are not supported by SLA official GA functions.
Visualization of the controls allows you to add interactive input to the Kibana dashboards. You can create two types of incoming information: a drop-down list or a one-of-many radio button.
Adding input controls
To initialize the visualization of the controls, open the Visualization tab and click the + button . Scroll to the Others section and select Controls .
Dropdown menu
A drop-down menu allows users to filter content by selecting one or more options from the list. The drop-down menu is dynamically populated with the results of aggregation of values (terms, approx. Per.).
Control Label. Signature for the drop-down list. By default, the signature is the name of the field.
Index Pattern. An index template that contains a dataset for visualization.
Field The field is used to populate the list of options and is filtered when users interact with input. The list of available fields is obtained from the specified index template.
Parent control.A control for creating chains of drop-down menus such that selecting in the first menu filters the values in the second menu. Available only when creating multiple drop-down lists.
Multiselect. When enabled, a drop-down menu allows users to select multiple options.
Size The number of options to include in the list.
Range slider
An adjustable range allows users to filter content within a range of numbers. The minimum and maximum values of the adjustable range are dynamically determined by the minimum and maximum values of aggregation.
Control Label. Signature adjustable range. By default, the signature is the name of the field.
Index Pattern. An index template that contains a dataset for visualization.
Field The field is used to fill the adjustable range and filter it when users interact with incoming data. The list of available fields is populated from a specific index template.
Step size. Increases / decreases the size of the slider.
Decimal Places. The number of decimal places.
Global variables
Click the Options tab to configure the settings that apply to all input controls in the Controls visualization.
Update Kibana filters on each change. When turned on, all inbound interactions instantly create filters that cause the dashboard to update. When off, Kibana filters are created when the user clicks Apply changes
. Use time filter. When enabled, the aggregations that are used to generate a drop-down list of options and a minimum-maximum range are tied to Kibana global time .
Pin filters to global state. When enabled, all filters created by interacting with the input data are automatically pinned.
Data table
Metric Aggregations:
Count. Count aggregation returns a net count of the elements in the selected index template.
Average This aggregation returns the average value over a numerical field. Select a field from the drop-down list.
Sum. Returns the total amount of a number field. Select a field from the drop-down list.
Min. Returns the minimum value by a numeric field. Select a field from the drop-down list.
Max Returns the maximum value by a numeric field. Select a field from the drop-down list.
Unique Count. Cardinal aggregation returns the number of unique values in a field. Select a field from the drop-down list.
Standard Deviation.Aggregation of general statistics returns the standard deviation of data in a numeric field. Select a field from the drop-down list.
Top hit. Aggregation of top values returns one or more top values from a special field in your document. Select a field from the drop-down list, type of sorting of documents, number of values to be returned.
Percentiles. Percentage aggregation divides the values of a number field into specified ranges. Select a field from the drop-down list, then define one or more areas in the Percentiles fields . Click X to remove the percent field. Click + Add to add a percentage field.
Percentile Rank.Percentage aggregation returns the percentage ranking for the selected number field. Select a field from the drop-down list, then specify one or more values of the percentage rank in the Values fields . Click X to delete the value field. Click + Add to add a value field.
Aggregations of the parent data sources:
For each aggregation of the parent information source, you must determine the metric for which the aggregation is calculated. This may be one of the existing metrics or a new one. You can also invest in these aggregations (for example, to get a third derivative).
Derivative. Derivative aggregation counts the derivative of certain metrics.
Cumulative sum.The cumulative aggregation aggregates the cumulative sum of certain metrics in the parent histogram.
Moving Average. Moving average aggregation will insert a window through the data and write the average value of this window.
Serial Diff. Sequential differentiation is a method where values in a time series are subtracted from themselves in another time period or delay.
Aggregations of a related source:
As in the case of aggregations of parent sources, you need to specify the metric by which the aggregation of a related source will be calculated. In addition, you need to provide for segment aggregation, which will determine on which segments the aggregation will start.
Average bucketThe segment average calculates the average of certain metrics in the aggregation of related sources.
Sum Bucket Calculates the sum of the values of a specific metric in the aggregation of a related source.
Min Bucket Returns the minimum value of a specific metric in an aggregation of a related source.
Max bucket Returns the maximum value of a specific metric in an aggregation of a related source.
You can create aggregation by clicking on the + Add Metrics button .
Enter a string in the Custom Label field to change the signature.
Rows of data tables are called segments. You can define segments for breaking a table into rows or for breaking into additional tables.
Each type of segment supports the following aggregations:
Date Histogram. The temporary histogram is built on the basis of a numerical field and is organized by date. You can define time frames for intervals in seconds, minutes, hours, days, weeks, months, or years. You can also define the default interval by selecting Custom as the interval and specifying the number and unit of time in the text box. The default time interval units are: s for seconds, m for minutes, h for hours, d for days, w for weeks, yfor years. Different units support different levels of accuracy, up to one second. Intervals are signed at the beginning of the interval using the date key that is returned from Elasticsearch. For example, the tooltip for the monthly interval will display the first day of the month.
Histogram. The standard histogram is built on the basis of a numerical field. Define an integer interval for this field. Select the Show empty buckets check box to include empty spacing in the histogram.
Range With the help of rank aggregation, you can define the ranks for the values of a number field. Click Add Range to add a set of rank endpoints. Click the red symbol (x) to remove the rank.
Date Range Aggregation of the time rank reports values that are in the specified date range. You can specify date ranges using mathematical date expressions. Click Add Range to add a set of rank endpoints. Click the red symbol (x) to remove the rank.
IPv4 Range. IPv4 rank aggregation allows you to define ranges of IPv4 addresses. Click Add Range to add a set of rank endpoints. Click the red symbol (x) to remove the rank.
Terms. Aggregating values allows you to define the top or bottom n elements of a given field to display, sorted by quantity or user metric.
Filters.You can define a set of filters for data. It is possible to specify the filter as a query string or in JSON format, as well as in the Discover search tab. Click Add Filter to add another filter. Click the label button to open the signature field where you can type a name for display on the visualization.
Significant Terms. Displays the results of experimental aggregation of signed values. The value of the Size parameter determines the number of inputs that this aggregation returns.
Geohash. Geo-hash aggregation displays points based on geographic coordinates.
Once you have determined the type of segment aggregation, you can define aggregation subgroups to improve visualization. Click on+ Add sub-buckets to create a nested segment, then select Split Rows or Split Table , then select aggregation from the list of types.
You can use the up / down arrows to the right of the aggregation type to change the aggregation priority.
Enter a line in the Custom Label field to change the signature.
You can click on the Advanced link to display more options for your metrics or segment aggregation:
Exclude Pattern. Specify a template in this field to exclude from the results.
Include Pattern. Specify a template in this field to include in the results.
JSON Input.A text field where you can add specific properties in JSON format to merge with a specific aggregation, as in the following example:
{ "script" : "doc['grade'].value * 1.2" }Note. In Elasticsearch 1.4.3 and later, this functionality needs Groovy dynamic scripting enabled .
The availability of these options depends on the aggregation you select.
Select the Options tab to change the following aspects of the table:
Per Page. This field controls the pagination of the table. By default, the value is ten lines per page.
Enable / disable flags are available for the following actions:
Show metrics for every bucket / level.Check this box to display intermediate results for each segment aggregation.
Show partial rows. Mark this position to display the line even if there is no result.
Note. Enabling these options can seriously affect performance.
Markdown widget
The Markdown widget is a text input field that accepts Markdown's github-encoded text. Kibana executes the text that you enter in this field and displays the results in the dashboard. You can click the Help link to go to the GitHub-assisted Markdown help page . Click Apply to display the executable text in the preview panel or Discard to return to the previous version.
Metric
Metric visualization displays one number for each selected aggregation.
Metric Aggregations:
Count. Count aggregation returns a net count of the elements in the selected index template.
Average This aggregation returns the average value over a numerical field. Select a field from the drop-down list.
Sum. Returns the total amount of a number field. Select a field from the drop-down list.
Min. Returns the minimum value by a numeric field. Select a field from the drop-down list.
Max Returns the maximum value by a numeric field. Select a field from the drop-down list.
Unique Count.Cardinal aggregation returns the number of unique values in a field. Select a field from the drop-down list.
Standard Deviation. Aggregation of general statistics returns the standard deviation of data in a numeric field. Select a field from the drop-down list.
Top hit. Aggregation of top values returns one or more top values from a special field in your document. Select a field from the drop-down list, type of sorting of documents, number of values to be returned.
Percentiles. Percentage aggregation divides the values of a number field into specified ranges. Select a field from the drop-down list, then define one or more areas in the Percentiles fields . Click X to remove the percent field. Click on+ Add to add a percentage field.
Percentile Rank. Percentage aggregation returns the percentage ranking for the selected number field. Select a field from the drop-down list, then specify one or more values of the percentage rank in the Values fields . Click X to delete the value field. Click + Add to add a value field.
Aggregations of the parent data sources:
For each aggregation of the parent information source, you must determine the metric for which the aggregation is calculated. This may be one of the existing metrics or a new one. You can also invest in these aggregations (for example, to get a third derivative).
Derivative.Derivative aggregation counts the derivative of certain metrics.
Cumulative sum. The cumulative aggregation aggregates the cumulative sum of certain metrics in the parent histogram.
Moving Average. Moving average aggregation will insert a window through the data and write the average value of this window.
Serial Diff. Sequential differentiation is a method where values in a time series are subtracted from themselves in another time period or delay.
Aggregations of a related source:
As in the case of aggregations of parent sources, you need to specify the metric by which aggregation of the related source will be calculated. In addition, you need to provide for segment aggregation, which will determine on which segments the aggregation will start.
Average bucket The segment average calculates the average of certain metrics in the aggregation of related sources.
Sum Bucket Calculates the sum of the values of a specific metric in the aggregation of a related source.
Min Bucket Returns the minimum value of a specific metric in an aggregation of a related source.
Max bucket Returns the maximum value of a specific metric in an aggregation of a related source.
You can create aggregation by clicking on the + Add Metrics button .
Enter a string in the Custom Label field to change the signature.
You can click on the Advanced link to display more options:
JSON Input. A text field where you can add specific properties in JSON format to merge with a specific aggregation, as in the following example:
{ "script" : "doc['grade'].value * 1.2" }Note. In Elasticsearch 1.4.3 and later, this functionality needs Groovy dynamic scripting enabled .
The availability of these options depends on the aggregation you select.
Click the Options tab to display the font size slider.
The third part.