Audio AI: extracting vocals from music using convolutional neural networks
- Transfer
Hacking music to democratize derived content
I wish I could return to 1965, knock on the front door of the Abby Road studio with a pass, go inside - and hear the real voices of Lennon and McCartney ... Well, let's try. Input: The Beatles' mid-quality MP3 We Can Work it Out . The upper track is the input mix, the lower track is the isolated vocals that our neural network has highlighted.
Formally, this problem is known as separation of sound sources or separation of the signal (audio source separation). It consists in restoring or reconstructing one or more of the original signals, which, as a result of a linear or convolutional process, are mixed with other signals. This research area has many practical applications, including improving sound (speech) quality and eliminating noise, music remixes, spatial distribution of sound, remastering, etc. Sound engineers sometimes call this technique stratification.(demixing). There are a lot of resources on this topic, from blind separation of signals with analysis of independent components (ICA) to semi-controlled factorization of non-negative matrices and ending with later approaches based on neural networks. You can find good information on the first two points in these mini-guides from CCRMA, which at one time were very useful to me.
But before diving into development ... quite a bit of the philosophy of applied machine learning ...
I was engaged in signal and image processing even before the slogan “deep learning decides everything” has spread, so I can present you a solution as a feature engineering journey and show why for this particular neural network problems turns out to be the best approach. What for? Very often, I see people write something like this:
“With deep learning, you no longer have to worry about choosing features; it will do it for you "
or worse ...
" The difference between machine learning and deep learning [hey ... deep learning is still machine learning!] is that in ML you yourself extract the attributes, and in deep learning this happens automatically inside network ".
These generalizations probably come from the fact that DNNs can be very effective in exploring good hidden spaces. But so it is impossible to generalize. I am very upset when recent graduates and practitioners succumb to the above misconceptions and adopt the “deep-learning-it-all” approach. Like, it’s enough to throw a bunch of raw data (even after a little preliminary processing) - and everything will work as it should. In the real world, you need to take care of things like performance, real-time execution, and so on. Because of such misconceptions, you will get stuck in experiment mode for a very long time ...
Feature Engineering remains a very important discipline in the design of artificial neural networks. As in any other ML technique, in most cases it is it that distinguishes effective solutions of the production level from unsuccessful or ineffective experiments. A deep understanding of your data and its nature still means a lot ...
Ok, I finished the sermon. Now let's see why we are here! As with any data processing problem, let's first see what it looks like. Take a look at the next piece of vocals from the original studio recording.
Studio vocals 'One Last Time', Ariana Grande
Not too interesting, right? Well, this is because we visualize the signal in time . Here we see only amplitude changes over time. But you can extract all sorts of other things, such as amplitude envelopes (envelope), root mean square values (RMS), the rate of change from positive values of amplitude to negative (zero-crossing rate), etc., but these signs are too primitive and not sufficiently distinctive, to help in our problem. If we want to extract vocals from an audio signal, first we need to somehow determine the structure of human speech. Fortunately, the Window Fourier Transform (STFT) comes to the rescue .
STFT amplitude spectrum - window size = 2048, overlap = 75%, logarithmic frequency scale [Sonic Visualizer]
Although I like speech processing and definitely like playing with input filter simulations, cepstrum, sottottami, LPC, MFCC and so on, we ’ll skip all this bullshit and focus on the main elements related to our problem so that the article is understood by as many people as possible, and not just signal processing specialists.
So what does the structure of human speech tell us?
Well, we can define three main elements here:
Let's forget for a second what is called machine learning. Can a vocal extraction method be developed based on our knowledge of the signal? Let me try ...
Naive V1.0 vocals isolation:

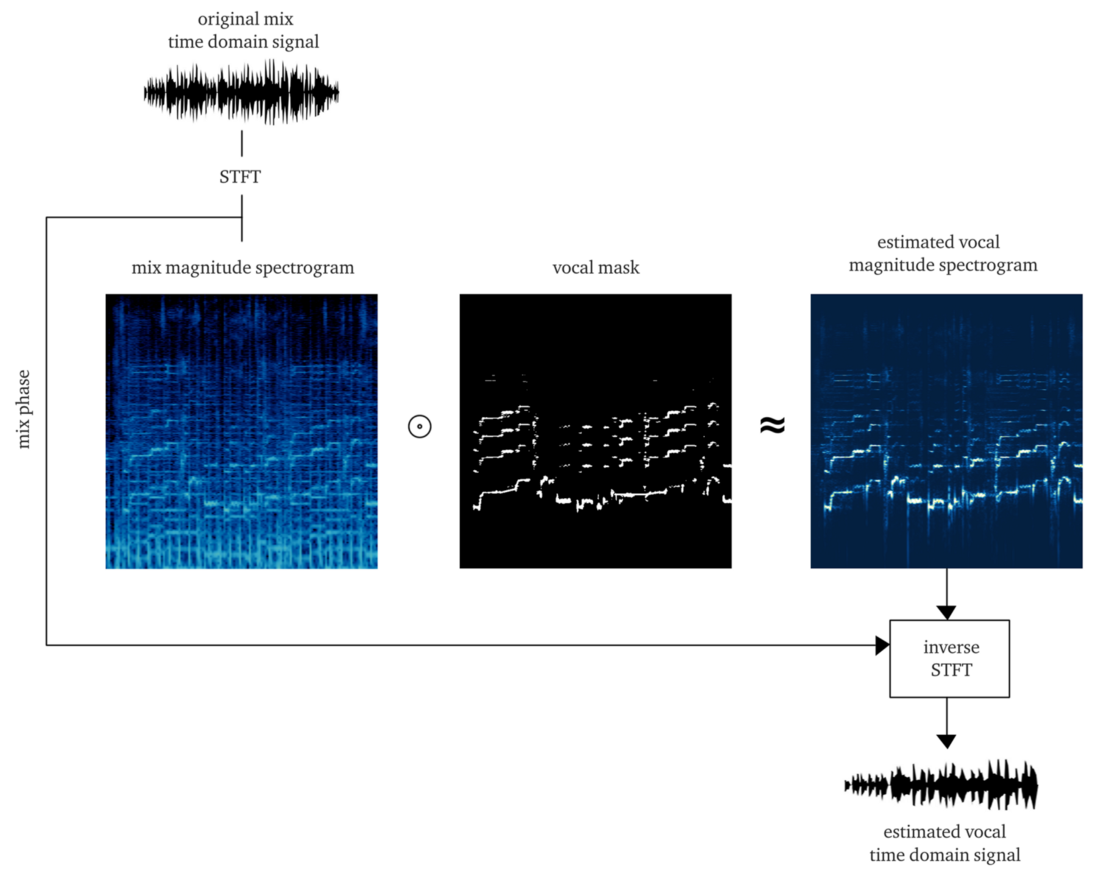
If we work worthily, the result should be a soft or bit mask , the application of which to the amplitude of the STFT (elementwise multiplication) gives an approximate reconstruction of the amplitude of the STFT vocals. Then we combine this vocal STFT with the phase information of the original signal, calculate the inverse STFT, and get the time signal of the reconstructed vocal.
Doing it from scratch is already a big job. But for the sake of demonstration, the implementation of the pYIN algorithm is applicable . Although it is intended to solve step 3, but with the correct settings, it performs decently steps 1 and 2, tracking the vocal basis even in the presence of music. The example below contains the output after processing this algorithm, without processing unvoiced speech.
So what...? He seems to have done all the work, but there is no good quality and close. Perhaps by spending more time, energy and money, we will improve this method ...
But let me ask you ...
What happens if a few voices appear on the track , and this is often found in at least 50% of modern professional tracks?
What happens if the vocals are processed by reverb, delays and other effects? Let's take a look at the last chorus of Ariana Grande from this song.
Do you already feel pain ...? I am yes.
Such methods on strict rules very quickly turn into a house of cards. The problem is too complicated. Too many rules, too many exceptions, and too many different conditions (effects and mix settings). A multi-step approach also implies that errors in one step extend problems to the next step. Improving each step will become very expensive: it will take a large number of iterations to get it right. And last, but not least, it is likely that in the end we will get a very resource-intensive conveyor, which in itself can negate all efforts.
In such a situation, it's time to start thinking about a more comprehensiveapproach and allow ML to find out part of the basic processes and operations necessary to solve the problem. But we still have to show our skills and do feature engineering, and you will see why.
Looking at the achievements of convolutional neural networks in photo processing, why not apply the same approach here?
Neural networks successfully solve such problems as colorization of images, sharpening and resolution.
In the end, you can imagine an audio signal “as an image” using a short-term Fourier transform, right? Although these sound images do not correspond to the statistical distribution of natural images, they still have spatial patterns (in time and frequency space) on which to train the network.

Left: drum beat and baseline below, several synthesizer sounds in the middle, all mixed with vocals. Right: only vocals
Conducting such an experiment would be an expensive undertaking since it is difficult to obtain or generate the necessary training data. But in applied research, I always try to use this approach: first, to identify a simpler problem that confirms the same principles , but does not require a lot of work. This allows you to evaluate the hypothesis, iterate faster and correct the model with minimal losses if it does not work as it should.
The implied condition is that the neural network must understand the structure of human speech . A simpler problem may be this: can a neural network determine the presence of speech on an arbitrary fragment of a sound recording . We are talking about a reliable voice activity detector (VAD)implemented as a binary classifier.
We know that sound signals, such as music and human speech, are based on time dependencies. Simply put, nothing happens in isolation at a given point in time. If I want to know if there is a voice on a particular piece of sound recording, then I need to look at neighboring regions. Such a time context provides good information about what is happening in the area of interest. At the same time, it is desirable to perform a classification with very small time increments in order to recognize a human voice with the highest possible time resolution.

Let's count a little ...
With the above requirements, the input and output of our binary classifier are as follows:
Using Keras, we will build a small model of a neural network to test our hypothesis.
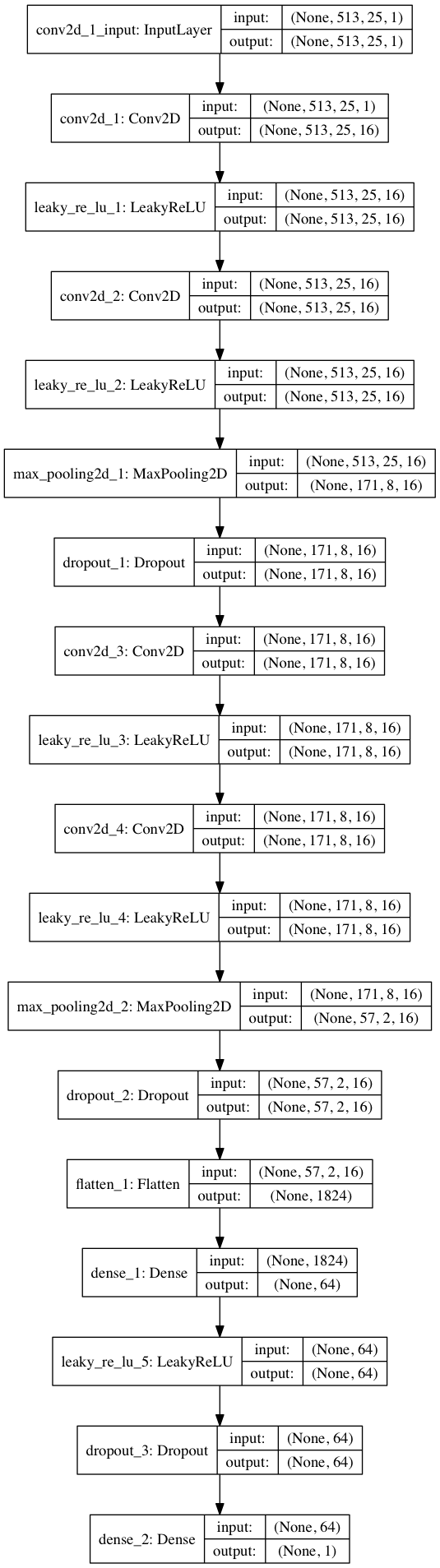
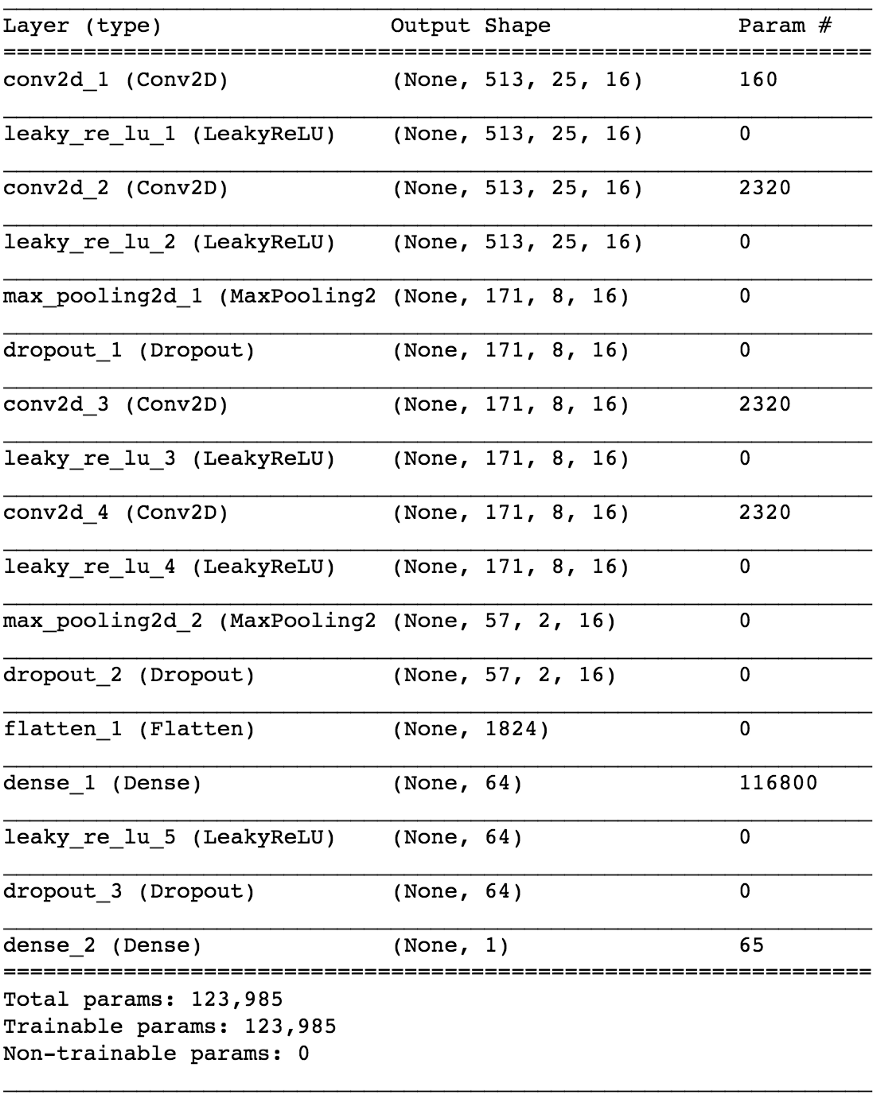
By dividing the 80/20 data into training and testing after ~ 50 eras, we get the accuracy when testing ~ 97% . This is sufficient evidence that our model is able to distinguish between vocals in musical sound fragments (and fragments without vocals). If we check some feature maps from the 4th convolutional layer, we can conclude that the neural network seems to have optimized its kernels to perform two tasks: filtering music and filtering vocals ...
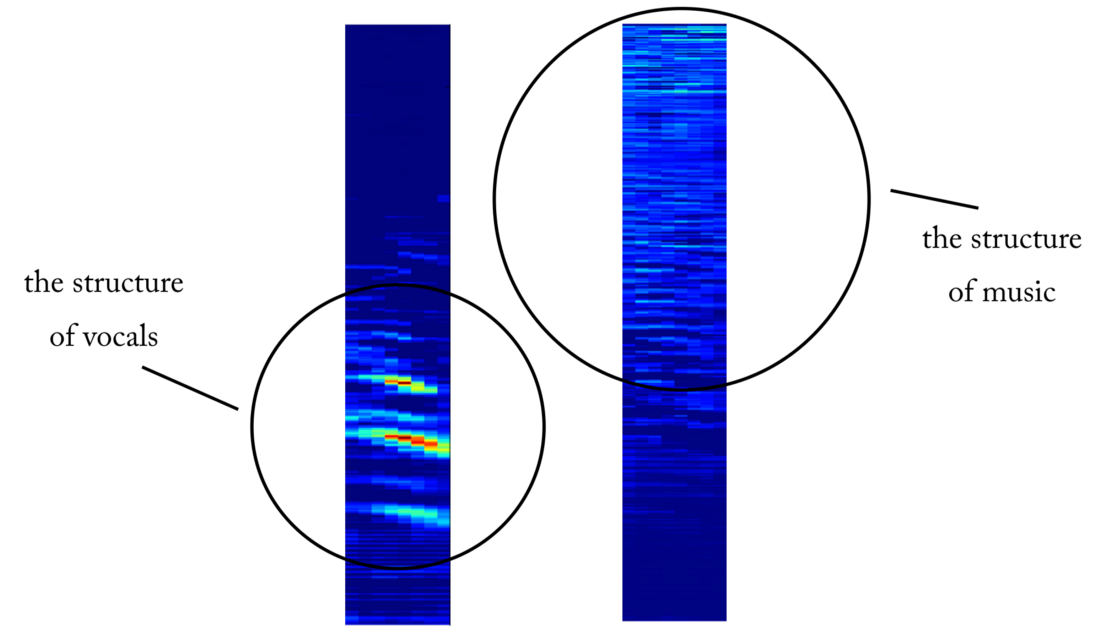
An example of an object map at the output of the 4th convolutional layer. Apparently, the output on the left is the result of kernel operations in an attempt to preserve vocal content while ignoring music. High values resemble the harmonious structure of human speech. The object map on the right seems to be the result of the opposite task.
Having solved the simpler classification problem, how can we move on to the real separation of vocals from music? Well, looking at the first naive method, we still want to somehow get the amplitude spectrogram for vocals. Now this is becoming a regression task. What we want to do is to calculate the corresponding amplitude spectrum for the vocals in this time frame from the STFT of the original signal, that is, from the mix (with a sufficient time context).
What about training dataset? (you can ask me at this moment)
Damn ... why so. I was going to consider this at the end of the article so as not to be distracted from the topic!
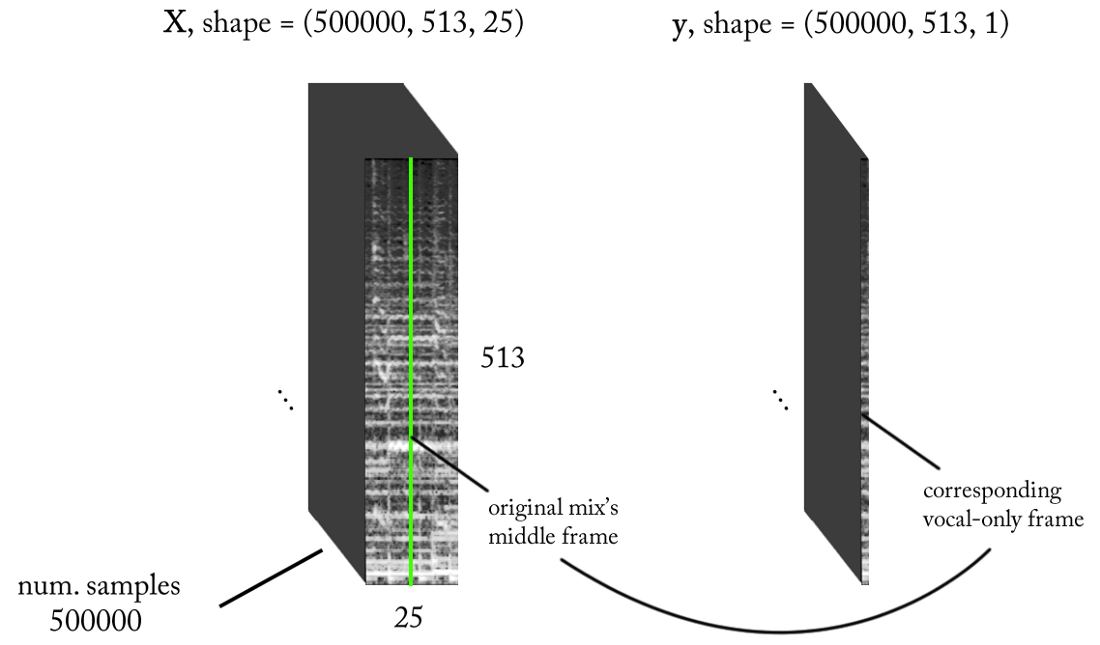
If our model is well-trained, then for a logical conclusion you just need to implement a simple sliding window to the STFT mix. After each forecast, move the window to the right by 1 timeframe, predict the next frame with vocals and associate it with the previous prediction. As for the model, we take the same model that was used for the voice detector and make small changes: the output signal form is now (513.1), linear activation at the output, MSE as a function of losses. Now we begin training.
So far, don’t rejoice ...
Although such an input / output representation makes sense, after training our model several times, with various parameters and data normalizations, there are no results. It seems we are asking too much ...
We have moved from a binary classifier to regressionon a 513-dimensional vector. Although the network is studying the problem to some extent, there are still obvious artifacts and interference from other sources in the restored vocals. Even after adding additional layers and increasing the number of model parameters, the results do not change much. And then the question arises: how to “simplify” the task for the network by deception, and at the same time achieve the desired results?
What if, instead of estimating the amplitude of the STFT vocals, we train the network to obtain a binary mask, which when applied to the STFT mix gives us a simplified, but perceptually acceptable amplitude spectrogram of the vocals?
Experimenting with various heuristics, we came up with a very simple (and, of course, unorthodox in terms of signal processing ...) way to extract vocals from mixes using binary masks. Without going into details, the essence is as follows. Imagine the output as a binary image, where the value '1' indicates the prevailing presence of vocal content at a given frequency and timeframe, and the value '0' indicates the prevailing presence of music in a given place. We can call it the binarization of perception , just to come up with a name. Visually, it looks pretty ugly, to be honest, but the results are surprisingly good.
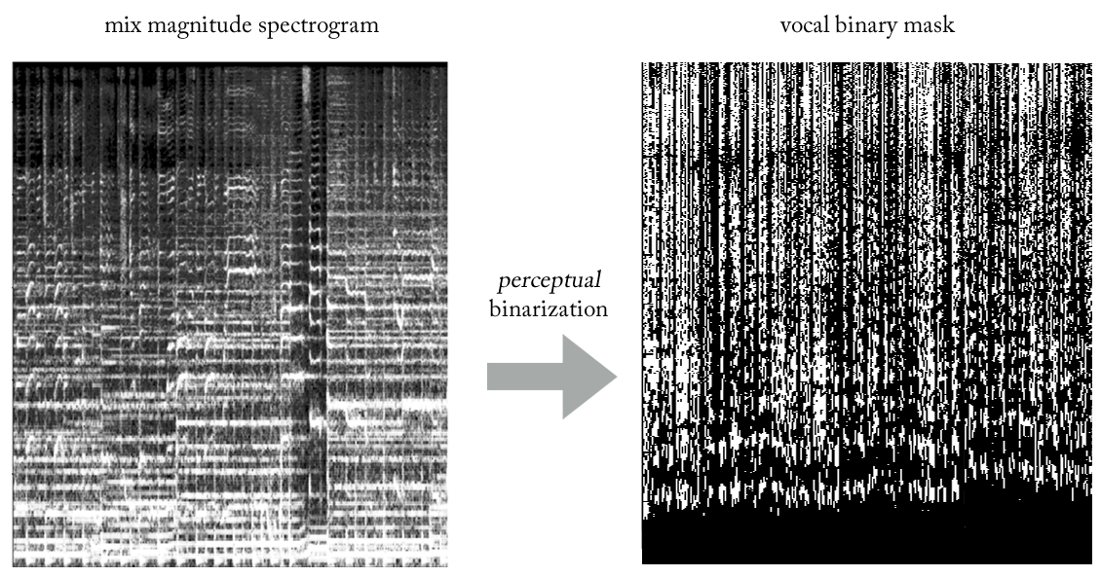
Now our problem is becoming a kind of hybrid regression-classification (very roughly ...). We ask the model to “classify pixels” at the output as vocal or non-vocal, although conceptually (as well as from the point of view of the used MSE loss function) the task remains regressive.
Although this distinction may seem inappropriate for some, in fact it is of great importance in the ability of the model to study the task, the second of which is simpler and more limited. At the same time, this allows us to keep our model relatively small in terms of the number of parameters, given the complexity of the task, something very desirable for real-time work, which in this case was a design requirement. After some minor tweaks, the final model looks like this.

In fact, as in the naive method . In this case, for each passage, we predict one timeframe of the binary vocals mask. Again, realizing a simple sliding window with a step of one timeframe, we continue to evaluate and combine successive timeframes, which ultimately make up the entire vocal binary mask.

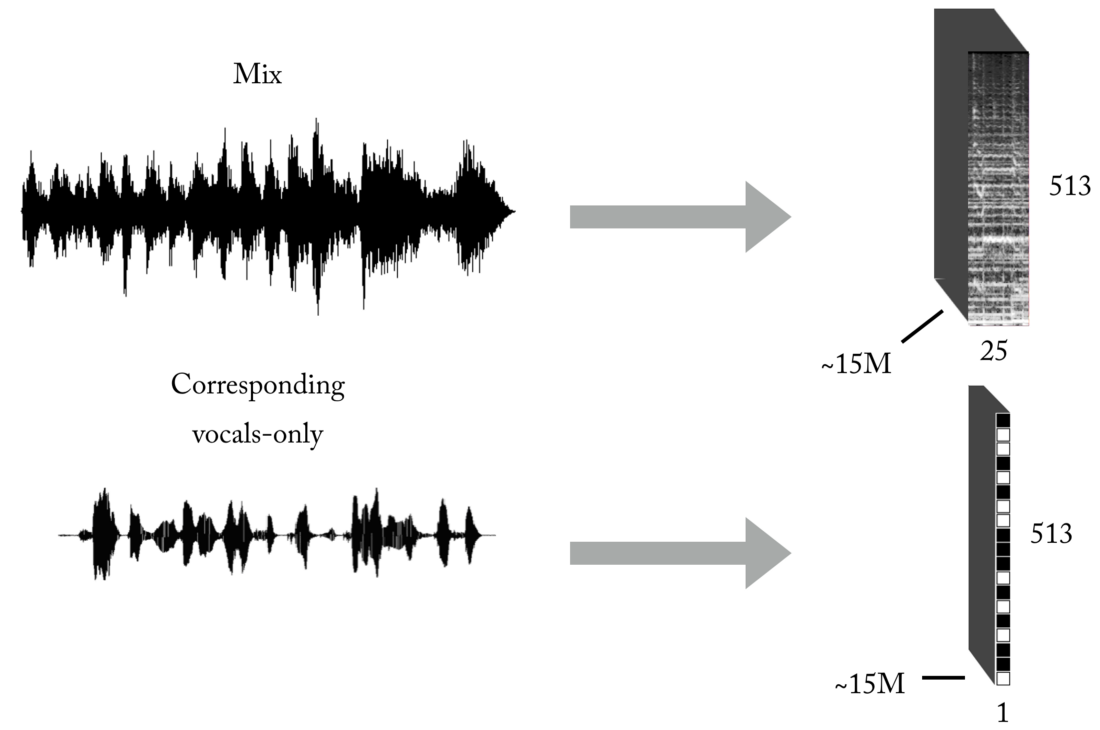
As you know, one of the main problems when teaching with a teacher (leave these toy examples with ready-made datasets) is the correct data (in quantity and quality) for the specific problem you are trying to solve. Based on the described representations of input and output, for training our model, you will first need a significant number of mixes and their corresponding, perfectly aligned and normalized vocal tracks. This set can be created in several ways, and we used a combination of strategies, from manually creating pairs [mix <-> vocals] based on several a cappella found on the Internet, to searching for rock band music material and Youtube scrapbooking. Just to give you an idea of how laborious and painful the process is,

A really large amount of data is needed for the neural network to learn the transfer function for broadcasting mixes to vocals. Our final set consisted of approximately 15 million samples of 300 ms mixes and their corresponding vocal binary masks.
As you probably know, creating an ML model for a specific task is only half the battle. In the real world, you need to think over the software architecture, especially if you need work in real time or close to it.
In this particular implementation, reconstruction in the time domain can occur immediately after predicting the complete binary vocals mask (stand-alone mode) or, more interestingly, in multi-threaded mode, where we receive and process data, restore vocals and reproduce sound - all in small segments, close to streaming and even almost in real time, processing music that is recorded on the fly with minimal delay. Actually, this is a separate topic, and I will leave it for another article on real-time ML pipelines ...
Here you can hear some minimal interference from the drums ...
Notice how at the very beginning our model extracts the screams of the crowd as vocal content :). In this case, there is some interference from other sources. Since this is a live recording, it seems acceptable that the extracted vocals are worse quality than the previous ones.
The article is already quite large, but given the work done, you deserve to hear the latest demo. With exactly the same logic as when extracting vocals, we can try to divide the stereo music into components (drums, basses, vocals, others), making some changes in our model and, of course, having the appropriate training set :).
Thank you for reading. As a final note: as you can see, the actual model of our convolutional neural network is not so special. The success of this work was determined by Feature Engineering and the neat hypothesis testing process, which I will write about in future articles!
Disclaimer: All intellectual property, designs, and methods described in this article are disclosed in US10014002B2 and US9842609B2.
I wish I could return to 1965, knock on the front door of the Abby Road studio with a pass, go inside - and hear the real voices of Lennon and McCartney ... Well, let's try. Input: The Beatles' mid-quality MP3 We Can Work it Out . The upper track is the input mix, the lower track is the isolated vocals that our neural network has highlighted.
Formally, this problem is known as separation of sound sources or separation of the signal (audio source separation). It consists in restoring or reconstructing one or more of the original signals, which, as a result of a linear or convolutional process, are mixed with other signals. This research area has many practical applications, including improving sound (speech) quality and eliminating noise, music remixes, spatial distribution of sound, remastering, etc. Sound engineers sometimes call this technique stratification.(demixing). There are a lot of resources on this topic, from blind separation of signals with analysis of independent components (ICA) to semi-controlled factorization of non-negative matrices and ending with later approaches based on neural networks. You can find good information on the first two points in these mini-guides from CCRMA, which at one time were very useful to me.
But before diving into development ... quite a bit of the philosophy of applied machine learning ...
I was engaged in signal and image processing even before the slogan “deep learning decides everything” has spread, so I can present you a solution as a feature engineering journey and show why for this particular neural network problems turns out to be the best approach. What for? Very often, I see people write something like this:
“With deep learning, you no longer have to worry about choosing features; it will do it for you "
or worse ...
" The difference between machine learning and deep learning [hey ... deep learning is still machine learning!] is that in ML you yourself extract the attributes, and in deep learning this happens automatically inside network ".
These generalizations probably come from the fact that DNNs can be very effective in exploring good hidden spaces. But so it is impossible to generalize. I am very upset when recent graduates and practitioners succumb to the above misconceptions and adopt the “deep-learning-it-all” approach. Like, it’s enough to throw a bunch of raw data (even after a little preliminary processing) - and everything will work as it should. In the real world, you need to take care of things like performance, real-time execution, and so on. Because of such misconceptions, you will get stuck in experiment mode for a very long time ...
Feature Engineering remains a very important discipline in the design of artificial neural networks. As in any other ML technique, in most cases it is it that distinguishes effective solutions of the production level from unsuccessful or ineffective experiments. A deep understanding of your data and its nature still means a lot ...
From A to Z
Ok, I finished the sermon. Now let's see why we are here! As with any data processing problem, let's first see what it looks like. Take a look at the next piece of vocals from the original studio recording.
Studio vocals 'One Last Time', Ariana Grande
Not too interesting, right? Well, this is because we visualize the signal in time . Here we see only amplitude changes over time. But you can extract all sorts of other things, such as amplitude envelopes (envelope), root mean square values (RMS), the rate of change from positive values of amplitude to negative (zero-crossing rate), etc., but these signs are too primitive and not sufficiently distinctive, to help in our problem. If we want to extract vocals from an audio signal, first we need to somehow determine the structure of human speech. Fortunately, the Window Fourier Transform (STFT) comes to the rescue .
STFT amplitude spectrum - window size = 2048, overlap = 75%, logarithmic frequency scale [Sonic Visualizer]
Although I like speech processing and definitely like playing with input filter simulations, cepstrum, sottottami, LPC, MFCC and so on, we ’ll skip all this bullshit and focus on the main elements related to our problem so that the article is understood by as many people as possible, and not just signal processing specialists.
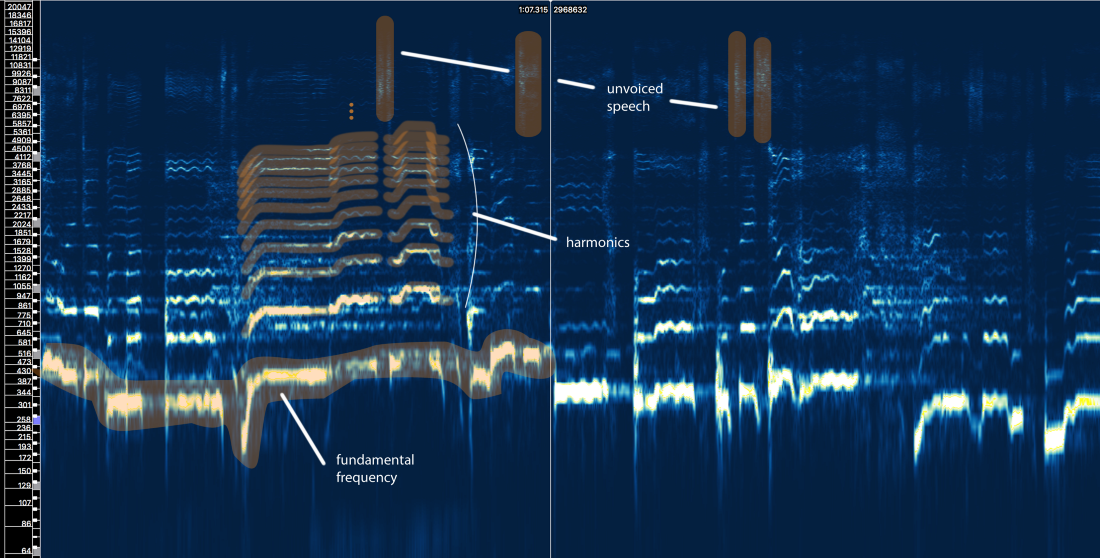
So what does the structure of human speech tell us?
Well, we can define three main elements here:
- The fundamental frequency (f0), which is determined by the vibration frequency of our vocal cords. In this case, Ariana sings in the range of 300-500 Hz.
- A series of harmonics above f0 that follow a similar shape or pattern. These harmonics appear at frequencies that are multiples of f0.
- Unvoiced speech, which includes consonants such as 't', 'p', 'k', 's' (which are not produced by vibration of the vocal cords), breathing, etc. All this manifests itself in the form of short bursts in the high-frequency region.
First Attempt with Rules
Let's forget for a second what is called machine learning. Can a vocal extraction method be developed based on our knowledge of the signal? Let me try ...
Naive V1.0 vocals isolation:
- Identify areas with vocals. There are a lot of things in the original signal. We want to focus on those areas that really contain vocal content, and ignore everything else.
- Distinguish between voiced and unvoiced speech. As we have seen, they are very different. They probably need to be handled differently.
- Assess the change in fundamental frequency over time.
- Based on pin 3, apply some kind of mask to capture harmonics.
- Do something with fragments of unvoiced speech ...
If we work worthily, the result should be a soft or bit mask , the application of which to the amplitude of the STFT (elementwise multiplication) gives an approximate reconstruction of the amplitude of the STFT vocals. Then we combine this vocal STFT with the phase information of the original signal, calculate the inverse STFT, and get the time signal of the reconstructed vocal.
Doing it from scratch is already a big job. But for the sake of demonstration, the implementation of the pYIN algorithm is applicable . Although it is intended to solve step 3, but with the correct settings, it performs decently steps 1 and 2, tracking the vocal basis even in the presence of music. The example below contains the output after processing this algorithm, without processing unvoiced speech.
So what...? He seems to have done all the work, but there is no good quality and close. Perhaps by spending more time, energy and money, we will improve this method ...
But let me ask you ...
What happens if a few voices appear on the track , and this is often found in at least 50% of modern professional tracks?
What happens if the vocals are processed by reverb, delays and other effects? Let's take a look at the last chorus of Ariana Grande from this song.
Do you already feel pain ...? I am yes.
Such methods on strict rules very quickly turn into a house of cards. The problem is too complicated. Too many rules, too many exceptions, and too many different conditions (effects and mix settings). A multi-step approach also implies that errors in one step extend problems to the next step. Improving each step will become very expensive: it will take a large number of iterations to get it right. And last, but not least, it is likely that in the end we will get a very resource-intensive conveyor, which in itself can negate all efforts.
In such a situation, it's time to start thinking about a more comprehensiveapproach and allow ML to find out part of the basic processes and operations necessary to solve the problem. But we still have to show our skills and do feature engineering, and you will see why.
Hypothesis: use the neural network as a transfer function that translates mixes into vocals
Looking at the achievements of convolutional neural networks in photo processing, why not apply the same approach here?
Neural networks successfully solve such problems as colorization of images, sharpening and resolution.
In the end, you can imagine an audio signal “as an image” using a short-term Fourier transform, right? Although these sound images do not correspond to the statistical distribution of natural images, they still have spatial patterns (in time and frequency space) on which to train the network.
Left: drum beat and baseline below, several synthesizer sounds in the middle, all mixed with vocals. Right: only vocals
Conducting such an experiment would be an expensive undertaking since it is difficult to obtain or generate the necessary training data. But in applied research, I always try to use this approach: first, to identify a simpler problem that confirms the same principles , but does not require a lot of work. This allows you to evaluate the hypothesis, iterate faster and correct the model with minimal losses if it does not work as it should.
The implied condition is that the neural network must understand the structure of human speech . A simpler problem may be this: can a neural network determine the presence of speech on an arbitrary fragment of a sound recording . We are talking about a reliable voice activity detector (VAD)implemented as a binary classifier.
We design the space of signs
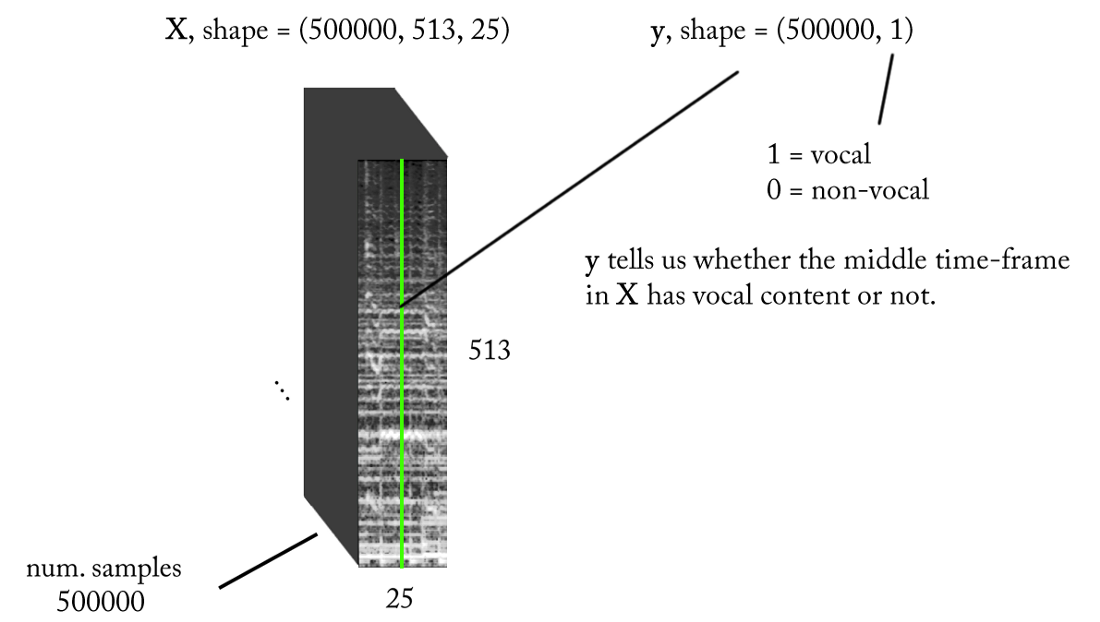
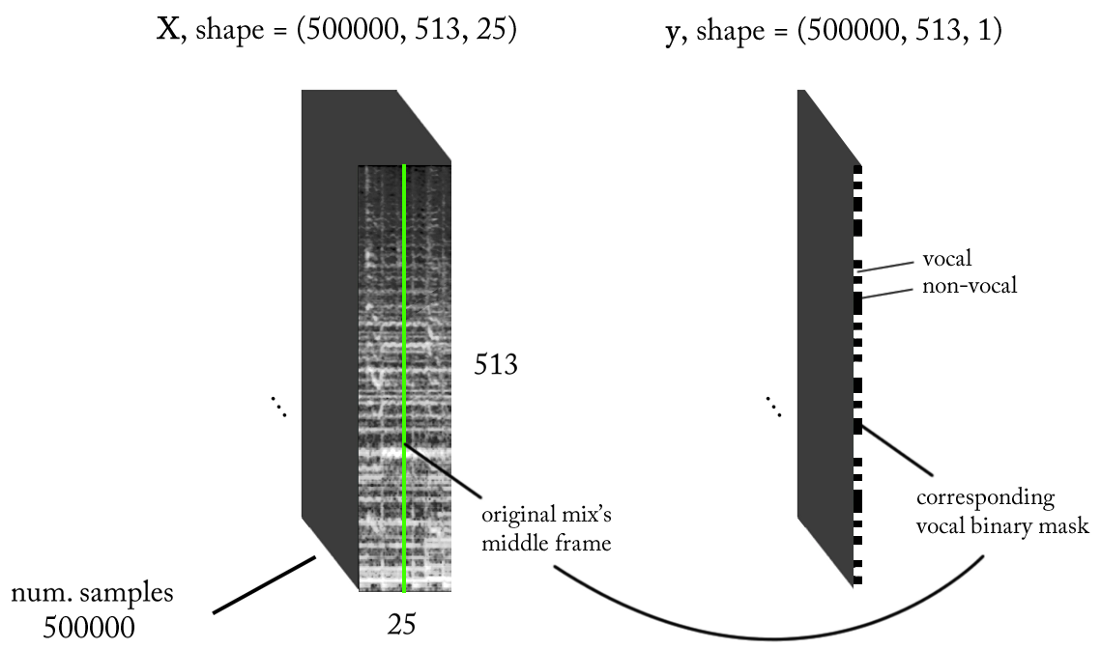
We know that sound signals, such as music and human speech, are based on time dependencies. Simply put, nothing happens in isolation at a given point in time. If I want to know if there is a voice on a particular piece of sound recording, then I need to look at neighboring regions. Such a time context provides good information about what is happening in the area of interest. At the same time, it is desirable to perform a classification with very small time increments in order to recognize a human voice with the highest possible time resolution.
Let's count a little ...
- Sampling frequency (fs): 22050 Hz (we downsample from 44100 to 22050)
- STFT design: window size = 1024, hop size = 256, chalk-line interpolation for the weighting filter, taking into account perception. Since our input is real , you can work with half the STFT (an explanation is beyond the scope of this article ...) while maintaining the DC component (optional), which gives us 513 frequency bins.
- Target classification resolution: one STFT frame (~ 11.6 ms = 256/22050)
- Target time context: ~ 300 milliseconds = 25 STFT frames.
- The target number of training examples: 500 thousand.
- Assuming we use a sliding window with a step of 1 STFT time frame to generate training data, we need about 1.6 hours of labeled sound to generate 500 thousand data samples
With the above requirements, the input and output of our binary classifier are as follows:
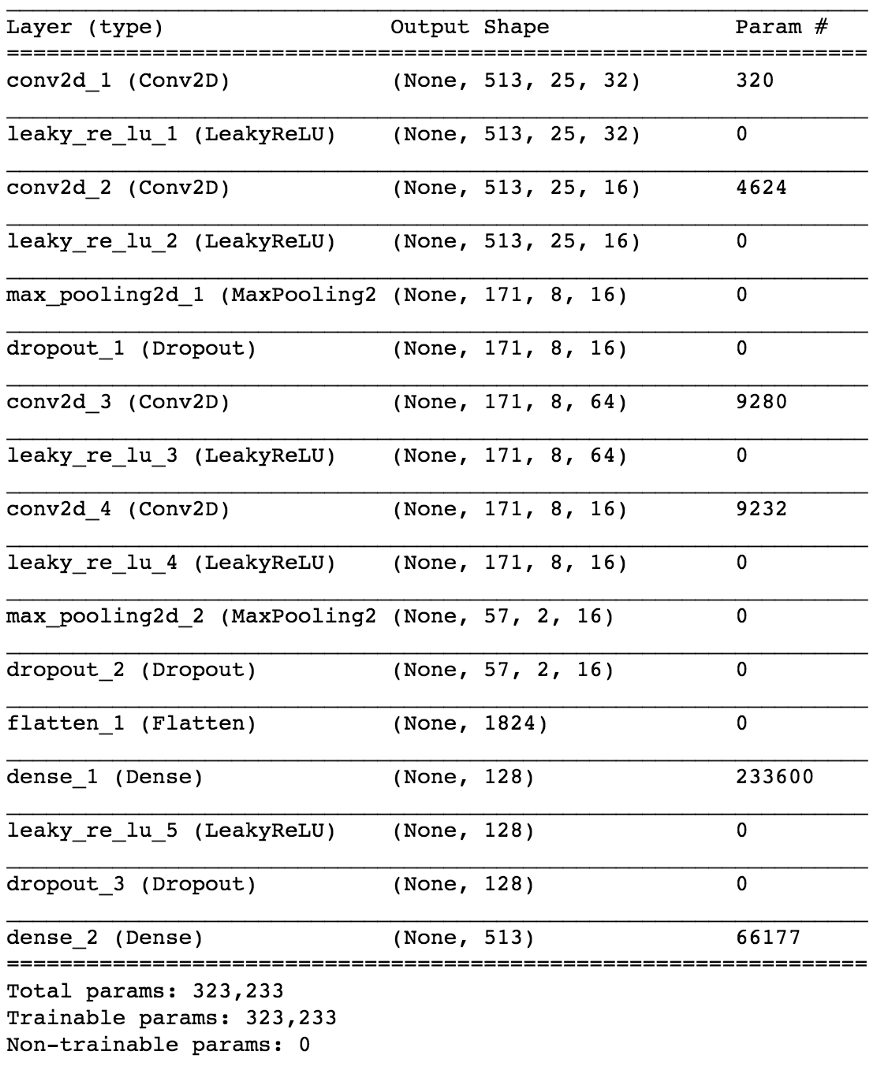
Model
Using Keras, we will build a small model of a neural network to test our hypothesis.
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.optimizers import SGD
from keras.layers.advanced_activations import LeakyReLU
model = Sequential()
model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1)))
model.add(LeakyReLU())
model.add(Conv2D(16, (3,3), padding='same'))
model.add(LeakyReLU())
model.add(MaxPooling2D(pool_size=(3,3)))
model.add(Dropout(0.25))
model.add(Conv2D(16, (3,3), padding='same'))
model.add(LeakyReLU())
model.add(Conv2D(16, (3,3), padding='same'))
model.add(LeakyReLU())
model.add(MaxPooling2D(pool_size=(3,3)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(64))
model.add(LeakyReLU())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])By dividing the 80/20 data into training and testing after ~ 50 eras, we get the accuracy when testing ~ 97% . This is sufficient evidence that our model is able to distinguish between vocals in musical sound fragments (and fragments without vocals). If we check some feature maps from the 4th convolutional layer, we can conclude that the neural network seems to have optimized its kernels to perform two tasks: filtering music and filtering vocals ...
An example of an object map at the output of the 4th convolutional layer. Apparently, the output on the left is the result of kernel operations in an attempt to preserve vocal content while ignoring music. High values resemble the harmonious structure of human speech. The object map on the right seems to be the result of the opposite task.
From voice detector to signal disconnect
Having solved the simpler classification problem, how can we move on to the real separation of vocals from music? Well, looking at the first naive method, we still want to somehow get the amplitude spectrogram for vocals. Now this is becoming a regression task. What we want to do is to calculate the corresponding amplitude spectrum for the vocals in this time frame from the STFT of the original signal, that is, from the mix (with a sufficient time context).
What about training dataset? (you can ask me at this moment)
Damn ... why so. I was going to consider this at the end of the article so as not to be distracted from the topic!
If our model is well-trained, then for a logical conclusion you just need to implement a simple sliding window to the STFT mix. After each forecast, move the window to the right by 1 timeframe, predict the next frame with vocals and associate it with the previous prediction. As for the model, we take the same model that was used for the voice detector and make small changes: the output signal form is now (513.1), linear activation at the output, MSE as a function of losses. Now we begin training.
So far, don’t rejoice ...
Although such an input / output representation makes sense, after training our model several times, with various parameters and data normalizations, there are no results. It seems we are asking too much ...
We have moved from a binary classifier to regressionon a 513-dimensional vector. Although the network is studying the problem to some extent, there are still obvious artifacts and interference from other sources in the restored vocals. Even after adding additional layers and increasing the number of model parameters, the results do not change much. And then the question arises: how to “simplify” the task for the network by deception, and at the same time achieve the desired results?
What if, instead of estimating the amplitude of the STFT vocals, we train the network to obtain a binary mask, which when applied to the STFT mix gives us a simplified, but perceptually acceptable amplitude spectrogram of the vocals?
Experimenting with various heuristics, we came up with a very simple (and, of course, unorthodox in terms of signal processing ...) way to extract vocals from mixes using binary masks. Without going into details, the essence is as follows. Imagine the output as a binary image, where the value '1' indicates the prevailing presence of vocal content at a given frequency and timeframe, and the value '0' indicates the prevailing presence of music in a given place. We can call it the binarization of perception , just to come up with a name. Visually, it looks pretty ugly, to be honest, but the results are surprisingly good.
Now our problem is becoming a kind of hybrid regression-classification (very roughly ...). We ask the model to “classify pixels” at the output as vocal or non-vocal, although conceptually (as well as from the point of view of the used MSE loss function) the task remains regressive.
Although this distinction may seem inappropriate for some, in fact it is of great importance in the ability of the model to study the task, the second of which is simpler and more limited. At the same time, this allows us to keep our model relatively small in terms of the number of parameters, given the complexity of the task, something very desirable for real-time work, which in this case was a design requirement. After some minor tweaks, the final model looks like this.
How to recover a time-domain signal?
In fact, as in the naive method . In this case, for each passage, we predict one timeframe of the binary vocals mask. Again, realizing a simple sliding window with a step of one timeframe, we continue to evaluate and combine successive timeframes, which ultimately make up the entire vocal binary mask.
Create a training set
As you know, one of the main problems when teaching with a teacher (leave these toy examples with ready-made datasets) is the correct data (in quantity and quality) for the specific problem you are trying to solve. Based on the described representations of input and output, for training our model, you will first need a significant number of mixes and their corresponding, perfectly aligned and normalized vocal tracks. This set can be created in several ways, and we used a combination of strategies, from manually creating pairs [mix <-> vocals] based on several a cappella found on the Internet, to searching for rock band music material and Youtube scrapbooking. Just to give you an idea of how laborious and painful the process is,
A really large amount of data is needed for the neural network to learn the transfer function for broadcasting mixes to vocals. Our final set consisted of approximately 15 million samples of 300 ms mixes and their corresponding vocal binary masks.
Pipeline architecture
As you probably know, creating an ML model for a specific task is only half the battle. In the real world, you need to think over the software architecture, especially if you need work in real time or close to it.
In this particular implementation, reconstruction in the time domain can occur immediately after predicting the complete binary vocals mask (stand-alone mode) or, more interestingly, in multi-threaded mode, where we receive and process data, restore vocals and reproduce sound - all in small segments, close to streaming and even almost in real time, processing music that is recorded on the fly with minimal delay. Actually, this is a separate topic, and I will leave it for another article on real-time ML pipelines ...
I guess I said enough, so why not listen to a couple of examples !?
Daft Punk - Get Lucky (studio recording)
Here you can hear some minimal interference from the drums ...
Adele - Set Fire to the Rain (live recording!)
Notice how at the very beginning our model extracts the screams of the crowd as vocal content :). In this case, there is some interference from other sources. Since this is a live recording, it seems acceptable that the extracted vocals are worse quality than the previous ones.
Yes, and "something else" ...
If the system works for vocals, why not apply it to other instruments ...?
The article is already quite large, but given the work done, you deserve to hear the latest demo. With exactly the same logic as when extracting vocals, we can try to divide the stereo music into components (drums, basses, vocals, others), making some changes in our model and, of course, having the appropriate training set :).
Thank you for reading. As a final note: as you can see, the actual model of our convolutional neural network is not so special. The success of this work was determined by Feature Engineering and the neat hypothesis testing process, which I will write about in future articles!