TDE in Apache Ignite: A Major Feature Story in a Large Open Source Project
Many organizations, especially financial ones, have to deal with various security standards - for example, PCI DSS. Such certifications require data encryption. Transparent data encryption on disk Transparent Data Encryption is implemented in many industrial DBMSs.
Apache Ignite is used in banks, therefore, it was decided to implement TDE in it.
I will describe how we developed TDE through the community, publicly, through Apachev processes.
Below, the text version of the report:
I will try to talk about architecture, about the complexity of development, how it really looks in open source.
Currently implemented Apache Ignite TDE. Phase 1.
It includes the basic features of working with encrypted caches:
In Phase 2, it is planned to enable the possibility of rotation (change) of the master key.
In Phase 3, the ability to rotate cache keys.
Everything is implemented according to the following scheme:
Banks and other organizations use their own encryption algorithms: GOST and others. It is clear that we have provided the opportunity to slip our Encryption SPI - the encryption implementation that a specific user needs.
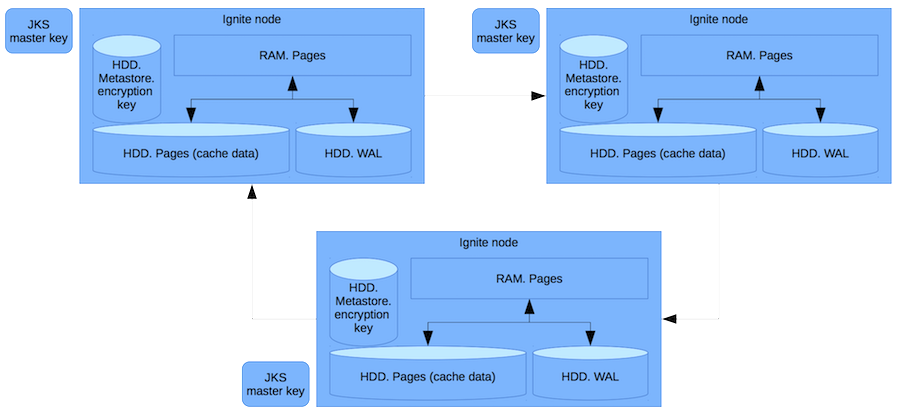
So, we have RAM - random access memory with pages containing pure data. Using RAM implies that we are not protected from a hacker who got root access and dumped all the memory. We protect ourselves from the administrator who takes the hard drive and sells it on the Tushino market (or where similar data is currently being sold).
In addition to the pages with the cache, the data is also stored in a write ahead log, which writes to the disk the delta of the records changed in the transaction. The metastore stores cache encryption keys. And in a separate file - a master key.
Each time a key for the cache is created, before writing to or transferring to the network, we encrypt this key using a master key. So that no one can get the cache key after receiving Ignite data. Only by stealing both the master key and data can you access them. This is unlikely, as access to these files requires various rights.
The algorithm of actions is as follows:
Now in more detail:
At the start of the node, we have a callback that starts our EncryptionSPI. According to the parameters, we subtract the master key from the jks file.
Next, when metastore is ready, we get the stored encryption keys. In this case, we already have a master key, so that we can decrypt the keys and gain access to the cache data.
Separately, there is a very interesting process - how do we join a new node into a cluster. We already have a distributed system consisting of several nodes. How to make sure that the new node is configured correctly, that it is not an attacker?
We perform these actions:
The second part is a superstructure over I / O operations. Pages are written to the partition file. Our add-in looks at which page cache, encrypts them accordingly and saves them.
The same goes for WAL. There is a serializer that serializes WAL record objects. And if the record is for encrypted caches, then we must encrypt it and only then save it to disk.
Difficulties common to all more or less complex open source projects:
Phase 1 is now implemented. You, as a developer, can help with Phase 2. The challenges ahead are interesting. PCI DSS, like other standards, requires additional features of the encryption system. Our system should be able to change the master key. For example, if he was compromised or the time has just come in accordance with the security policy. Now Ignite does not know how. But in future releases, we will teach TDE to change the master key.
The same thing with the ability to change the cache key without stopping the cluster and working with data. If the cache is long-lived and at the same time stores some data - financial, medical - Ignite should be able to change the cache encryption key and re-encrypt everything on the fly. We will solve this problem in the third phase.
To summarize. They will be relevant for any open source. I participated in Kafka and in other projects - everywhere the story is the same.
Further more obvious tips which are not so easy to follow:
Thanks for reading!
Apache Ignite is used in banks, therefore, it was decided to implement TDE in it.
I will describe how we developed TDE through the community, publicly, through Apachev processes.
Below, the text version of the report:
I will try to talk about architecture, about the complexity of development, how it really looks in open source.
What has been done and what remains to be done?
Currently implemented Apache Ignite TDE. Phase 1.
It includes the basic features of working with encrypted caches:
- Key management
- Creating Encrypted Caches
- Saving all cache data to disk in encrypted form
In Phase 2, it is planned to enable the possibility of rotation (change) of the master key.
In Phase 3, the ability to rotate cache keys.
Terminology
- Transparent Data Encryption - transparent (for the user) data encryption when saving to disk. In the case of Ignite, cache encryption, because Ignite is about caches.
- Ignite cache - key-value cache in Apache Ignite. Cache data can be saved to disk
- Pages - data pages. In Ignite, all data is paginated. Pages are written to disk and must be encrypted.
- WAL - write ahead log. All data changes in Ignite are saved there, all the actions that we performed for all caches.
- Keystore - standard java keystore, which is generated by keytool Javascript. It works and is certified everywhere, we used it.
- Master key - master key. Using it, keys for tables are encrypted, cache encryption keys. Stored in java keystore.
- Cache keys - keys with which data is actually encrypted. Together with the master key, a two-level structure is obtained. The master key is stored separately from the key cache and master data - for security purposes, separation of access rights, etc.
Architecture
Everything is implemented according to the following scheme:
- All cache data is encrypted using the new Encryption SPI.
- By default, AES is used - an industrial encryption algorithm.
- The master key is stored in a JKS file - a standard java file for keys.
Banks and other organizations use their own encryption algorithms: GOST and others. It is clear that we have provided the opportunity to slip our Encryption SPI - the encryption implementation that a specific user needs.
Scheme of work
So, we have RAM - random access memory with pages containing pure data. Using RAM implies that we are not protected from a hacker who got root access and dumped all the memory. We protect ourselves from the administrator who takes the hard drive and sells it on the Tushino market (or where similar data is currently being sold).
In addition to the pages with the cache, the data is also stored in a write ahead log, which writes to the disk the delta of the records changed in the transaction. The metastore stores cache encryption keys. And in a separate file - a master key.
Each time a key for the cache is created, before writing to or transferring to the network, we encrypt this key using a master key. So that no one can get the cache key after receiving Ignite data. Only by stealing both the master key and data can you access them. This is unlikely, as access to these files requires various rights.
The algorithm of actions is as follows:
- At the start of the node, subtract the master key from jks.
- At the start of the nodes, read the meta store and decrypt cache keys.
- When you join nodes into a cluster:
- check the hashes of the master key.
- check keys for shared caches.
- save keys for new caches. - When creating a cache dynamically, we generate a key and save it in the meta store.
- When reading / writing a page, we decrypt / encrypt it.
- Each WAL entry for the encrypted cache is also encrypted.
Now in more detail:
At the start of the node, we have a callback that starts our EncryptionSPI. According to the parameters, we subtract the master key from the jks file.
Next, when metastore is ready, we get the stored encryption keys. In this case, we already have a master key, so that we can decrypt the keys and gain access to the cache data.
Separately, there is a very interesting process - how do we join a new node into a cluster. We already have a distributed system consisting of several nodes. How to make sure that the new node is configured correctly, that it is not an attacker?
We perform these actions:
- When a new node arrives, it sends a hash from the master key. We look that it matches the existing one.
- Then we verify the keys for shared caches. From the node comes the cache identifier and the encrypted cache key. We check them to make sure that all the data on all nodes is encrypted with the same key. If this is not so, then we simply do not have the right to let the node into the cluster; otherwise, it will travel by keys and data.
- If there are any new keys and caches on the new node, save them for future use.
- When creating a cache dynamically, a key generation function is provided. We generate it, save it in the meta store and can continue to carry out the described operations.
The second part is a superstructure over I / O operations. Pages are written to the partition file. Our add-in looks at which page cache, encrypts them accordingly and saves them.
The same goes for WAL. There is a serializer that serializes WAL record objects. And if the record is for encrypted caches, then we must encrypt it and only then save it to disk.
Development difficulties
Difficulties common to all more or less complex open source projects:
- First you need to understand the Ignite device altogether. Why, what, and how it was done there, how and in what places to attach your handlers.
- It is necessary to provide backward compatibility. This can be quite difficult, not obvious. When developing a product that others use, you need to consider that users want to be updated without problems. Backward compatibility is right and good. When you make such a big improvement as TDE, you change the rules for saving to disk, you encrypt something. And backward compatibility has to be worked on.
- Another non-obvious point is related to the distribution of our system. When different clients try to create the same cache, you need to agree on the encryption key, because by default two different ones will be generated. We have solved this problem. I will not dwell in more detail - the solution deserves a separate post. Now we are guaranteed to use one key.
- The next important thing led to great improvements, when it seemed that everything was ready (a familiar story?) :). Encryption has overhead. We have an init vector - zero random data that is used in the AES algorithm. They are stored in open form, and with their help we increase entropy: the same data will be encrypted differently in different encryption sessions. Roughly speaking, even if we have two Ivan Petrovs with the same surname, each time we encrypt, we will receive different encrypted data. This reduces the chance of hacking.
Encryption takes place in blocks of 16 bytes, and if the data is not aligned by 16 bytes, then we add padding info - how much data we actually have encrypted. On a disk you need to write a page that is a multiple of 2 Kb. These are the performance requirements: we must use the disk buffer. If we write not 2 Kb (not 4 or not 8, depending on the disk buffer), then we immediately get a big drop performance.
How did we solve the problem? I had to crawl into PageIO, in RAM and cut off 16 bytes from each page, which would be encrypted when written to disk. In these 16 bytes we write init vector. - Another difficulty is not to break anything. This is a common thing when you come and make some changes. In reality, it is not as simple as it seems.
- In MVP it turned out 6 thousand lines. It’s difficult to review, and few people want to do this - especially from experts who already do not have time. We have various parts - public API, core part, SPI managers, persistent store for pages, WAL managers. Changes in various subsystems require that they be reviewed by different people. And this also imposes additional difficulties. Especially when you work in a community where all people are busy with their tasks. Nevertheless, everything worked out for us.
What will happen in TDE.Phase 2 and 3
Phase 1 is now implemented. You, as a developer, can help with Phase 2. The challenges ahead are interesting. PCI DSS, like other standards, requires additional features of the encryption system. Our system should be able to change the master key. For example, if he was compromised or the time has just come in accordance with the security policy. Now Ignite does not know how. But in future releases, we will teach TDE to change the master key.
The same thing with the ability to change the cache key without stopping the cluster and working with data. If the cache is long-lived and at the same time stores some data - financial, medical - Ignite should be able to change the cache encryption key and re-encrypt everything on the fly. We will solve this problem in the third phase.
Total: How to implement a big feature in an open source project?
To summarize. They will be relevant for any open source. I participated in Kafka and in other projects - everywhere the story is the same.
- Start with small tasks. Never try to solve a super-big problem right away. It is necessary to understand what is happening, how it is happening, how it is being realized. Who will help you. And in general - from which side to approach this project.
- Understand the project. Usually, all developers - at least me - come and say: everything needs to be rewritten. Everything was bad before me, and now I will rewrite it - and everything will be fine. It is advisable to postpone such statements, to figure out what exactly is bad and whether it needs to be changed.
- Discuss whether improvements are needed. I have had cases when I came to the various communities with experience, for example, in Spark. He told me, but the community was not interested for some reason. In any case it happens. You need this revision, but the community says: no, we are not interested, we will not merge and help.
- Make a design. There are open source projects in which this is mandatory. You cannot start coding without a design agreed upon by the committee and experienced people. In Ignite, this is not formally true, but in general it is an important part of development. It is necessary to make a description in competent English or Russian, depending on the project. So that the text can be read and it was clear on it what exactly you are going to do.
- Discuss the public API. The main argument: if there is a beautiful and understandable public API that is easy to use, then the design is correct. These things are usually adjacent to each other.
Further more obvious tips which are not so easy to follow:
- Implement the feature without breaking anything. Do the tests.
- Ask and wait (this is most difficult) for a review from the right guys, from the right members of the community.
- Make benchmarks, find out if you have a performance drop. This is especially important when finalizing some critical subsystems.
- Wait for merge, do some examples and documentation.
Thanks for reading!