The day Dodo IS stopped. Synchronous script
Dodo IS is a global system that helps you effectively manage your business at Dodo Pizza. It closes pizza ordering issues, helps the franchisee keep track of the business, improves employee efficiency, and sometimes falls. The last is the worst for us. Every minute of such falls leads to loss of profits, user dissatisfaction and sleepless nights of developers.
But now we sleep better. We learned to recognize systemic apocalypse scenarios and process them. Below I will tell you how we ensure system stability.

The system is a great competitive advantage of our franchise, because franchisees get a ready-made business model. These are ERP, HRM and CRM, all in one.
The system appeared a couple of months after the opening of the first pizzeria. It is used by managers, customers, cashiers, cooks, mystery shoppers, call center employees - that’s all. Conventionally, Dodo IS is divided into two parts. The first is for customers. This includes a website, a mobile application, a contact center. The second for franchisee partners, it helps manage pizzerias. Through the system, invoices from suppliers, personnel management, people taking shifts, automatic payroll accounting, online training for personnel, certification of managers, a quality control system and mystery buyers pass through the system.
System Performance Dodo IS = Reliability = Fault Tolerance / Recovery. Let us dwell on each of the points.
We do not have large mathematical calculations: we need to service a certain number of orders, there are certain delivery zones. The number of customers does not particularly vary. Of course, we will be happy when it grows, but this rarely happens in large bursts. For us, performance boils down to how few failures occur, to the reliability of the system.
One component may be dependent on another component. If an error occurs in one system, the other subsystem must not fall.
Failures of individual components occur every day. This is normal. It is important how quickly we can recover from a failure.
The instinct of a big business is to serve many customers at the same time. Just as it is impossible to work in the kitchen of a pizzeria working for delivery in the same way as a hostess in a kitchen at home, a code developed for synchronous execution cannot successfully work for mass customer service on a server.
There is a fundamental difference between executing an algorithm in a single instance, and executing the same algorithm as a server in the framework of mass service.
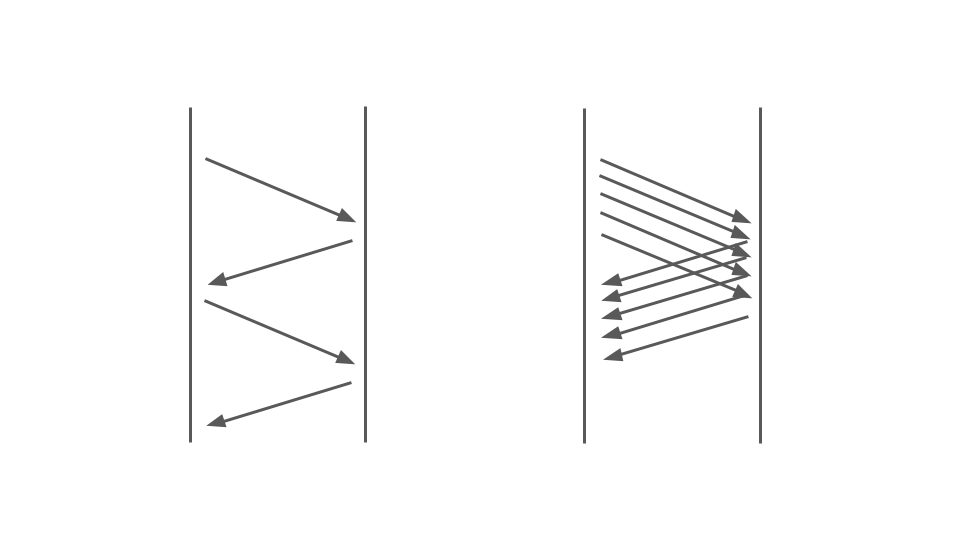
Take a look at the picture below. On the left, we see how requests occur between two services. These are RPC calls. The next request ends after the previous one. Obviously, this approach does not scale - additional orders are lined up.
To serve many orders we need the right option:
The operation of the blocking code in a synchronous application is greatly affected by the multithreading model used, namely preemptive multitasking. It itself can lead to failures.
Simplified, preemptive multitasking could be illustrated as follows:

Color blocks are the real work that the CPU does, and we see that the useful work, indicated by green in the diagram, is quite small against the general background. We need to arouse the flow, put it to sleep, and this is overhead. Such sleep / waking occurs during synchronization on any synchronization primitives.
Obviously, the CPU performance will decrease if you dilute the useful work with a large number of synchronizations. How much can preemptive multitasking affect performance?
Consider the results of the synthetic test:
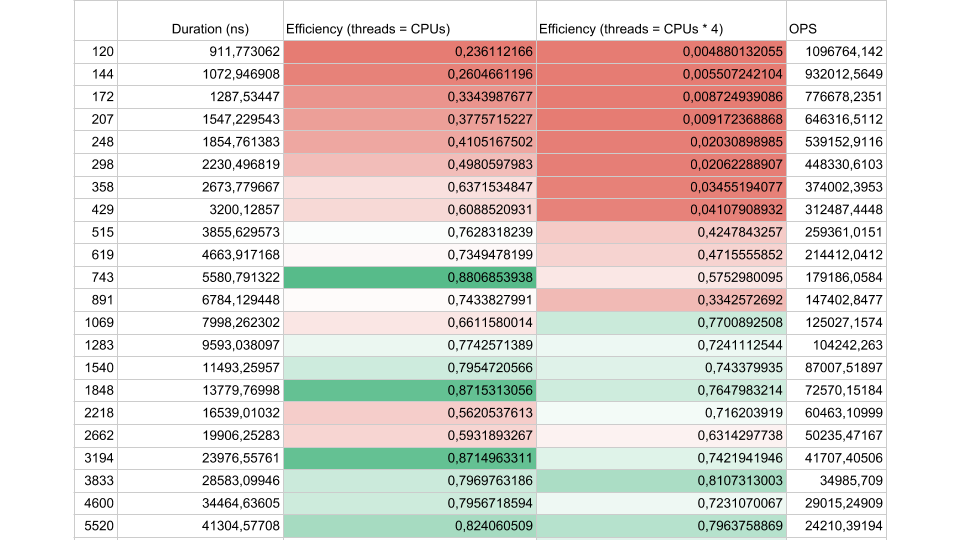
If the interval between the synchronization flows is about 1000 nanoseconds, the efficiency is quite small, even if the number of Threads is equal to the number of cores. In this case, the efficiency is about 25%. If the number of Threads is 4 times greater, the efficiency drops dramatically, to 0.5%.
Think about it, in the cloud you ordered a virtual machine with 72 cores. It costs money, and you use less than half of one core. This is exactly what can happen in a multi-threaded application.
If there are fewer tasks, but their duration is longer, efficiency increases. We see that at 5,000 operations per second, in both cases the efficiency is 80-90%. For a multiprocessor system, this is very good.
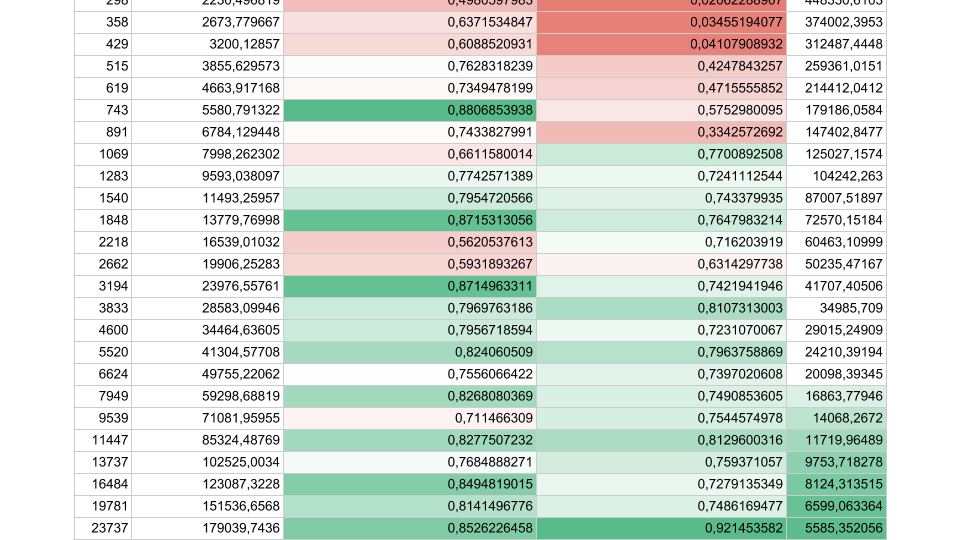
In our real applications, the duration of one operation between synchronizations lies somewhere in between, so the problem is urgent.
Pay attention to the result of stress testing. In this case, it was the so-called "extrusion test."
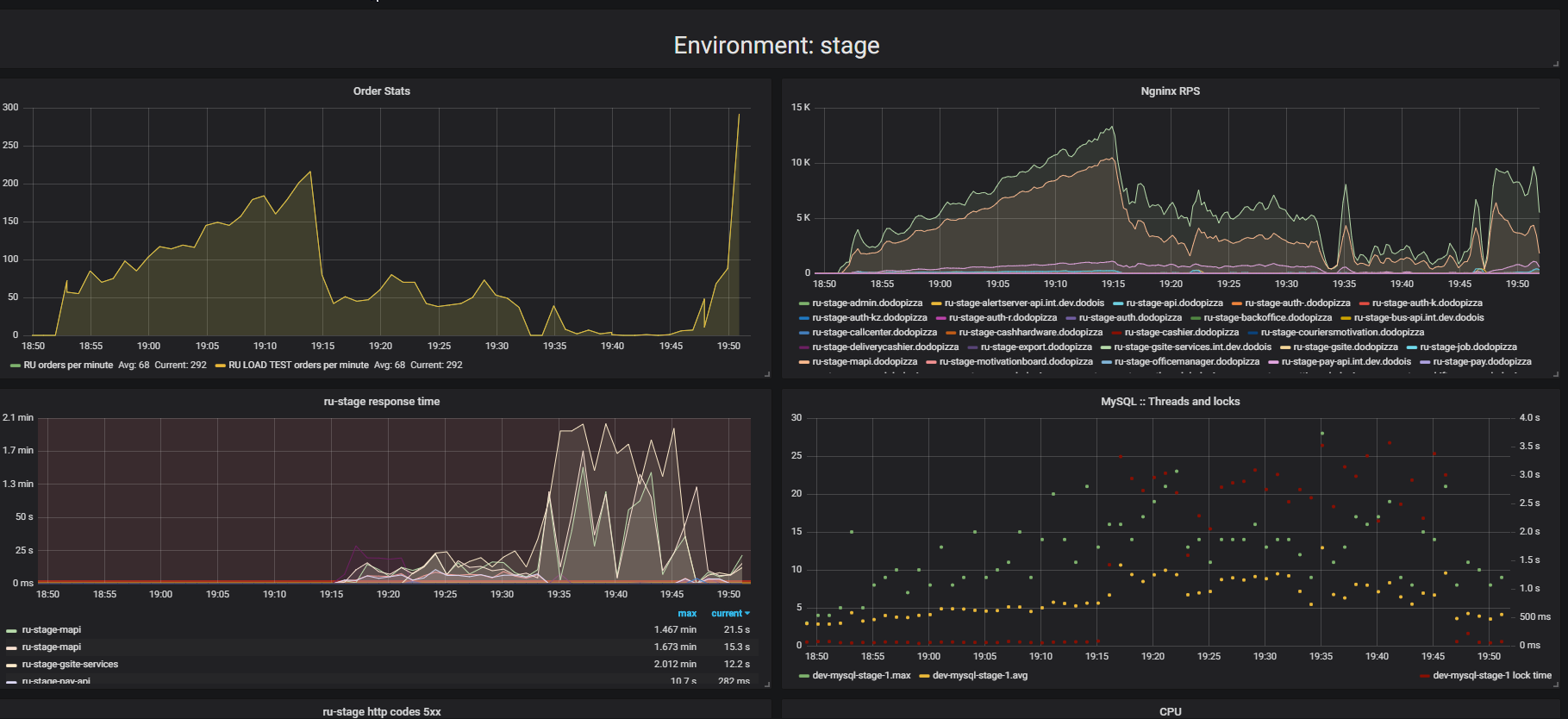
The essence of the test is that using a load stand, we submit more and more artificial requests to the system, try to place as many orders as possible per minute. We try to find the limit after which the application will refuse to serve requests beyond its capabilities. Intuitively, we expect the system to run to the limit, discarding additional requests. This is exactly what would happen in real life, for example - when serving in a restaurant that is crowded with customers. But something else happens. Customers made more orders, and the system began to serve less. The system began to serve so few orders that it can be considered a complete failure, breakdown. This happens with many applications, but should it be?
In the second graph, the time for processing a request grows, for this interval fewer requests are served. Requests that arrived earlier are served much later.
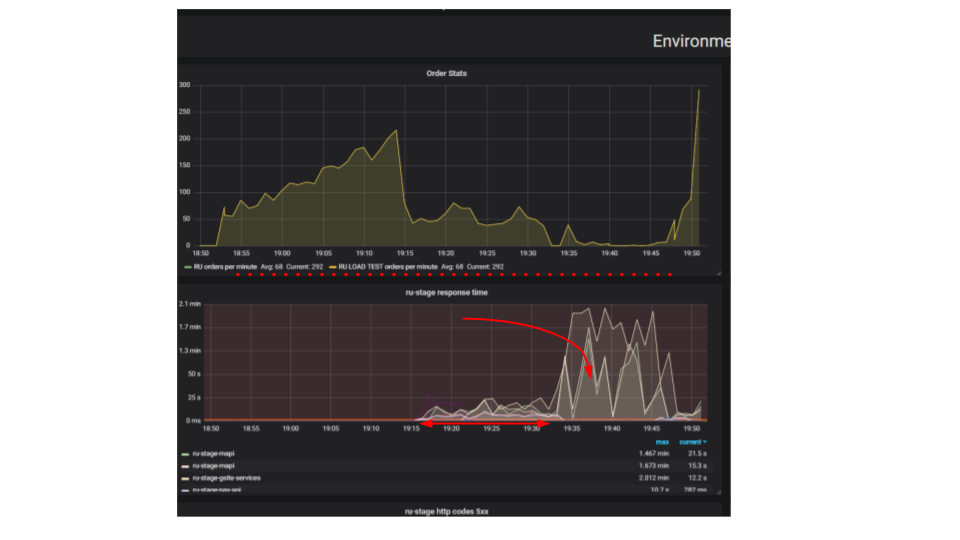
Why is the application stopping? There was an algorithm, it worked. We start it from our local machine, it works very quickly. We think that if we take a hundred times more powerful machine and run one hundred identical requests, then they should be executed in the same time. It turns out that requests from different clients collide. Contention arises between them and this is a fundamental problem in distributed applications. Separate requests fight for resources.
If the server does not work, the first thing we will try to find and fix the trivial problems of locks inside the application, in the database and with file I / O. There is still a whole class of problems in networking, but so far we will limit ourselves to these three, this is enough to learn how to recognize similar problems, and we are primarily interested in the problems that cause Contention - the struggle for resources.
Here is a typical request in a blocking application.
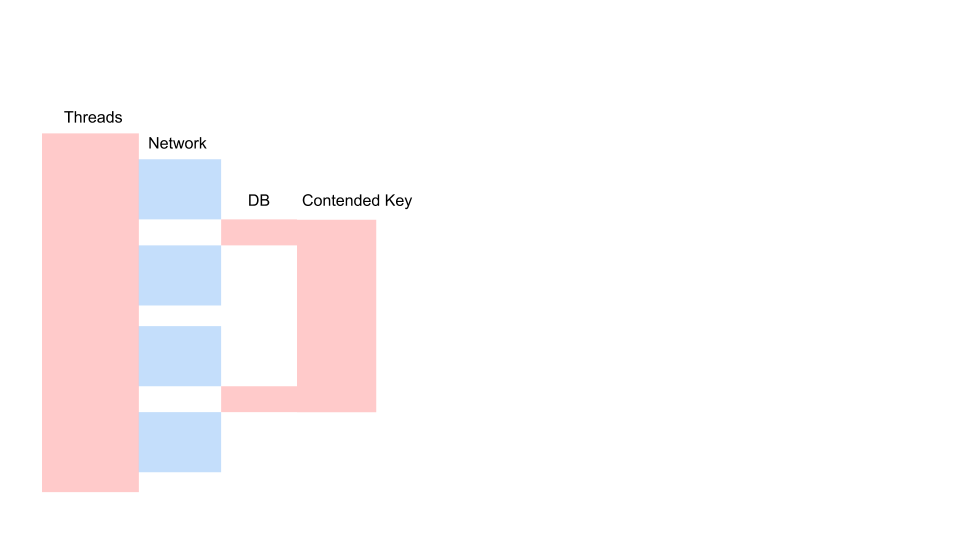
This is a variation of the Sequence Diagram, which describes the interaction algorithm between the application code and the database as a result of some conditional operation. We see that a network call is being made, then something happens in the database - the database is slightly used. Then another request is made. For the entire period, a transaction in the database and a key common to all requests are used. It can be two different customers or two different orders, but one and the same restaurant menu object, stored in the same database as customer orders. We work using a transaction for consistency; two queries have Contention on the key of the common object.
Let's see how it scales.
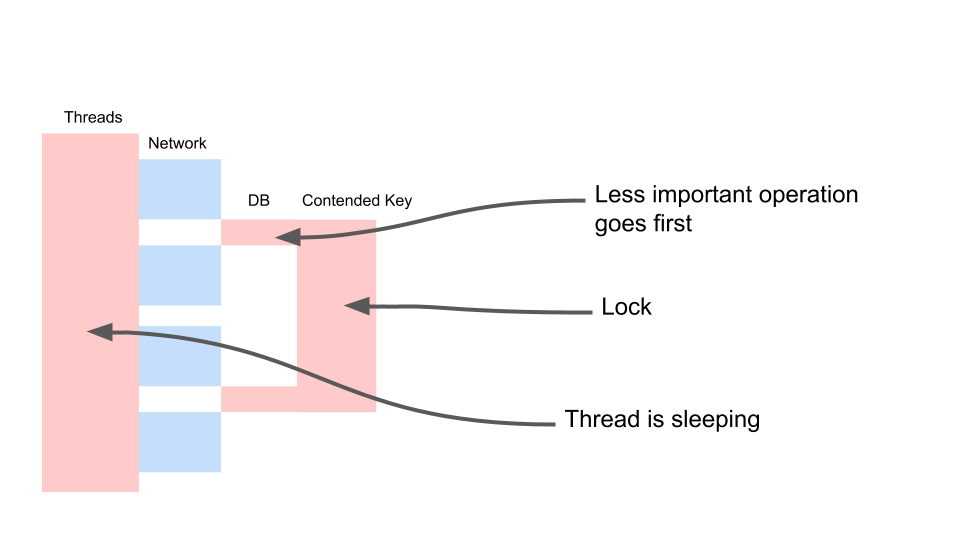
Thread sleeps most of the time. He, in fact, does nothing. We have a lock that interferes with other processes. The most annoying thing is that the least useful operation in the transaction that locked the key occurs at the very beginning. It lengthens scope transactions in time.
We will fight this like that.
This is Eventual Consistency. We assume that some of our data may be less recent. To do this, we need to work with the code differently. We must accept that the data is of a different quality. We will not look at what happened before - the manager changed something in the menu or the client clicked the “issue” button. For us, it makes no difference which of them pressed the button two seconds earlier. And for the business there is no difference.
There is no difference, we can do just such a thing. Conditionally call it optionalData. That is, some value that we can do without. We have a fallback - the value that we take from the cache or pass some default value. And for the most important operation (the required variable) we will do await. We will wait for him firmly, and only then we will wait for a response to requests for optional data. This will allow us to speed up the work. There is another significant point - this operation may not be performed at all for some reason. Suppose the code for this operation is not optimal, and at the moment there is a bug. If the operation could not be completed, do fallback. And then we work with this as with the usual value.
We get approximately the same layout when we rewrote on async and changed the consistency model.
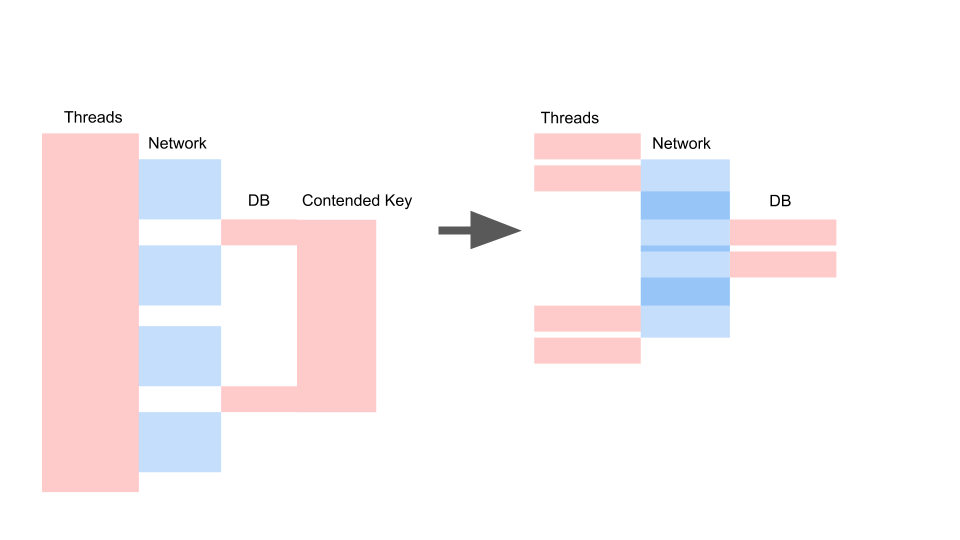
What matters here is not that the request has become faster in time. The important thing is that we do not have Contention. If we add requests, then only the left side of the picture is saturated with us.
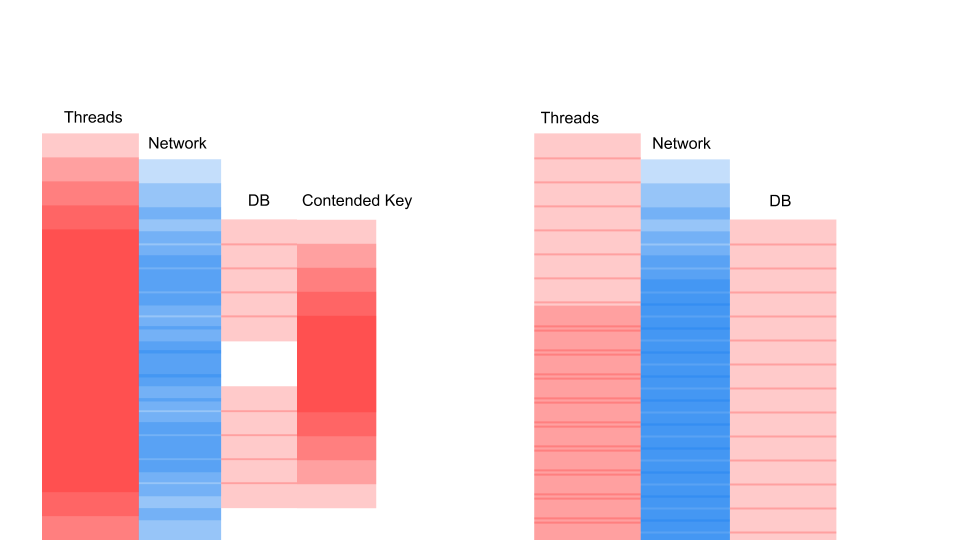
This is a blocking request. Here Threads overlap and the keys on which Contention occurs. On the right, we don’t have any transactions in the database at all and they are quietly executed. The right case can work in this mode indefinitely. Left will cause the server to crash.
Sometimes we need file logs. Surprisingly, the logging system can give such unpleasant failures. Latency on disk in Azure - 5 milliseconds. If we write a file in a row, it is only 200 requests per second. That's it, the application has stopped.

It’s just that your hair stands on end when you see this - more than 2000 Threads have bred in the application. 78% of all Threads are the same call stack. They stopped at the same place and are trying to enter the monitor. This monitor delimits access to the file where we all log. Of course, this must be cut.

Here's what you need to do in NLog to configure it. We make an asynchronous target and write to it. And asynchronous target writes to the real file. Of course, we can lose a certain amount of messages in the log, but what is more important for business? When the system fell for 10 minutes, we lost a million rubles. It is probably better to lose several messages in the service log, which went into failure and rebooted.
Contention is a big issue in multi-threaded applications that doesn’t allow you to simply scale a single-threaded application. Sources of Contention need to be able to identify and eliminate. A large number of Threads are disastrous for applications, and blocking calls must be rewritten to async.
I had to rewrite a lot of legacy from blocking calls to async, I myself often initiated such an upgrade. Quite often, someone comes up and asks: “Listen, we’ve been rewriting for two weeks now, almost all async. And how much will it work faster? ”Guys, I’ll upset you - it won’t work faster. It will become even slower. After all, TPL is one competitive model on top of another - cooperative multitasking over preemptive multitasking, and this is overhead. In one of our projects - approximately + 5% to CPU usage and load on GC.
There is one more bad news - the application can work much worse after just rewriting on async, without realizing the features of the competitive model. I will talk about these features in great detail in the next article.
This raises the question - is it necessary to rewrite?
The synchronous code is rewritten on async in order to unblock the Concurrency Model and get rid of the Preemptive Multitasking model. We saw that the number of Threads can adversely affect performance, so you need to free yourself from the need to increase the number of Threads to increase Concurrency. Even if we have Legacy and we don’t want to rewrite this code - this is the main reason to rewrite it.
The good news at the end is that we now know something about how to get rid of the trivial problems of Contention of blocking code. If you find such problems in your blocking application, then it's time to get rid of them before rewriting to async, because there they will not disappear on their own.
But now we sleep better. We learned to recognize systemic apocalypse scenarios and process them. Below I will tell you how we ensure system stability.
A series of articles about the collapse of the Dodo IS * system :
1. The day that Dodo IS stopped. Synchronous script.
2. The day Dodo IS stopped. Asynchronous script.
* Materials were written based on my performance at DotNext 2018 in Moscow .
Dodo is
The system is a great competitive advantage of our franchise, because franchisees get a ready-made business model. These are ERP, HRM and CRM, all in one.
The system appeared a couple of months after the opening of the first pizzeria. It is used by managers, customers, cashiers, cooks, mystery shoppers, call center employees - that’s all. Conventionally, Dodo IS is divided into two parts. The first is for customers. This includes a website, a mobile application, a contact center. The second for franchisee partners, it helps manage pizzerias. Through the system, invoices from suppliers, personnel management, people taking shifts, automatic payroll accounting, online training for personnel, certification of managers, a quality control system and mystery buyers pass through the system.
System performance
System Performance Dodo IS = Reliability = Fault Tolerance / Recovery. Let us dwell on each of the points.
Reliability
We do not have large mathematical calculations: we need to service a certain number of orders, there are certain delivery zones. The number of customers does not particularly vary. Of course, we will be happy when it grows, but this rarely happens in large bursts. For us, performance boils down to how few failures occur, to the reliability of the system.
Fault Tolerance
One component may be dependent on another component. If an error occurs in one system, the other subsystem must not fall.
Resilience
Failures of individual components occur every day. This is normal. It is important how quickly we can recover from a failure.
Synchronous System Failure Scenario
What is it?
The instinct of a big business is to serve many customers at the same time. Just as it is impossible to work in the kitchen of a pizzeria working for delivery in the same way as a hostess in a kitchen at home, a code developed for synchronous execution cannot successfully work for mass customer service on a server.
There is a fundamental difference between executing an algorithm in a single instance, and executing the same algorithm as a server in the framework of mass service.
Take a look at the picture below. On the left, we see how requests occur between two services. These are RPC calls. The next request ends after the previous one. Obviously, this approach does not scale - additional orders are lined up.
To serve many orders we need the right option:
The operation of the blocking code in a synchronous application is greatly affected by the multithreading model used, namely preemptive multitasking. It itself can lead to failures.
Simplified, preemptive multitasking could be illustrated as follows:
Color blocks are the real work that the CPU does, and we see that the useful work, indicated by green in the diagram, is quite small against the general background. We need to arouse the flow, put it to sleep, and this is overhead. Such sleep / waking occurs during synchronization on any synchronization primitives.
Obviously, the CPU performance will decrease if you dilute the useful work with a large number of synchronizations. How much can preemptive multitasking affect performance?
Consider the results of the synthetic test:
If the interval between the synchronization flows is about 1000 nanoseconds, the efficiency is quite small, even if the number of Threads is equal to the number of cores. In this case, the efficiency is about 25%. If the number of Threads is 4 times greater, the efficiency drops dramatically, to 0.5%.
Think about it, in the cloud you ordered a virtual machine with 72 cores. It costs money, and you use less than half of one core. This is exactly what can happen in a multi-threaded application.
If there are fewer tasks, but their duration is longer, efficiency increases. We see that at 5,000 operations per second, in both cases the efficiency is 80-90%. For a multiprocessor system, this is very good.
In our real applications, the duration of one operation between synchronizations lies somewhere in between, so the problem is urgent.
What is going on?
Pay attention to the result of stress testing. In this case, it was the so-called "extrusion test."
The essence of the test is that using a load stand, we submit more and more artificial requests to the system, try to place as many orders as possible per minute. We try to find the limit after which the application will refuse to serve requests beyond its capabilities. Intuitively, we expect the system to run to the limit, discarding additional requests. This is exactly what would happen in real life, for example - when serving in a restaurant that is crowded with customers. But something else happens. Customers made more orders, and the system began to serve less. The system began to serve so few orders that it can be considered a complete failure, breakdown. This happens with many applications, but should it be?
In the second graph, the time for processing a request grows, for this interval fewer requests are served. Requests that arrived earlier are served much later.
Why is the application stopping? There was an algorithm, it worked. We start it from our local machine, it works very quickly. We think that if we take a hundred times more powerful machine and run one hundred identical requests, then they should be executed in the same time. It turns out that requests from different clients collide. Contention arises between them and this is a fundamental problem in distributed applications. Separate requests fight for resources.
Ways to find a problem
If the server does not work, the first thing we will try to find and fix the trivial problems of locks inside the application, in the database and with file I / O. There is still a whole class of problems in networking, but so far we will limit ourselves to these three, this is enough to learn how to recognize similar problems, and we are primarily interested in the problems that cause Contention - the struggle for resources.
In-process locks
Here is a typical request in a blocking application.
This is a variation of the Sequence Diagram, which describes the interaction algorithm between the application code and the database as a result of some conditional operation. We see that a network call is being made, then something happens in the database - the database is slightly used. Then another request is made. For the entire period, a transaction in the database and a key common to all requests are used. It can be two different customers or two different orders, but one and the same restaurant menu object, stored in the same database as customer orders. We work using a transaction for consistency; two queries have Contention on the key of the common object.
Let's see how it scales.
Thread sleeps most of the time. He, in fact, does nothing. We have a lock that interferes with other processes. The most annoying thing is that the least useful operation in the transaction that locked the key occurs at the very beginning. It lengthens scope transactions in time.
We will fight this like that.
var fallback = FallbackPolicy
.Handle()
.FallbackAsync(OptionalData.Default);
var optionalDataTask = fallback
.ExecuteAsync(async () => await CalculateOptionalDataAsync());
//…
var required = await CalculateRequiredData();
var optional = await optionalDataTask;
var price = CalculatePriceAsync(optional, required); This is Eventual Consistency. We assume that some of our data may be less recent. To do this, we need to work with the code differently. We must accept that the data is of a different quality. We will not look at what happened before - the manager changed something in the menu or the client clicked the “issue” button. For us, it makes no difference which of them pressed the button two seconds earlier. And for the business there is no difference.
There is no difference, we can do just such a thing. Conditionally call it optionalData. That is, some value that we can do without. We have a fallback - the value that we take from the cache or pass some default value. And for the most important operation (the required variable) we will do await. We will wait for him firmly, and only then we will wait for a response to requests for optional data. This will allow us to speed up the work. There is another significant point - this operation may not be performed at all for some reason. Suppose the code for this operation is not optimal, and at the moment there is a bug. If the operation could not be completed, do fallback. And then we work with this as with the usual value.
DB Locks
We get approximately the same layout when we rewrote on async and changed the consistency model.
What matters here is not that the request has become faster in time. The important thing is that we do not have Contention. If we add requests, then only the left side of the picture is saturated with us.
This is a blocking request. Here Threads overlap and the keys on which Contention occurs. On the right, we don’t have any transactions in the database at all and they are quietly executed. The right case can work in this mode indefinitely. Left will cause the server to crash.
Sync io
Sometimes we need file logs. Surprisingly, the logging system can give such unpleasant failures. Latency on disk in Azure - 5 milliseconds. If we write a file in a row, it is only 200 requests per second. That's it, the application has stopped.
It’s just that your hair stands on end when you see this - more than 2000 Threads have bred in the application. 78% of all Threads are the same call stack. They stopped at the same place and are trying to enter the monitor. This monitor delimits access to the file where we all log. Of course, this must be cut.
Here's what you need to do in NLog to configure it. We make an asynchronous target and write to it. And asynchronous target writes to the real file. Of course, we can lose a certain amount of messages in the log, but what is more important for business? When the system fell for 10 minutes, we lost a million rubles. It is probably better to lose several messages in the service log, which went into failure and rebooted.
Everything is very bad
Contention is a big issue in multi-threaded applications that doesn’t allow you to simply scale a single-threaded application. Sources of Contention need to be able to identify and eliminate. A large number of Threads are disastrous for applications, and blocking calls must be rewritten to async.
I had to rewrite a lot of legacy from blocking calls to async, I myself often initiated such an upgrade. Quite often, someone comes up and asks: “Listen, we’ve been rewriting for two weeks now, almost all async. And how much will it work faster? ”Guys, I’ll upset you - it won’t work faster. It will become even slower. After all, TPL is one competitive model on top of another - cooperative multitasking over preemptive multitasking, and this is overhead. In one of our projects - approximately + 5% to CPU usage and load on GC.
There is one more bad news - the application can work much worse after just rewriting on async, without realizing the features of the competitive model. I will talk about these features in great detail in the next article.
This raises the question - is it necessary to rewrite?
The synchronous code is rewritten on async in order to unblock the Concurrency Model and get rid of the Preemptive Multitasking model. We saw that the number of Threads can adversely affect performance, so you need to free yourself from the need to increase the number of Threads to increase Concurrency. Even if we have Legacy and we don’t want to rewrite this code - this is the main reason to rewrite it.
The good news at the end is that we now know something about how to get rid of the trivial problems of Contention of blocking code. If you find such problems in your blocking application, then it's time to get rid of them before rewriting to async, because there they will not disappear on their own.