Network debugging with eBPF (RHEL 8 Beta)
All with the last holidays!
After the holidays, we decided to dedicate our first article to Linux, that is, under our wonderful course “Linux Administrator” , which we have included in the cohort of the most dynamic courses, that is, with the most relevant materials and practices. Well and, accordingly, we offer interesting articles and an open lesson .
Article author: Matteo Croce
Original title: Network debugging with eBPF (RHEL 8 Beta)
Introduction
Working with the network is an exciting activity, but it is not always possible to avoid problems. Troubleshooting can be tricky, as well as trying to reproduce the wrong behavior that happens “in the field”.
Fortunately, there are tools that can help with this: network namespaces, virtual machines,
This article describes how to troubleshoot complex network issues with eBPF (extended BPF), an enhanced version of Berkeley Packet Filter. eBPF is a relatively new technology, the project is at an early stage, so the documentation and the SDK are not yet ready. But let's hope for improvements, especially since XDP (eXpress Data Path) comes with Red Hat Enterprise Linux 8 Beta , which you can download and run right now.
eBPF will not solve all the problems, but it is still a powerful tool for network debugging that deserves attention. I am sure it will play a really important role in the future of networks.

Problem
I debugged an Open vSwitch (OVS) network problem that affected a very complex installation: some TCP packets were scattered and delivered in the wrong order, and virtual machine bandwidth dropped from stable 6 Gb / s to 2-4 Gb / s fluctuating . The analysis showed that the first TCP packet of each connection with the PSH flag was sent in the wrong order: only the first and only one per connection.
I tried to reproduce this configuration with two virtual machines and, after a lot of reference articles and searches, found that none
It might have been possible to solve the problem with a combination
What is eBPF?
eBPF is an enhanced version of Berkeley Batch Filter. She brings a lot of improvements to BPF. In particular, it allows you to write in memory, and not just read, so packages can not only be filtered, but also edited.
Often, eBPF is simply called BPF, and BPF itself is called cBPF (classic (classic) BPF), so the word “BPF” can be used to refer to both versions, depending on the context: in this article I always talk about the extended version.
“Under the hood” of eBPF is a very simple virtual machine that can execute small pieces of bytecode and edit some memory buffers. EBPF has limitations that protect it from malicious use:
The program can be loaded into the kernel in various ways using debugging and tracing . In our case, we are interested in the work of eBPF with network subsystems. There are two ways to use the eBPF program:
To create an eBPF program to connect, just write the code in C and convert it to bytecode. Below is a simple example using XDP:
The fragment above, without expressions
To compile our code into eBPF bytecode, a compiler with appropriate support is required. Clang supports it and creates the eBPF bytecode by refining bpf as a target at compile time:
The command above creates a file that, at first glance, appears to be a regular object file, but upon closer inspection, it turns out that the specified type of computer is Linux eBPF, and not the native type of operating system:
Having received the wrapper of a regular object file, the eBPF program is ready to be loaded and connected to the device via XDP. This can be done using
This command specifies the target interface wlan0 and, thanks to the -force option, overwrites any existing eBPF code that has already been loaded. After downloading the eBPF bytecode, the system behaves as follows:
Each package passes through eBPF, which eventually makes some changes and decides whether to drop the package or skip.
How eBPF can help.
Returning to the initial network problem, we recall that we had to mark several TCP flags, one per connection, and
This sounds like a great solution, but it’s worth considering that XDP only supports the processing of received packets, and connecting eBPF to the path of the
To solve this problem, eBPF must be downloaded using
When loading eBPF programs between
Compilation into bytecode is done as shown in the XDP example above using the following:
But the download is different:
The eBPF is now loaded in the right place and the packages leaving the VM are marked. After checking the packets received in the second VM, we will see the following:
Conclusion
eBPF is a fairly new technology, and the community has a clear opinion about its implementation. It is also worth noting that projects based on eBPF, for example bpfilterare becoming more and more popular, and as a result, many equipment vendors are beginning to implement eBPF support directly into network cards.
eBPF will not solve all the problems, so do not abuse them, but it still remains a very powerful tool for network debugging and deserves attention. I am sure he will play an important role in the future of networks.
THE END
We are waiting for your comments here, and also invite you to visit our open lesson , where, if anything, you can also ask questions.
After the holidays, we decided to dedicate our first article to Linux, that is, under our wonderful course “Linux Administrator” , which we have included in the cohort of the most dynamic courses, that is, with the most relevant materials and practices. Well and, accordingly, we offer interesting articles and an open lesson .
Article author: Matteo Croce
Original title: Network debugging with eBPF (RHEL 8 Beta)
Introduction
Working with the network is an exciting activity, but it is not always possible to avoid problems. Troubleshooting can be tricky, as well as trying to reproduce the wrong behavior that happens “in the field”.
Fortunately, there are tools that can help with this: network namespaces, virtual machines,
tc and netfilter. Simple network settings can be reproduced using network namespaces and veth devices, while more complex settings require connecting virtual machines with a software bridge and using standard network tools, for example, iptables or tcto simulate incorrect behavior. If there is a problem with ICMP responses generated when the SSH server crashes, iptables -A INPUT -p tcp --dport 22 -j REJECT --reject-with icmp-host-unreachablein the correct namespace can help solve the problem. This article describes how to troubleshoot complex network issues with eBPF (extended BPF), an enhanced version of Berkeley Packet Filter. eBPF is a relatively new technology, the project is at an early stage, so the documentation and the SDK are not yet ready. But let's hope for improvements, especially since XDP (eXpress Data Path) comes with Red Hat Enterprise Linux 8 Beta , which you can download and run right now.
eBPF will not solve all the problems, but it is still a powerful tool for network debugging that deserves attention. I am sure it will play a really important role in the future of networks.
Problem
I debugged an Open vSwitch (OVS) network problem that affected a very complex installation: some TCP packets were scattered and delivered in the wrong order, and virtual machine bandwidth dropped from stable 6 Gb / s to 2-4 Gb / s fluctuating . The analysis showed that the first TCP packet of each connection with the PSH flag was sent in the wrong order: only the first and only one per connection.
I tried to reproduce this configuration with two virtual machines and, after a lot of reference articles and searches, found that none
iptables, nor nftables can not manipulate the flags of TCP, while the tc can, but only overwriting flags and breaking new connections and TCP as a whole.It might have been possible to solve the problem with a combination
iptables, conntrack and tc, but I decided that it was a great job for eBPF. What is eBPF?
eBPF is an enhanced version of Berkeley Batch Filter. She brings a lot of improvements to BPF. In particular, it allows you to write in memory, and not just read, so packages can not only be filtered, but also edited.
Often, eBPF is simply called BPF, and BPF itself is called cBPF (classic (classic) BPF), so the word “BPF” can be used to refer to both versions, depending on the context: in this article I always talk about the extended version.
“Under the hood” of eBPF is a very simple virtual machine that can execute small pieces of bytecode and edit some memory buffers. EBPF has limitations that protect it from malicious use:
- Cycles are prohibited so that the program always ends at a specific time;
- It can access memory only through the stack and the scratch buffer;
- Only authorized kernel functions can be called.
The program can be loaded into the kernel in various ways using debugging and tracing . In our case, we are interested in the work of eBPF with network subsystems. There are two ways to use the eBPF program:
- Connected via XDP to the beginning of the RX path of a physical or virtual network card;
- Connected through
tcto the qdisc inlet or outlet.
To create an eBPF program to connect, just write the code in C and convert it to bytecode. Below is a simple example using XDP:
SEC("prog")
intxdp_main(structxdp_md *ctx)
{
void *data_end = (void *)(uintptr_t)ctx->data_end;
void *data = (void *)(uintptr_t)ctx->data;
struct ethhdr *eth = data;
struct iphdr *iph = (struct iphdr *)(eth + 1);
struct icmphdr *icmph = (struct icmphdr *)(iph + 1);
/* sanity check needed by the eBPF verifier */
if (icmph + 1 > data_end)
return XDP_PASS;
/* matched a pong packet */
if (eth->h_proto != ntohs(ETH_P_IP) ||
iph->protocol != IPPROTO_ICMP ||
icmph->type != ICMP_ECHOREPLY)
return XDP_PASS;
if (iph->ttl) {
/* save the old TTL to recalculate the checksum */
uint16_t *ttlproto = (uint16_t *)&iph->ttl;
uint16_t old_ttlproto = *ttlproto;
/* set the TTL to a pseudorandom number 1 < x < TTL */
iph->ttl = bpf_get_prandom_u32() % iph->ttl + 1;
/* recalculate the checksum; otherwise, the IP stack will drop it */
csum_replace2(&iph->check, old_ttlproto, *ttlproto);
}
returnXDP_PASS;
}
char _license[]SEC("license") = "GPL";The fragment above, without expressions
include, helpers, and an optional code, is an XDP program that changes the TTL of the received ICMP echo-responses, namely pong'ov, to a random number. The main function receives a structure xdp_mdin which there are two pointers to the beginning and end of the packet. To compile our code into eBPF bytecode, a compiler with appropriate support is required. Clang supports it and creates the eBPF bytecode by refining bpf as a target at compile time:
$ clang -O2 -target bpf -c xdp_manglepong.c -o xdp_manglepong.oThe command above creates a file that, at first glance, appears to be a regular object file, but upon closer inspection, it turns out that the specified type of computer is Linux eBPF, and not the native type of operating system:
$ readelf -h xdp_manglepong.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Linux BPF <--- HERE
[...]Having received the wrapper of a regular object file, the eBPF program is ready to be loaded and connected to the device via XDP. This can be done using
ipthe package iproute2with the following syntax:# ip -force link set dev wlan0 xdp object xdp_manglepong.o verboseThis command specifies the target interface wlan0 and, thanks to the -force option, overwrites any existing eBPF code that has already been loaded. After downloading the eBPF bytecode, the system behaves as follows:
$ ping -c10 192.168.85.1
PING 192.168.85.1 (192.168.85.1) 56(84) bytes of data.
64 bytes from 192.168.85.1: icmp_seq=1 ttl=41 time=0.929 ms
64 bytes from 192.168.85.1: icmp_seq=2 ttl=7 time=0.954 ms
64 bytes from 192.168.85.1: icmp_seq=3 ttl=17 time=0.944 ms
64 bytes from 192.168.85.1: icmp_seq=4 ttl=64 time=0.948 ms
64 bytes from 192.168.85.1: icmp_seq=5 ttl=9 time=0.803 ms
64 bytes from 192.168.85.1: icmp_seq=6 ttl=22 time=0.780 ms
64 bytes from 192.168.85.1: icmp_seq=7 ttl=32 time=0.847 ms
64 bytes from 192.168.85.1: icmp_seq=8 ttl=50 time=0.750 ms
64 bytes from 192.168.85.1: icmp_seq=9 ttl=24 time=0.744 ms
64 bytes from 192.168.85.1: icmp_seq=10 ttl=42 time=0.791 ms
--- 192.168.85.1 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 125ms
rtt min/avg/max/mdev = 0.744/0.849/0.954/0.082 msEach package passes through eBPF, which eventually makes some changes and decides whether to drop the package or skip.
How eBPF can help.
Returning to the initial network problem, we recall that we had to mark several TCP flags, one per connection, and
iptablesneither tc could have done so. Writing code for this scenario is a snap: set up two virtual machines connected by an OVS bridge, and simply connect eBPF to one of the virtual VM devices. This sounds like a great solution, but it’s worth considering that XDP only supports the processing of received packets, and connecting eBPF to the path of the
rx receiving virtual machine will have no effect on the switch. To solve this problem, eBPF must be downloaded using
tc and is connected to the output path of the VM, because it tc can download and connect eBPF programs to qdisk. To mark packets leaving the host, eBPF must be connected to the output qdisk. When loading eBPF programs between
XDP and tc API there are some differences: the default name different sections, different type of structure is the argument of the main function, different return values. But it's not a problem. Below is a fragment of a program marking TCP when it is attached to a tc action:#define RATIO 10
SEC("action")
intbpf_main(struct __sk_buff *skb){
void *data = (void *)(uintptr_t)skb->data;
void *data_end = (void *)(uintptr_t)skb->data_end;
structethhdr *eth = data;structiphdr *iph = (structiphdr *)(eth + 1);structtcphdr *tcphdr = (structtcphdr *)(iph + 1);/* sanity check needed by the eBPF verifier */if ((void *)(tcphdr + 1) > data_end)
return TC_ACT_OK;
/* skip non-TCP packets */if (eth->h_proto != __constant_htons(ETH_P_IP) || iph->protocol != IPPROTO_TCP)
return TC_ACT_OK;
/* incompatible flags, or PSH already set */if (tcphdr->syn || tcphdr->fin || tcphdr->rst || tcphdr->psh)
return TC_ACT_OK;
if (bpf_get_prandom_u32() % RATIO == 0)
tcphdr->psh = 1;
return TC_ACT_OK;
}
char _license[] SEC("license") = "GPL";Compilation into bytecode is done as shown in the XDP example above using the following:
clang -O2 -target bpf -c tcp_psh.c -o tcp_psh.oBut the download is different:
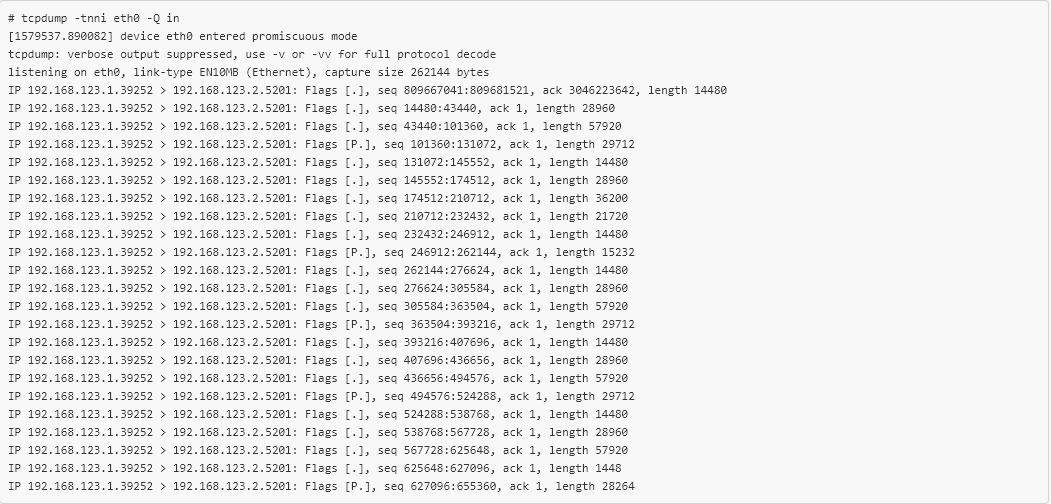
# tc qdisc add dev eth0 clsact# tc filter add dev eth0 egress matchall action bpf object-file tcp_psh.oThe eBPF is now loaded in the right place and the packages leaving the VM are marked. After checking the packets received in the second VM, we will see the following:
tcpdump confirms that the new eBPF code is working, and about 1 out of every 10 TCP packets have the PSH flag set. Only 20 lines of C code were needed to selectively mark TCP packets leaving a virtual machine, reproduce the error that occurs “in combat”, and all without recompiling or even restarting! This greatly simplified the verification of the Open vSwitch fix , which could not be achieved using other tools. Conclusion
eBPF is a fairly new technology, and the community has a clear opinion about its implementation. It is also worth noting that projects based on eBPF, for example bpfilterare becoming more and more popular, and as a result, many equipment vendors are beginning to implement eBPF support directly into network cards.
eBPF will not solve all the problems, so do not abuse them, but it still remains a very powerful tool for network debugging and deserves attention. I am sure he will play an important role in the future of networks.
THE END
We are waiting for your comments here, and also invite you to visit our open lesson , where, if anything, you can also ask questions.