PHP: changing database structure in team development
In the PHP world, database structure migration tools are well known - Doctrine , Phinx from CakePHP, from Laravel , from Yii - this is the first thing that came to mind. Surely there are a dozen more. And most of them work with migrations - commands for making incremental changes to the database schema.
I will not describe why this is, there are many posts on this topic on Habré. For instance:
- Versioned migration of the database structure: basic approaches - although the old article, the principles do not age
- Evolutionary database design - translation of Martin Fowler's article, good description [incremental approach]
- Experience 1440 database migrations - a practical post on working with PostgesSQL
Further, the development of my experience as a team with a constant change in the structure of the database in different branches.
raw SQL vs PHP api
We write migrations in pure SQL. Many tools provide PHP api for writing instructions translated into SQL code. Now I don’t understand why this is? Such a tool will always be limited in its capabilities. They do not allow to write specific instructions for a specific engine; you still have to use pure SQL. I'm not talking about writing procedures and views.
Someone complained that he did not want to learn the syntax of ALTER commands ... Well, I don’t know, I opened the directory and wrote examples of the mountain, especially in a large project.
Data migrations (INSERT, UPDATE) are also always written in SQL. Because you can never rely on the current version of ORM and Models. In one revision they are, in another no longer.
For instance:
Rollback
Country::delete()->where(....)->execute();
Want to roll back the state of the database. And this PHP class is no longer in the repo. You need to look for the last commit where he was and roll back from there. Brrr ...
Therefore, SQL is simple and reliable:
--TRANSACTION
--UP
ALTER TABLE authors ADD COLUMN code INT;
ALTER TABLE posts ADD COLUMN slug TEXT;
UPDATE authors SET ...
--DOWN
ALTER TABLE authors DROP COLUMN code;
ALTER TABLE posts DROP COLUMN slug;
Transactions in DDL
With the transition to PostgreSQL, I forgot about broken migrations like a nightmare - migration fell in the middle, something rolled up, something not there, sit and edit the pens ... This forced us to write atomic single-line commands and run them one at a time. Everything is simple with transactions: if something breaks - everything rolls back (well, almost everything))). Just fix it and restart it. Automatic assembly works with a bang, if something fell, it quickly fixes and rises.
Views (views) and functions
The problem here is that they cannot be updated incrementally, like ALTER in tables. Need DROP and CREATE. Those. on the differential (text of migration) it is not at all clear what changed in the end. Especially when the logic is twisted, it is quite inconvenient. For instance:
--UP
DROP VIEW ...
CREATE VIEW mvstock AS
SELECT (now() - '7 days'::interval) AS refreshed_at,
o.pid,
COALESCE(sum(o.debit), 0)::integer AS debit,
COALESCE(sum(o.credit) FILTER (WHERE d.type <> 104), 0)::integer AS credit,
COALESCE(sum(o.debit), 0) - COALESCE(sum(o.credit), 0)::integer AS total
FROM operations o
JOIN docs d ON d.id = o.doc_id AND d.deleted_at IS NULL
WHERE d.closed_at < (now() - '7 days'::interval) AND d.type <> 500
GROUP BY o.pid
WITH DATA;
--DOWN
DROP VIEW ...
CREATE VIEW mvstock AS
SELECT (now() - '10 days'::interval) AS refreshed_at,
o.pid,
COALESCE(sum(o.debit), 0)::integer AS debit,
COALESCE(sum(o.credit) FILTER (WHERE d.type <> 104), 0)::integer AS credit,
COALESCE(sum(o.debit), 0) - COALESCE(sum(o.credit), 0)::integer AS total
FROM operations o
JOIN docs d ON d.id = o.doc_id AND d.deleted_at IS NULL
WHERE d.closed_at < (now() - '10 days'::interval) AND d.type <> 500
GROUP BY o.pid
WITH DATA;
What has changed here?
We stopped at the fact that next to the migrations is a daddy, where the current view and procedure code is stored, which is updated and copied in the rollback migration.
And now the diff becomes similar to:

Even in Avito, they made an interesting solution for versioning the code of stored procedures.
In general, this case raises a good problem - how to look at the history of changes in a particular object of the database structure. For each table, I want to see the history of changes in connection with the solution of specific tasks.

Found on Habré an interesting approach for automation of fixing changes in the database structure.
Work with branches
My eternal pain is how to switch between two A- and B-branches, each of which has edits on the structure of the database.

It is necessary to roll back migrations in the A-branch (we must also remember which and how many), then switch to the B-branch and roll new migrations. Okay, if our edits are compatible and I can just switch to the second branch and roll additional migrations from B.
And if not? And if I have more than one such branch? And then roll back all these review state? I always hated it ...
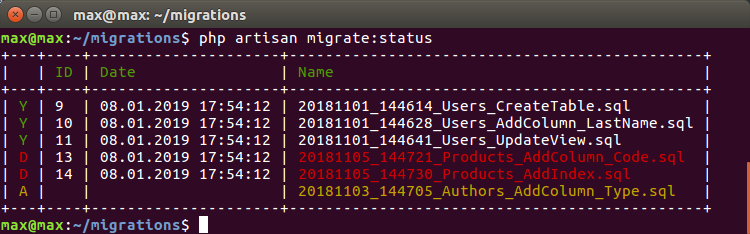
Now, when I switch to someone else’s branch, I can automatically delete someone else’s migrations and roll the current ones:
where:
D - A-migrations that were launched in the A-branch, but they are not in the current branch, and it is recommended to delete
A- B-migrations that have appeared in the new branch and they need to be rolled
It becomes insanely convenient when testing and auto- assembling on the same base. When there is no sense or opportunity for each branch to create a base from scratch. Switch to the branch and automatically synchronize the state of the database.
Numbering and order of execution
All the tools I know are timed stamped migrations is a good solution. If I write several migrations, the necessary sequence is preserved. Another developer can have any date in another thread, even mine - but it doesn’t matter in what order we roll with him, our changes are independent of each other. Even if we work with the same table (add by column), then all necessary changes will take place in any order. The main thing is that the sequence of my dependent edits is respected.

I do not consider cases when we need to edit the same thing - these points are always consistent. Well, or there will be a fail at the stage of assembly and testing.
Here is an interesting example.
We make different edits in one view or procedure, i.e. in those structures that are updated through deletion. Those. For example, I added the col_A column to the view, and my colleague col_B. Accordingly, if his code rolls out after mine, then his column will not have my column:
CREATE VIEW vusers AS
SELECT
login,
name,
-- ....
| branch-A | branch-B |
|---|---|
| |
Another interesting case is corrections in migrations.
The bottom line is that the migration that was applied will no longer be applied again, no matter how many changes you make to it (you need to roll back first and then apply it again). Those. You sent Migration for testing, all the rules, and then you realized it and made a small edit. But the test or other server where you used it will not know about it.
In these cases, we rename the migration file, adding a new version number, so that the migrator begins to interpret this as 2 commands - roll back 1 and roll 2,
for example:

Rollback
Always write ROLLBACK, even if it cannot return the base to its original state. For example, DROP TABLE, what kind of ROLLBACK can it be?
In such cases, we write an empty CREATE TABLE. The bottom line is that the dev system can always easily switch between branches. For PROD, irreversible revision management is already decided at a different level. I can make a copy of the table, or rename it instead of deleting it. But the very principle of writing migration - the rollback is OBLIGED to return the STRUCTURE of the base to the initial level, and the data is already possible.
In a combat environment, I used a rollback only 1-2 times in my life. And in dev all the time. Therefore, I always check that the rollback returns everything to the desired state.
Often developers can make mistakes in the rollback. Because they primarily focus on new edits, they are tested and work with them. Other people and processes are already working with the rollback. Therefore, I always test migrations UP - ROLLBACK - UP
An interesting point appears on a permanent test base (the database is not deleted). They wrote a migration, the rollback works fine, they sent it for testing, the tester generated data in a new format, tries to roll back, but they don’t give new data. Classic example
ALTER TABLE abc ALTER COLUMN code SET NULLPerfectly! After testing, the database is full of NULL values. Do ROLLBACK:
ALTER TABLE abc ALTER COLUMN code SET NOT NULLand vice versa :-(
We must add the command:
DELETE FROM abc WHERE code IS NULLThe difficulty is that you need to keep this in mind and not automate it if we are not talking about re-creating the database from scratch every time.
A bit about data deletion
Usually we try NOT to delete filled tables and columns at once. It is better to rename or make a copy, and delete it later, when everything settles down and the data loses its relevance:
ALTER TABLE user_logs RENAME TO user_logs_20190223;
-- или
CREATE TABLE user_logs_20190223 AS TABLE user_logs;
Migrator
We are working with Laravel now - he has a standard, familiar migration management engine. If you want, write even in pure SQL, though it's still in the PHP class. But my repeated attempts to make it work the way we needed resulted in a separate repo:
- The solution consists of 2 parts - lib and implementation for a specific console (Laravel, Symfony). You can integrate into any console, or at least in the web-muzzle.
- There is no config and connection - why, when it is already in your project. Cling your connection to the interface and go.
- SQL rollback is stored in the database. This is necessary to switch between branches.
- Tested on Postgesql, Mysql (no transactions). It is suitable in principle for any bases and structures, because the raw format is used.
Links
- migrations-lib
- implementation under Laravel / Artisan
- implementation under Symfony / Console