Spring JPA repositories in CUBA

The topic of the article is quite narrowly focused, but it may be useful for those who are developing their own data warehouses and are thinking about integration with the Spring Framework.
Prerequisites
Developers usually do not like to change their habits (often, the list of habits includes frameworks). When I started working with CUBA , I did not have to learn too much of everything new, it was possible almost immediately to be actively involved in the work on the project. But there was one thing that I had to sit on a bit longer - it was work with data.
In Spring there are several libraries that can be used to work with the database, one of the most popular is spring-data-jpa , which in most cases makes it possible not to write SQL or JPQL. You just need to create a special interface with methods that are named in a special way, and Spring will generate and execute for you the rest of the work on fetching data from the database and creating instances of entity objects.
Below is the interface, with a method for counting customers with a given last name.
interfaceCustomerRepositoryextendsCrudRepository<Customer, Long> {
longcountByLastName(String lastName);
}This interface can be directly used in Spring services without creating any implementation, which greatly speeds up the work.
CUBA has an API for working with data, which includes various functionality, such as partially loaded entities or a clever security system with access control to entity attributes and rows in database tables. But this API is a little different from what Spring Data or JPA / Hibernate developers are used to.
Why is there no JPA repositories in CUBA and can I add them?
Work with data in CUBA
CUBA has three main classes responsible for working with data: DataStore, EntityManager and DataManager.
DataStore is a high-level abstraction for any data storage: database, file system or cloud storage. This API allows you to perform basic operations on data. In most cases, developers do not need to work with DataStore directly, except when developing their own storage, or if you need some very special access to data in the storage.
EntityManager - a copy of the well-known JPA EntityManager. Unlike the standard implementation, it has special methods for working with CUBA views , for "soft" (logical) deletion of data, as well as for working with queries in CUBA . As in the case of the DataStore, in 90% of projects, an ordinary developer will not have to deal with EntityManager, except for the cases when it is necessary to execute any queries that bypass the data access restriction system.
DataManager is the main class for working with data in CUBA. Provides an API for data manipulation and supports data access control, including access to attributes and row-level constraints. DataManager implicitly modifies all queries that are executed in CUBA. For example, it can exclude table fields to which the current user does not have access from the operator selectand add conditions whereto exclude table rows from the selection. And it makes life much easier for developers, because you don’t have to think about how to correctly write requests based on access rights, CUBA does this automatically based on data from the database service tables.
Below is a diagram of the interaction of CUBA components that participate in data sampling through DataManager.
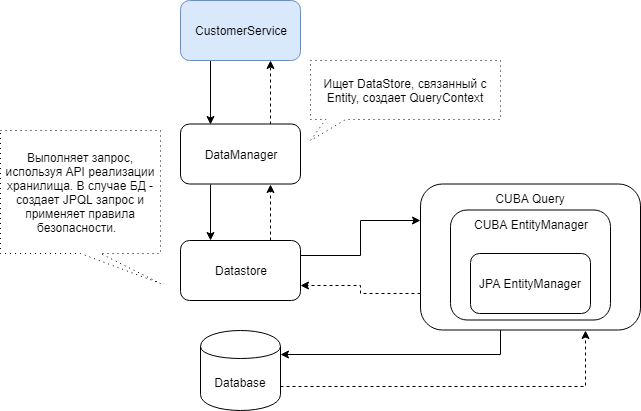
With DataManager, you can relatively easily load entities and whole hierarchies of entities using CUBA views. In its simplest form, the query looks like this:
dataManager.load(Customer.class).list();As already mentioned, DataManager will filter out "logically deleted" records, remove forbidden attributes from the request, and also open and close the transaction automatically.
But, when it comes to queries, it’s more difficult, then in CUBA you have to write JPQL.
For example, if you need to count clients with a given last name, as in the example from the previous section, you need to write something like this code:
public Long countByLastName(String lastName){
return dataManager
.loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class)
.parameter("lastName", lastName)
.one();
}or this:
public Long countByLastName(String lastName){
LoadContext<Customer> loadContext = LoadContext.create(Customer.class);
loadContext
.setQueryString("select c from sample$Customer c where c.lastName = :lastName")
.setParameter("lastName", lastName);
return dataManager.getCount(loadContext);
}In the CUBA API, you need to pass the JPQL expression as a string (the Criteria API is not yet supported), this is a readable and understandable way to create queries, but debugging such queries can bring a lot of fun minutes. In addition, JPQL strings are not verified by either the compiler or the Spring Framework during container initialization, which leads to errors only in Runtime.
Compare this with Spring JPA:
interfaceCustomerRepositoryextendsCrudRepository<Customer, Long> {
longcountByLastName(String lastName);
}The code is three times shorter, and no lines. In addition, the method name is countByLastNamechecked during the initialization of the Spring container. If a typo is made and you have written countByLastNsme, the application will crash with an error during deployment:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer! CUBA is built around the Spring Framework, so that in an application written using CUBA, you can connect the spring-data-jpa library, but there is a small problem - access control. Implementing CrudRepository in Spring uses its EntityManager. Thus, all queries will be bypassed by the DataManager. Thus, in order to use JPA repositories in CUBA, you need to replace all EntityManager calls with DataManager calls and add support for CUBA views.
One might say that spring-data-jpa is such an uncontrollable black box and it is always preferable to write pure JPQL or even SQL. This is the eternal problem of the balance between convenience and level of abstraction. Everyone chooses the way he likes, but to have an additional way to work with data in the arsenal will never hurt. And for those who need more control, in Spring there is a way to define your own query for JPA methods of repositories.
Implementation
JPA repositories are implemented as a CUBA module, using the spring-data-commons library . We abandoned the idea of modifying spring-data-jpa because the amount of work would be much larger compared to writing our own query generator. Especially since spring-data-commons does most of the work. For example, parsing a method name and associating a name with classes and properties is done entirely in this library. Spring-data-commons contains all the necessary base classes for implementing your own repositories and it takes not so much effort to implement this. For example, this library is used in spring-data-mongodb .
The most difficult thing was to accurately implement JPQL generation based on a hierarchy of objects — the result of parsing the method name. But, fortunately, Apache Ignite has already implemented a similar task, so the code was taken from there and slightly adapted for generating JPQL instead of SQL and operator support delete.
Spring-data-commons uses proxying to dynamically create interface implementations. When the CUBA application context is initialized, all references to interfaces are replaced with references to proxies published in the context. When calling an interface method, it is intercepted by the corresponding proxy object. Then this object generates a JPQL query by the method name, inserts the parameters, and sends the query with the parameters in the DataManager for execution. The following diagram shows a simplified process of interaction of key components of the module.

Using repositories in CUBA
To use the repositories in CUBA, you just need to connect the module in the project assembly file:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")You can use the XML configuration to "enable" repositories:
<?xml version="1.0" encoding="UTF-8"?><beans:beansxmlns:beans="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa"xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd
http://www.cuba-platform.org/schema/data/jpa
http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd"><!-- Annotation-based beans --><context:component-scanbase-package="com.company.sample"/><repositories:repositoriesbase-package="com.company.sample.core.repositories"/></beans:beans>And you can use the annotations:
@Configuration@EnableCubaRepositoriespublicclassAppConfig{
//Configuration here
}After the repository support is activated, you can create them as usual, for example:
publicinterfaceCustomerRepositoryextendsCubaJpaRepository<Customer, UUID> {
longcountByLastName(String lastName);
List<Customer> findByNameIsIn(List<String> names);
@CubaView("_minimal")
@JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')")
List<Customer> findByNameStartingWith(String name);
}For each method, you can use annotations:
@CubaView- to set the CUBA view to be used in the DataManager@JpqlQuery- to set the JPQL query to be executed, regardless of the name of the method.
This module is used in the globalCUBA framework module , therefore, you can use repositories both in the module coreand in web. The only thing you need to remember is to activate the repositories in the configuration files of both modules.
An example of using the repository in the CUBA service:
@Service(CustomerService.NAME)
publicclassCustomerServiceBeanimplementsPersonService{
@Injectprivate CustomerRepository customerRepository;
@Overridepublic List<Date> getCustomersBirthDatesByLastName(String name){
return customerRepository.findByNameStartingWith(name)
.stream().map(Customer::getBirthDate).collect(Collectors.toList());
}
}Conclusion
CUBA is a flexible framework. If you want to add something to it, then there is no need to fix the kernel yourself or wait for the new version. I hope that this module will make development with CUBA more efficient and faster. The first version of the module is available on GitHub , tested on CUBA version 6.10