Gentleman sysadmin set
An admin is the person without whom nothing in the IT company will work. And with a happy and productive admin, things will move better and faster, so a comfortable working atmosphere is the concern of the company. The report by Anton Turetsky ( banuchka ) on Highload ++ 2017 was about how to make the team productive with tools.
Anton loves infrastructure tasks and automation of everything that can be automated, so his story is based on the example of setting up infrastructure in a data center and related technologies Docker, Consul, Puppet ...). But aspects that interfere with quality work and how to solve them are as universal as possible and suitable for almost any executive team. So we ask you for a cut for decoding this report.

Badoogrowing every year, here are a few numbers that reflect this: 350 million messages per day, 364 million registered users worldwide, 300 thousand new users per day. But this is far from the most important thing, for the person who works at Badoo, the main thing is first of all a way of thinking and a team. Badoo is a family, it's about people and it's cool!
I want to start with a provocation that someone might not support:
I think you will agree with me: the admin is the person without whom nothing in the company will work: the equipment comes to him, he puts in the system, he allocates new equipment again. Therefore, I believe that he is the main one.
I will give an example from personal practice in Badoo. Judge about this situation yourself: we had a new project called ReThink. We updated our logo: changed the font and color of letters from multi-colored to purple, added a heart - monotonous and cool. But the admins were warned that ReThink would happen - we just take it and switch it - we warned the last night almost before going home. And here a somewhat unpredictable load in one of the clusters started to hit. Thanks to the person who was on duty and helped the rest of the team just to find additional servers and finish them. The project actually shot, we did not fall, rolled out normally and everyone was happy.
In confirmation of my words, I want to say that a happy and productive admin in the company is, among other things, profitable and interesting for the company.I would like to ask all companies to make their admins happy . Then you will be fine!

Let's think about what makes the admin sad . It will occur to many that the admin is sad from a crashed server and lost backups. This is all true, but if the admin would think and go into sadness every time when he did something wrong - and he does something wrong every day - he wouldn’t have enough nerves.
Therefore, I denote the problem, which is a certain human factor, namely, context switching.
Context switch
There is a fairly large number of studies on what happens when a person is torn off, and why it is bad. One of the last good studies is the work of Chris Parnin , a fellow at Georgia University of Technology. He collected a bunch of different data on this topic and made a lot of conclusions, the main of which is:
This is an average figure. Someone may have more, someone else less, depending on the switching. With a simple addition, you can find that if you were distracted 4-5 times in one hour by something, an entire hour of working time is likely to be lost, and you are unlikely to do your job.
This is a theory - a person investigated, came to conclusions. In practice, you probably faced this situation: you come to work, spent the whole working day in a booze - did everything all day, did not have time to have lunch, did not answer the instant messengers and mail. By the end of the working day you are all tortured, it seems to you that you have done a lot of everything. But at best, in the evening you realize that you didn’t do halfwhat was planned for the working day. Worse, when a manager or colleague approaches you and asks: “What did you do today?” And you understand that you ran, ran, ran - but there is nothing at the exit .
In many respects, this comes from switching our context and the inability to concentrate on the task. For the admin - a simple performer - this is so.
But there are still managers / team leaders and the flip side. The key feature of team leaders is that they, like maniacs, this context-switching is not something that they can survive, but even they sometimes increase it to reduce it later. That is, they focus many meetings with this switch for several hours, and then rest in the evening, working on one task. The switching skill can be developed to the point that it takes only 5 minutes to immerse yourself in a new task. This is very cool, and for the fact that they know how to do it, managers can be appreciated and respected. But for the administrator and the performer it is better to get rid of the switches .
Process opacity
The second important problem is the opacity of the processes, which can be divided into two zones:
Inside the team, this is what we can influence: shortcomings or lack of coordination between team members. The worst thing that the opacity of processes within a team can lead to is duplication of work . In principle, this is not bad, apart from the fact that you are losing, most likely, the working time of one of the employees.
Here you can find the pros and say: “Perhaps Vasya did better than Petya! Let's take his decision. ” But they could talk among themselves, and someone would do one. It is important.
If non-transparent processes are outside the team, for example, as a whole something is happening incomprehensibly in the company, inside the team this can lead to incorrect prioritization of tasks.

For example, a developer from the mobile web came to me and said that it’s important for him to pick up a service that will give something for the new API today. I have many other tasks, and it does not seem to me at all that his task is a priority. He was waiting for his release for a week, he will wait another two days, I will do it later. For business, this is not always the case. If a team comes to us from above that the current task has high priority, because it is part of a very large next task, it is important that this is not even conveyed by the manager, but that each member of the team understands this simply without further ado .
From the point of view of the performer and admin, I would like to build my story today to solve these two main problems within the team. I’ll talk about how we found a few rules in order tominimize context switching and make processes as transparent as possible .
How to solve the context switching problem
The admin came to work, drank a cup of coffee, read the mail, backups work, nothing fell - sit, work, which can interfere.
Consider the usual situation. The man came fresh, everything is fine, he opened his working tools, wrote in a chat and in the mail, and then the phone rang - they asked what had fallen at night - he was distracted. Then the wife or girl posted a cool photo - you need to go in and out, and Facebook is also moving. Here friends come to discuss yesterday's football meeting, they call me in the evening to drink beer or now tea. And all this comes to a person from all sides little by little.

What to do with this problem? We have a person, there is his general social life, there is its working aspect. In this case, we can only consider and optimize the part that concerns itworking tools . We cannot forbid him to go to drink beer after work or to use social accounts, because we are not in prison after all.
Therefore, we decided to look at what kind of working tools the administrator has, where he is often pulled from, and what we can do to reduce this.
The first idea is rather strange, but we tried it - to allow the administrator to simply not use the chat , because a lot of people write to the chat. You are working on a task, and one wrote to you that this is important to him, the other - that it is important to him. And we allowed the admins not to use chat - not to answer and not to write anything there.
The idea, of course, did not take off, because in addition to writing what you need to read in the chat, chat is the fastest way to communicate. You just need to write there. Just a week later, it became clear that the idea was utopian, we decided to abandon it and went further.

We made a partly strange decision - we single out one member of the team and told him: “Dude, you will be a conditional leader! This is not a promotion, you just know a lot about which of your colleagues is good in which field, you know the general stream of tasks and more or less about priorities. Therefore, come on, you will work according to the following scenario. There is a pool of tasks that fall on all the admins in the team, you see who is busy with what, you know what the deadlines are for the task, and you can always give it to the person who can handle it as quickly as possible; or, if there is a lot of time for execution, you can assign it to the junior. Junior needs to tell basic things, but you know that if they help him, he will be pumped and everything will be cool. ” In principle, the idea is quite robust.
One of the reasons why she didn’t completely go in is because we all admins love to work on what they like. We can do tasks when everything is on fire and we have to do it - we don’t understand, we take and do, no matter who. Another thing is when you have a choice: "I am currently working on one task and want to configure replication in MySQL, I don’t want to touch Puppet - let someone else do it."
People began to burgle, for some there are few tasks, for many there are, for some people they get uninteresting - something so incomprehensible and inexplicable. Perhaps this was our miscalculation, but this approach did not work.
Around the same time, we are trying to load the Arbitrator with another duty. To the admin team, other teams are tasked with doing something - backup, restore, etc. A person with such an application is, in fact, a client, and he is always waiting for feedback. When, having set a task, he sees that the task has switched in the general pool from the status “not assigned” to “assigned” to a specific executor, 2-3 hours have passed, one working day, another, and the task has no beats, it’s not clear at all engaged in his task or not.
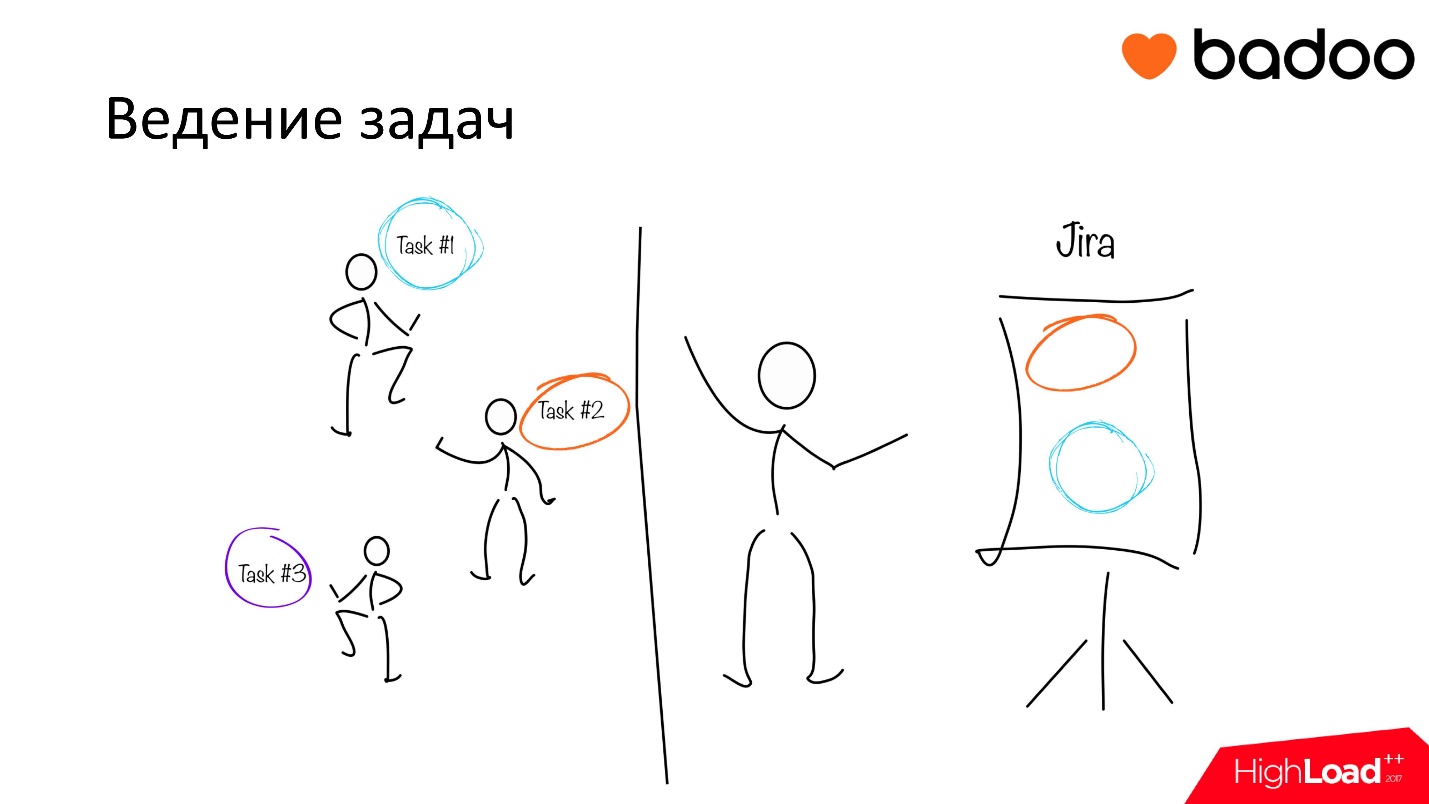
There are administrators who do not really like to conduct their tasks in the form of correspondence. Therefore, the Arbiter now needs to arrange one-to-one meetings with each member of his team, conduct almost every task, ask if there are difficulties on the task, how to help, and summarize the information collectedevery 1-2 days.
Tasks began to be carried out somehow. But everything stalled, because our current Referee simply buried in so much knowledge . Indeed, in order to summarize something for you, you need to understand each subject area, think of what stage an employee has reached, what is stopping him, and write this. When there are a lot of such tasks, the Referee simply stops writing something, and the tasks cease to be conducted in the same way. Therefore, it was necessary to move on and change something again.
Eisenhower matrix
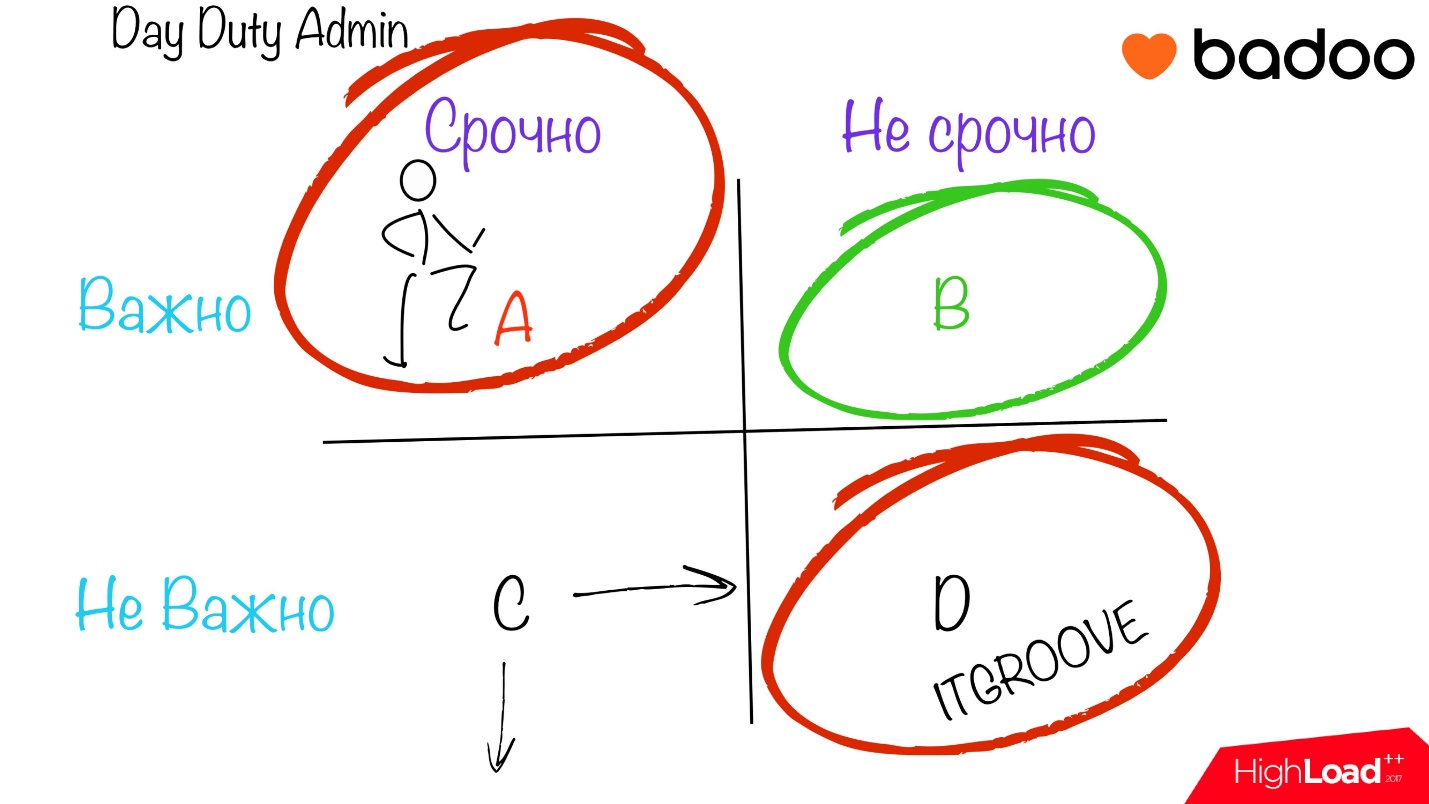
You may have already seen this matrix, you just don’t know the name. The bottom line is that we divide the task sheet into 4 parts according to two parameters:
We simply throw all our tasks into this wonderful tablet and start working.
It is worth noting immediately that cell B , the most productive and comfortable for the performer, is an important and not urgent task. This is a great motivator for a person when your task is important either for the team, or for the project, or just for you. You understand that you are working not just on some kind of nonsense, but on what people will use, and this adds an incentive. The plus of non-urgency is that you are left to your own devices. Do you have time to read, test, make some calculations.
We sat, thought and came up with the idea of separating all the tasks coming into the operation department, and format tasks are not very important and not very urgent to separate into a separate project, which we calledITGROOVE . Here we included tasks that, in the future, maybe someday will really turn into a problem, but now they are not a problem, and it would be nice to do them in some foreseeable future - a week or two.
After that, we introduced the function of the day duty administrator , the essence of which is as follows. We have the first line of support and response to emergency operations and triggers, monitoring. If she can’t cope with the problem and decides what needs to be escalated, then the first person who gets involved in solving this problem in the daytime is the day duty administrator.
If before that I told you that we are getting rid of the influence of context switching, here we are simply throwing a person at the embrasure and telling everyone to do everything in a row, switch as soon as you can.
In fact, this is not entirely true, because the day-time administrator on duty performs the following actions: either escalates the problem and passes it to the best specialist of the department in this subject area, which is currently available, or almost automatically fixes the problem. This is not mental activity - wake a person at night, he will go and fix it.
As an added bonus, we offered the day duty officer, if he had nothing to do and was bored, to work on the ITGROOVE project. Not only does the person cover the rest of the team, he also closes unimportant and non-urgent tasks!
By introducing the role of the day duty officer and dividing the tasks into completely unimportant and project ones, we allowed the rest of the team to work in the most comfortable zone B on non-urgent, but important tasks. People just emerged from point A, looked around, and there is point B - and I feel comfortable, and everyone is happy - it's cool! Will be working!
I will not disregard the tasks from point C. It sounds somehow delusional: “Urgent, but not important” - either urgently or not important. In our case, usually work in this segment does not occur. Tasks with the criteria “not important, but urgent” either become “not important and not urgent”, or simply disappear, and we do not work on them.
Since I touched on the fact that we introduced the role of a daytime administrator on duty, let's briefly go over what administrators we generally have:
How to make processes transparent
The complexity of our specific team lies in the fact that one part of it is in London, the other in Moscow, this is a fairly large shift in time zones. In Moscow, the guys begin to work much earlier, in London they just come to work, and they have already done something. In turn, we at the London office, finishing up in the evening, are doing some other things that people in Moscow did not know when they went home. To coordinate processes within the team, we have a weekly Monday rally.
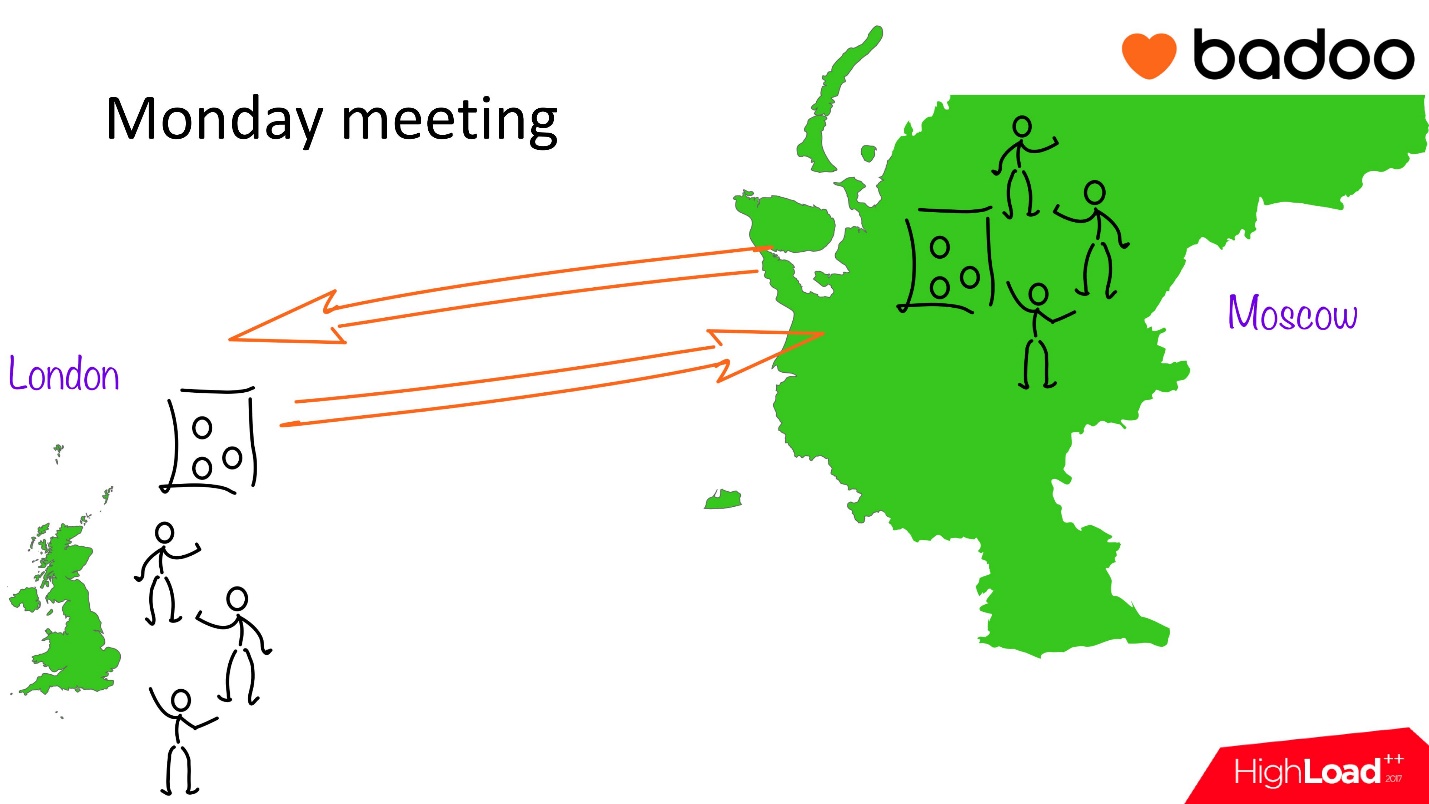
It looks like this:
But the problem is that somewhere by the evening of Tuesday or the morning of Wednesday, coordination is a little lost . For example, I started working on a task, stepped aside, I have different tasks for this week, something similar happens for a colleague from Moscow. We will be out of sync until next Monday, until the next auction - something needs to be done.
Status hero
There is a cool tool called Status Hero . Its essence is that when you come to work, you plan for yourself certain tasks. Status Hero has 3 fields to fill out. Moreover, this is not a mandatory tool, we can not fill it in and not use it.
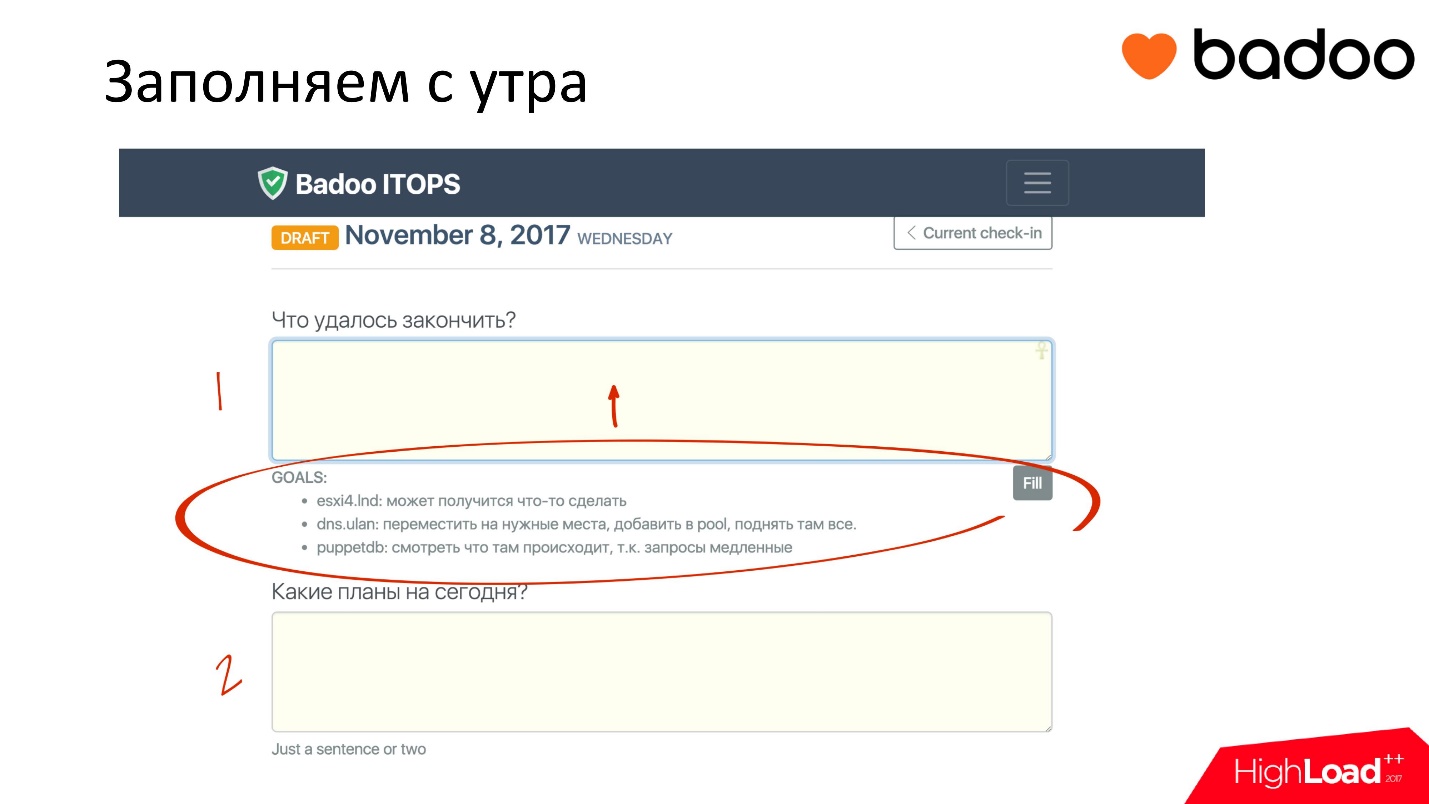
The trick is this: I came to work fresh, and I know that today I want to fix some DNS, set up metrics reset in Prometheus, see how new charts work, and possibly close current tasks. I fit all this into the plan for today.
But a line flickers over my plan for today, which says that yesterday you promised yourself to do this, and come on, you first write what you did yesterday from what you promised, and then what you will do Today.
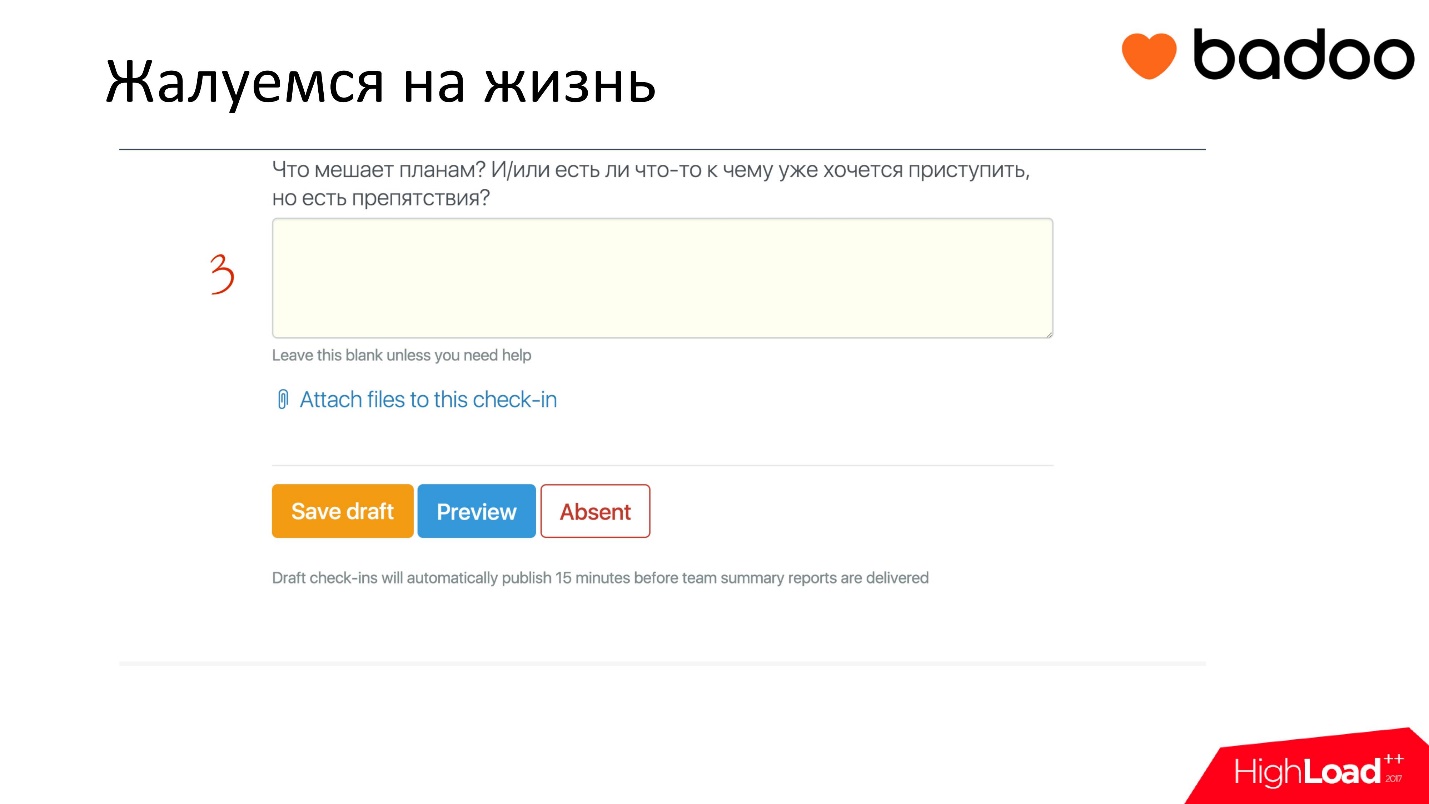
Also there is a wonderful third point. This field is to indicate some external events that block the execution of tasks . For example, someone from another team did not provide you, it doesn’t matter what - a patch, fix, the necessary data to do the job, and you are a shy guy and you can’t call and demand him. Now you can write something like this here, it will be highlighted in red, and either the manager or the guys from the team will help you. That is, you will voice your problem , and you won’t sit silently and wait for a problem independent of you to be solved and you will be able to do your job.

In turn, the team also sees this. We have a special group in HipChat, where after someone has filled out a form, it is shown to the whole team. A person with a cursory glance is enough to view the chat and understand what his colleagues will do. If suddenly there is some kind of blocker that he can resolve and thereby help his colleague, then he does it. That's cool!
Why does Status Hero work?
Status Hero revealed the problem
But not only did Status Hero help us organize this activity, it also revealed one rather strange problem for us. It consisted in the fact that at that time the operational documentation either did not exist at all, or it was not enough.
You managed to understand this approximately when you began to see what colleagues were working on, to help them and tell how to do something. When you explain the same thing for the sixth time , you understand that if you wrote it once, your colleague would go through the script once, make corrections and comments, and that’s all - there would be no need to be distracted by the explanations six times . A person, in turn, would not have to ask about commonplace things that can be read about.
The documentation was, but in insufficient quantity, as it turned out. As soon as they started using Status Hero, there were really more articles in the internal Wiki , articles began to edit and comment, even likes were entered in Confluence, and they began to complement the triggers in the monitoring systems that worked. We began to write more clearly, in human language, about what really happens there, who to call and where to look.
And that's not all. There is another aspect in which Status Hero also helps us.
Team contribution
Alexey Rybak spoke at HighLoad ++ with a story about the Review process at Badoo . This is a cool, mostly managerial thing, because they need to evaluate their staff: how we work, how the team works. From the point of view of the manager, this is a cool tool with which all information becomes structured.
From the point of view of the administrator - a simple employee - the opposite is true . It is almost like preparing for exams in a session. A week is allotted for filling out Review, for which you must write what you have been doing for the past six months. But usually this reaches the last day, which is spent almost all on re-reading your tickets for a long time, delving into them and writing something about your achievements.
So that the writing process of Review is not so painful, we are invited to fill out snippets . This can be done both at the end of the working day and at the end of the working week.

But, since we have already talked about the problem of context switching, it is obviously not always possible on Friday, for example, to recall what I did on Monday or Tuesday. At best, I will write what I did on Thursday and Friday, at worst it will be the last 3 hours of work on Friday. As for daily snippets - the working day can be different, and in the evening I want to go home to the pub - anything, but not to write about what I did today.
Here again, Status Hero comes to the rescue. We wrote in it every day what we promised to do and what we did. For the period that we need, we can simply make a selection of positive aspects - what we actually did.
Not only is this sample positive , there is another plus: in Status Hero we wrote for ourselves, and when we make a sample for writing a six-month report, then reading what we wrote for ourselves, you are immersed in the future in context. You do not need to go into tickets and remember what you did there, long or short.
It’s beautiful and wonderful, but
One day in the life of the admin
So that my claims that Status Hero are cool are not unfounded, let's look at one day in the life of the admin in Badoo. The situation is half-imagined, but quite real.

A person comes to work in the morning, for example, after the weekend. He rested and knows that he has a big project in the future. The first thing he needs to do to get started is to plan a working day. Let's say he decided to set up the infrastructure in a new data center.
We all remember very well about conscience and about the fact that if he promised on Monday, he will probably do it by Friday. But consider the ideal situation that the task closes within one business day.
The man wrote this and thought that in order to raise a new data center, he needs to configure the infrastructure for xCAT.
Here the guys join, who meanwhile came to work in London, and each of them adds that you still need to install Puppet - you won’t start without it, Consul is also needed, and how can it be without Docker, and glpi, and so on. There is not enough time to talk about each of these systems in detail; we will consider them briefly.
Our data center consists of five puzzle elements, on the basis of which we can begin to work further.

The first main management tool is iron , which has just arrived from the factory. He was put in a data center, mounted in racks. The administrator needs to update the firmware, install the OS, build Raid, and move the machine to the place where it will then work.
We have used and continue to use a product called xCAT, which contains a PXE server and a dhcp server. There we store the base of all our subnets, dns addresses, dynamic ranges and other information. For us, this is a server base, but a base in the server - name - mac address format - network interfaces and a fixed IP directly in the cluster in which it will be located if we transfer the server to the cluster.
It is important that xCAT provides the ability to monitor what is happening in the consolesservers. If some kind of Kernel Panic happens, then we get the impression from the monitor just in text form and then we can use it. That is, xCAT works in the format of a management node, which knows everything about everything, but can remove part of its load by passing it to a service node, on which we in turn raise the console server. If the data center will be small - conditionally 100 machines, then everything will fit on one management node, we will not raise the second. If the data center is large, there are many servers with consoles, we will take and simply horizontally increase the number of SNs and hook them all to the master. Therefore, xCAT SNs are in square brackets in the diagram.
In fact, the person who lifts the DC and sets up xCAT starts up one container with the management node, enters information about the new subnets that will be in this DC, generates a file with dhcp and informs network engineers if necessary that that for these subnets, dhcp helper will be on the new container.
In case it is necessary to raise the console server on a separate container, we start just the next one and everything becomes wonderful, at least we get basic configuration of the equipment.
Docker
I wouldn’t be me if I hadn’t said the word Docker here - I would have to remove my hat in the end. But I will not talk deeply about Docker, its infrastructure for any of our data centers looks something like this.

The essence of Docker here is not in itself, but in how the registry is arranged , because we need it in order to pull already further containers of our services from there. This scheme had several iterations while we implemented Docker and used it, but at the moment the registry working scheme in Badoo is in the form as shown above. All images, all layers and everything else we store in Ceph through the Swift API .
In order to store the cache from our registry, we use Redis. HTTP nodes, which are the Docker distribution service, we can scale horizontally as much as we like, the only condition is that we always need to route all docker-registry nodes to the same address of the Redis caching service and specify one endpoint for Ceph accordingly.
Before the HTTP service, nginx stands as a balancer, which terminates SSL, makes basic Auth. Next are our target servers, which access the registry in order to pull or push.
Consul
In modern realities, the new data center will definitely need Consul, which is currently being used, rather than as a service discovery for the whole Badoo, but as a service discovery for the infrastructure part .
Demonstrating what the basic installation of Consul looks like in any of the data centers probably makes no sense. This is usually at least 3 master servers and synchronization with all available data centers.
Why infrastructure, especially the new Consul data center?
Puppet
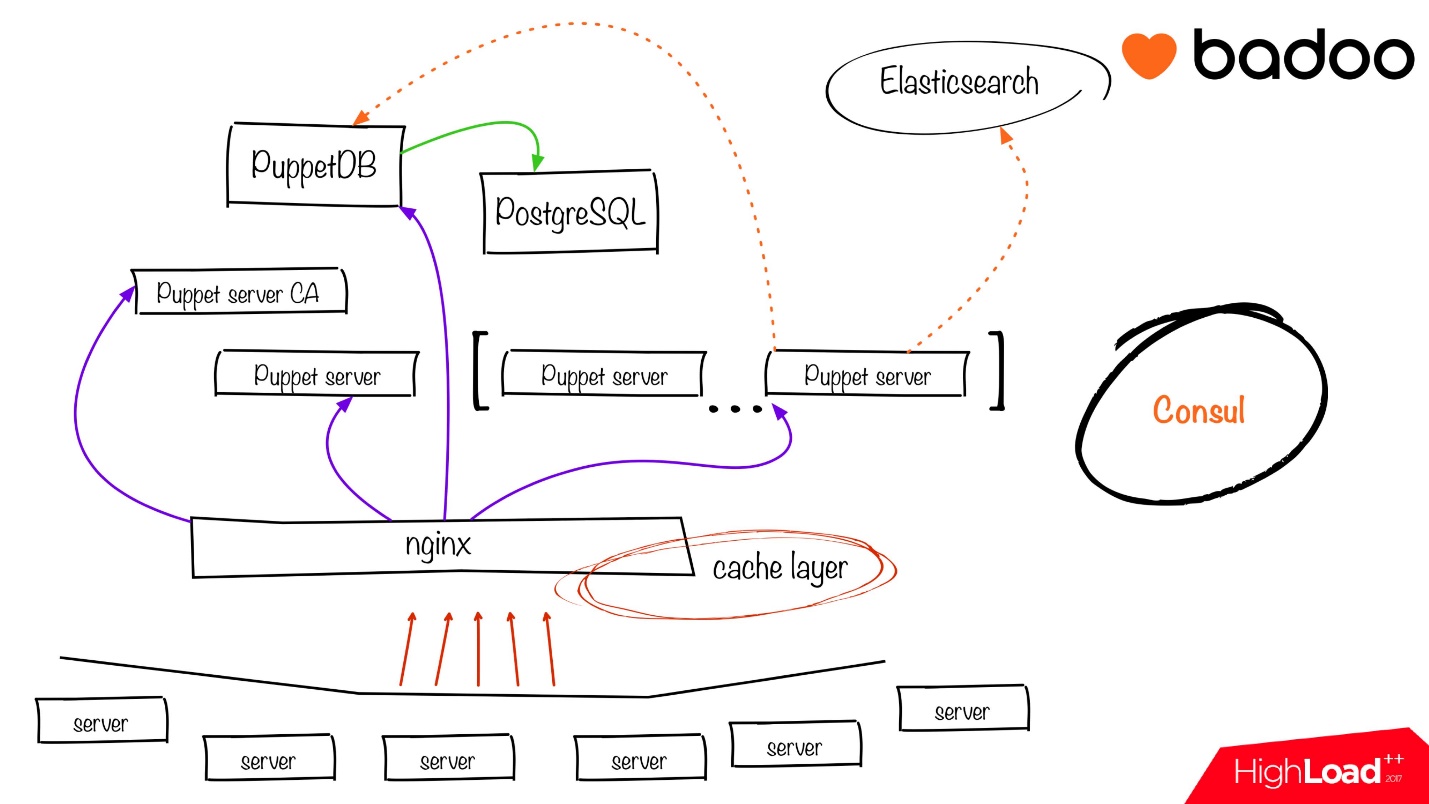
Let's take a look at our wonderful Puppet infrastructure.
The essence of Consul here is that we raise the infrastructure from top to bottom (if you look at the slide above):
All other clients go through load balancing.
GLPI
We have such a thing called glpi, it is necessary for any data center. Everything is quite clumsy and simple - this is a service for inventory .
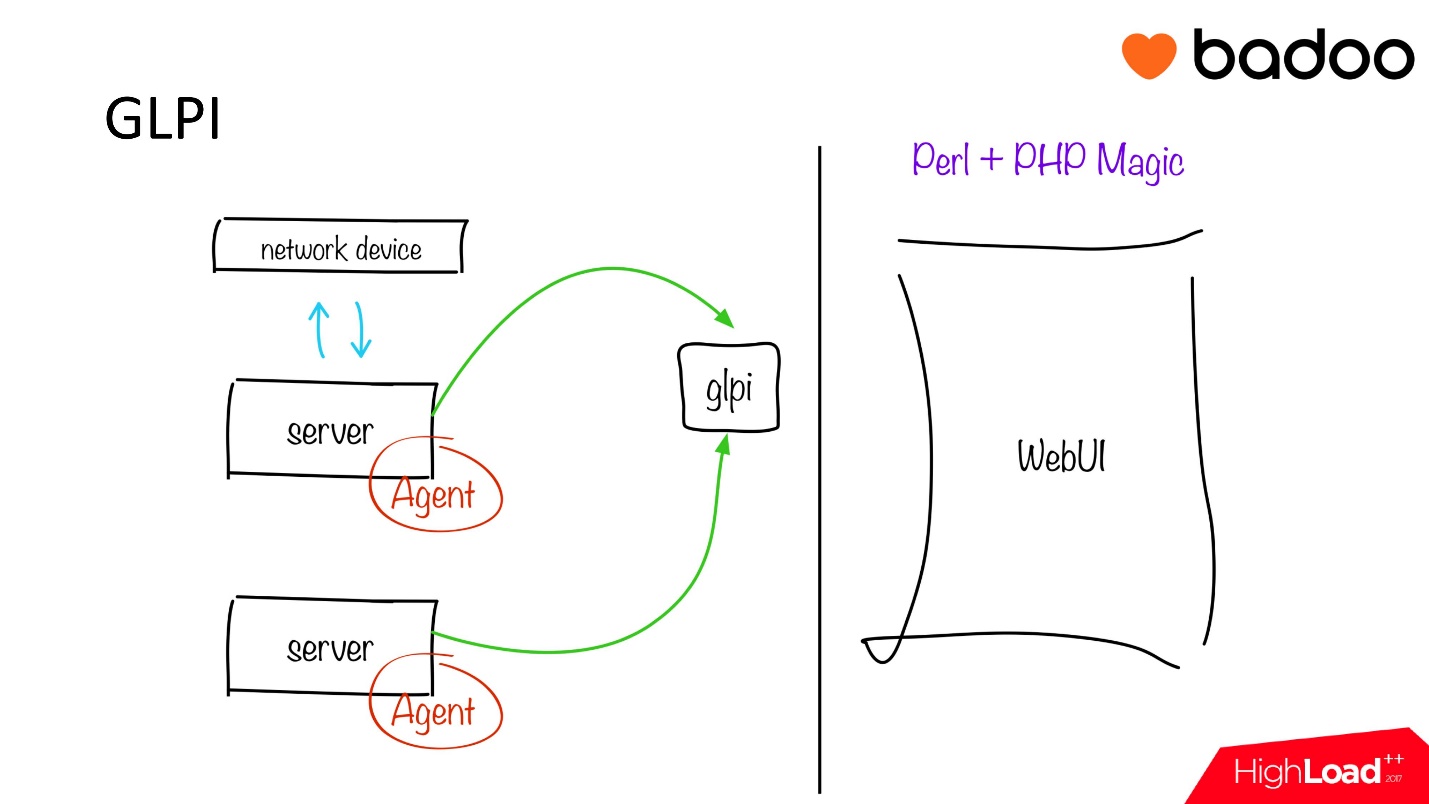
It works as follows:
Another advantage of using GLPI and FusionInventory is that we can inventory not only server hardware, but also network equipment, in order to get information about which ports are available and what speed they are on, and most importantly, which server with which serial, being located in which rack, connected to which network node and to which ports. The result of all this action is a web page where you can watch all this information.
We examined 5 tools that were described in our Wiki, our hypothetical admin looked at them and launched no more than 3-5 containers for each - the infrastructure is ready. We got a house of happy people who work productively: one task was outlined, others helped him, by and large we got acquainted, read, and lifted such a thing.

In Badoo, there are more such men with balls in the team of admins, but we are productive and definitely happy for the most part. We managed to create our team of friendly professionals, because we were able to identify three problems and learned how to deal with them.
So, what is necessary for the performers (it seems to me, not only for the admin):
When you increase the transparency of work in the department, the problem of updating the documentation is solved by itself, because you see what iterations are happening, and you are constantly asked: “Update, update, update.”
References
These are links to various studies on the topic of context-switching, how to work competently, how not to be distracted and do more, as well as links to all the products that I talked about that are the basis and support of any of the Badoo data centers.
Anton loves infrastructure tasks and automation of everything that can be automated, so his story is based on the example of setting up infrastructure in a data center and related technologies Docker, Consul, Puppet ...). But aspects that interfere with quality work and how to solve them are as universal as possible and suitable for almost any executive team. So we ask you for a cut for decoding this report.
Badoogrowing every year, here are a few numbers that reflect this: 350 million messages per day, 364 million registered users worldwide, 300 thousand new users per day. But this is far from the most important thing, for the person who works at Badoo, the main thing is first of all a way of thinking and a team. Badoo is a family, it's about people and it's cool!
I want to start with a provocation that someone might not support:
Admin is the main person in the company!
I think you will agree with me: the admin is the person without whom nothing in the company will work: the equipment comes to him, he puts in the system, he allocates new equipment again. Therefore, I believe that he is the main one.
I will give an example from personal practice in Badoo. Judge about this situation yourself: we had a new project called ReThink. We updated our logo: changed the font and color of letters from multi-colored to purple, added a heart - monotonous and cool. But the admins were warned that ReThink would happen - we just take it and switch it - we warned the last night almost before going home. And here a somewhat unpredictable load in one of the clusters started to hit. Thanks to the person who was on duty and helped the rest of the team just to find additional servers and finish them. The project actually shot, we did not fall, rolled out normally and everyone was happy.
In confirmation of my words, I want to say that a happy and productive admin in the company is, among other things, profitable and interesting for the company.I would like to ask all companies to make their admins happy . Then you will be fine!
Let's think about what makes the admin sad . It will occur to many that the admin is sad from a crashed server and lost backups. This is all true, but if the admin would think and go into sadness every time when he did something wrong - and he does something wrong every day - he wouldn’t have enough nerves.
Therefore, I denote the problem, which is a certain human factor, namely, context switching.
Context switch
There is a fairly large number of studies on what happens when a person is torn off, and why it is bad. One of the last good studies is the work of Chris Parnin , a fellow at Georgia University of Technology. He collected a bunch of different data on this topic and made a lot of conclusions, the main of which is:
A person who has been torn from work on a task takes 10-15 minutes to return to it.
This is an average figure. Someone may have more, someone else less, depending on the switching. With a simple addition, you can find that if you were distracted 4-5 times in one hour by something, an entire hour of working time is likely to be lost, and you are unlikely to do your job.
This is a theory - a person investigated, came to conclusions. In practice, you probably faced this situation: you come to work, spent the whole working day in a booze - did everything all day, did not have time to have lunch, did not answer the instant messengers and mail. By the end of the working day you are all tortured, it seems to you that you have done a lot of everything. But at best, in the evening you realize that you didn’t do halfwhat was planned for the working day. Worse, when a manager or colleague approaches you and asks: “What did you do today?” And you understand that you ran, ran, ran - but there is nothing at the exit .
In many respects, this comes from switching our context and the inability to concentrate on the task. For the admin - a simple performer - this is so.
But there are still managers / team leaders and the flip side. The key feature of team leaders is that they, like maniacs, this context-switching is not something that they can survive, but even they sometimes increase it to reduce it later. That is, they focus many meetings with this switch for several hours, and then rest in the evening, working on one task. The switching skill can be developed to the point that it takes only 5 minutes to immerse yourself in a new task. This is very cool, and for the fact that they know how to do it, managers can be appreciated and respected. But for the administrator and the performer it is better to get rid of the switches .
Process opacity
The second important problem is the opacity of the processes, which can be divided into two zones:
- opacity of processes within the team ;
- opacity of processes outside the team .
Inside the team, this is what we can influence: shortcomings or lack of coordination between team members. The worst thing that the opacity of processes within a team can lead to is duplication of work . In principle, this is not bad, apart from the fact that you are losing, most likely, the working time of one of the employees.
Here you can find the pros and say: “Perhaps Vasya did better than Petya! Let's take his decision. ” But they could talk among themselves, and someone would do one. It is important.
If non-transparent processes are outside the team, for example, as a whole something is happening incomprehensibly in the company, inside the team this can lead to incorrect prioritization of tasks.
For example, a developer from the mobile web came to me and said that it’s important for him to pick up a service that will give something for the new API today. I have many other tasks, and it does not seem to me at all that his task is a priority. He was waiting for his release for a week, he will wait another two days, I will do it later. For business, this is not always the case. If a team comes to us from above that the current task has high priority, because it is part of a very large next task, it is important that this is not even conveyed by the manager, but that each member of the team understands this simply without further ado .
From the point of view of the performer and admin, I would like to build my story today to solve these two main problems within the team. I’ll talk about how we found a few rules in order tominimize context switching and make processes as transparent as possible .
How to solve the context switching problem
The admin came to work, drank a cup of coffee, read the mail, backups work, nothing fell - sit, work, which can interfere.
Consider the usual situation. The man came fresh, everything is fine, he opened his working tools, wrote in a chat and in the mail, and then the phone rang - they asked what had fallen at night - he was distracted. Then the wife or girl posted a cool photo - you need to go in and out, and Facebook is also moving. Here friends come to discuss yesterday's football meeting, they call me in the evening to drink beer or now tea. And all this comes to a person from all sides little by little.
What to do with this problem? We have a person, there is his general social life, there is its working aspect. In this case, we can only consider and optimize the part that concerns itworking tools . We cannot forbid him to go to drink beer after work or to use social accounts, because we are not in prison after all.
Therefore, we decided to look at what kind of working tools the administrator has, where he is often pulled from, and what we can do to reduce this.
The first idea is rather strange, but we tried it - to allow the administrator to simply not use the chat , because a lot of people write to the chat. You are working on a task, and one wrote to you that this is important to him, the other - that it is important to him. And we allowed the admins not to use chat - not to answer and not to write anything there.
The idea, of course, did not take off, because in addition to writing what you need to read in the chat, chat is the fastest way to communicate. You just need to write there. Just a week later, it became clear that the idea was utopian, we decided to abandon it and went further.
We made a partly strange decision - we single out one member of the team and told him: “Dude, you will be a conditional leader! This is not a promotion, you just know a lot about which of your colleagues is good in which field, you know the general stream of tasks and more or less about priorities. Therefore, come on, you will work according to the following scenario. There is a pool of tasks that fall on all the admins in the team, you see who is busy with what, you know what the deadlines are for the task, and you can always give it to the person who can handle it as quickly as possible; or, if there is a lot of time for execution, you can assign it to the junior. Junior needs to tell basic things, but you know that if they help him, he will be pumped and everything will be cool. ” In principle, the idea is quite robust.
One of the reasons why she didn’t completely go in is because we all admins love to work on what they like. We can do tasks when everything is on fire and we have to do it - we don’t understand, we take and do, no matter who. Another thing is when you have a choice: "I am currently working on one task and want to configure replication in MySQL, I don’t want to touch Puppet - let someone else do it."
People began to burgle, for some there are few tasks, for many there are, for some people they get uninteresting - something so incomprehensible and inexplicable. Perhaps this was our miscalculation, but this approach did not work.
Around the same time, we are trying to load the Arbitrator with another duty. To the admin team, other teams are tasked with doing something - backup, restore, etc. A person with such an application is, in fact, a client, and he is always waiting for feedback. When, having set a task, he sees that the task has switched in the general pool from the status “not assigned” to “assigned” to a specific executor, 2-3 hours have passed, one working day, another, and the task has no beats, it’s not clear at all engaged in his task or not.
There are administrators who do not really like to conduct their tasks in the form of correspondence. Therefore, the Arbiter now needs to arrange one-to-one meetings with each member of his team, conduct almost every task, ask if there are difficulties on the task, how to help, and summarize the information collectedevery 1-2 days.
Tasks began to be carried out somehow. But everything stalled, because our current Referee simply buried in so much knowledge . Indeed, in order to summarize something for you, you need to understand each subject area, think of what stage an employee has reached, what is stopping him, and write this. When there are a lot of such tasks, the Referee simply stops writing something, and the tasks cease to be conducted in the same way. Therefore, it was necessary to move on and change something again.
Eisenhower matrix
You may have already seen this matrix, you just don’t know the name. The bottom line is that we divide the task sheet into 4 parts according to two parameters:
- urgently / not urgently;
- important / not important.
We simply throw all our tasks into this wonderful tablet and start working.
It is worth noting immediately that cell B , the most productive and comfortable for the performer, is an important and not urgent task. This is a great motivator for a person when your task is important either for the team, or for the project, or just for you. You understand that you are working not just on some kind of nonsense, but on what people will use, and this adds an incentive. The plus of non-urgency is that you are left to your own devices. Do you have time to read, test, make some calculations.
We sat, thought and came up with the idea of separating all the tasks coming into the operation department, and format tasks are not very important and not very urgent to separate into a separate project, which we calledITGROOVE . Here we included tasks that, in the future, maybe someday will really turn into a problem, but now they are not a problem, and it would be nice to do them in some foreseeable future - a week or two.
After that, we introduced the function of the day duty administrator , the essence of which is as follows. We have the first line of support and response to emergency operations and triggers, monitoring. If she can’t cope with the problem and decides what needs to be escalated, then the first person who gets involved in solving this problem in the daytime is the day duty administrator.
If before that I told you that we are getting rid of the influence of context switching, here we are simply throwing a person at the embrasure and telling everyone to do everything in a row, switch as soon as you can.
In fact, this is not entirely true, because the day-time administrator on duty performs the following actions: either escalates the problem and passes it to the best specialist of the department in this subject area, which is currently available, or almost automatically fixes the problem. This is not mental activity - wake a person at night, he will go and fix it.
As an added bonus, we offered the day duty officer, if he had nothing to do and was bored, to work on the ITGROOVE project. Not only does the person cover the rest of the team, he also closes unimportant and non-urgent tasks!
By introducing the role of the day duty officer and dividing the tasks into completely unimportant and project ones, we allowed the rest of the team to work in the most comfortable zone B on non-urgent, but important tasks. People just emerged from point A, looked around, and there is point B - and I feel comfortable, and everyone is happy - it's cool! Will be working!
I will not disregard the tasks from point C. It sounds somehow delusional: “Urgent, but not important” - either urgently or not important. In our case, usually work in this segment does not occur. Tasks with the criteria “not important, but urgent” either become “not important and not urgent”, or simply disappear, and we do not work on them.
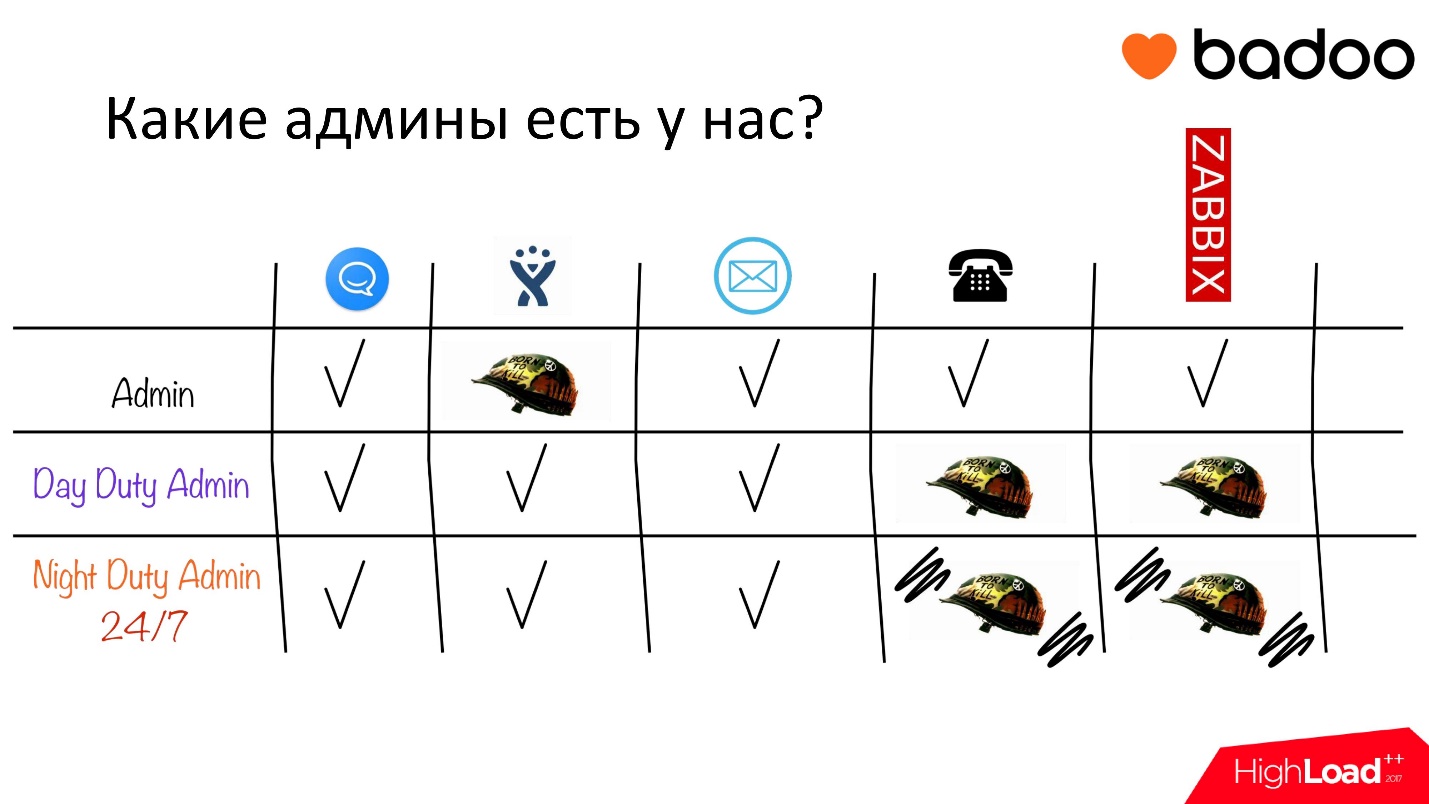
Since I touched on the fact that we introduced the role of a daytime administrator on duty, let's briefly go over what administrators we generally have:
- The admin is ordinary. In principle, everyone always does everything, but the ordinary admin primarily works on tasks in Jira.
- The day-time administrator on duty mainly answers the phone and escalates from monitoring.
- The night administrator on duty - a mixture of the ordinary and daytime administrators - answers calls and escalations at night, and works as an ordinary admin during the day.
How to make processes transparent
The complexity of our specific team lies in the fact that one part of it is in London, the other in Moscow, this is a fairly large shift in time zones. In Moscow, the guys begin to work much earlier, in London they just come to work, and they have already done something. In turn, we at the London office, finishing up in the evening, are doing some other things that people in Moscow did not know when they went home. To coordinate processes within the team, we have a weekly Monday rally.
It looks like this:
- We occupy one meeting room in Moscow, one in London.
- Moreover, the time is set so that in London they just came to work, and in Moscow they already returned from lunch. Everyone needs about 40 minutes to tune in to a worker. Therefore, we gather in an informal atmosphere on TV, take an agent and begin to discuss.
- This is a many-to-many discussion. We tell each other what important projects we have done, what we expect, what we plan to do, make appointments for each other.
But the problem is that somewhere by the evening of Tuesday or the morning of Wednesday, coordination is a little lost . For example, I started working on a task, stepped aside, I have different tasks for this week, something similar happens for a colleague from Moscow. We will be out of sync until next Monday, until the next auction - something needs to be done.
Status hero
There is a cool tool called Status Hero . Its essence is that when you come to work, you plan for yourself certain tasks. Status Hero has 3 fields to fill out. Moreover, this is not a mandatory tool, we can not fill it in and not use it.
The trick is this: I came to work fresh, and I know that today I want to fix some DNS, set up metrics reset in Prometheus, see how new charts work, and possibly close current tasks. I fit all this into the plan for today.
But a line flickers over my plan for today, which says that yesterday you promised yourself to do this, and come on, you first write what you did yesterday from what you promised, and then what you will do Today.
Also there is a wonderful third point. This field is to indicate some external events that block the execution of tasks . For example, someone from another team did not provide you, it doesn’t matter what - a patch, fix, the necessary data to do the job, and you are a shy guy and you can’t call and demand him. Now you can write something like this here, it will be highlighted in red, and either the manager or the guys from the team will help you. That is, you will voice your problem , and you won’t sit silently and wait for a problem independent of you to be solved and you will be able to do your job.
In turn, the team also sees this. We have a special group in HipChat, where after someone has filled out a form, it is shown to the whole team. A person with a cursory glance is enough to view the chat and understand what his colleagues will do. If suddenly there is some kind of blocker that he can resolve and thereby help his colleague, then he does it. That's cool!
Why does Status Hero work?
- The most important aspect is what you promise yourself . From practice, I can say that if you promise yourself from Monday to Friday, then most likely by Thursday you will make at least one of the points that you wrote on Monday. Every day, Status Hero will be an eyesore to you and say: “Promised - did not!” And your colleagues also know whom you actually promised, so you take and do just by force.

- The next positive point is that the resulting transparency makes it possible to help each other . When I see that, for example, my colleague is going to perform a certain task, in which my knowledge is perhaps more, or I can just help with something, I say: “Come on, I will help you. I know where to send the documentation and what to read, or do it right away so as not to lose a couple of days of work. It will be better for you. "

- Now those quiet people who sat and did not say that something was stopping them from working can also write quietly and they will be helped. Perhaps some problem will be solved, which otherwise could not be handled.
Status Hero revealed the problem
But not only did Status Hero help us organize this activity, it also revealed one rather strange problem for us. It consisted in the fact that at that time the operational documentation either did not exist at all, or it was not enough.
You managed to understand this approximately when you began to see what colleagues were working on, to help them and tell how to do something. When you explain the same thing for the sixth time , you understand that if you wrote it once, your colleague would go through the script once, make corrections and comments, and that’s all - there would be no need to be distracted by the explanations six times . A person, in turn, would not have to ask about commonplace things that can be read about.
The documentation was, but in insufficient quantity, as it turned out. As soon as they started using Status Hero, there were really more articles in the internal Wiki , articles began to edit and comment, even likes were entered in Confluence, and they began to complement the triggers in the monitoring systems that worked. We began to write more clearly, in human language, about what really happens there, who to call and where to look.
And that's not all. There is another aspect in which Status Hero also helps us.
Team contribution
Alexey Rybak spoke at HighLoad ++ with a story about the Review process at Badoo . This is a cool, mostly managerial thing, because they need to evaluate their staff: how we work, how the team works. From the point of view of the manager, this is a cool tool with which all information becomes structured.
From the point of view of the administrator - a simple employee - the opposite is true . It is almost like preparing for exams in a session. A week is allotted for filling out Review, for which you must write what you have been doing for the past six months. But usually this reaches the last day, which is spent almost all on re-reading your tickets for a long time, delving into them and writing something about your achievements.
So that the writing process of Review is not so painful, we are invited to fill out snippets . This can be done both at the end of the working day and at the end of the working week.
But, since we have already talked about the problem of context switching, it is obviously not always possible on Friday, for example, to recall what I did on Monday or Tuesday. At best, I will write what I did on Thursday and Friday, at worst it will be the last 3 hours of work on Friday. As for daily snippets - the working day can be different, and in the evening I want to go home to the pub - anything, but not to write about what I did today.
Here again, Status Hero comes to the rescue. We wrote in it every day what we promised to do and what we did. For the period that we need, we can simply make a selection of positive aspects - what we actually did.
Not only is this sample positive , there is another plus: in Status Hero we wrote for ourselves, and when we make a sample for writing a six-month report, then reading what we wrote for ourselves, you are immersed in the future in context. You do not need to go into tickets and remember what you did there, long or short.
It’s beautiful and wonderful, but
“Theory without practice is dead, practice without theory is blind”
A. Suvorov
One day in the life of the admin
So that my claims that Status Hero are cool are not unfounded, let's look at one day in the life of the admin in Badoo. The situation is half-imagined, but quite real.
A person comes to work in the morning, for example, after the weekend. He rested and knows that he has a big project in the future. The first thing he needs to do to get started is to plan a working day. Let's say he decided to set up the infrastructure in a new data center.
We all remember very well about conscience and about the fact that if he promised on Monday, he will probably do it by Friday. But consider the ideal situation that the task closes within one business day.
The man wrote this and thought that in order to raise a new data center, he needs to configure the infrastructure for xCAT.
Here the guys join, who meanwhile came to work in London, and each of them adds that you still need to install Puppet - you won’t start without it, Consul is also needed, and how can it be without Docker, and glpi, and so on. There is not enough time to talk about each of these systems in detail; we will consider them briefly.
Our data center consists of five puzzle elements, on the basis of which we can begin to work further.
The first main management tool is iron , which has just arrived from the factory. He was put in a data center, mounted in racks. The administrator needs to update the firmware, install the OS, build Raid, and move the machine to the place where it will then work.
We have used and continue to use a product called xCAT, which contains a PXE server and a dhcp server. There we store the base of all our subnets, dns addresses, dynamic ranges and other information. For us, this is a server base, but a base in the server - name - mac address format - network interfaces and a fixed IP directly in the cluster in which it will be located if we transfer the server to the cluster.
It is important that xCAT provides the ability to monitor what is happening in the consolesservers. If some kind of Kernel Panic happens, then we get the impression from the monitor just in text form and then we can use it. That is, xCAT works in the format of a management node, which knows everything about everything, but can remove part of its load by passing it to a service node, on which we in turn raise the console server. If the data center will be small - conditionally 100 machines, then everything will fit on one management node, we will not raise the second. If the data center is large, there are many servers with consoles, we will take and simply horizontally increase the number of SNs and hook them all to the master. Therefore, xCAT SNs are in square brackets in the diagram.
In fact, the person who lifts the DC and sets up xCAT starts up one container with the management node, enters information about the new subnets that will be in this DC, generates a file with dhcp and informs network engineers if necessary that that for these subnets, dhcp helper will be on the new container.
In case it is necessary to raise the console server on a separate container, we start just the next one and everything becomes wonderful, at least we get basic configuration of the equipment.
Docker
I wouldn’t be me if I hadn’t said the word Docker here - I would have to remove my hat in the end. But I will not talk deeply about Docker, its infrastructure for any of our data centers looks something like this.
The essence of Docker here is not in itself, but in how the registry is arranged , because we need it in order to pull already further containers of our services from there. This scheme had several iterations while we implemented Docker and used it, but at the moment the registry working scheme in Badoo is in the form as shown above. All images, all layers and everything else we store in Ceph through the Swift API .
In order to store the cache from our registry, we use Redis. HTTP nodes, which are the Docker distribution service, we can scale horizontally as much as we like, the only condition is that we always need to route all docker-registry nodes to the same address of the Redis caching service and specify one endpoint for Ceph accordingly.
Before the HTTP service, nginx stands as a balancer, which terminates SSL, makes basic Auth. Next are our target servers, which access the registry in order to pull or push.
Consul
In modern realities, the new data center will definitely need Consul, which is currently being used, rather than as a service discovery for the whole Badoo, but as a service discovery for the infrastructure part .
Demonstrating what the basic installation of Consul looks like in any of the data centers probably makes no sense. This is usually at least 3 master servers and synchronization with all available data centers.
Why infrastructure, especially the new Consul data center?
Puppet
Let's take a look at our wonderful Puppet infrastructure.
The essence of Consul here is that we raise the infrastructure from top to bottom (if you look at the slide above):
- To get started, you need PostgreSQL, which in turn will be needed for PuppetDB.
- Raising PostgreSQL, we register it in Consul. Raising PuppetDB, we take information from Consul about PostgreSQL, connect to it and pass the information about PuppetDB back to Consul.
- Next, we raise the required number of Puppet-server nodes in Java. We take information for them from Consul, we put information about them in Consul.
- At the last stage we raise load balancing to nginx, which deals with SSL termination, serves 3 ports:
- port for direct Puppet agents;
- port for Puppet DB;
- port for statistics.
All other clients go through load balancing.
GLPI
We have such a thing called glpi, it is necessary for any data center. Everything is quite clumsy and simple - this is a service for inventory .
It works as follows:
- На каждом сервере запускается простой FusionInventory Agent, которые собирает всю информацию по железу, софту, антивирусам, файловым системам — все зависит от настроек. Нам обычно интересны всякие «железные» показатели: какой памяти сколько, какие диски, контроллер, кэш и т.д.
- Эту информация через определенный временной интервал (в нашем случае раз в сутки) отправляется на некий PHP endpoint, в котором происходит обработка и передача данных в glpi базу данных.
Another advantage of using GLPI and FusionInventory is that we can inventory not only server hardware, but also network equipment, in order to get information about which ports are available and what speed they are on, and most importantly, which server with which serial, being located in which rack, connected to which network node and to which ports. The result of all this action is a web page where you can watch all this information.
We examined 5 tools that were described in our Wiki, our hypothetical admin looked at them and launched no more than 3-5 containers for each - the infrastructure is ready. We got a house of happy people who work productively: one task was outlined, others helped him, by and large we got acquainted, read, and lifted such a thing.
In Badoo, there are more such men with balls in the team of admins, but we are productive and definitely happy for the most part. We managed to create our team of friendly professionals, because we were able to identify three problems and learned how to deal with them.
So, what is necessary for the performers (it seems to me, not only for the admin):
- Уменьшать переключение контекста. Дайте человеку работать — если он технарь, пускай сидит и работает, не отрывайте!
- Делать процессы прозрачными. Если вы срываете сроки и есть подозрение, что что-то не так приоритизацией задач, дайте команде информацию о том, почему конкретная задача важна. Человек должен видеть дальше своего монитора, и знать, что его участие в проекте важно. Тогда он будет работать иначе, он будет понимать срочность и полезность своей работы.
- Write good documentation. Moreover, it is good if this documentation is divided into different parts. It can be detailed and deep, if you want to get acquainted and burrow. But at the same time you should have an excerpt about the service or service, which is placed on one page and contains a set of 5-6 actions that must be done before escalating. Moreover, the documentation is important to always keep up to date.
When you increase the transparency of work in the department, the problem of updating the documentation is solved by itself, because you see what iterations are happening, and you are constantly asked: “Update, update, update.”
References
These are links to various studies on the topic of context-switching, how to work competently, how not to be distracted and do more, as well as links to all the products that I talked about that are the basis and support of any of the Badoo data centers.
- Why developers hate being interrupted ,
- Programmer Interrupted ,
- Interrupts: just a minute never is ,
- A diary study of task switching and interruptions ,
- No task left behind ?: examining the nature of fragmented work ,
- xCAT ,
- GLPI , FusionInventory ,
- Puppet ,
- Consul ,
- Status Hero .
The Siberian version of the conference for developers of high-load projects Highload ++ Siberia will start on Monday and will take June 25 and 26 . At it, Anton will talk about the evolution of tools and services in service with the Badoo operating team,
and another 30 recognized experts and representatives of industry leaders will present their experiences and share experiences - see the program .