How we conduct experiments on people. A / B testing for advanced

In biology and medicine, many experiments on humans and other higher primates, as you know, are now prohibited. But in marketing and product management, this is not yet forbidden. What we actively use in ID Finance, conducting multivariate tests of value offers, product features, interfaces, and more.
A / B testing in our company is widespread and especially perverse. Tests are carried out by us all, with the exception of lawyers and accounting. But the problem is that these experiments are usually much more complicated than what is usually understood by A / B testing - changing the button color, moving the fields, redesigning the landing page - something that can be easily done through frameworks such as Google Analytics or Visual Website Optimizer. In our case, large pieces of the customer journey are changing, and a significant part of the main business metrics can catch such a test.
As a result, the correct conduct of such tests, and, most importantly, the correct summing up of their results, has become a kind of art, accessible to a few enlightened ones. Which, of course, is not good. In the end, we decided to start collecting recommendations and examples in order to help business analysts and managers do everything right. Indeed, mistakes are quite expensive: in the best case, we will lose time collecting data curves and restarting the test, in the worst case, we may make an erroneous business decision. At the same time, the company is growing, new people come and I want to reduce the learning curve as much as possible.
In my opinion, our experience and the path that we went to accumulate it can be quite applicable in your company. Especially if:
- you have a difficult customer journey;
- its different parts are interconnected, and often key metrics change in different directions;
- you want to conduct complex experiments that have a complex effect.
In order not to go straight to generalizations, I would like to first lead you through a sequence of selected cases. I tried to choose such examples from our practice in which the obvious obvious conclusion was not true. Having examined the problems in this way, we can already more preparedly move on to conclusions and recommendations.
Our way of samurai user
To set the context for the further story, we will briefly consider the main stages of our client’s life path.
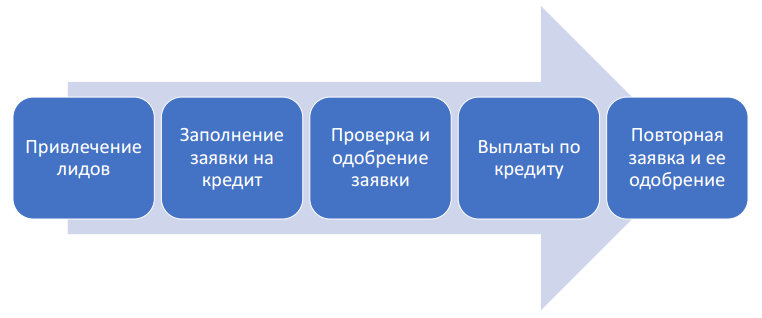
As is customary in any decent e-commerce, we attract customers through online (and sometimes through offline) channels to our website, where they register and fill out a loan application. Filling out an application is a rather complicated and responsible process, the client must provide a lot of information so that we can make an informed decision about (not) providing him a loan. Actually, consideration of the application and verification of the client is the next step. After the issuance of money begins a "fundraising" campaign for their return. But after successfully repaying the loan, the client usually comes for the following: the return on our projects is in the region of 80-90%.
The table below shows several directions for experimenting in the context of the stages of the client’s life cycle.
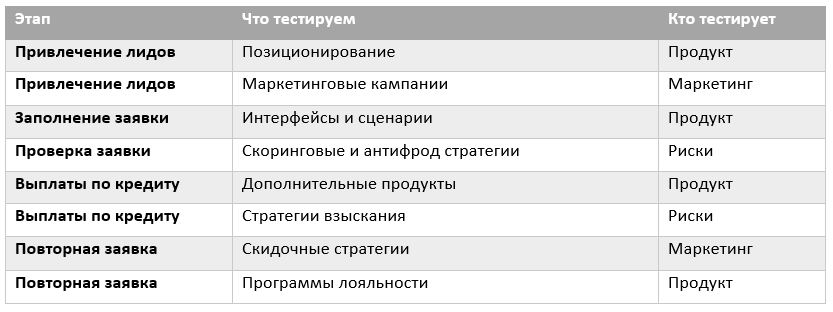
In general, there is where to roam. Now let's see what rake you can step on.
We start with a simple: Landing test
I will not deviate from tradition and give a fairly classic example in our performance of testing a landing page in a specific marketing channel.
Below are two options for this very landing. Without reading further, try to guess which option gives the greatest conversion in the next step?
Option A
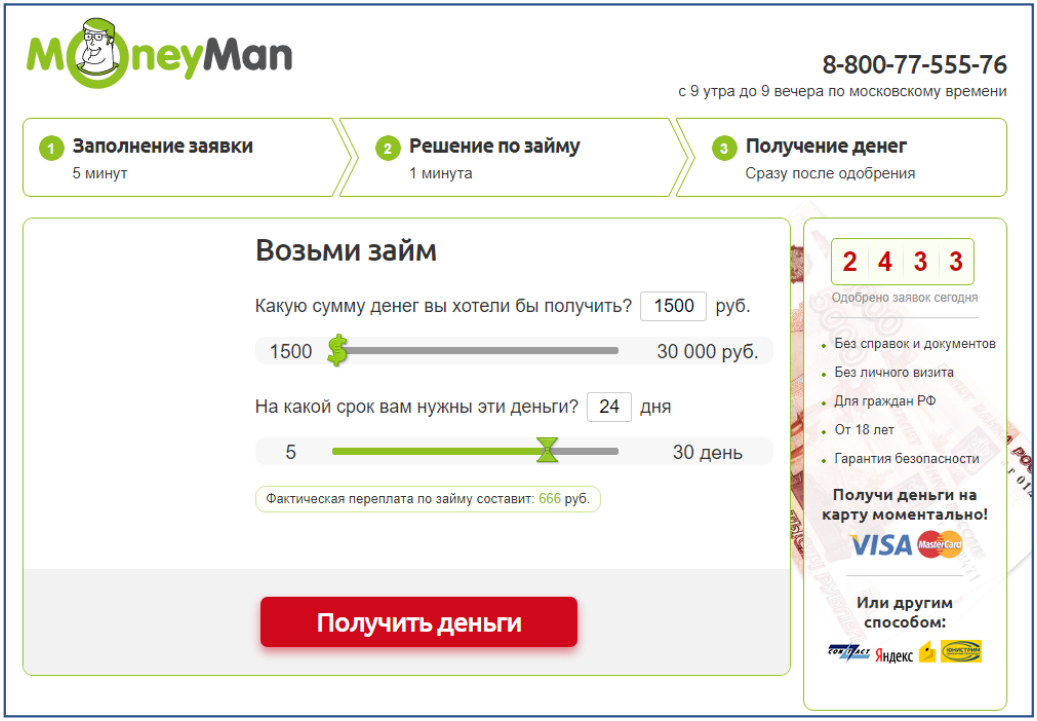
Option B

And which option did we choose for future use?
The trick is that the answers to these two questions are different. You can verify this by looking at the conversion change in the steps of the funnel for applying for a loan:

The conversion to the next step is higher in option B, because all that is required of the user in this case is to press a button. It's simple and fun: clicked - and already at the next step. But there, the future client is already waiting for numerous questions about his personal data. Well, actually, in one step, the application does not end. As a result, we have a quick fading of customer motivation and a deterioration in conversion at all other steps, while in option A the borrower seems to have realized more deeply and got a bigger crush to get to the end.
Thus, the end-to-end conversion, unfortunately, has not improved, despite the improvement in the passage of the landing. We come to our first conclusion:you need to look at the entire part of the life cycle that the test affects, and not just the conversion directly at the exit from the experiment (the piece that we, in fact, changed).
I do not want and I will not
The next case is also associated with an attempt to increase conversion (for example, our Spanish project).
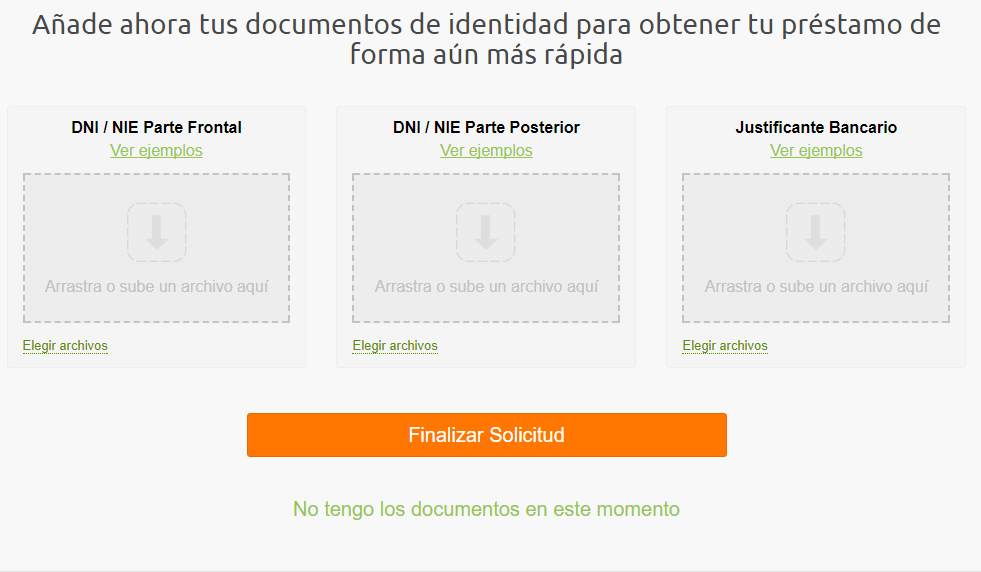
In some countries, we have the step of uploading photo documents (like the one presented above). The experiment was to move this step, which was initially in the middle of the application process, to the end and make it optional. The calculation was that right at the moment clients might not have the necessary document and they would send it later.
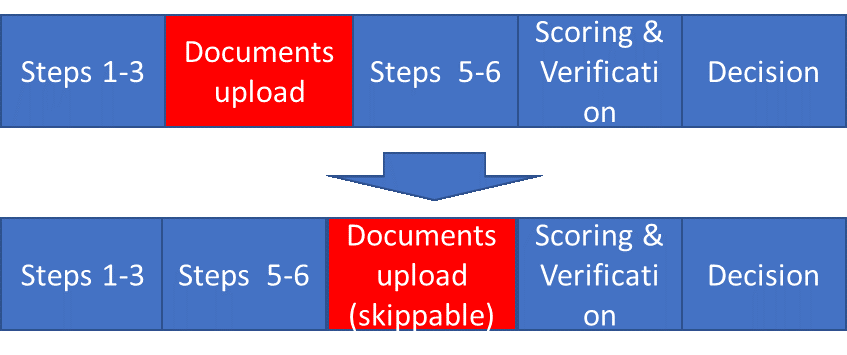
As a result, as expected, the funnel conversion increased by some x%. But, at the same time, the number of loans issued increased only by% <x%. Where did this difference come from? The fact is that some clients who skip a step, as well as in the future, at the verification stage could not (did not want to) provide photo documents. As a result, the metric we call the “approval level” has decreased - the ratio of the number of loans issued to requested. The situation is complicated by the fact that one department is responsible for the conversion of the funnel, and another is responsible for the level of approval.
As in the previous example, the main thing here was to determine the part of the life cycle that the test influenced and determine the target metric to look at. In this case, the effect of the test can be modeled in the following simple way:
Credits = Leads * Conversion * Level of approval
i.e. if the cumulative effect on the issuance is positive, then there will be a change, otherwise it will not. So we usually solve the contradictions between departments.
Who has a landline phone?
So at some point we thought that not everyone has a landline phone now, and decided to test the form without it (hereinafter, the Polish project).
The problem is that a landline telephone is a good tool to reach out to a client (you won’t throw it away so easily, it’s tied to an address, etc.). Therefore, as expected, in the variation without a phone, the return on loans fell slightly.
Conversion is growing, and collection is dropping. How in this situation to understand which option is better? To answer this question, we had to model the unit-based economy of the loan in sufficient detail.
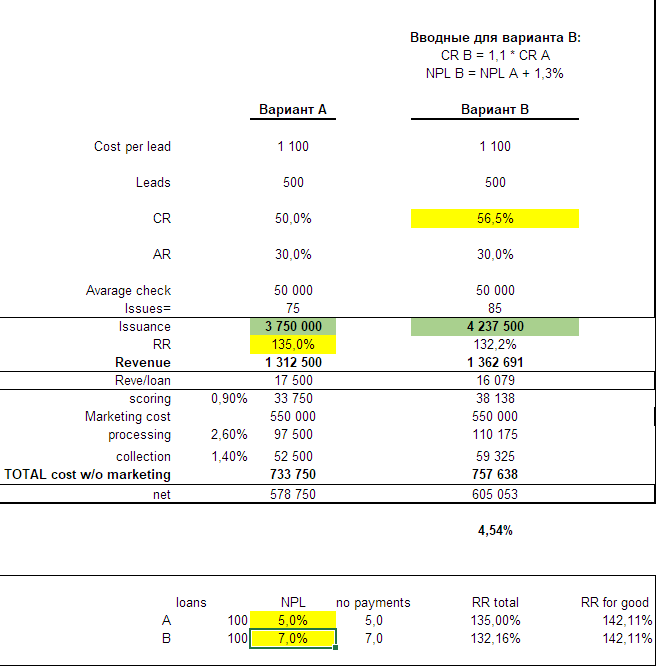
The picture above is full of all kinds of obscure numbers, and thanks to this, I suppose, it well illustrates the level of difficulty that we have to deal with periodically, although it all started with such a seemingly trifle thing as removing one field from one of the form steps.
In short, the economic effect boils down to the fact that an increase in conversion reduces the share of marketing costs in the unit economy, which compensates (or not) for a decrease in profit due to a deterioration in customer contact. A bit of math, and we figured out which option is better. Although I had to wait for this for almost two months - it was necessary to collect statistics on collection after the date of the 1st loan payment.
Forgotten Customers
Once, a long time ago, one of the steps of registering a client on our Kazakhstan project looked like this:
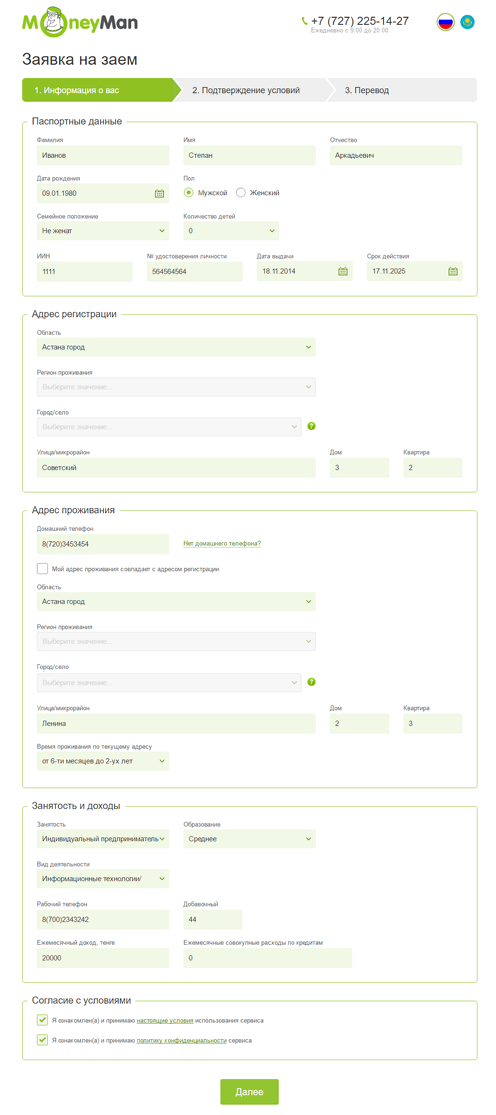
We (just like you just) thought that this sheet was too long, and this could scare off morally unstable clients. An alternative option in the experiment was an interface in which each subsequent block was shown only after successfully filling the previous one.
Conversion by result increased, although not as much as we expected, and we switched traffic completely to the new option. It would seem, happy end, the play is over and the curtain is omitted, but no.
After some time, we accidentally discovered that there are some users who convert very poorly. When they began to sort it out, it turned out that these users were visiting some strange page that didn't seem to be in the funnel. Although, wait a minute, somewhere I already saw this URL ....
The fact is that the system worked in such a way that if a client didn’t immediately go through all the steps of submitting an application and left the site, and then returned and wants to continue, then he would go straight to the step he had left the last time. And I must say, there are a lot of such cases. When the experiment was played out, some of the clients who were in the control strategy did not master the long version of the 2nd step. These users at that moment left the site, and then returned after the "end" of the experiment. And then the system, based on the experiment variant played out earlier, sent them again to the old version of the 2nd step. But progress does not stand still, and soon the forgotten and unsupported old 2nd step simply ceased to be compatible with the back-end and stopped working normally. Poor clients are held hostage to legacy code.
What have we done wrong here? We did not finish the experiment properly. In this case, at the end of the test, it was necessary to ensure the migration of clients from the control group to the winning group, and, preferably, clean out the legacy code.
Materiel
It’s probably time to move from practice to theory. The structure of the test can be represented somehow like this:

Red highlighted, in fact, that part of the life cycle that is directly exposed to change. Yellow is the part that, although it remains the same for everyone, but the experiment has a direct effect on it. Accordingly, in order to make a decision about the test result, we must analyze key metrics not only from the “red”, but also from the “yellow” parts. The rest of the journey begins, the influence of the experiment on which, we assume, can be neglected. But the test is a test to check the assumptions, so you need to look at all the basic metrics, too. Statistically significant differences between these metrics may mean any of these:
- We did not take into account any effect of the experiment - and then this metric must be taken into account when summarizing.
- There is a mistake in the design of the experiment (it may be technical — that arose during implementation, it may be “ideological” that arose at the design stage). This error lubricates the test results, and the bias is manifested by the difference in metrics, which should not differ. In such a sad situation, it is necessary to check whether we can nevertheless clear the data from the influence of errors - for example, select some subsegment or time period or examine not all the indicators that we wanted. If it does not work out, you will have to restart the test in the new edition.
To summarize. To set up an experiment correctly, it is necessary to answer a number of questions. Before it starts, of course.
- Why do we need this test. What we want to improve.
- What, in fact, is the improvement - the content of one or more experimental strategies.
- On whom we are testing, i.e. which customer segment should get into the experiment.
- The entry point to the experiment is the moment in the user's life path when the experiment strategy is played out, and the users' paths diverge, according to the option that has fallen out.
- The exit point from the experiment is the moment in life, from which the user can again fall into the same experiment (and get, for example, another option). A special case is a “lifelong” test, when the once played option is assigned to the user before the end of the experiment.
- The expected effect of the experiment, and what metrics we will look at in order to measure this effect.
- Assessment of this effect in positive and negative situations.
- Criteria of (non) success are the boundary values of metrics, at a statistically significant intersection of which we can make a decision.
- The impact of this test on others, and others on this one.
- Test duration and required sample size.
- The end of the test is how we will migrate the system and all users to a new reality.
- Suspension of the test - if something goes wrong, can we pause the test to clarify the circumstances and roll corrections?
I hope that these examples and techniques will help to improve the quality of experiments in your company as well.