Software testing: automation, evaluation and ... utopianism
Last time we told how to prove to all project participants that testing is a useful thing. We hope that the arguments were convincing. Now we can talk about how to approach the creation and planning of tests, their classification and evaluation.

The effective distribution of tests from the point of view of their automation can be represented in the form of a pyramid.
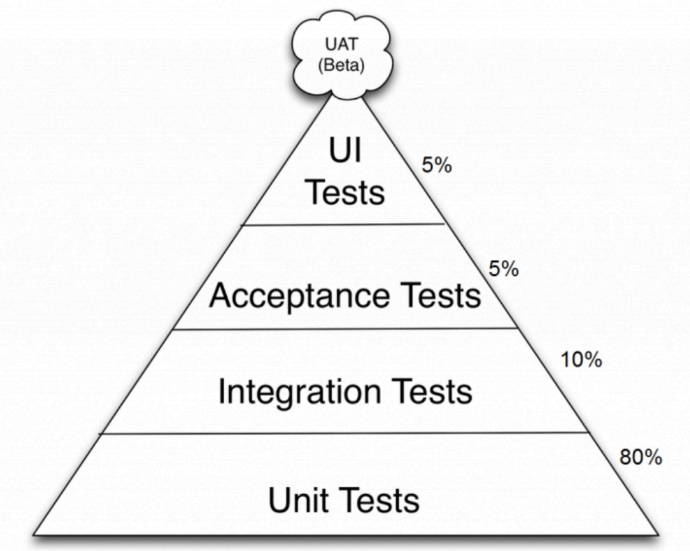
Most of the software’s functionality is covered by simple unit tests, and more complex ones are created for the remaining functionality. If we turn this pyramid over, we get a funnel with many different bugs at the entrance and a small number of heisenbags at the exit. Let's consider each group in more detail.
At the beginning of the project and in young teams, manual tests take a lot of time and effort, and automatic tests are almost never used. Because of this, the testing efficiency is reduced, and it is necessary to get rid of it: to get away from manual tests and increase the number of unit tests.
Compared to UI tests, unit tests are faster and require less development time. They can be launched locally, without powerful farms or separate devices. Feedback from unit tests is many times faster than from UI tests. From changes in the API or XML file, UI tests begin to fall en masse, they must be rewritten every time. Against this background, an important advantage of unit tests is greater stability.

From the point of view of code coverage, unit tests are more efficient, but testing cannot be completely blocked by them. You need to constantly maintain a balance in which unit tests close the base cases, and UI tests solve more complex problems.
It is important to understand that high-level tests signal unclosed bugs in tests at lower levels, so if an error occurs, for example, in the battle code, you should immediately do the corresponding unit test. When bugs are resurrected, it is much more offensive than when they are discovered for the first time.
In addition to the well-known SOLID principles that determine the quality and beauty of the code, when programming tests, two more requirements must be taken into account: speed and reliability. They can be achieved with five key principles, united by the acronym FIRST.

If you simplify it completely, then the tests should be fast and reliable. For this, synchronism is important, the lack of expectation of external reactions and internal timeouts.
As part of TDD (test-driven-development), today there are two testing schools. At the Chicago School, emphasis is placed on the results that test classes and methods produce. At a London school, testing focuses on behavior and involves the use of mock objects.
Suppose we have a class that multiplies two numbers, for example, 7 and 5. The Chicago school simply checks that the result will be 35 - it doesn’t matter how we learn it. The London school says that you need to lock the internal calculator that exists in our class, check that it is called with the correct set of methods and data, and make sure that it returns the locked data. The Chicago school is testing "on the black box", the London - on white. In different tests it makes sense to use both methods.
Even if you cover tests with 100% of the code, you can’t guarantee the absence of bugs. And the desire to achieve 100% coverage only interferes with the work: developers begin to strive for this figure, creating tests for the sake of indicators. The quality of the tests is not indicated by the level of coverage, but simpler facts: few bugs reach the final product and when closing a found bug no new ones appear. The coverage level only signals what it should by definition determine - do we have uncovered sections of code or not.
In the next material of our testing series, we will move on to design, analyze various test notations and types of test objects, as well as requirements for the quality of the test code.
Testing Pyramid
The effective distribution of tests from the point of view of their automation can be represented in the form of a pyramid.
Most of the software’s functionality is covered by simple unit tests, and more complex ones are created for the remaining functionality. If we turn this pyramid over, we get a funnel with many different bugs at the entrance and a small number of heisenbags at the exit. Let's consider each group in more detail.
- Unit or block testing works with certain functions, classes or methods separately from the rest of the system. Due to this, when a bug occurs, you can take turns isolating each block and determining where the error is. In this group, behavioral testing is distinguished. In fact, it looks like a modular one, but it implies strict rules for writing test code, which is regulated by a set of keywords.
- Integration testing is more complicated than unit testing , as it checks the interaction of application code with external systems. For example, EarlGrey UI tests track how an application interacts with server API responses.
- Acceptance testing verifies that the functions described in the terms of reference are working correctly. It consists of sets of large integration test cases that are expanded or narrowed in terms of test environment and specific launch conditions.
- UI testing checks how the application interface meets specifications from designers or user requests. It distinguishes snapshot testing when a screenshot of an application is compared pixel by pixel with a reference one. With this method, it is impossible to close the entire application, since comparing two pictures requires a lot of resources and loads test servers.
- Manual or regression testing remains after automation of all other scenarios. These cases are performed by QA specialists when there is no time to write UI tests or you need to catch a floating error.
At the beginning of the project and in young teams, manual tests take a lot of time and effort, and automatic tests are almost never used. Because of this, the testing efficiency is reduced, and it is necessary to get rid of it: to get away from manual tests and increase the number of unit tests.
Unit vs UI
Compared to UI tests, unit tests are faster and require less development time. They can be launched locally, without powerful farms or separate devices. Feedback from unit tests is many times faster than from UI tests. From changes in the API or XML file, UI tests begin to fall en masse, they must be rewritten every time. Against this background, an important advantage of unit tests is greater stability.
From the point of view of code coverage, unit tests are more efficient, but testing cannot be completely blocked by them. You need to constantly maintain a balance in which unit tests close the base cases, and UI tests solve more complex problems.
It is important to understand that high-level tests signal unclosed bugs in tests at lower levels, so if an error occurs, for example, in the battle code, you should immediately do the corresponding unit test. When bugs are resurrected, it is much more offensive than when they are discovered for the first time.
Test Code Requirements
In addition to the well-known SOLID principles that determine the quality and beauty of the code, when programming tests, two more requirements must be taken into account: speed and reliability. They can be achieved with five key principles, united by the acronym FIRST.
- F - Fast . Good tests give the fastest response. The test itself, installing it in the environment and cleaning up resources after execution should take several milliseconds.
- I - Isolated. Tests must be isolated. The test carries out the verification on its own, and all the data for it is taken from the environment, it does not depend on other tests and test modules. A nice bonus for following this principle: the order of the tests is not important, and they can be run in parallel.
- R - Repeatable. Tests should have predictable behavior. The test should give a clear result, regardless of the number of repetitions and the environment.
- S - Self-verifying. The test result should be available, displayed in some obvious log.
- T - Thorough / Timely. Tests must be developed in parallel with the code, at least as part of a single pull request. This ensures that the combat code is covered, as well as the relevance of the tests themselves and that they will not need to be further modified.
If you simplify it completely, then the tests should be fast and reliable. For this, synchronism is important, the lack of expectation of external reactions and internal timeouts.
What tests should cover
As part of TDD (test-driven-development), today there are two testing schools. At the Chicago School, emphasis is placed on the results that test classes and methods produce. At a London school, testing focuses on behavior and involves the use of mock objects.
Suppose we have a class that multiplies two numbers, for example, 7 and 5. The Chicago school simply checks that the result will be 35 - it doesn’t matter how we learn it. The London school says that you need to lock the internal calculator that exists in our class, check that it is called with the correct set of methods and data, and make sure that it returns the locked data. The Chicago school is testing "on the black box", the London - on white. In different tests it makes sense to use both methods.
Why 100% test coverage is not possible
Even if you cover tests with 100% of the code, you can’t guarantee the absence of bugs. And the desire to achieve 100% coverage only interferes with the work: developers begin to strive for this figure, creating tests for the sake of indicators. The quality of the tests is not indicated by the level of coverage, but simpler facts: few bugs reach the final product and when closing a found bug no new ones appear. The coverage level only signals what it should by definition determine - do we have uncovered sections of code or not.
In the next material of our testing series, we will move on to design, analyze various test notations and types of test objects, as well as requirements for the quality of the test code.