Another article on recognition of workers without helmets by neural networks
Hello, Habr! My name is Vladimir, I am a 4th year student at KubSTU (unfortunately).
Some time ago, I came across an article on the development of a CV-system for detecting working personnel without helmets, and decided to share my own experience in this field, gained during an internship in an industrial company in the summer of 2017. The theory and practice of OpenCV and TensorFlow in the context of the task of detecting people and helmets is right under the cut.

KDPV taken in real time from a surveillance camera
Given: access to video surveillance cameras of industrial facilities of the employer, 2-4 student trainees (during the development, the number of people involved in the project changed).
Objective: to develop a prototype system that detects employees without helmets in real time. The choice of technology is up to you. Our choice fell on Python, as a language that allows you to implement the first working prototype with minimal effort, and - at first - OpenCV, as the machine vision library that we have heard the most about.
OpenCV is a library that implements primarily classical machine vision methods, such as cascading classifiers. The essence of this approach is to create the so-called ensemble of weak classifiers, i.e. such that their ratio of the objects correctly classified by them to the total number of positive responses was at least slightly greater than 0.5. One such classifier is not able to give any result, however, the union of thousands of such classifiers can give an extremely accurate result.

An example of how an ensemble of weak classifiers is able to perform a fairly accurate classification. A source
Obviously, the task of finding a person without a helmet comes down to the task of finding a person as such and ... a helmet! Or its absence. Access to video cameras made it possible to quickly assemble the first dataset from cropped photos of helmets and people themselves, both in helmets and without (they were found quite quickly too), and in the future to bring its volume to 2k + photos.

Image markup for training
At this stage, the first unpleasant feature of OpenCV was found - the official documentation was scattered and sometimes simply referred to the book of one of the leading developers of the library. For many parameters, the values had to be selected experimentally.
 The very first launch of the classifier trained on helmets revealed them with an accuracy of about 60% in isolated cases of false positives! We felt that we were on the right track. The task of detecting people turned out to be much more complicated: unlike helmets, people appeared in the frame from a large number of angles and generally demanded from the classifier much more advanced generalization abilities. While I was working on the refinement of the classifier trained on helmets, as an alternative, we tested the CV-classical detection of objects, based on the algorithm for extracting Canny contours and counting moving objects.
The very first launch of the classifier trained on helmets revealed them with an accuracy of about 60% in isolated cases of false positives! We felt that we were on the right track. The task of detecting people turned out to be much more complicated: unlike helmets, people appeared in the frame from a large number of angles and generally demanded from the classifier much more advanced generalization abilities. While I was working on the refinement of the classifier trained on helmets, as an alternative, we tested the CV-classical detection of objects, based on the algorithm for extracting Canny contours and counting moving objects.
In parallel, we developed a subsystem for processing data received from the classifier. The logic of the work is simple: a frame is taken from the surveillance camera and transmitted to the classifier, a check is made to see if the number of recognized people and helmets in the frame matches, if a person without a helmet is found, a record is made in the database with information about the number of recognized objects, and the frame is saved manual analysis. This solution had one more plus - the frames saved due to a classifier error made it possible to retrain it on the data that it could not cope with.
And here a new problem arose: the vast majority of frames were saved due to recognition errors, and not personnel without helmets. Learning with fresh data slightly improved the recognition result, however, helmets were recognized in ~ 75% of cases (with single false positives), and overlapping figures in the frame were correctly counted only in a little more than half of the cases. I convinced the project manager to give me a week to develop a neural network detector.
One of the features that make working with NS convenient - at least in comparison with classifiers - is the end-to-end approach: in addition to marked helmets / people, classifier training required background images and images to validate the classifier, which needed to be converted to a special format , while the conversion process is controlled by many different non-trivial parameters, not to mention the parameters of the classifier itself! In the case of working with algorithms for counting moving objects and others, the process becomes even more complicated, filters are preliminarily applied to images, the background is removed, etc. End-to-end learning requires the developer to "just" tagged the dataset and the parameters of the model being trained.
The TensorFlow ML framework and the tensorflow / models repository recently appeared at that time met my requirements - it was well documented, it was possible to quickly write a working prototype (the most popular architectures work almost out of the box ), at the same time the functionality was fully suitable for further development if the prototype is successful. After adapting the existing tutorial to the existing dataset using the 101-layer reznet (the principles of convolutional neural networks have been repeatedly covered on Habré, I only allow myself to refer to the articles [1] , [2]), trained on the COCO dataset (which includes photos of people), I immediately received more than 90% accuracy! This was a convincing argument for starting the development of a SNA helmets detector.

Trained on a third-party dataset, the SNS easily recognizes people standing nearby, but makes a mistake where they did not expect recognition from it at all :)
During model training, TensorFlow can generate checkpoint files that allow you to compile and test NSs at different stages, which is useful if something went wrong during retraining. The compiled model is a directed computational graph, the initial vertices of which are input data (in the case of images, the color values of each pixel), and the final ones are recognition results.
In addition to data about the model itself, the checkpoint can contain metadata about the learning process itself, which can be visualized using Tensorboard .
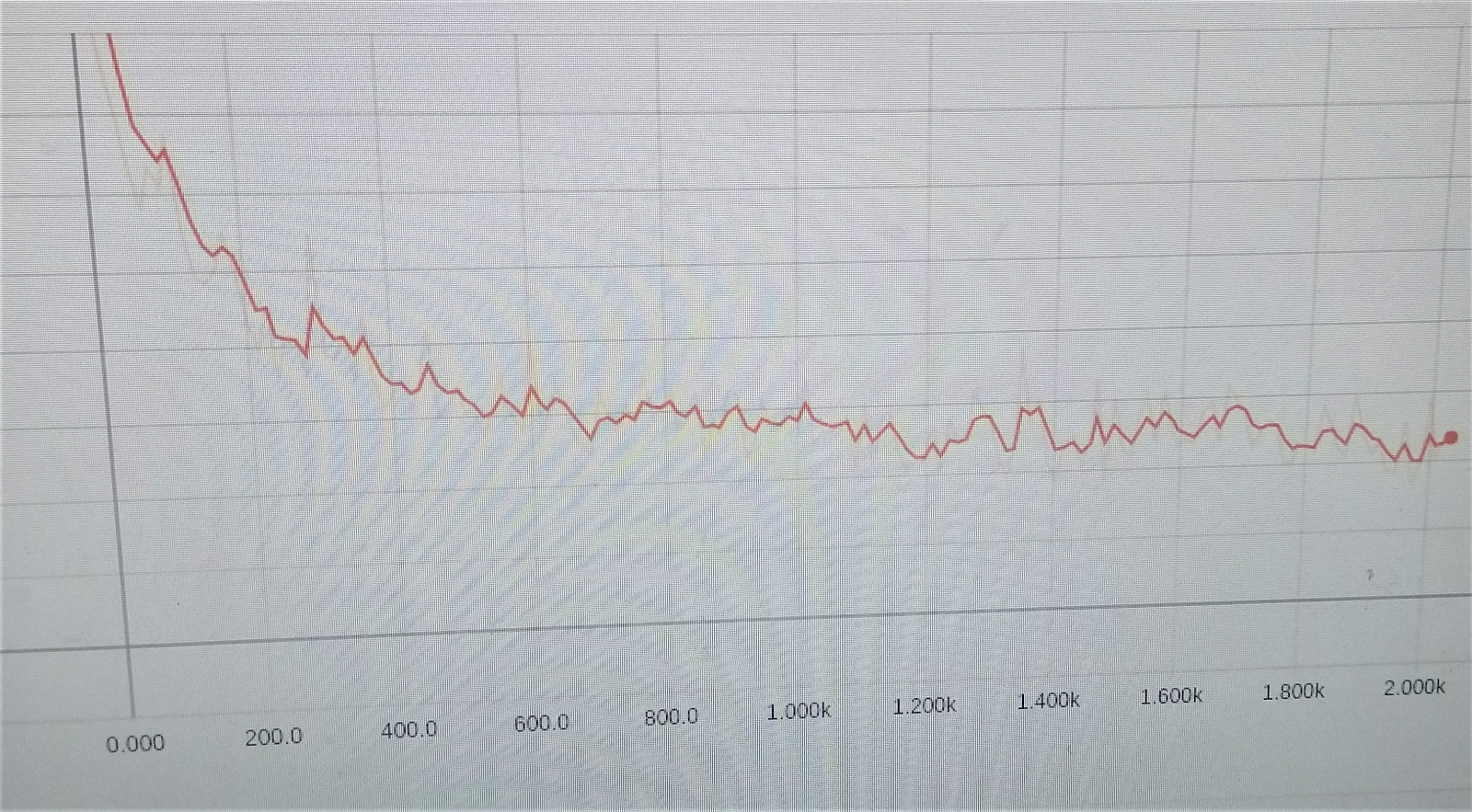
The cherished schedule to reduce learning errors
After testing a number of architectures, ResNet-50 was chosen as providing the optimum between speed and recognition quality. After weighing all the pros and cons, it was decided to leave this trained network as it is, since it already gave an acceptable result, and to train on helmets a simpler Single Shot Detector (SSD) network [3], which gave less accuracy in recognizing people, but provided a satisfactory 90% + when working with helmets. This seemingly illogical decision was due to the fact that the additional use of SSDs slightly increased the time spent on recognition itself, but significantly reduced the time spent on training and testing the network with different parameters and an updated dataset (from several days to 20-30 hours on the GTX 1060 6GB), which means it increased the iteration of the development.
Thus, several conclusions can be drawn: firstly, modern NS frameworks have a low entry threshold (but, undoubtedly, their effective use requires deep knowledge in the field of machine learning) and are much more convenient and functional in solving pattern recognition problems; secondly, students are useful for rapid prototyping and technology testing;)
I will be glad to answer questions and constructive criticism in the comments.