Key features of CUBRID 8.4.0
Welcome all!
This blog will be very entertaining! Today I will talk about very interesting features of the latest version of CUBRID 8.4.0, about what you usually can’t find in the manual. I will give very important recommendations for optimizing queries and indexes, I will give test results, as well as examples of use in real Web services.
Earlier, I talked superficially about the changes in the new version, about the twice as fast database engine, the expanded support for MySQL syntax, etc. Today I’ll talk about them and other things in more detail, focusing on how we were able to double the performance of CUBRID.
The main areas that affected the performance of CUBRID are:
In CUBRID 8.4.0, the size of the database volume has decreased by as much as 218%. The reason for this is the completely changed structure for storing indexes, which in parallel affected the performance of the entire system.
In the following figure, you can see a comparison of the size of the database volumes in the previous version 8.3.1 and the new 8.4.0. In this case, both databases stored 64,000,000 records with a primary key. Data is in gigabytes.

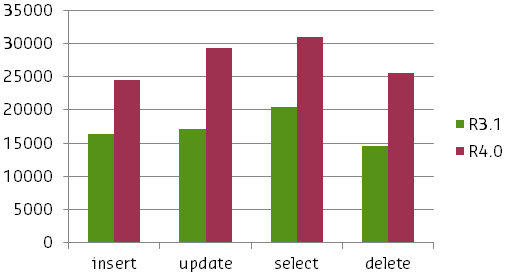
CUBRID 8.4.0 improves parallel computing in the Windows platform version using advanced Mutexes. The following graph shows the comparative performance results of the previous and new versions.
Here I will tell you everything in great detail.
CUBRID 8.4.0 is twice as fast as the previous version of the database engine. We have implemented some very important index optimizations, such as:
Now let's see how the index structure is organized in CUBRID 8.4.0. In CUBRID, an index is implemented as a B + tree [link to a Wikipedia article], in which the values of the index keys are stored in tree leaves.
For a practical example, I suggest looking at the following table structure (STRING = VARCHAR (1,073,741,823)): Enter the
data:
And create a multi-column index. By the way, notice that I create the index after I entered the data. This is the recommended method if you want to enter data at the initial stage or when restoring it. In this way, you can avoid the time and expense of indexing with each input. You can read more about recommendations for entering big data here .
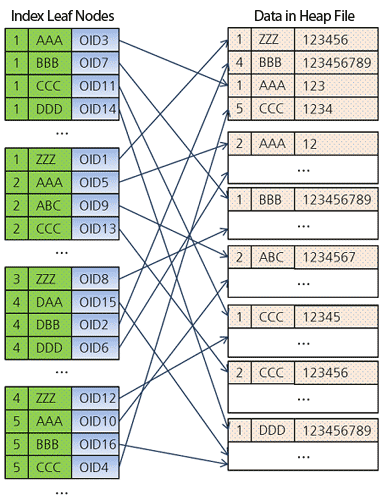
The figure below shows the structure of this index, the leaves of which contain pointers ( OID ) to the data itself located in the heap file on the disk.
Now let's see how index searches typically occur. Given the table created above, we will run the following query.
Now let's see how the covering index can significantly increase the performance of CUBRID. In short, the covering index allows you to get query results without having to access the heap on the disk, which reduces the number of I / O operations, which in turn is the most expensive operation in terms of time spent.
However, the magic of the Cover Index can only be applied when all columns whose values are requested in the query are in the same composite index . In other words, their values must be in the same leaf of the index tree. For example, look at the following query.
And so, if we run this query:

Let's now see how a covering index can improve server performance. For the same example above, we assume that a very large amount of data is stored in the database.
Q1. The following is a query that uses columns specified in a single composite index.
Q2. And now a query where column a is indexed and column c is not.
The following graph shows how quickly queries can be processed if they use a covering index.

CUBRID 8.4.0 has a very “smart” analyzer of LIMIT statements. This analyzer has been very optimized, which allows you to process only the number of records that is required in the condition of the LIMIT operator, upon reaching which the server immediately returns the results. For example, look at the following query.

Multiband scanning optimization is another major improvement in the new CUBRID 8.4.0. When users fill in data that lies in a certain range, for example, between a> 0 AND a <5 , the task is quite easy for most DBMSs. However, everything becomes much more complicated when scattered ranges are included in the conditions, for example, a> 0 AND a <5 AND a = 7 AND a> 10 AND a <15 . Here CUBRID is different. A new optimization function in-place sorting (sorting on the fly) allows you to solve two problems at once:
For example, consider the following query.
With this multi-range scanning capability with on-the-fly sorting, CUBRID can perform very fast searches among large amounts of data.

In Korea, there is a very popular Me2Day Web service, an analogue of Twitter. The following test results were obtained based on real data from this service.
Like Twitter, Me2Day has a posts table where all the “tweets” are stored. Statistics of users and their relationships show that:
The following index has been created for this table.
The most important request, which is most often requested on both Twitter and Me2Day, is to " show the last 20 random posts of all the users I'm following ." Below is this very request. The test was run for 10 minutes, during which this request was continuously processed. Below is a graph of the test results, which compares the UNION operator in MySQL , which is 4 times faster on average than the IN operator in MySQL, with the IN operator in CUBRID . For one, comparing with the previous version, you can see how much the performance of CUBRID 8.4.0 has increased after implementing multi-band scanning.

After such positive results, we replaced the MySQL Me2Day server responsible for the daily operation of the service with the CUBRID server. Next time I’ll talk about this test in more detail. In the meantime, you can also read about it in English on the main site .
The new version of CUBRID 8.4.0 significantly accelerated the processing of queries containing ORDER BY and GROUP BY statements. When columns included in a multi-column index are used in the ORDER BY and GROUP BY conditions, it is no longer necessary to sort the values, since they are already sorted in the index tree. Such optimization can significantly increase the processing performance of the entire request. We can look at the work of the following request.

In addition to improving the performance of the entire system, the new version of CUBRID 8.4.0 supports more than 90% of the SQL DBMS syntax of MySQL. We also implemented enhanced support for implicit type conversions to keep developers focused on improving the functionality of their applications, while CUBRID will do all the internal conversions. Below are some examples of the new syntax.
In total, the new version has 23 new DATE / TIME syntax, 5 - associated with strings, and 5 new aggregation functions. The entire list of new syntax can be found in the blog off. site.
Also in version CUBRID 8.4.0 significantly improved the locking mechanism to minimize the occurrence of stagnation. For example, in a High Availability environment, stagnation will not occur between transactions that enter data into the same table at the same time.
As you probably already understood, the new version of CUBRID 8.4.0 is clearly superior to all previous versions in terms of performance, reliability, and ease of development. CUBRID is developed for use in Web applications and services, therefore, all major development, improvements and optimizations are carried out in the field of functions often used in Web applications (for example, as IN statements, LIMIT restrictions, grouping and sorting, as well as High Availability), excellence whose performance is proved by the results of comparative tests.
If you have specific questions, write in the comments. I will be very glad to clarify everything!
This blog will be very entertaining! Today I will talk about very interesting features of the latest version of CUBRID 8.4.0, about what you usually can’t find in the manual. I will give very important recommendations for optimizing queries and indexes, I will give test results, as well as examples of use in real Web services.
Earlier, I talked superficially about the changes in the new version, about the twice as fast database engine, the expanded support for MySQL syntax, etc. Today I’ll talk about them and other things in more detail, focusing on how we were able to double the performance of CUBRID.
The main areas that affected the performance of CUBRID are:
- Reducing the size of the database volume
- Improved parallel computing in Windows version
- Index Optimizations
- Optimization of condition processing in LIMIT
- Optimization of condition processing in GROUP BY
Reducing the size of the database volume
In CUBRID 8.4.0, the size of the database volume has decreased by as much as 218%. The reason for this is the completely changed structure for storing indexes, which in parallel affected the performance of the entire system.
In the following figure, you can see a comparison of the size of the database volumes in the previous version 8.3.1 and the new 8.4.0. In this case, both databases stored 64,000,000 records with a primary key. Data is in gigabytes.
Improved parallel computing in Windows version
CUBRID 8.4.0 improves parallel computing in the Windows platform version using advanced Mutexes. The following graph shows the comparative performance results of the previous and new versions.
Index Optimizations
Here I will tell you everything in great detail.
CUBRID 8.4.0 is twice as fast as the previous version of the database engine. We have implemented some very important index optimizations, such as:
- Covering Index
- Optimized condition processing in LIMIT
- Key Limit
- Multi Range Scan - Optimization of condition processing in GROUP BY
- Index Scan Descending
- Index scan support in LIKE statements
Now let's see how the index structure is organized in CUBRID 8.4.0. In CUBRID, an index is implemented as a B + tree [link to a Wikipedia article], in which the values of the index keys are stored in tree leaves.
For a practical example, I suggest looking at the following table structure (STRING = VARCHAR (1,073,741,823)): Enter the
CREATE TABLE tbl (a INT, b STRING, c BIGINT);data:
INSERT INTO tbl VALUES (1, ‘AAA, 123), (2, ‘AAA’, 12), …;And create a multi-column index. By the way, notice that I create the index after I entered the data. This is the recommended method if you want to enter data at the initial stage or when restoring it. In this way, you can avoid the time and expense of indexing with each input. You can read more about recommendations for entering big data here .
CREATE INDEX idx ON tbl (a, b);The figure below shows the structure of this index, the leaves of which contain pointers ( OID ) to the data itself located in the heap file on the disk.
- Thus, the index key values ( a and b ) are sorted by increase (default).
- Each sheet has a pointer (indicated by an arrow) to the corresponding data (entry in the table) located on the disk heap.
- The data in the heap is randomly arranged as shown in the figure.
Index scan
Now let's see how index searches typically occur. Given the table created above, we will run the following query.
SELECT * FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’
AND c > 10000
ORDER BY b;- First, CUBRID will find all leaves in which a> 1 and a <5 .
- Then, among this result, he will select leaves in which b <'K' .
- Since the c column is not indexed, to get its values, you need to go to the heap that is on the disk.
- Each sheet in the index tree contains an OID (Object Identifier) value that indicates where exactly the data of a particular table record is stored on the disk.
- Based on these OIDs, the server will go to the heap to get the values of column c .
- Then CUBRID will find all those records in which c> 10000 .
- As a result, all these records will be sorted by column b , as required in the query.
- Then the results are sent to the client.
Covering Index
Now let's see how the covering index can significantly increase the performance of CUBRID. In short, the covering index allows you to get query results without having to access the heap on the disk, which reduces the number of I / O operations, which in turn is the most expensive operation in terms of time spent.
However, the magic of the Cover Index can only be applied when all columns whose values are requested in the query are in the same composite index . In other words, their values must be in the same leaf of the index tree. For example, look at the following query.
SELECT a, b FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’
ORDER BY b;- As you can see, all the columns used in this query are in the same multi-column index, which we created at the very beginning.
- In the WHERE clause, only those bells that are in the same multi-column index are specified.
- Also, only the column that is in the same multi-column index is specified in the condition of the ORDER BY operator.
And so, if we run this query:
- As part of the normal index scan process, CUBRID will first find all the leaves in the index tree with a> 1 and a <5 .
- Then, among this result, he will select leaves in which b <'K' .
- Since the values of columns a and b were already obtained during the index scan, there is no need to go and look at the heap on the disk to get these values. Thus, after the second step, the server immediately starts sorting the results by column b .
- Then returns the values.
Let's now see how a covering index can improve server performance. For the same example above, we assume that a very large amount of data is stored in the database.
Q1. The following is a query that uses columns specified in a single composite index.
SELECT a, b FROM tbl WHERE a BETWEEN ? AND ?Q2. And now a query where column a is indexed and column c is not.
SELECT a, c FROM tbl WHERE a BETWEEN ? AND ?The following graph shows how quickly queries can be processed if they use a covering index.
Optimization of condition processing in LIMIT
Key Limit
CUBRID 8.4.0 has a very “smart” analyzer of LIMIT statements. This analyzer has been very optimized, which allows you to process only the number of records that is required in the condition of the LIMIT operator, upon reaching which the server immediately returns the results. For example, look at the following query.
SELECT * FROM tbl
WHERE a = 2
AND b < ‘K’
ORDER BY b
LIMIT 3;- CUBRID first finds the first sheet in the index tree, in which a = 2 .
- Since the index includes the values of column b that are already sorted, there is no need to sort the results separately.
- The server passes only the first 3 keys of the index and stops at this, since there is no need to return more than 3 results.
- Then the server already heaps into a heap to get the values of all the other columns. Therefore, only 3 entries will be affected on disk.
Multi Range Scan
Multiband scanning optimization is another major improvement in the new CUBRID 8.4.0. When users fill in data that lies in a certain range, for example, between a> 0 AND a <5 , the task is quite easy for most DBMSs. However, everything becomes much more complicated when scattered ranges are included in the conditions, for example, a> 0 AND a <5 AND a = 7 AND a> 10 AND a <15 . Here CUBRID is different. A new optimization function in-place sorting (sorting on the fly) allows you to solve two problems at once:
- Key Limit
- As well as sorting records on the fly
For example, consider the following query.
SELECT * FROM tbl
WHERE a IN (2, 4, 5)
AND b < ‘K’
ORDER BY b
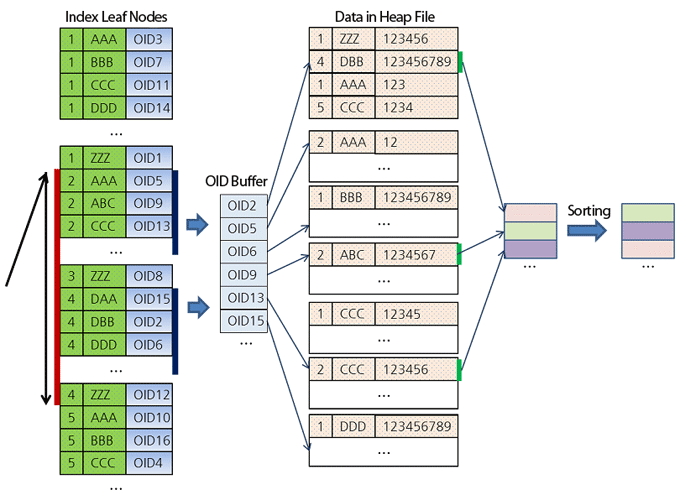
LIMIT 3;- Since all the keys in the index tree are sorted, the server will begin scanning from the first sheet, where a = 2 (see the figure below).
- Since it is necessary to get only 3 rows of the table, sorted by column b , the server will sort the results that satisfy the condition a IN (2, 4, 5) AND b <'K' , on the fly.
1. At the very beginning, the server will find the record (2, AAA), which gives the 1st result.
2. Then it finds the record (2, ABC), which gives the 2nd result.
3. Then it finds the entry (2, CCC), which gives the 3rd result.
4. Since the server has already found 3 records, it jumps to the next range in order to search for records where the values of column b will be less than the values already found.- First, the server will find the record (4, DAA), which is greater than the last value of column b of the records already found. Therefore, this range immediately disappears, and the server jumps to the next range.
- Finds a record (5, AAA), which is smaller than ABC and CCC. Therefore, it removes the last record and inserts this record in a suitable place.
- The next record (5, BBB) is already larger than the last record of preliminary results. Therefore, this completes the scan of this range. The entire search also ends, as there are no other ranges needed for scanning.
- Since all the results are already sorted, it remains only to look into the heap and get the values of the remaining columns.
With this multi-range scanning capability with on-the-fly sorting, CUBRID can perform very fast searches among large amounts of data.
Test results
In Korea, there is a very popular Me2Day Web service, an analogue of Twitter. The following test results were obtained based on real data from this service.
Like Twitter, Me2Day has a posts table where all the “tweets” are stored. Statistics of users and their relationships show that:
- 50% of users follow 1-50 users.
- 40% of users follow 51-2000 users.
- 10% of users follow 2001+ users.
The following index has been created for this table.
INDEX (author_id, registered DESC)The most important request, which is most often requested on both Twitter and Me2Day, is to " show the last 20 random posts of all the users I'm following ." Below is this very request. The test was run for 10 minutes, during which this request was continuously processed. Below is a graph of the test results, which compares the UNION operator in MySQL , which is 4 times faster on average than the IN operator in MySQL, with the IN operator in CUBRID . For one, comparing with the previous version, you can see how much the performance of CUBRID 8.4.0 has increased after implementing multi-band scanning.
SELECT * FROM posts
WHERE author_id IN (?, ?, ..., ?) AND registered < :from ORDER BY reg_date DESC
LIMIT 20;After such positive results, we replaced the MySQL Me2Day server responsible for the daily operation of the service with the CUBRID server. Next time I’ll talk about this test in more detail. In the meantime, you can also read about it in English on the main site .
Optimization of condition processing in GROUP BY
The new version of CUBRID 8.4.0 significantly accelerated the processing of queries containing ORDER BY and GROUP BY statements. When columns included in a multi-column index are used in the ORDER BY and GROUP BY conditions, it is no longer necessary to sort the values, since they are already sorted in the index tree. Such optimization can significantly increase the processing performance of the entire request. We can look at the work of the following request.
SELECT COUNT(*) FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’ AND c > 10000
GROUP BY a;- As part of the normal index scan process, CUBRID will first find all the leaves in the index tree with a> 1 and a <5 .
- Using the OID values, the server will go to the heap to get the values of column c .
- Then CUBRID will find all those records in which c> 10000 .
- Since all the necessary values are already sorted, the GROUP BY operation will be performed immediately without preliminary sorting.
- Then the server returns the results.
Developers Productivity Increase
In addition to improving the performance of the entire system, the new version of CUBRID 8.4.0 supports more than 90% of the SQL DBMS syntax of MySQL. We also implemented enhanced support for implicit type conversions to keep developers focused on improving the functionality of their applications, while CUBRID will do all the internal conversions. Below are some examples of the new syntax.
- Implicit type conversion
CREATE TABLE x (a INT);
INSERT INTO x VALUES (‘1’); - SHOW Queries
SHOW TABLES; SHOW COLUMNS; SHOW INDEX; … - ALTER TABLE ... CHANGE / MODIFY COLUMN ...
CREATE TABLE t1 (a INTEGER);
ALTER TABLE t1 CHANGE a b DOUBLE;
ALTER TABLE t2 MODIFY col1 BIGINT DEFAULT 1; - UPDATE ... ORDER BY
UPDATE t
SET i = i + 1
WHERE 1 = 1
ORDER BY i
LIMIT 10; - DROP TABLE IF EXISTS ...
DROP TABLE IF EXISTS history;
In total, the new version has 23 new DATE / TIME syntax, 5 - associated with strings, and 5 new aggregation functions. The entire list of new syntax can be found in the blog off. site.
Improving High Availability Reliability
Improving next key lock
Also in version CUBRID 8.4.0 significantly improved the locking mechanism to minimize the occurrence of stagnation. For example, in a High Availability environment, stagnation will not occur between transactions that enter data into the same table at the same time.
Conclusion
As you probably already understood, the new version of CUBRID 8.4.0 is clearly superior to all previous versions in terms of performance, reliability, and ease of development. CUBRID is developed for use in Web applications and services, therefore, all major development, improvements and optimizations are carried out in the field of functions often used in Web applications (for example, as IN statements, LIMIT restrictions, grouping and sorting, as well as High Availability), excellence whose performance is proved by the results of comparative tests.
If you have specific questions, write in the comments. I will be very glad to clarify everything!