Designing a Schemaless Uber Engineering Data Warehouse Using MySQL
Designing Schemaless, Uber Engineering's Scalable Datastore Using MySQL
By Jakob Holdgaard Thomsen
January 12, 2016
https://eng.uber.com/schemaless-part-one/

Designing a Schemaless Uber Engineering data warehouse using MySQL. This is the first part of a three-part series of articles about the Schemaless data warehouse.
In Project Mezzanine, we described how we migrated Uber trip data from one Postgres instance to Schemaless, our high-performance and reliable data warehouse. This article describes its architecture, role in Uber infrastructure, and design history.
The fight for a new database
At the beginning of 2014, our database resources were exhausted due to an increase in the number of trips. Each new city, each new trip led us to the abyss, until one day we realized that the Uber infrastructure could not function by the end of the year - we simply could not store enough trip data using Postgres. Our task was to change the database technology in Uber, a task that took many months, and to the solution of which we attracted a large number of engineers from our offices around the world.
But wait, why build a scalable data warehouse when there are many commercial and open source solutions? We had five key requirements for our new data warehouse:
Our data warehouse should have been able to linearly increase capacity by adding new servers, which was missing in our Postgres installation. Adding new servers should both increase available disk space and reduce system response time.
We need high availability of data storage when recording. Previously, we implemented a simple buffer mechanism with Redis, so if the Postgres write failed, we could try again later because the trip was saved in Redis. At the time that the record was saved in Redis and not yet saved in Postgres, we lost functionality, such as billing. It’s annoying, but at least we didn’t lose the trip! Uber has grown over time, and our Redis-based solution is not scalable. The Schemaless data store was supposed to support a mechanism similar to our solution with Redis, but provide read-your-write consistency.
We need a way to messaging with dependent components. In the system that was working at that time, we worked with dependent components sequentially within the same process (for example, billing, analytics, etc.). It was a process prone to errors: if any step of the process failed, we had to try again from the very beginning, even if some steps of the process were successful. This did not scale, so we wanted to break processes down into isolated subordinate processes that would start in response to data changes. We already had an asynchronous messaging system based on Kafka 0.7. But we could not start it without data loss, so we would welcome a new system that had something similar, but could work without data loss.
We need secondary indexes. We were moving away from Postgres, however, the new datastore was supposed to support indexes at the Postgres level, which would make it possible to search secondary indexes just as efficiently.
We need an absolutely reliable system , as it contains mission critical data. If at 3 a.m. they tell us that our data warehouse is not responding and our business is destroyed, will we have operational information to quickly restore it?
In the light of the foregoing, we analyzed the advantages and potential limitations of some alternative widely used systems, such as Cassandra, Riak, MongoDB, etc. For illustration purposes, a diagram below shows various combinations of capabilities of various systems products):
| Linear extensibility | Write accessibility | Message exchange | Secondary Indexes | Reliability | |
| Product 1 | ✓ | ✓ | ✗ | (✓) | ✗ |
| Product 2 | ✓ | ✓ | ✗ | (✓) | (✓) |
| Product 3 | ✓ | ✗ | ✗ | (✓) | ✗ |
While all three systems are linearly expandable by the addition of new servers, only two of them have high write accessibility. None of the solutions implements messaging out of the box, so we would have to implement it at the application level. All of them have indexes, but if you are going to index a lot of different values, the queries become slow, because they use the scatter-gather command to poll all nodes (shards).
Finally, our decision was ultimately determined by reliability, because we must store travel data critical for the business. Some existing solutions can function reliably in theory. But do we have operational knowledge to immediately realize their fullest potential? Indeed, a lot depends not only on the technology that we use, but also on those people who were on our team.
It should be noted that since we considered these options more than two years ago and found that none of them is applicable in the case of using the data warehouse of trips, we successfully applied both Cassandra and Riak in other areas of our infrastructure, and we We use them in production to serve millions of users.
At Schemaless, we are reliable.
Since none of the above options corresponded to our requirements in accordance with the time frame that we had, we decided to create our own system, which was as simple as possible for work, using scaling lessons from others. The design is inspired by Friendfeed, and the focus was on the operational side, inspired by Pinteres.
We came to the conclusion that it is necessary to design key-value storage, which allows you to save any JSON data without strictly checking the schema (hence the name schemaless). It was implemented on a MySQL server distributed on shards, with write buffering for fault tolerance, and publish-subscribe messaging about data changes, which is based on trigger calls. Finally, the Schemaless datastore supports global indexes.
Schemaless Data Model
Schemaless is an append-only sparse three-dimensional hash map similar to Google's Bigtable. The smallest data object in Schemaless is called a cell and is immutable. After recording, it cannot be modified or deleted. A cell is a JSON (BLOB) object that can be accessed using the row key, column name, and reference key called ref key. The row key is the UUID, the column name is the row, and the reference key is an integer.
You can represent a row key as a primary key in a relational database and a column name as a column of a relational database. However, Schemaless does not have a predefined or forced schema, and column names are not predefined for rows. In fact, the names of the columns are completely determined by the application. The ref key is used to version cells. Therefore, if a cell needs to be updated, you must write a new cell with a higher ref key (the last cell has the highest ref key). The ref key can also be used as an index in an array, but it is usually used for versioning. The way ref key is used is determined by the application.
Typically, applications group related data into one and the same column, and all cells in each column have approximately the same schema on the application side. This grouping is a great way to combine data that changes together and allows the application to quickly change the schema without downtime on the database side. Below is an example of this.
Example: Storing Schemaless Trip Data
Before we dive into how we simulate a trip to Schemaless, let's take a look at the anatomy of a trip to Uber. Trip data is generated at different points in time, for example: the end of the trip, payment for the trip, and these various pieces of information arrive asynchronously. The diagram below is a simplified flow when different parts of the Uber trip occur:

The diagram shows a simplified version of our event flow. * indicates parts that are optional and may be present several times.
The trip is contacted by the driver, who fulfills the customer’s order, and has a time stamp for its beginning and end. This information is a basic (estimated) trip, and from this we calculate the cost of the trip (tariff), which is the tariff for the client. After the trip, we may have to adjust the fare. We can add notes to the trip, taking into account reviews from the client or from the driver (marked with an asterisk in the diagram above). Or, perhaps the client will have to make several attempts to pay for the trip with a payment card if one of his cards is blocked. The flow of events in Uber is a data driven process. As data becomes available or added during the trip, a specific set of processes will be performed. Some information
So, how do we compare the above trip model with Schemaless?
Trip Data Model
We will use italics to denote UUIDs and capital letters to denote column names, the table below shows the data model for a simplified version of our travel repository. We have two trips (UUIDs trip_uuid1 and trip_uuid2) and four columns (BASE, STATUS, NOTES and FARE ADJUSTMENT). Each cell is represented by a block with a number and a JSON object (abbreviated {...}). Blocks are shown superimposed to represent versioning.
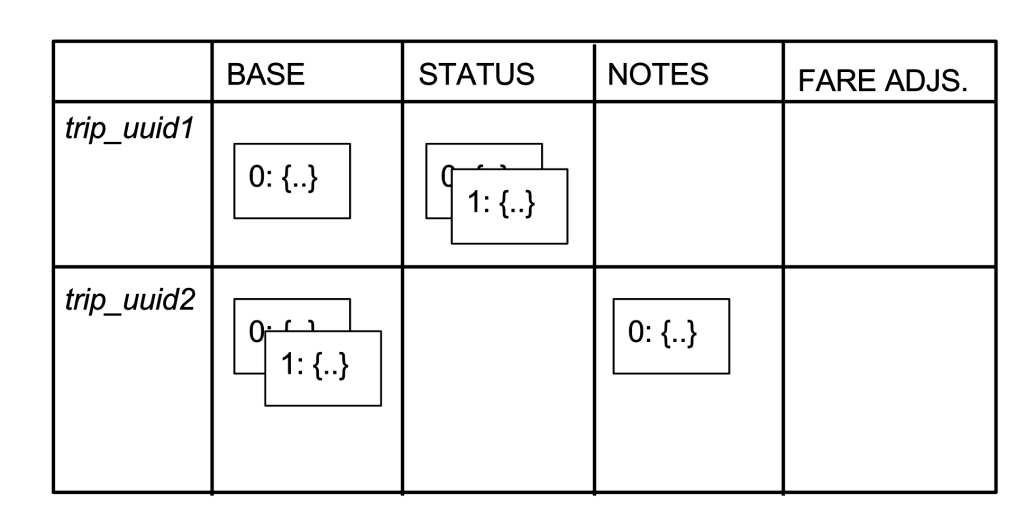
trip_uuid1 has three cells: one in the BASE column, two in the STATUS column, and none in the FARE ADJUSTMENTs column. trip_uuid2 has two cells in the BASE column, one in the NOTES column, and also in the FARE ADJUSTMENTS column. For Schemaless, the columns are no different; therefore, the semantics of the columns are determined by the application, which in this case is the Mezzanine service.
In Mezzanine, the BASE base cells contain basic ride information, such as driver UUID and travel time. The STATUS column contains the current travel payment status, into which we insert a new cell for each attempt to bill. (The attempt failed if the credit card did not have sufficient funds or the card is blocked). The NOTES column contains a cell if there are notes left by the driver or dispatcher. Finally, the FARE ADJUSTMENTs column contains cells if the travel fare has been adjusted.
We use this column structure to avoid race conditions and minimize the amount of data that needs to be recorded during the update. The BASE column is recorded when the trip is completed, and usually only once. The STATUS column is recorded when we try to pay for the trip that occurs after writing data in the BASE column and can happen several times if there was a failure in paying the bill. A NOTES column can also be written several times at some point after a BASE record, but it is completely separate from the STATUS column record. Similarly, the FARE ADJUSTMENTS column is only recorded if the fare is changed, for example, due to an inefficient route.
End-to-end triggers
A key feature of Schemaless are triggers that allow you to be notified of changes to an instance of Schemaless. Because cells are immutable and new versions are added, each cell also represents a change or version, allowing values in the instance to be treated as a change log. For this instance, you can listen to these changes and run functions on them that are very similar to message buses, such as Kafka.
Schemaless triggers make Schemaless a reliable data source, because, in addition to direct access to data, the message system can use the trigger function to monitor and run any application code (a similar system is LinkedB's DataBus), separating data creation and processing.
Among other uses, Uber uses Schemaless triggers to invoice when a BASE column is written to an instance of Mezzanine. In the above example, when the BASE column is written for trip_uuid1, our billing service, which runs in the BASE column, selects this cell and will try to pay for the trip through a payment card. The result of payment through a payment card, whether it is success or failure, is recorded in Mezzanine in the STATUS column. Thus, the billing service is separate from the creation of the trip, and Schemaless acts as an asynchronous message bus.

Easy Access Indexes
Finally, Schemaless supports indexes defined by fields in JSON objects. An index is queried through these predefined fields to find cells that match the query parameters. Querying these indexes is effective because querying an index requires accessing only one shard to find a set of cells to return. In fact, queries can be further optimized because Schemaless allows you to denormalize cell data by writing it directly to the index. The presence of denormalized data in the index means that only one shard is required to query the index to query the index and obtain information. In fact, we usually recommend that Schemaless users denormalize frequently requested data into indexes, in addition to getting the cell directly through the row key.
As an example, for Mezzanine we have an index that allows us to find the trips of a given driver. We also denormalized the time of the trip creation and the city where the trip was made. This allows you to find all the trips for the driver in the city for a certain period of time. Below we provide a definition of the driver_partner_index index in YAML format, which is part of the trip data storage and is defined above the BASE column (the example is annotated with comments using standard #).
table: driver_partner_index # Name of the index.
datastore: trips # Name of the associated datastore
column_defs:
– column_key: BASE # From which column to fetch from.
fields: # The fields in the cell to denormalize
– { field: driver_partner_uuid, type: UUID}
– { field: city_uuid, type: UUID}
– { field: trip_created_at, type: datetime}
Using this index, we can find trips for a given driver_partner_uuid, filtered by city_uuid, and / or trip_created_at. In this example, we use only the fields from the BASE column, but Schemaless supports denormalizing data from multiple columns, which will contain multiple entries in the column_def list above.
As mentioned, Schemaless has efficient indexes implemented by sharding indexes based on a shaded field. Therefore, the only requirement for a shaded index is that one of the fields in the index is designated as a shaded field (in the above example, it will be driver_partner_uuid, since it is the first one specified). The shard field determines which shard should write or read the index. To do this, we need to determine the shard field when querying the index. This means that at the time of the query, we need to request only one shard to retrieve index entries. An important requirement for a shard field is that it must provide a good distribution of data across shards. UUIDs are best suited, city identifiers are less preferred,
With the exception of shard fields, Schemaless supports queries for equality, inequality, and a range of queries for filtering, and also supports selecting only a subset of the fields in the index and retrieving specific or all columns for the row key that the index records point to. Currently, the shard field must be unchangeable, which allows Schemaless to single-handedly define the shard on which the data is located. But we are learning how to make it mutable without performance overhead.
Our indexes are eventually consistent. Whenever we write data to a cell, we also update index entries, but this does not happen in a single transaction. Cells and index entries usually do not belong to the same shard. Therefore, if we were to implement consistent indexes, we would need to introduce a two-phase commit when writing, which would entail significant overhead. As a result, with eventually consistent indexes, we avoid overhead, but Schemaless users can see outdated data in the indexes. Most of the time, the lag is significantly lower than 20 ms between cell changes and corresponding index changes.
Summary
We provided an overview of the data model, triggers, and indexes, which are key features that define Schemaless, the core component of our trip data storage engine. In future posts, we’ll look at a few more features of Schemaless to illustrate how he became a good assistant in the Uber infrastructure: more about architecture, using MySQL as a shard, and how we handle errors to ensure the reliability of the mobile application.
Part 2: Schematic architecture
Part 3: Using triggers in Schemaless
Jakob Thomsen is a software engineer and tech lead on the Schemaless project and works at the Uber Engineering office in Aarhus, Denmark. See our talk at Facebook's second annual @Scale conference in September 2015 for more info on Schemaless.
Photo Credits for Header: “anim1069” by NOAA Photo Library licensed under CC-BY 2.0. Image cropped for header dimensions and color corrected.
Header Explanation: Since Schemaless is built using MySQL, we introduce the series using a dolphin striking a similar pose but with opposite orientation to the MySQL logo.