OPA and SPIFFE - Two New Projects at CNCF for Cloud Application Security

At the end of March, the CNCF fund, which helps develop Open Source projects for cloud-native applications, experienced a double replenishment: OPA (Open Policy Agent) and SPIFFE (Secure Production Identity Framework For Everyone), which are related to each other , were added to the sandbox security topic. Why can they come in handy?
Open policy agent
Open Policy Agent ( GitHub ) is an engine written in Go that offers a unified way to use policies that are context sensitive and work across the entire stack of infrastructure used for cloud applications.
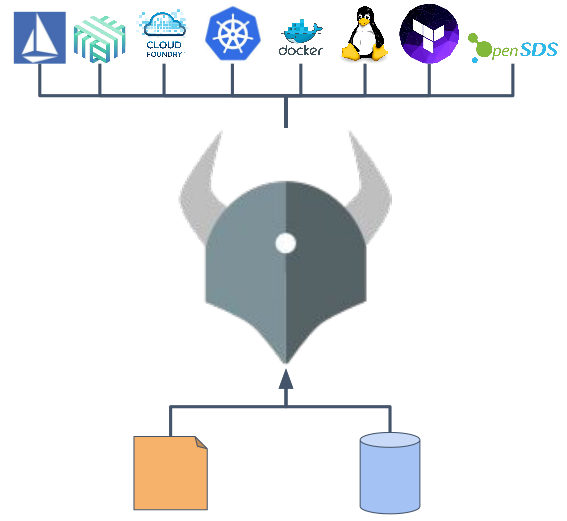
The initiative to create the Open Policy Agent comes from Netflix. As its representatives told CloudNativeCon US 2017, this project allowed to solve the authorization problem on a large cloud environment. In short, the company's engineers wanted to provide a standardized (and simple) ability to define and enforce rules of the following form: Subject (identity, I) may / may not perform Operation (operation, O) on the Resource (resource, R) - in all possible combinations in the entire ecosystem.
At the same time, as you might guess, the Netflix ecosystem is very diverse: it has more than one type of resources (REST interfaces, gRPC methods, SSH, Kafka topics, etc.), more than one type of subjects, and many protocols used (HTTP / HTTPS, gRPC, its binary), programming languages (Java, Node.js, Python, Ruby) ... Finally, the critical requirement for this entire system is the minimum delay : for example, one node of the Kafka cluster processes thousands of requests per second, therefore, about the layer , requiring authorization for more than 1 millisecond, and there was no question.
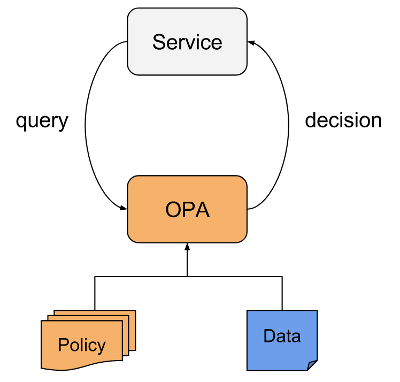
The general solution scheme that Netflix came up with was the following:
And in a more detailed view, the architecture of a system using OPA looks like this (slides are taken from this presentation ) :
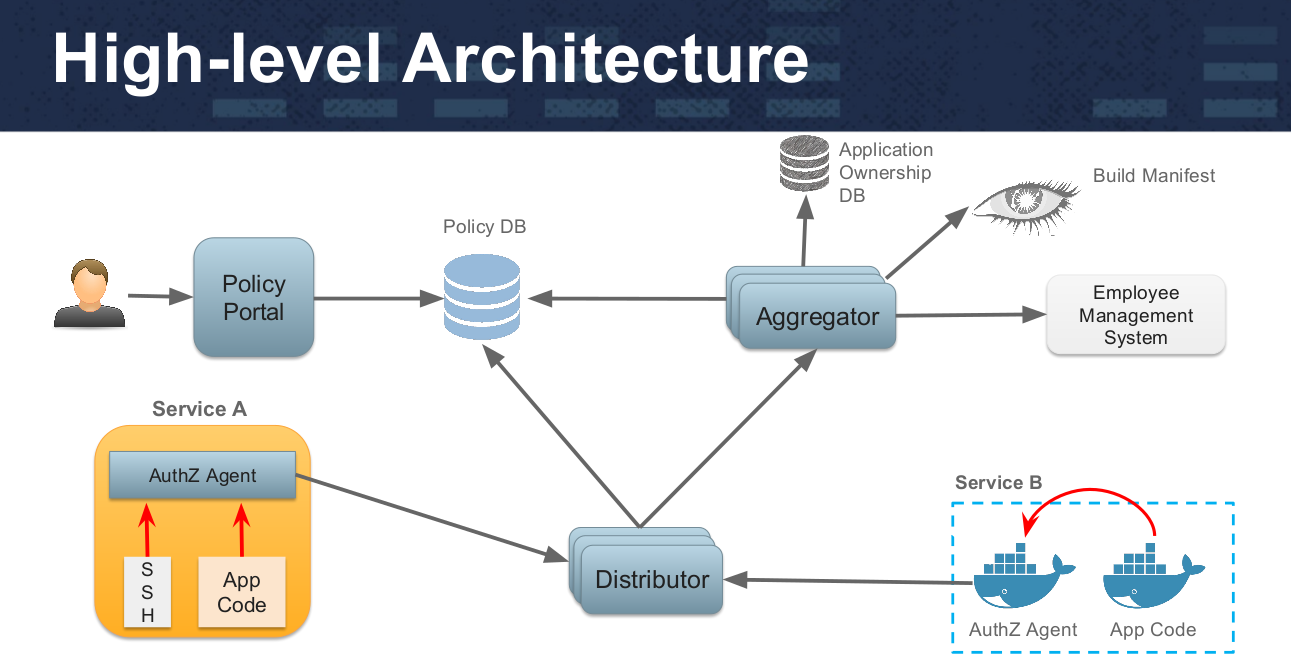
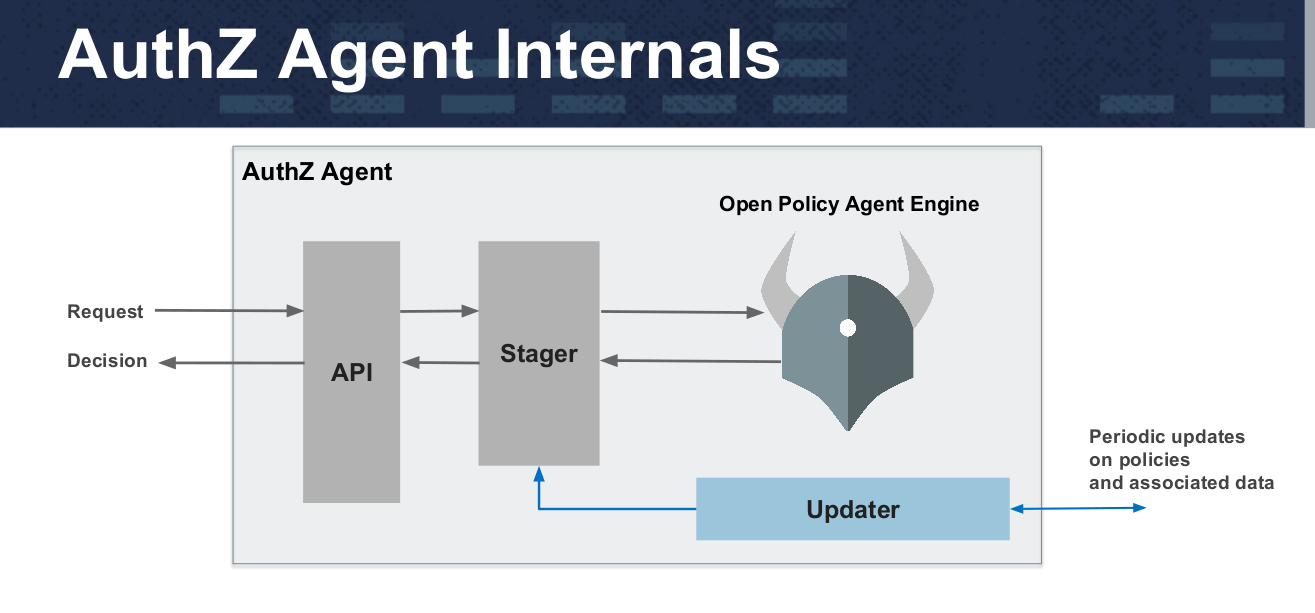
Policies in OPA are written in a high-level declarative language (called Rego) and loaded through a file system or API. Services transfer responsibility for making a decision on policies by request to the Open Policy Agent engine, which looks at policies and additional data, makes a decision on request and returns it to the client. Integration of the application with OPA can be implemented by various methods: sidecar-container, host-level daemon, library. According to the authors, for simple policies, the average delay is about 0.2 ms.
Simple illustrationuse of the API from the Open Policy Agent is presented in the GitHub project :
Users can view their salaries and the salaries of employees under their supervision:
allow {
input.method = "GET"
input.path = ["salary", id]
input.user_id = id
}
allow {
input.method = "GET"
input.path = ["salary", id]
managers = data.management_chain[id]
id = managers[_]
}Request: Can Bob see his salary?
> input = {"method": "GET", "path": ["salary", "bob"], "user_id": "bob"}
> allow
trueRequest: A chain of managers for Bob.
> data.management_chain["bob"]
[
"ken",
"janet"
]Query: Can Alice see Bob's salary?
> input = {"method": "GET", "path": ["salary", "bob"], "user_id": "alice"}
> allow
falseRequest: Can Janet see Bob's salary?
> input = {"method": "GET", "path": ["salary", "bob"], "user_id": "janet"}
> allow
trueDetails about the OPA device, as well as about working with this engine, are described in the project documentation . There you can find examples of integration with Admission Controllers in Kubernetes (requires version K8s 1.9+ and included
ValidatingAdmissionWebhook) , with Docker (requires Docker Engine 1.11+) and with SSH (uses the Linux-PAM plugin) .Secure Production Identity Framework For Everyone
The authors of SPIFFE ( GitHub ) took a different approach to the authentication problem - they offer web services a framework and a set of standards that eliminate the very need for authentication and authorization at the application level, as well as for complex configuration of access lists at the network level.
SPIFFE is based on three components:
- SPIFFE ID . A standard that defines how services identify each other. These are structured strings (represented as URIs, for example,
spiffe://trust-domain/path), acting as a name for an entity. - SPIFFE Verifiable Identity Document (SVID) . A standard for converting SPIFFE IDs into a cryptographically verified document (such a document is called SVID). The specification is defined in The SPIFFE Identity and Verifiable Identity Document . In addition, there is a separate specification for the X.509 SVID .
- Workload API . An API specification for issuing and receiving SVIDs. Typically, API methods are available locally (for example, through a Unix domain socket) and do not require authentication from the workload. The authenticity of the call to the Workload API can be verified by a third-party method (for example, by the properties of the process that accesses the socket provided by the operating system). In addition, the Workload API provides CA certificates (CA bundles). Work on the specification is still underway ( prototype available ).
The architecture of environments using the approach proposed in SPIFFE is as follows:
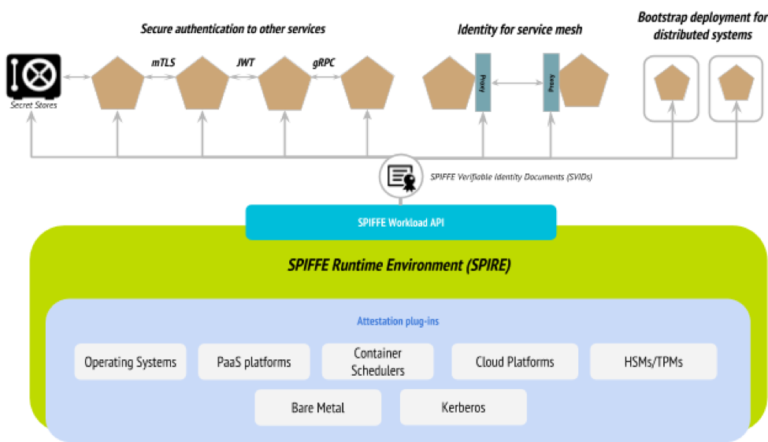
In addition to the specifications themselves, as well as related examples and other documentation stored in the main project repositories , the authors prepared a reference implementation of their basic components - SPIRE (the SPIFFE Runtime Environment). Its code is written in Go and is a bunch of server and agent that represent the SPIFFE Workload API in action, i.e. allow you to certify software systems (workloads, "workloads") and issue them SPIFFE IDs and SVIDs.
SPIFFE's Workload API is similar to the AWS EC2 Instance Metadata API and the Google GCE Instance Metadata API in the sense that it does not require the caller to have prior knowledge of the subject or an authentication token. However, the authors note important distinguishing features of their development: 1) it runs on many platforms, b) it allows you to identify running services not only at the process level, but also at the kernel level, which allows it to be used with container schedulers like Kubernetes. To minimize the consequences of a key leak / compromise, all private keys (and corresponding certificates) do not live long and are subject to frequent (automated) rotation. Read more about SPIRE architecture here .
In addition, the project has libraries on Go (go-spiffe ) and C / C ++ ( C-SPIFFE ).
Work on SPIFFE is carried out within the framework of SIG (Special Interest Groups) by analogy with Kubernetes. Among the experts leading them are employees of Scytale companies (initiators and main authors of the project), Google, Pensando and Blend. In particular, there are teams that integrate SPIFFE with Kubernetes , gRPC and AWS .
The SPIFFE website states that the project "is in the early stages of implementation and is not yet ready for use in production".
PS
Read also in our blog:
- " CNCF Guide to Open Source Solutions (and more) for cloud native ";
- “ Four CNCF releases 1.0 and major announcements about Kubernetes with KubeCon 2017 ”;
- “ Rook is a“ self-serving ”data warehouse for Kubernetes ”;
- “ CoreDNS - DNS server for the cloud native world and Service Discovery for Kubernetes ”;
- “ Container Networking Interface (CNI) - the network interface and standard for Linux containers ”;
- “ Infrastructure with Kubernetes as an affordable service .”