How to learn to predict lateness of trains
Rail transportation, both freight and passenger, is one of the most popular modes of transport in our country. The fact that trains travel only on rails, on the one hand, simplifies and reduces the variability of the model, on the other hand, adds a lot of dependencies. If any unforeseen situation happens on the tracks, this can have significant consequences for the entire network. Deviation from the schedule of one train or an accident on rails can affect the movement of a whole direction. This affects both the companies that do not receive the goods on time, and the passengers who can be late for work, miss the necessary train, take the wrong train, or spend extra half an hour (or even more) on the platform.
My name is Alexander Podlevskikh, I’m a lead developer at Tutu.ru, a team leader in the Electric Train team, and in this article I will tell you how we predict train deviations from the schedule - being late and ahead of schedule. And also about what the GVC RZD is, how the system of suburban railway transport is technically arranged, and how we talk about passengers being late.

The main computing center of Russian Railways (GVC Russian Railways) is an organization whose main task is the information support of Russian Railways. In essence, the MCC is IT Railways.
The MCC system contains and processes colossal amounts of data. In a previous article, I described the interaction of Tutu.ru with the MCC, working with data on the basic schedule of electric trains and with options for their movement. Soon after, we also connected the use of data on the actual routing of commuter trains.
The actual follow-up data is a set of records in the database, each of which is the fact that the train passed the checkpoint in the route. These facts are recorded by sensors located at the entrance and exit from the stations. There are four types of sensors:
For each station, data in the MCC can come from several sources - depending on what equipment is installed on it. In addition, different sources may have different accuracy. For example, we analyzed that the signaling system has a significantly lower probability of error than SAIPS. Therefore, if there is data from both sources for the same event, we give priority to signaling. And at the moment, it is signaling that is the main source of data. In addition, we provide a source of data for each time on the pages of the route. This is a story, first of all, for advanced users who, having this data, can understand the approximate forecast accuracy.
All this data is collected in the DB2 database in the MCC system, and from there partners will pick it up for their own needs.
The rules for ensuring anti-terrorist security require the use of data of the actual succession of railway transport not less than 10 minutes ago. In addition, since the system is heavily loaded, partners (such as Tutu.ru ) can access it no more than once every few minutes. Because of this, users are not able to follow the actual composition, but how it followed 10 minutes ago. Moreover, the data comes only from sensors at the stations, and at small stops (where there may not even be a platform) or simply along the way, they are practically absent.
And there are also situations when the station’s investigation data is attached to the wrong composition. As a rule, such situations arise infrequently and are corrected by the employees of the MCC rather quickly. Nevertheless, in order to minimize such cases in our local data warehouse, we have to insure ourselves each time and request from the MCC more data depth than necessary. And even in this case, we cannot be 100% sure of the data - there are too many variables and all sorts of “buts”. But the degree of error is negligible (approximately 1 error per 100,000 entries).
To obtain and store actual follow-up data, a connection mechanism to the MCC was used, similar to receiving data from planned schedules (I described the mechanism in a previous article ). And for their use on our website, the previously built links of our local data and the MCC base, as well as the communications of stations (the algorithm is also described in the previous article) were useful in many ways. Using this correspondence, it was possible to connect approximately 90% of our entities with the actual succession data. For the rest of the trains, we found new connections by searching the numbers of trains and train stations.
We have a schedule page on the site (for example, Moscow - Petushki ), for display of which the “schedule” service is polled. It accepts the identifiers of departure and destination stations and the date of the trip, and in response provides a set of objects containing data of electric trains passing between these stations. It includes train identifiers - number, start / end station, timetable, as well as information about a specific train journey from one station to another - arrival / departure times, platforms. The answer does not contain the complete train route data (transit time of each intermediate station) - such a volume of information would be too large, the calculations would take longer and it is simply superfluous.
We needed to calculate a mark of a possible delay / advance on the basis of the actual follow-up data, which are compared with the schedule data from our local database. Sometimes the calculation is based not on the last record about the passage of the control point by train, but on several. This happens when different sensors work with varying degrees of accuracy. For example, at some station, a strong difference appears between the actual train and the planned one. And then we look at the time of passing the previous station.
That is, we were faced with the task of showing users information about the possible deviation of trains from the schedule.
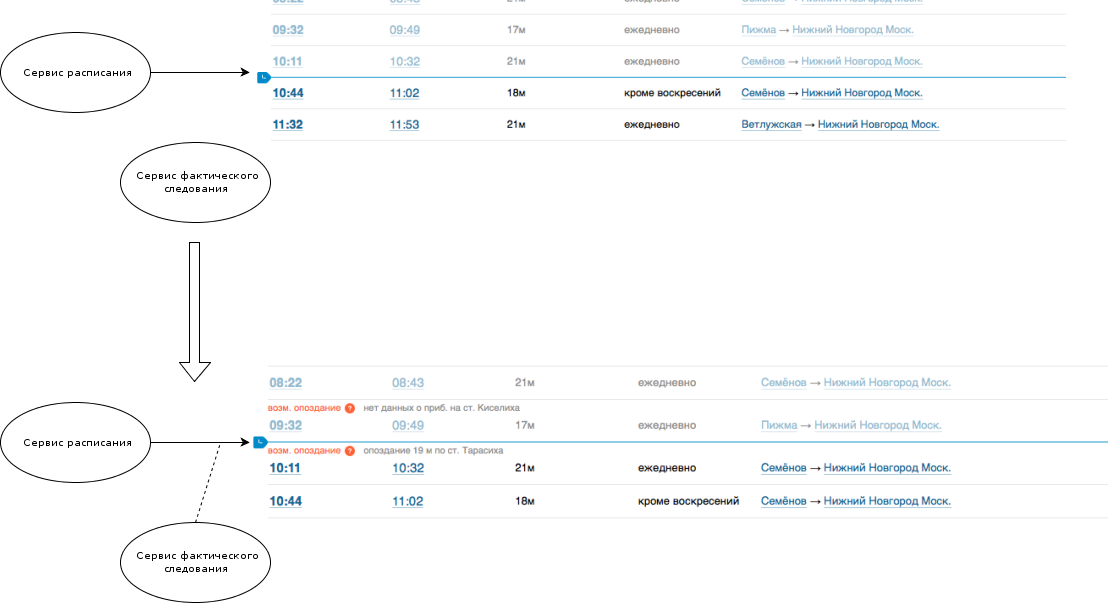
Actual follow-up data only from the MCC to solve this problem would not be enough for us. And we made a microservice, the task of which is to return the full route by train identifier, including data not only from the planned schedule, but also the actual data on the passage of stations.
The algorithm of the service is as follows: we get the train identifier at the entrance and make a request to the schedule service to get the current route. Next, another request - to a service that stores connections between our local trains and trains in the MCC system. If there is a connection, then from the actual data storage service we get all the information about the train passing the control points. If there are no connections in our storage, or there is no actual data on these connections, then we make a request to receive data by train number and by passing stations. If in the second case the data were found, then we establish a new connection between the found train and ours, for which the search was performed.
In order to correctly mix the data of the actual following to the route, it is necessary to understand what fact belongs to which station. In the actual route data, the station is identified by the ECP code - the station number in the Express-3 system, in the data of our routes the stations have their own identifiers.
To match stations, requests are made in 3 more services: a communication service between our stations and stations in the MCC. Based on these identifiers, a request is made to the local MCC data storage service to obtain complete information about the stations (with ECP identifiers). In addition, a request is made to the service of local stations, from which Express-3 codes are obtained. Knowing the communications of the stations, we are building the electric train route for the current date with the planned passage of the stations and the actual passage of these stations.
In the first version, the service worked just like that - when opening the pages, requests were made for each train in the schedule, and there was no caching. Moreover, the overwhelming majority of inquiries are in Moscow directions “for today” (more than 100 electric trains run daily here).
In general, when the mechanism for production was turned on by 5% of users, we got a load of about 6000 rps in total for all services used. The infrastructure was not ready for this. It was necessary to optimize the work, reduce the total number of requests. We solved this problem as follows:
As a result, the scheme of calculating the train route with actual data is as follows:

It works on each page of the schedule for the current date for 30-50% of trains and gives an overhead for page loading up to 100 ms at 90 percentile.
Based on the data obtained, it can be concluded that the train is late or is ahead of schedule.
First of all, we analyze whether there is any actual data for a particular train, when it should already be. If they are not, then we write that it is possible to be late, because the train should have started from the starting station more than 5 minutes ago, but this did not happen.
If there is data, then data is analyzed for the last or last two stations (for reliability), for which there is data of the actual sequence. If there are deviations from the schedule, then the train is marked as “possibly late / very late / advanced”. In addition, a reason is written - for example, that the train to one of the previous stations arrived with a delay of several minutes.
Another small but useful improvement is this. Let's say we have a train Semenov - Nizhny Novgorod, which passes through 2 stations - Tarasikha and Kiselikha. The train starts from Semyonov at 9:20, arrives at Tarasikha at 9:43, arrives at Kiselikha at 10:11, and arrives in Nizhny Novgorod at 10:32, or rather should arrive. But according to actual data, we see that the train only reached Tarasikha at 10:02 (that is, it is already 19 minutes late). A frozen passenger on a deserted platform in Kiselikha looks at the schedule at 10:25, and if we showed only the schedule data, then the person would decide that the train had already left. But, since it’s not possible to catch up with the schedule of 19 minutes in practice, we show this train as it has not yet left Kiselikha.

If according to the latest received data the train runs according to the schedule, then the following stations are analyzed, according to which the actual data usually follows. If there is no data on them on time, then most likely the train was late somewhere on the stage and we show a warning that it has not arrived at the intermediate station yet, although it should already.
But that is not all. It happens that a person watches the schedule from Moscow, standing on the Chukhlinka platform. Here, the story with the actual following does not work, since Moscow is the starting point of the path. There is either no information or it is, but this means that the train has already left. In this case, we analyze the speed of movement of the trains.
In most cases, one electric train per day makes more than one trip, but runs along the route all day. At the same time, for each trip, his number changes, the crew of drivers can change. In all systems with a schedule (both ours and the MCC), these are different objects. However, in many cases, the systems have information on which flight the electric train will be sent in the future. The composition itself may be different every day, but it is a bunch of flights that is fixed. And, if the train travels late on the first trip, then the second trip will also begin late. There are exceptions to these rules, for example, if the delay is very strong, then another train may be allowed on the second trip, but in practice this happens quite rarely.
Having data on such connections, we also analyze data on the actual number of trains served by the same train and show a warning about a possible delay. But this is done only if the delay of the previous flight can affect the one that the user is watching.
In general, the next time you gather from Tarasikha to Kiselikha - be sure that we will notify you of a late train.
My name is Alexander Podlevskikh, I’m a lead developer at Tutu.ru, a team leader in the Electric Train team, and in this article I will tell you how we predict train deviations from the schedule - being late and ahead of schedule. And also about what the GVC RZD is, how the system of suburban railway transport is technically arranged, and how we talk about passengers being late.
What is the actual following of trains and trains
The main computing center of Russian Railways (GVC Russian Railways) is an organization whose main task is the information support of Russian Railways. In essence, the MCC is IT Railways.
The MCC system contains and processes colossal amounts of data. In a previous article, I described the interaction of Tutu.ru with the MCC, working with data on the basic schedule of electric trains and with options for their movement. Soon after, we also connected the use of data on the actual routing of commuter trains.
The actual follow-up data is a set of records in the database, each of which is the fact that the train passed the checkpoint in the route. These facts are recorded by sensors located at the entrance and exit from the stations. There are four types of sensors:
- ASOUP (automated system for the operational management of transportation). In fact, this is a system that aggregates data from the tracks and allows you to monitor all shipments. In particular, compliance with the plans for the formation, mass and length of freight trains, forecasting the arrival of goods, accounting for the passage of trains, wagons and containers through the butt points of roads and branches ( ASOUP ). From here, the MCC receives information about whether the train passed the station or not.
- Signaling, signaling, centralization and blocking devices - a set of technical means used to regulate and ensure the safety of train traffic ( signaling, centralization and blocking devices ). In fact, these devices are sensors on railroad switches, the data from which are supplied to the MCC.
- SAIPS (Automation System for identifying rolling stock) - devices that stand along the tracks and fix cars passing by.

- GIS (Geoinformation System of Russian Railways) is a GLONASS-based geolocation system that allows you to monitor railroad transport performance, speed in sections, traffic safety violations, and more.
For each station, data in the MCC can come from several sources - depending on what equipment is installed on it. In addition, different sources may have different accuracy. For example, we analyzed that the signaling system has a significantly lower probability of error than SAIPS. Therefore, if there is data from both sources for the same event, we give priority to signaling. And at the moment, it is signaling that is the main source of data. In addition, we provide a source of data for each time on the pages of the route. This is a story, first of all, for advanced users who, having this data, can understand the approximate forecast accuracy.
All this data is collected in the DB2 database in the MCC system, and from there partners will pick it up for their own needs.
Interaction with the MCC
The rules for ensuring anti-terrorist security require the use of data of the actual succession of railway transport not less than 10 minutes ago. In addition, since the system is heavily loaded, partners (such as Tutu.ru ) can access it no more than once every few minutes. Because of this, users are not able to follow the actual composition, but how it followed 10 minutes ago. Moreover, the data comes only from sensors at the stations, and at small stops (where there may not even be a platform) or simply along the way, they are practically absent.
And there are also situations when the station’s investigation data is attached to the wrong composition. As a rule, such situations arise infrequently and are corrected by the employees of the MCC rather quickly. Nevertheless, in order to minimize such cases in our local data warehouse, we have to insure ourselves each time and request from the MCC more data depth than necessary. And even in this case, we cannot be 100% sure of the data - there are too many variables and all sorts of “buts”. But the degree of error is negligible (approximately 1 error per 100,000 entries).
Using
To obtain and store actual follow-up data, a connection mechanism to the MCC was used, similar to receiving data from planned schedules (I described the mechanism in a previous article ). And for their use on our website, the previously built links of our local data and the MCC base, as well as the communications of stations (the algorithm is also described in the previous article) were useful in many ways. Using this correspondence, it was possible to connect approximately 90% of our entities with the actual succession data. For the rest of the trains, we found new connections by searching the numbers of trains and train stations.
So, what was the task:
We have a schedule page on the site (for example, Moscow - Petushki ), for display of which the “schedule” service is polled. It accepts the identifiers of departure and destination stations and the date of the trip, and in response provides a set of objects containing data of electric trains passing between these stations. It includes train identifiers - number, start / end station, timetable, as well as information about a specific train journey from one station to another - arrival / departure times, platforms. The answer does not contain the complete train route data (transit time of each intermediate station) - such a volume of information would be too large, the calculations would take longer and it is simply superfluous.
We needed to calculate a mark of a possible delay / advance on the basis of the actual follow-up data, which are compared with the schedule data from our local database. Sometimes the calculation is based not on the last record about the passage of the control point by train, but on several. This happens when different sensors work with varying degrees of accuracy. For example, at some station, a strong difference appears between the actual train and the planned one. And then we look at the time of passing the previous station.
That is, we were faced with the task of showing users information about the possible deviation of trains from the schedule.
Actual follow-up data only from the MCC to solve this problem would not be enough for us. And we made a microservice, the task of which is to return the full route by train identifier, including data not only from the planned schedule, but also the actual data on the passage of stations.
Work algorithm
The algorithm of the service is as follows: we get the train identifier at the entrance and make a request to the schedule service to get the current route. Next, another request - to a service that stores connections between our local trains and trains in the MCC system. If there is a connection, then from the actual data storage service we get all the information about the train passing the control points. If there are no connections in our storage, or there is no actual data on these connections, then we make a request to receive data by train number and by passing stations. If in the second case the data were found, then we establish a new connection between the found train and ours, for which the search was performed.
In order to correctly mix the data of the actual following to the route, it is necessary to understand what fact belongs to which station. In the actual route data, the station is identified by the ECP code - the station number in the Express-3 system, in the data of our routes the stations have their own identifiers.
To match stations, requests are made in 3 more services: a communication service between our stations and stations in the MCC. Based on these identifiers, a request is made to the local MCC data storage service to obtain complete information about the stations (with ECP identifiers). In addition, a request is made to the service of local stations, from which Express-3 codes are obtained. Knowing the communications of the stations, we are building the electric train route for the current date with the planned passage of the stations and the actual passage of these stations.
In the first version, the service worked just like that - when opening the pages, requests were made for each train in the schedule, and there was no caching. Moreover, the overwhelming majority of inquiries are in Moscow directions “for today” (more than 100 electric trains run daily here).
In general, when the mechanism for production was turned on by 5% of users, we got a load of about 6000 rps in total for all services used. The infrastructure was not ready for this. It was necessary to optimize the work, reduce the total number of requests. We solved this problem as follows:
- They limited the number of trains for which requests are made. They now leave not for all trains on the current day, but only for the next ones: which will leave within a few hours or have already left. This reduced requests by about 2 times. But that was not enough.
- Next, we did not download data for each individual train, but for a train of trains. There were attempts to vary the number of elements, but another problem surfaced - if you increase the size of the pack, this significantly slows down the loading of pages, since the data is generated not in parallel, but in series.
- The next way is to cache static data (connections between trains and stations). This improvement has already significantly facilitated the overall picture - we were able to enable the delivery of 100% of users. However, at peak hours (Monday morning and Friday evening) there were still problems and periodically the resources allocated for the servers ran out.
- Then we added a cache with the totals: the train route + the actual follow-up with all the calculated matches. This significantly accelerated the average loading of pages. But, since we get the latest actual follow-up data every few minutes, and the service that performs the final calculations has no idea which electric train received the new data and which not, we had to check the time since the last data download. If this time is more than what was previously, the cache is completely reset. This had an effect, and the average page load time was greatly reduced. But at the time of receiving data and, accordingly, flushing the cache, due to the huge number of requests, the load time still jumped. At peak hours, the graph looked like a cardiogram.
- And finally, the final cache was added to the data storage service - and now it completely leveled the situation. That is, now the result of the query to the database is cached, and when new data is received, it is updated only for those trains for which this data was received.
As a result, the scheme of calculating the train route with actual data is as follows:
It works on each page of the schedule for the current date for 30-50% of trains and gives an overhead for page loading up to 100 ms at 90 percentile.
Data analysis
Based on the data obtained, it can be concluded that the train is late or is ahead of schedule.
First of all, we analyze whether there is any actual data for a particular train, when it should already be. If they are not, then we write that it is possible to be late, because the train should have started from the starting station more than 5 minutes ago, but this did not happen.
If there is data, then data is analyzed for the last or last two stations (for reliability), for which there is data of the actual sequence. If there are deviations from the schedule, then the train is marked as “possibly late / very late / advanced”. In addition, a reason is written - for example, that the train to one of the previous stations arrived with a delay of several minutes.
Another small but useful improvement is this. Let's say we have a train Semenov - Nizhny Novgorod, which passes through 2 stations - Tarasikha and Kiselikha. The train starts from Semyonov at 9:20, arrives at Tarasikha at 9:43, arrives at Kiselikha at 10:11, and arrives in Nizhny Novgorod at 10:32, or rather should arrive. But according to actual data, we see that the train only reached Tarasikha at 10:02 (that is, it is already 19 minutes late). A frozen passenger on a deserted platform in Kiselikha looks at the schedule at 10:25, and if we showed only the schedule data, then the person would decide that the train had already left. But, since it’s not possible to catch up with the schedule of 19 minutes in practice, we show this train as it has not yet left Kiselikha.
If according to the latest received data the train runs according to the schedule, then the following stations are analyzed, according to which the actual data usually follows. If there is no data on them on time, then most likely the train was late somewhere on the stage and we show a warning that it has not arrived at the intermediate station yet, although it should already.
But that is not all. It happens that a person watches the schedule from Moscow, standing on the Chukhlinka platform. Here, the story with the actual following does not work, since Moscow is the starting point of the path. There is either no information or it is, but this means that the train has already left. In this case, we analyze the speed of movement of the trains.
Revs
In most cases, one electric train per day makes more than one trip, but runs along the route all day. At the same time, for each trip, his number changes, the crew of drivers can change. In all systems with a schedule (both ours and the MCC), these are different objects. However, in many cases, the systems have information on which flight the electric train will be sent in the future. The composition itself may be different every day, but it is a bunch of flights that is fixed. And, if the train travels late on the first trip, then the second trip will also begin late. There are exceptions to these rules, for example, if the delay is very strong, then another train may be allowed on the second trip, but in practice this happens quite rarely.
Having data on such connections, we also analyze data on the actual number of trains served by the same train and show a warning about a possible delay. But this is done only if the delay of the previous flight can affect the one that the user is watching.
In general, the next time you gather from Tarasikha to Kiselikha - be sure that we will notify you of a late train.