Complexity Control and UDF Architecture

Complexity is the main enemy of the developer. There is such a hypothesis, although I would attribute it to the axioms that the complexity of any software product over time, in the process of adding new functionality inevitably grows. It grows until it reaches the threshold at which any change is guaranteed, i.e. with a probability close to 100%, will introduce an error. There is also an addition to this hypothesis - if such a project continues to be further supported, then sooner or later it will reach such a level of complexity that it will be impossible to make the necessary change at all. It will be impossible to come up with a solution that does not contain any crutches, notorious antipatterns.
Source of difficulty
Complexity is inevitably introduced by input requirements, it is impossible to avoid this type of complexity. For example, in any accounting program you have a task to make payments to a person, and among the calculation of these payments there is such a requirement that a person who has worked in the company for more than a certain period is charged an additional amount for the experience. The application code will inevitably contain something like this:
if(qualifiedForExtraPayment(employee)) {
calculateThatExtraPayment(...)
}
This if is the element of complexity introduced into the application by a business requirement.
But there is a complexity that is not defined by the requirements, and is introduced directly by the developer. Most of all this "artificial" complexity comes from some peculiarity of the developers understanding of the DRY principle .
For example, in the already mentioned hypothetical accounting program, you need to make two almost identical pages, on both you need to calculate the payments to the person, and show detailed information on these payments. But one page is purely informational, to see how many people will receive money, and the second page is already executive, where the third action is present - to make the actual money transfer.
The example is certainly fictional, but I encounter similar things in the code of other developers regularly.
How to solve it.
On the first page, the pseudocode will be like this
const payment = calculatePayment(employee);
displayPayment(payment);
On the second page
const payment = calculatePayment(employee);
displayPayment(payment);
proceedWithPayment(payment);
How is it sometimes decided.
Instead of creating the second method, an additional parameter is introduced into the first
const payment = calculatePayment(employee);
displayPayment(payment);
if(isOnlyInformation) {
return;
}
proceedWithPayment(payment);
And here we see another if, another element of complexity in our application. This point of complexity does not come from the requirements, but from the way the developer solves the problem.
Where the code is already sufficiently decomposed, it turns out that the two methods "stuck together" into one due to the fact that only two lines coincided in them. But initially, at the stage when the code is first written “forehead”, the implementation of these methods (calculatePayment and displayPayment) may not yet be put into separate methods, but written directly in the body of this, and the picture looks like the two methods are the same, say , 100 first lines. In such a case, this “getting rid of code duplication” might seem like a good solution. But this is obviously not the case. In my last article about dry antipatternI have already given examples of how using the DRY principle brings complexity to your application that can be avoided. With ways to write the same code, but without using this pattern, without introducing complexity into the application that does not come from the requirements.
Thus, we come to the conclusion that in the hands of one developer the complexity of the application grows linearly, in proportion to the complexity of the requirements, well, or at least tends to this, in the hands of another developer the complexity grows exponentially.
Principle of sole responsibility
“Evenly distributed” complexity is not so harmful and dangerous for all its inevitability, but it becomes a terrible dream for a developer when he concentrates in one place. If you have an if in the function, then you add a second branch, if there are two, and it doesn’t matter whether it is nested or not, there will be at least 4 possible options for passing through the method, the third if will do 8. And if you have two separated successfully decomposed, not influencing each other functions, in each of which there are 4 branches of execution, then each of them potentially needs to write four tests, total 8. If it was not possible to decompose, and all this logic is in one method, then the tests you need to write 4 * 4 => 16, and each such test will be more complicated than tes of the first eight. The number and complexity of the tests reflect the final complexity of the application,
A widely known code design principle, hereinafter referred to as SRP, the first paragraph of the SOLID Principles Collection, is aimed at combating such a pile of complexity. And while the remaining letters of this abbreviation contain rules for the most part refer to object-oriented programming, then SRP is universal, and is applicable not only to any programming paradigm, but also to architectural solutions, to say nothing, to other engineering areas as well. The principle, unfortunately, contains some understatement, it is not always clear, but how to determine now the only responsibility for something or not. For example, here is a god-class of a million lines, but it has the sole responsibility of controlling the satellite. But he does nothing else, does everything mean in order? Obviously not. The principle can be rephrased somewhat - if a certain element of your code, and this can be either a function, a class, or the whole layer of your application, has too much responsibility, then you need to decompose, break it into pieces. And the fact that there is too much of it can be determined just by such signs - if the test for this is too complicated, contains many steps, or if you need a lot of tests, then there is too much responsibility, and you need to decompose. Sometimes this can be determined even without looking at the code. According to the so-called code-smell, if I go into a file with one class and see 800 lines of code there - I don’t even need to read this code to see that this class carries too much responsibility. If the file contains a whole page of dependencies (imports, yuzings, etc.), I don’t have to scroll down and start reading this code to come to the same conclusion. There are certainly different tricks, IDEs indulge citizens with coders, collapsing imports “under the plus sign”, there are tricks of Mr. coders themselves, who put a widescreen monitor upright. I repeat, I do not even need to read the code of such a developer in order to understand that I most likely will not like it.
But decomposition is not required to reach the absolute, “the other end of this stick” - a million methods each with one operand can be no better than one method with a million operands. Again, with excessive decomposition, the first of those two playful “most complex programming tasks” will inevitably arise - function naming and cache invalidation. But before reaching this point, the average developer must first learn how to decompose it at least minimally, at least move slightly away from that end, with a class of 800 lines.
By the way, there is another such jokingly philosophical thought - a class, as a concept, carries too much responsibility - behavior and condition. It can be divided into two entities - functions for behavior and “plain” objects (POJO, POCO, etc., or structures in C) for the state. Hence, the OOP paradigm is untenable. Live with it.
Architecture as a struggle with complexity
As I said, complexity, as well as multiplication of complexity, are not specific to programming; they exist in all aspects of life. And the solution to this problem was proposed by Caesar - divide and conquer. Two problems linked to each other are more difficult to defeat than both of these problems separately one after another, as well as more difficult to defeat two barbarian tribes united to fight the Romans. If they are somehow separated from each other, then individually defeating one tribe, then another is much easier. At a low level, when writing already specific code, this is decomposition and SRP. At a high level, at the application design level, architectural solutions serve this.
From here on I focus on UI / frontend specifics.
For the development of applications containing UI, architectural solutions such as MVC, MVP, MVVM have long been used. All these solutions have two common features, the first is M, the "model". They even give her some kind of definition, I will manage here with such a simplification - the rest of the program. The second is V, "view" or view. This is a layer separated from the rest of the application, whose sole responsibility is a visual representation of the data coming from the model. These architectures differ in the way M and V communicate with each other. Of course, I will not consider them, I will only pay attention once again that all the efforts spent on the development of these architectures were directed at separating one problem from another, and, as you might guess, at reducing the complexity of the application.
And, saying that visual representation is the only responsibility of this layer, I just mean the fundamental principle of these architectures - there should not be logic in the presentation layer. Absolutely. It is for this that these architectures are conceived. And speaking of MVC architecture, there was still such a term “thin controller”. Using this architecture, people came to the conclusion that the logic controller should not contain. Absolutely. For logic, this will be the second responsibility of this layer, and we must strive to ensure that it is one.
Unidirectional Data Flow Architecture
Motivation
The purpose of this architecture, as well as the goal of the previously mentioned architectures, is exactly the same - to reduce the complexity of the application, by separating problems among themselves, and erecting a logical barrier between them. The advantage of this architecture is why it should be preferred to other architectures in the following. Applications are not limited to one “view” and one “model”, in any application you will have several of them. And there must be some kind of connection between them. I’ll take the following as an example - you need to calculate some amount according to the table. In one view, a person enters data in a table, another model subscribes to this data, calculates the amount, tells his view that it needs to be updated. Further, we expand the example by the fact that then a third model is signed for this amount, in which you need to make the "Apply" button active. Moreover, sometimes the developer may be confused,
This is already a mistake, comparing two numbers is already the logic that a model should strictly control, the markup should operate with flags strictly calculated for it -
In especially advanced cases, it is in view that this relationship between two models is written, data from a foreign model is checked, and a method that carries side effects in its model is called. In any case, between the models a sort of change propagation graph appears.
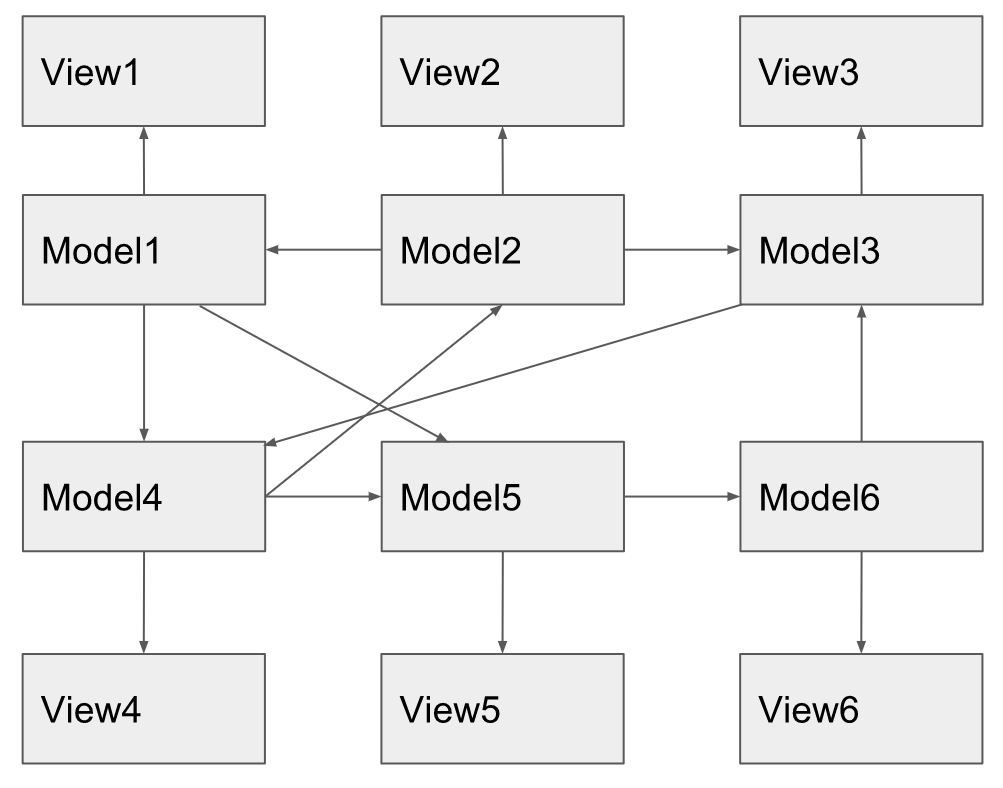
Sooner or later, this graph becomes uncontrollable and, making changes, it is not easy for the developer to track what consequences this will have in the side-effects that occur below the graph. In a presentation from Facebook, it was called downstream effects, this is not a term. Also, another developer trying to fix the error that occurred below the graph will have difficulties in tracking the root-cause of this problem, which lies one or even several steps higher in this graph. In some places, this graph can also go in cycles, and the condition for exiting this cycle can be broken by a harmless change at a completely different point in the graph, as a result, your application hangs and you cannot understand why. It is easy to see that the change propagation graph does not come from customer requirements. They only dictate sequential actions that need to be performed, otherwise, that these actions are scattered throughout the code as {substitute the necessary epithet}, and between them are inserted subscriptions, event throws, etc. It is already on the conscience of the developer.
You can read a little more about this in Redux motivation .
The UDF architecture is a pipeline that has two fundamental restrictions imposed 1) the next stage of the pipeline has no right to influence the previous one, or the results of its execution. 2) The "looping" of the conveyor can only produce input from the user. Hence the name of the architecture - the application independently moves the data in only one direction, towards the user, and only external influence can go in the direction opposite to this main stream.
There are two main stages in the pipeline, the first is responsible for the state, the second is for display. In some ways, it looks like a model and a representation in the above architectures, the difference as well as between those architectures is in the interaction of the model with the representation. And in addition to this, in the interaction of models with each other. The entire state of the application is concentrated in a certain store, and when a certain external event occurs, for example, user input, all state changes from point A (to an external stimulus) to point B (after the stimulus) must occur in one action. That is, in the same script above, the code will look something like this, using the redux example in redux:
function userInputHappened(prev, input) {
const table = updateRow(prev.table, input);
const total = calculateTotal(prev.total, table);
const canProceed = determineCanProceed(prev.canProceed, total);
return {
...prev,
table,
total,
canProceed
};
}
This illustrates a key principle, the main difference from the usual construction of logic. There are no subscriptions of one to the other, no thrown events between two consecutive operations. All actions that need to be performed on a given external stimulus should be written sequentially. And when making changes to such code, all the consequences of the changes are visible. And, as a result, this artificially introduced complexity is minimized.
Redux
Initially, the UDF frontend architecture was proposed by Facebook as part of a bundle of two react and flux libraries, a bit later flux was replaced by redux, offering a couple of very important changes. First, state control is now supposed to be written with clean code, in fact, all of our state management can now be described with one simple formula

The next state is equal to a pure function of the previous state and some stimulus.
Second - the presentation layer is now another clean function

That is, the task of all UI components is to get an object at the input, to give the markup as a result.
Thus, the following is achieved:
1. "unclean", asynchronous code is shifted from the application to its edge, two large, you can even say the defining blocks of your application become clean.
2. Very cool instruments. The first one is hot reload, which allows you to replace the pure render function on the fly without losing state, that is, you can “hot” edit the UI layer and immediately see the result. without restarting the application each time, and also without the need to "click" to the point of playback of the bug. The second tool - time travel, allows you to remember all your states from State (1) to State (n), and walk them forward backwards, looking sequentially at what could go wrong where. Additionally, it is possible to reproduce the bug on one PC, export the timeline, and download it on another PC, that is, transfer the bug from the tester to the developer even without describing the steps for playing this bug. But this second tool imposes one more requirement - state and the actions of your application must be serializable. Those. even base classes such as Map or DateTime cannot be used. Only POJO. In addition, in reducers, you cannot rely on the reference equality of objects; you need to compare by value, for example, by id.
3. reuse - ask yourself questions - did you come across a case when some UI component creeps into the model, receives data for itself, processes and displays it?
Has it ever happened that a new task comes in to use the same UI, but with a different data source, or in a different scenario, with a different set of actions? Sometimes reusing the same markup in another scenario is simply unrealistic.
It is quite another thing to reuse a piece of UI that takes an object and produces markup as a result. Even if you have a different data construct in the right place, you convert it to what this component accepts, insert it into yourself and give it this object. As a result, you are completely sure that it will render what you need and it will not suffer absolutely any side effects.
Same thing with state management. You have a function that updates a row in a table. Suppose she does something else inside herself, normalizes the table in some way, sorts it, etc. What is worth calling a pure function from another script? You are again confident that it will not suffer any side effects.
Reusing the whole script becomes impossible. By virtue of the fact that there is a complete decoupling of the presentation state. And the entry points for such reuse will have to be duplicated, but the main "meat" at such entry points can and should be reused.
Unfortunately there is no good and without a trace, Redux has lost one important limitation. As I have already said, “looping” can only be initiated by the user, and such a restriction was implemented in FLUX - you cannot throw a new Action in the state change subscription handler, but this throws an exception. That is, the UI component, subscribed to the party, in the processor of this subscription does not have the right to make an additional change in the state. Only render, only hardcore. Reduced this exception in redux.
Example of incorrect use of Redux and UDF
In one of our applications, a violation of a lot of things was discovered, up to common sense.
1) The logic is located directly in the UI components, the UI component decides what data to load
2) The UI components are inherited from each other (sick!) And from some other classes.
3) UI components are called * Adapter (what's next, * Injector, * Factory?)
4) UI component “knows” where “its” data and data of other components are in the state tree
5) UI components independently subscribe to a part of the state, new actions are thrown as a result of processing to change “their” state, a looping architecture in which obviously there should not be these loops
The motivation for this design was the desire to make a single point of reuse. And this point, of course, in the UI layer, right in the markup. It sounds something like this - I insert the UI component, it is automatically picked up (yes, these are the words I hear all the time from neighboring cubes, it is hooked, injected, signed, forwarded, the code-smell is already felt remotely, by ear) its state, the component is subscribed to the state neighboring components that produce input for him, the data on which he depends, he receives data from the backend for both initial and lazy loading. And when the api method suddenly changes in this component used in three applications, or you need to add new logic to this component, then we will add this to the component, and this accordingly applies in three places at once.
What should I do if one of the three places has a different data source, or another processing logic somewhere in the middle of this component - this architectural solution does not suggest this. As they say - well, do something, tyzhprogrammer. Obviously you need to get inside, write a new logic, and stick an if, which turns it on for the 3rd scenario and turns it off for the first two.
The graph of distribution of changes in this application looks like this:
It turned out that people used redux in their application, got its negative sides, in particular, the “noisy” syntax, which for anybody implies a change in 4 files, but did not get the advantages that it carries .
If you try to depict the graph of the distribution of changes, then it is easy to see that it is very similar to the graph that was used as an anti-example in the presentation of Facebook.
Total:
1) UDF architecture has been violated, and redux is supposed to implement it, and not as a fancy pub-sub.
2) Hard coupling of the markup with state
3) The principle of SRP is violated - logic in the presentation layer
4) Common sense is violated - the name / purpose of the components of the presentation layer.
Comparison with reactive programming
There is another concept suitable for creating UI applications, which is also "better than regular powder." And for her, as well as for implementing her frameworks, there are many agitators.
It involves such an interaction between models in which when you change an entity, you do not need to take care of dependent entities, they themselves will find that it has changed and will recount themselves.
I will write the pseudo-code using the example of the knockoutJS framework.
We have tableVm, it has a table field, and a function that allows you to update this table
tableVm.table = ko.observable(someInitialData);
tableVm.updateTable = function(input) {
const current = tableVm.table();
const updated = ... // some code here
tableVm.table(updated);
}
Further there is a code in another (sometimes in the same) View-Model
tableTotalVm.total = ko.computed(() => tableVm.table().map(...).sum());
In the third VM, the following code
submitVm.canProceed = ko.computed(() => tableTotalVm.total() === 100);
It is easy to see that we, what is called “back to square one,” came to what UDF deliberately left — one piece of code is signed to another, the second is signed to the third, etc. Sooner or later, we come to a large and uncontrolled graph of the distribution of changes.
In addition, the reverse distribution of changes is also expected.
Here I’ll give a simpler example, where at the lower level an index starting from zero is stored, and on the UI you need to map from one to the index, that is, you need to convert it to one side, when something changes on the UI, then you need to convert to the lower level, respectively back.
lowerVm.index = ko.observable(indexLoadedFromApi);
upperVm.index = ko.computed(
() => lowerVm.index() + 1),
(newVal) => lowerVm.index(newVal - 1)
);
And when the UI changes the upper value in such a system, computed pushes this change to the lower model. Because if the lower model has changed, then you need to recount the upper model again, and update the UI accordingly. There may still be such a situation - when you put one value on top, and from this whirl of updates, another was recounted, either due to an error in the code or due to fuzzy logic. In this case, in the circular dependency detection framework, the mechanism may not work correctly and you will either “hang” or get an exception in a completely incomprehensible place, with a silent error message, or even stack overflow.
And the very fact of the existence of such a mechanism, as it were, says that there is a danger of creating looping dependencies. And sometimes cyclic dependencies are dictated by business requirements. Imagine a game like Civilization where there are three sliders, science, culture and production, their sum should always be 100%, you turn one up, the other two automatically go down proportionally. Try to implement something with three computed. Or, for example, a life simulator. It turns out that this will not be a thousand computed dependent on each other, but one observable, in which there will be an entire model of the entire application. And the question is, do we need this one observable in the application.
HereThere is an opinion of the author who advocates reactive programming, not quite the same as in knockout, but there is a suspicion that the symptoms there are exactly the same. And the author joyfully exposes the UDF "in a bad light", with emoticons. Which very clearly shows that sometimes even people who consider themselves experts in writing UI applications, probably even deservedly consider them, do not understand this architecture at all. It really is not easy to understand, because it breaks everything that is used to for many years.
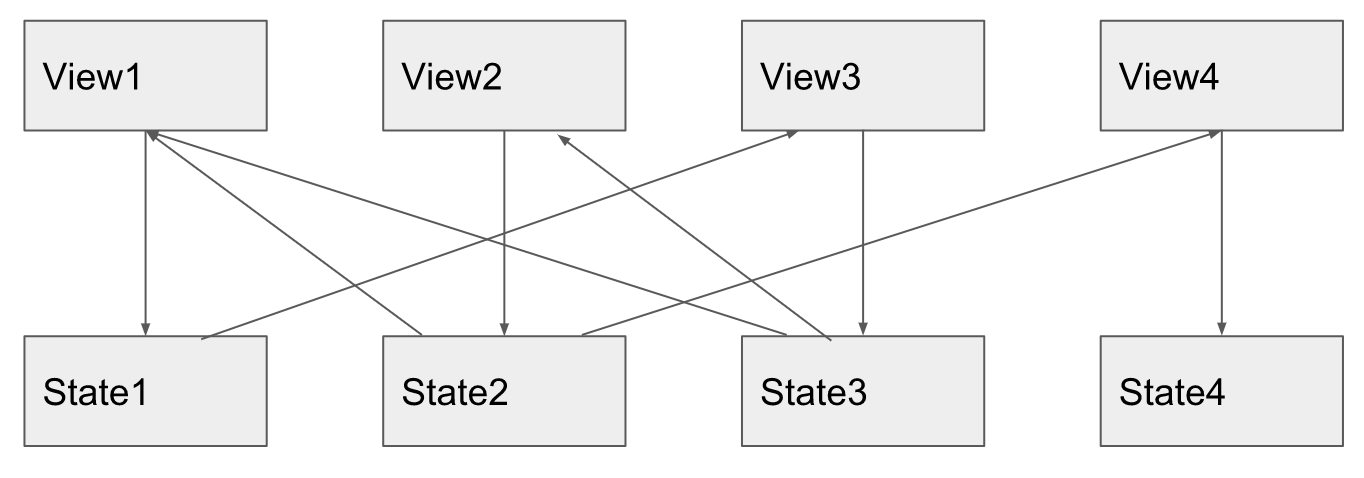
This misunderstanding can be seen by the way the diagram is drawn, and it is drawn with a single model, a single view, where it is not clear what exactly UDF should win the minds of developers. Where all architectures look good, and in general it is not easy to understand the difference between them. And you need to draw a situation where there are a lot of these models and views. And where there are a lot of them using reactive programming, the change distribution diagram looks something like this:

Here I drew, as with any user action in view1, the changes are distributed sequentially to different computed, then to some observable ones, and it is clear that computed5 will be recounted twice, and view3 will also be updated twice. In our knockout application, we also once ran into such an effect, where one computed was recounted N times, by the number of elements in the array. The claimed loud advantage that knockout updates only what is needed, and its jet model brings performance to the world, at that moment burst with a bang.
Application with UDF
When I studied the react / redux application examples, I had a feeling that it was not fully developed. In particular, the redux author himself, Den Abramov, proposes directly in the UI components to write in the same files the so-called dispatchToProps functions that hang on the props ui components of the following
(dispatch) => {
return {
someMethod: (someData) => {
dispatch({type: Actions.someAction, someData });
}
}
};
Sometimes these methods become more complex, their content expands, including asynchronous operations
(dispatch) => {
return {
async someMethod: (someId) => {
dispatch({type: Actions.startedLoadingAction });
const someData = await api.loadSomeData(someId);
dispatch({type: Actions.someAction, someData });
}
}
};
It is easy to see that this is business logic. And for a long time I was crucified on the topic that there is no place for business logic in the UI layer. In addition, this logic, located in the second step of the pipeline, affects the first, which violates the UDF architecture itself. The fact that you can’t do this, it became obvious right away, how can you do and need to? After some time, after research, trial and error, the answer came. Moreover, the obviousness of this answer is striking in its simplicity - the code that affects the Nth step of the pipeline should be on the step of the N-1 pipeline. In addition, the statement that the asynchronous code should be shifted to the edge of the application also acquires a refinement to which edge. Suddenly this is where the backend is, the connection with which is asynchronous. The puzzle developed, and even the socks matched in color. We need to create one more step of the conveyor,
The general diagram is as follows.
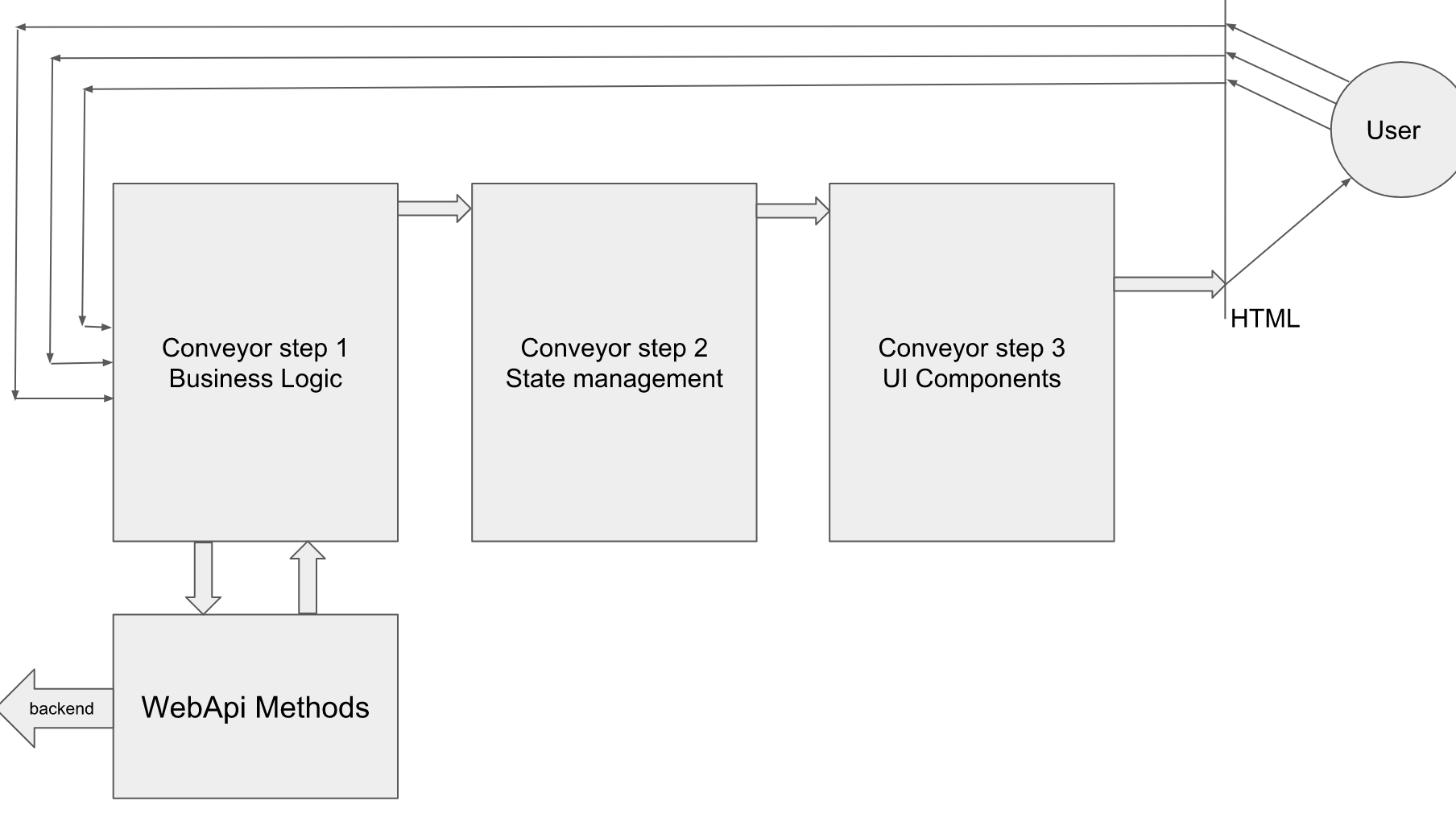
At the moment of entering the page / application, we need to create a store, and then call the first input method in the pipeline. I will continue to call this an irritant method. And also issue a single subscription UI per side. The irritant method by calling the corresponding Action initializes the state to the “progress indicator” position, then the UI subscription is triggered accordingly and draws what it looks like.
The irritant method, by the following action, causes an asynchronous action on the loading of the initial data. When the response comes from the server, the next pass on the pipeline occurs, with another render.
In the markup, similar things are located
thus, there is no business logic in the ui-layer, there is only an indication of which stimulus method to pull with the appropriate user action.
In this case, the developer can decide whether all pages of the application have a common root, or each page may have its own root. In the latter case, each page initializing the side will have to indicate its reducer.
The interaction of the first step of the pipeline with the second.
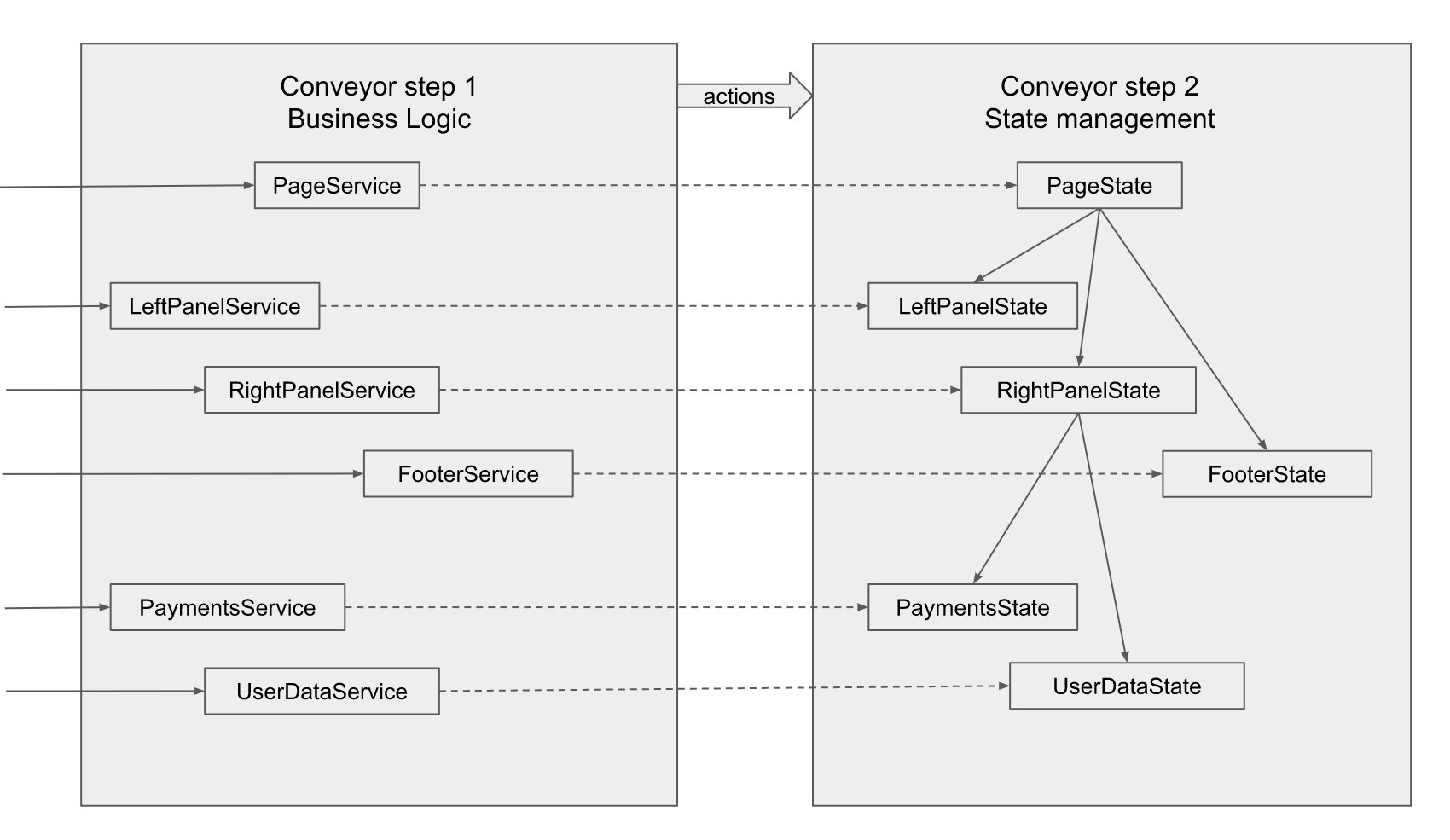
The names of the services correspond to the names of the UI components composed specifically for this example. The page is decomposed into the left panel, right panel and footer, it is also supposed to place some components on the left panel and footer, Payments and UserData are located on the right panel. It should be noted that the corresponding services and the corresponding states of the UI do not belong to the components, but correspond to, and have the format that these components accept.
If user input concerns a specific component, i.e. according to the requirements, this user input does not affect anything else on the screen, then the service corresponding to this particular component is called, its method creates an Action lying next to the definition of its state, i.e. interface (implies time script), and actually a reducer. The service naturally does not have a direct connection with the reducer of this component, so the arrow is dotted. Action is fed to the central entry point, st.
A more interesting case is when the requirement implies changing something in the state of two components at once, for example, in the UserData component, the person clicks the “show payments for the past year” button and the payments table should be updated, and the “total” field should change on the UserData component. In this case, the service corresponding to the right panel should be called, the corresponding Action should be thrown, and the right panel reducer should take appropriate actions on its state and its state fields, calling the corresponding pure functions. Just like in the example that I gave in the motivation of architecture. In the same way, if we need to update a lot of everything on the page, for example, if another user is selected, then, having reloaded all the data, in the page service we need to call the action of the page reducer level, which will update everything at once. Alternatively for example, if the data for the left and right panels can be loaded separately, showing separate progress indicators, then it is allowed to call the corresponding methods of the left panel and right panel service from the page service. You can replay this action as you like, you can combine these requests in parallel, you can sequentially, you can independently, as best suited to the requirements.
The third step of the conveyor
As I said, subscription to the state should be one. In this example, this page-level subscription. The page assumes a similar code
import {store} from ...
import {LeftPanel, RightPanel, Footer } from ...
export class Page extends React.Component {
componentWillMount() {
store.subscribe(() => this.setState(store.getState()));
}
render() {
return (
Title here
Further, this very division into smart and stupid components is assumed, the component responsible for the right panel is specific to this page, it is not assumed that it will be called somewhere else, so you can make it smart. That is, he must know which particular stimuli need to be triggered by the user's specific actions. And the UserData component can be made silly at will. And in one scenario, one service together with the corresponding reducer can manage its data in memory, and in another scenario, on another page, another service will call asynchronous methods.
It will look something like this
import {rightPanelService, userDataService} from ...
import {UserData } from ...
export class RightPanel extends React.PureComponent{
render() {
const state = this.props.state;
return (
rightPanelService.lastYearClicked()}
onUserNameChanged={(userName) => userDataService.userNameChanged(userName)} />
);
}
}
Here you can note that PureComponent is used, this means that if the rightPanel field has the same value when updating the state on the page in this state, if the changes applied only to other parts of the page, but not this one, then all rendering of the right panel and below will be cut off . This has the positive effect of pure reducer code on rendering performance. Previously, this PureComponent had to be written by yourself, since its implementation is extremely simple, or imported from another library of the Redux author, but now such a component is included directly in the react. In the hangar (versions 2, 4, 5 ...), the component update strategy is responsible for this. There you can also define the rule that if none of its @ Inputs has changed (reference equality is implied), then the dirty check of this component,
Next, the UserData component itself
export function UserData({state, onLastYearClicked, onUserNameChanged}) {
return (
onUserNameChanged(newVal)} />
...etc.
);
}
Extreme testing
Another thought visited me not so long ago. In fact, it turns out that the frontend application, which lacks logic, can function even without markup rendering. And if you bring such facts to discussion:
1) calling the browser is the most expensive operation in terms of time in the behavior tests of the UI layer.
2) The functionality of the markup is relatively small in comparison with the rest of the application
3) The markup is expensive to test in terms of developer costs, and the elimination of bugs found, such as crawling some elements onto others, etc. usually very cheap.
those. testing costs are not worth the bugs that they can identify.
But what if you test such an application directly in nodeJS? Without opening the browser, without performing any rendering, create a store directly in the test, call service methods, simulate user actions, by calling irritant methods, and test the data that turned out in the store as a result of such operations. You can have time to test much more, because you don’t even need to write the code for interacting with selenium (or whatever you use there), and the tests will go tens or even hundreds of times faster than regular ones.
Of course, there remains the option of additionally checking the launch of the application in the browser, you can even go to each page once, test how routing works, and subscription in the root of the pages. And such a test can be put in the same place where the long-term load test lies, which runs once every two weeks before delivery, well, or overnight. And most of the tests, which are still behavior tests and up to the level of unit tests, have not yet rolled up, but they are already moving fast enough, so you can run them on every commit, but at least on any sneeze in the development process.
Unfortunately, such a trick is unlikely to work with an angular. Since for the functioning of the application all services will be wrapped in @Injectable, and you will use the Http angular service for backend requests. Attempting to abandon the dependency injection mechanism plus using the native fetch instead of Http and Promise instead of Observable may fail, there is a great risk of running into a script not supported by the zone.js library, for example, it is known that async / await is not supported.
In the end
In the next article, I plan to squeeze out a solution from myself that allows me to simplify my life with redux and automatically generate three out of four pieces of code on the fly. The solution applies only to typescript, as based on the fact that you describe your state tree in interfaces.