How to switch to microservices and not break production
Today we’ll tell you how a monolithic solution was transferred to microservices. From our application around the clock passes from 20 to 120 thousand transactions per day. Users work in 12 time zones. At the same time, functionality was added a lot and often, which is quite difficult to do on a monolith. This is why the system needed stable 24/7 operation, i.e. HighLoad, High Availability and Fault Tolerance.
We are developing this product according to the MVP model . Architecture changed in several stages following the requirements of the business. Initially, it was not possible to do everything at once, because no one knew what the solution should look like. We moved around the Agile model, iterating over and expanding functionality.
Initially, the architecture looked like this: we had MySql with the only war, Tomcat and Nginx for proxying requests from users.
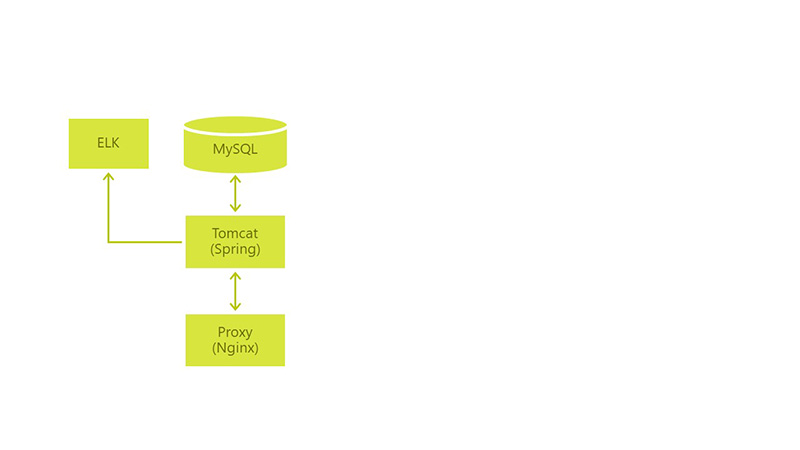
Environment (& minimum CI / CD):
The development was built on the basis of user scenarios. Already at the start of the project, most of the scripts fit into a kind of workflow. But still, not all, and this circumstance complicated our development and did not allow us to carry out “deep design”.

In 2015, our application saw production. Industrial operation has shown that we lack flexibility in the application, its development and in sending changes to prod-servers. We wanted to achieve High Availability (HA), Continuous Delivery (CD) and Continuous Integration (CI).
Here are the problems that needed to be solved in order to come to HI, CD, CI:
We began to solve all these problems one by one. And the first thing they took up was the changing product requirements.
Challenge: Changing product requirements and new use cases.
Technological answer: The first microservice appeared - they took part of the business logic into a separate war file and put it into Tomcat.
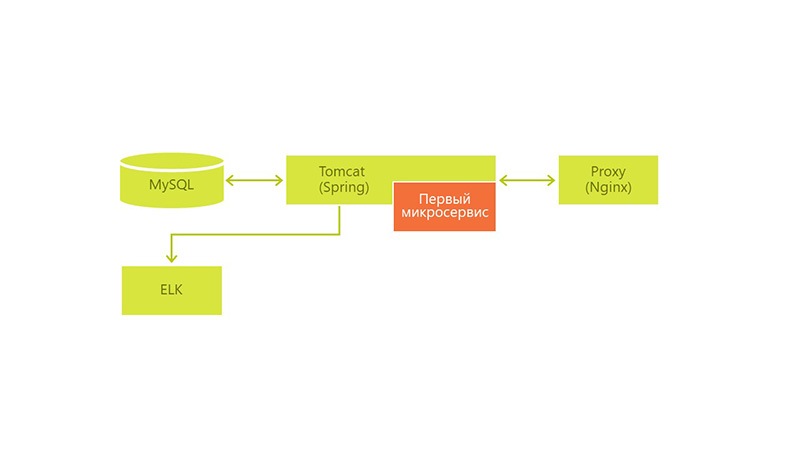
Another task of the form came to us: by the end of the week, update the business logic in the service and we decided to put this part in a separate war-file and put it in the same Tomcat. We used Spring Boot for speed of configuration and development.
We made a small business function that solves the problem with periodically changing user settings. In the event of a change in business logic, we would not have to restart the entire Tomcat, lose our users for half an hour and restart only a small part of it.
After successfully rendering the logic according to the same principle, we continued to make changes to the application. And from the moment when tasks came to us that radically changed something inside the system, we took out these parts separately. Thus, we constantly accumulated new microservices.
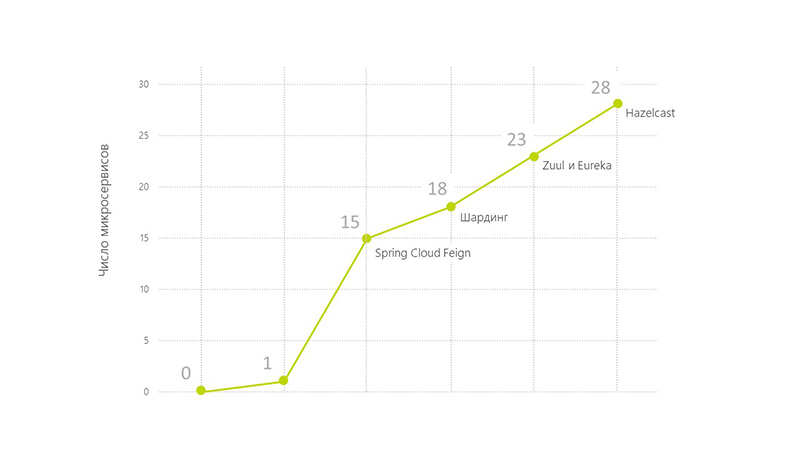
Challenge: Microservice already 15. The typing problem.
Technical answer: Spring Cloud Feign.
The problems did not resolve by themselves just because we began to cut our solutions into microservices. Moreover, new problems began to arise:
New problems have increased the restart time of all Tomcat during technical work. It turns out that we complicated our work.
The problem with typing, of course, did not arise by itself. Most likely, over the course of several releases, we simply ignored it, because we found these errors at the testing stages or during development and managed to do something. But when several errors were discovered just halfway into production and required urgent correction, we introduced regulations or started using tools that solve this problem. We noticed Spring Cloud Feign, a client library for http requests.
- there is little overhead for implementation in the project,
- it generated the client itself,
- you can use one interface both on the server and on the client.
He solved our typing problems by the fact that we formed customers. And for the controllers of our services, we used the same interfaces as for the formation of customers. So typing problems went away.
Business Challenge: 18 microservices, now system downtime is unacceptable.
Technical answer: architecture change, server expansion.
We still have a problem with downtime and rolling out new versions, there is a problem with restoring a Tomcat session and releasing resources. The number of microservices continued to grow.
The deployment process of all microservices took about an hour. From time to time, I had to restart the application due to a tomcat resource release problem. There were no easy ways to do this more quickly.
We began to think about how to change the architecture. Together with the infrastructure solutions department, we built a new solution based on what we already had.
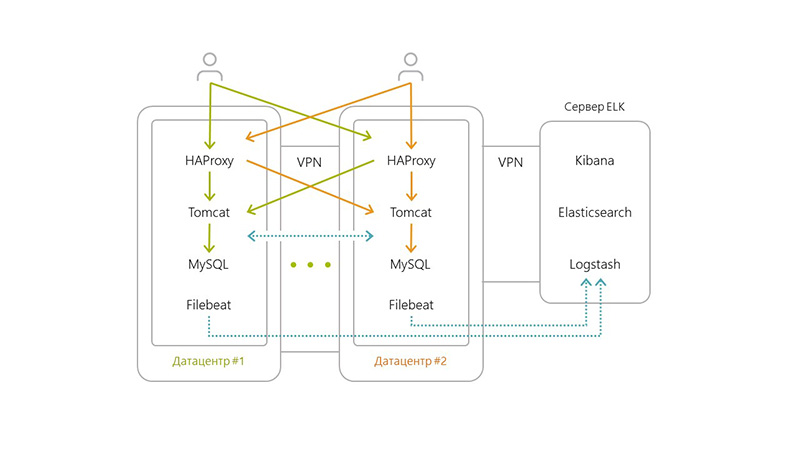
The architecture changed its appearance as follows:
The technologies used were as follows:
Accordingly, when a request came from the user to the services in Tomcat, they simply requested data from MySQL. The data that required integrity was collected from all servers and glued together (all requests were through the API).
Applying this approach, we lost a little in data consistency, but we solved the current problem. The user could work with our application in any situations.
So big problems were solved. Gone easy to use users. Now they did not feel when we rolled update.
Business Challenge: 23 microservices. Problems with data consistency.
Technical solution: launching services separately from each other. Improved monitoring. Zuul and Eureka. Simplified the development of individual services and their delivery.
Problems kept popping up. This is how our redela looked:
Thinking, we decided that launching the services separately from each other would solve our problem - if we would not start the services in one Tomcat, but each in its own on the same server.
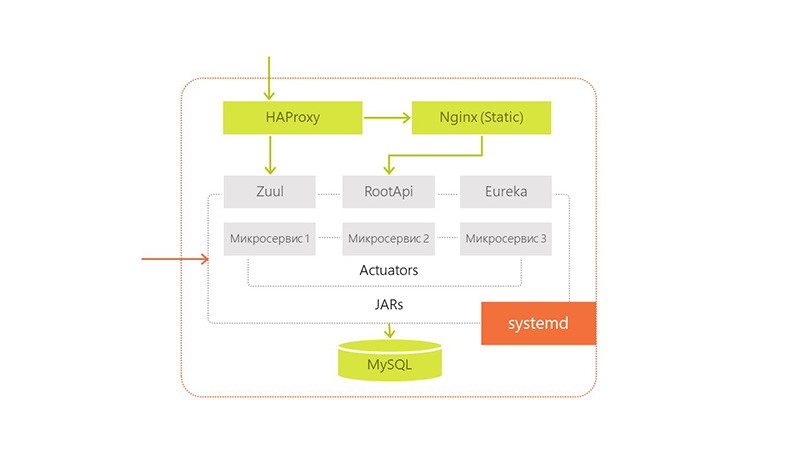
But other questions arose: how do the services now communicate with each other, which ports should be open to the outside?
We selected a number of ports and distributed them to our modules. In order not to need to keep all this information about ports somewhere in a pom-file or general configuration, we chose Zuul and Eureka to solve these problems.
To improve monitoring, we added Spring Boot Admin from the existing stack to understand what is happening on which service.
We also began to transfer our dedicated services to a stateless architecture in order to get rid of the problems of deploying several identical services on the same server. This gave us horizontal scaling within a single data center. Inside the same server, we ran different versions of the same application when updating, so that even there was no downtime.
It turned out that we approached Continuous Delivery / Continuous Integration in that we simplified the development of individual services and their delivery. Now there was no need to fear that the supply of one service would cause a leak of resources and it would be necessary to restart the entire service.
Simple when rolling out new versions still remained, but not entirely. When we updated several jars on the server one by one, this happened quickly. And there were no problems on the server when updating a large number of modules. But restarting all 25 microservices during the update took a very long time. Although faster than inside Tomcat, which does this consistently.
We also solved the problem with freeing up resources by running everything with a jar, and the system Out of memory killer dealt with leaks or problems.
Business Challenge: 28 microservices. A lot of information that needs to be managed.
Technical Solution: Hazelcast.
We continued to implement our architecture and realized that our basic business transaction covers several servers at once. It was inconvenient for us to send a request to a dozen systems. Therefore, we decided to use Hazelcast for event messaging and for systematic work with users. Also for subsequent services they used it as a layer between the service and the database.

We finally got rid of the consistency problem of our data. Now we could save any data to all databases simultaneously, without doing any unnecessary actions. We told Hazelcast to which databases it should store incoming information. He did this on every server, which simplified our work and allowed us to get rid of sharding. And so we moved on to application-level replication.
Also now we began to store the session in Hazelcast and used it for authorization. This allowed to transfer users between servers unnoticed by them.
Business Challenge: You need to speed up the release of updates in production.
Technical solution: the deployment pipeline of our application, GitFlow for working with code.
Together with the number of microservices, the internal infrastructure also developed. We wanted to expedite the delivery of our services to production. To do this, we implemented a new deployment pipeline for our application and switched to GitFlow for working with code. SI began to collect and run tests for each commit, run unit tests, integration tests, add artifacts with the application delivery.
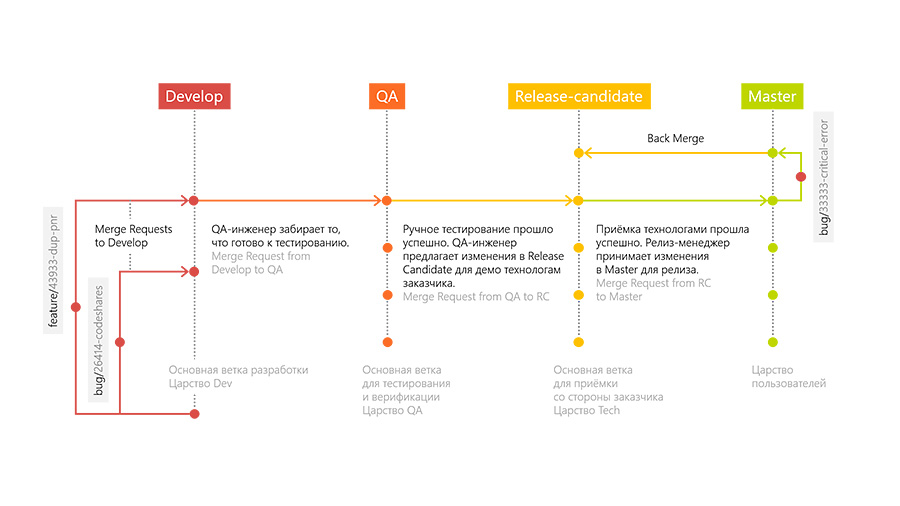
To do this quickly and dynamically, we deployed several GitLab runners that ran all these tasks to push developers. Thanks to the approach of GitLab Flow, we have several servers: Develop, QA, Release-candidate and Production.
Development is as follows. The developer adds new functionality in a separate branch (feature branch). After the developer has finished, he creates a request to merge his branch with the main branch of development (Merge Request to Develop branch). Other developers look at the merger request and accept it or do not accept it, after which the comments are corrected. After merging, a special environment unfolds in the trunk branch, on which tests for raising the environment are performed.
When all these stages are completed, the QA engineer takes the changes to his “QA” branch and conducts testing on the previously written test cases for the feature and research testing.
If the QA engineer approves the work done, then the changes go to the Release-Candidate branch and are deployed in an environment that is accessible to external users. In this environment, the customer accepts and verifies our technologies. Then we distill it all into Production.
If at some stage there are bugs, then it is in these branches that we solve these problems and their merge in Develop. We also made a small plugin so that Redmine can tell us what stage the feature is at.
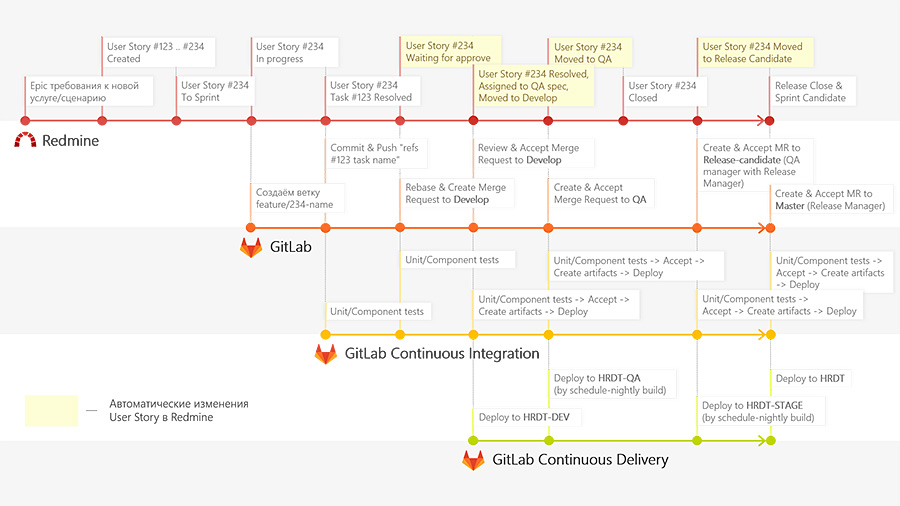
This helps testers to see at what stage you need to connect to the task, and developers to fix bugs, because they see at what stage the error occurred, can go to a specific branch and play it there.
Business Challenge: Switch between servers without downtime.
Technical solution: Packaging in Kubernetes.
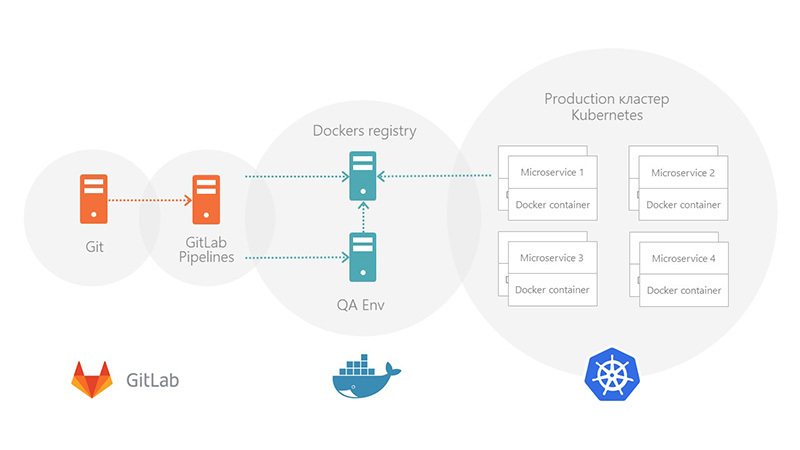
Now, at the end of the deployment, technical experts report jerkings to PROD servers and restart them. This is not very convenient. We want to automate the system’s work by implementing Kubernetes and linking it to the data center, updating them and rolling them all at once.
To move on to this model, we need to finish the following work.
We are developing this product according to the MVP model . Architecture changed in several stages following the requirements of the business. Initially, it was not possible to do everything at once, because no one knew what the solution should look like. We moved around the Agile model, iterating over and expanding functionality.
Initially, the architecture looked like this: we had MySql with the only war, Tomcat and Nginx for proxying requests from users.
Environment (& minimum CI / CD):
- Dev - Deploy by Push in develop,
- QA - once a day with develop,
- Prod - by button with master,
- Manual integration tests,
- Everything works on Jenkins.
The development was built on the basis of user scenarios. Already at the start of the project, most of the scripts fit into a kind of workflow. But still, not all, and this circumstance complicated our development and did not allow us to carry out “deep design”.
In 2015, our application saw production. Industrial operation has shown that we lack flexibility in the application, its development and in sending changes to prod-servers. We wanted to achieve High Availability (HA), Continuous Delivery (CD) and Continuous Integration (CI).
Here are the problems that needed to be solved in order to come to HI, CD, CI:
- simple when rolling out new versions - deploy applications took too long,
- a problem with changing product requirements and new user cases - it took too much time to test and validate even with small fixes,
- a problem with restoration of sessions at Tomcat: session management for the reservation system and third-party services, when restarting the application, the session was not restored by Tomcat,
- problems with the release of resources: I had to restart Tomcat sooner or later, a memory leak occurred.
We began to solve all these problems one by one. And the first thing they took up was the changing product requirements.
First microservice
Challenge: Changing product requirements and new use cases.
Technological answer: The first microservice appeared - they took part of the business logic into a separate war file and put it into Tomcat.
Another task of the form came to us: by the end of the week, update the business logic in the service and we decided to put this part in a separate war-file and put it in the same Tomcat. We used Spring Boot for speed of configuration and development.
We made a small business function that solves the problem with periodically changing user settings. In the event of a change in business logic, we would not have to restart the entire Tomcat, lose our users for half an hour and restart only a small part of it.
After successfully rendering the logic according to the same principle, we continued to make changes to the application. And from the moment when tasks came to us that radically changed something inside the system, we took out these parts separately. Thus, we constantly accumulated new microservices.
The main approach by which we began to single out microservices is the allocation of a business function or a business service as a whole.So we quickly separated services integrated with third-party systems, such as 1C.
The first problem is typing.
Challenge: Microservice already 15. The typing problem.
Technical answer: Spring Cloud Feign.
The problems did not resolve by themselves just because we began to cut our solutions into microservices. Moreover, new problems began to arise:
- the problem of typing and versioning in Dto between modules,
- how to deploy not one war-file in Tomcat, but many.
New problems have increased the restart time of all Tomcat during technical work. It turns out that we complicated our work.
The problem with typing, of course, did not arise by itself. Most likely, over the course of several releases, we simply ignored it, because we found these errors at the testing stages or during development and managed to do something. But when several errors were discovered just halfway into production and required urgent correction, we introduced regulations or started using tools that solve this problem. We noticed Spring Cloud Feign, a client library for http requests.
github.com/OpenFeign/feignWe chose it, because
cloud.spring.io/spring-cloud-netflix/multi/multi_spring-cloud-feign.html
- there is little overhead for implementation in the project,
- it generated the client itself,
- you can use one interface both on the server and on the client.
He solved our typing problems by the fact that we formed customers. And for the controllers of our services, we used the same interfaces as for the formation of customers. So typing problems went away.
Downtime First fight. Operability
Business Challenge: 18 microservices, now system downtime is unacceptable.
Technical answer: architecture change, server expansion.
We still have a problem with downtime and rolling out new versions, there is a problem with restoring a Tomcat session and releasing resources. The number of microservices continued to grow.
The deployment process of all microservices took about an hour. From time to time, I had to restart the application due to a tomcat resource release problem. There were no easy ways to do this more quickly.
We began to think about how to change the architecture. Together with the infrastructure solutions department, we built a new solution based on what we already had.
The architecture changed its appearance as follows:
- horizontally divided our application into several data centers,
- added Filebeat to each server,
- added a separate server for ELK, as the number of transactions and logs grew,
- several haproxy + Tomcat + Nginx + MySQL servers (this is how we provided High Availability).
The technologies used were as follows:
- Haproxy routing and balancing between servers,
- Nginx is responsible for distributing statics, tomcat was an application server,
- The peculiarity of the solution was that MySQL on each of the servers does not know about the existence of its other MySQLs,
- Due to the latency problem between datacenters, replication at the MySQL level was not possible. Therefore, we decided to implement sharding at the level of microservices.
Accordingly, when a request came from the user to the services in Tomcat, they simply requested data from MySQL. The data that required integrity was collected from all servers and glued together (all requests were through the API).
Applying this approach, we lost a little in data consistency, but we solved the current problem. The user could work with our application in any situations.
- Even if one of the servers crashed, we still had 3-4, which supported the operability of the entire system.
- We did not store backups on servers in the same data center in which they were made, but in neighboring ones. This helped us with disaster recovery.
- Fault tolerance was also addressed through several servers.
So big problems were solved. Gone easy to use users. Now they did not feel when we rolled update.
Downtime The second fight. Full value
Business Challenge: 23 microservices. Problems with data consistency.
Technical solution: launching services separately from each other. Improved monitoring. Zuul and Eureka. Simplified the development of individual services and their delivery.
Problems kept popping up. This is how our redela looked:
- We didn’t have consistency of data in the case of redip, so part of the functionality (not the most important) faded into the background. For example, when rolling a new application, statistics worked inferiorly.
- We had to drive users from one server to another in order to restart the application. It also took about 15-20 minutes. On top of that, users had to log in when switching from server to server.
- We also restarted Tomcat more and more often due to an increase in the number of services. And now I had to follow a large number of new microservices.
- Red-lay time increased in proportion to the number of services and servers.
Thinking, we decided that launching the services separately from each other would solve our problem - if we would not start the services in one Tomcat, but each in its own on the same server.
But other questions arose: how do the services now communicate with each other, which ports should be open to the outside?
We selected a number of ports and distributed them to our modules. In order not to need to keep all this information about ports somewhere in a pom-file or general configuration, we chose Zuul and Eureka to solve these problems.
Eureka - service discoveryEureka also improved our performance in High Availability / Fault Tolerance, as communication between services has now become possible. We set it up so that if the current data center does not have the right service, go to another one.
Zuul - proxy (to save context urls that were in Tomcat)
To improve monitoring, we added Spring Boot Admin from the existing stack to understand what is happening on which service.
We also began to transfer our dedicated services to a stateless architecture in order to get rid of the problems of deploying several identical services on the same server. This gave us horizontal scaling within a single data center. Inside the same server, we ran different versions of the same application when updating, so that even there was no downtime.
It turned out that we approached Continuous Delivery / Continuous Integration in that we simplified the development of individual services and their delivery. Now there was no need to fear that the supply of one service would cause a leak of resources and it would be necessary to restart the entire service.
Simple when rolling out new versions still remained, but not entirely. When we updated several jars on the server one by one, this happened quickly. And there were no problems on the server when updating a large number of modules. But restarting all 25 microservices during the update took a very long time. Although faster than inside Tomcat, which does this consistently.
We also solved the problem with freeing up resources by running everything with a jar, and the system Out of memory killer dealt with leaks or problems.
Fight Three, Information Management
Business Challenge: 28 microservices. A lot of information that needs to be managed.
Technical Solution: Hazelcast.
We continued to implement our architecture and realized that our basic business transaction covers several servers at once. It was inconvenient for us to send a request to a dozen systems. Therefore, we decided to use Hazelcast for event messaging and for systematic work with users. Also for subsequent services they used it as a layer between the service and the database.
We finally got rid of the consistency problem of our data. Now we could save any data to all databases simultaneously, without doing any unnecessary actions. We told Hazelcast to which databases it should store incoming information. He did this on every server, which simplified our work and allowed us to get rid of sharding. And so we moved on to application-level replication.
Also now we began to store the session in Hazelcast and used it for authorization. This allowed to transfer users between servers unnoticed by them.
From microservices to CI / CD
Business Challenge: You need to speed up the release of updates in production.
Technical solution: the deployment pipeline of our application, GitFlow for working with code.
Together with the number of microservices, the internal infrastructure also developed. We wanted to expedite the delivery of our services to production. To do this, we implemented a new deployment pipeline for our application and switched to GitFlow for working with code. SI began to collect and run tests for each commit, run unit tests, integration tests, add artifacts with the application delivery.
To do this quickly and dynamically, we deployed several GitLab runners that ran all these tasks to push developers. Thanks to the approach of GitLab Flow, we have several servers: Develop, QA, Release-candidate and Production.
Development is as follows. The developer adds new functionality in a separate branch (feature branch). After the developer has finished, he creates a request to merge his branch with the main branch of development (Merge Request to Develop branch). Other developers look at the merger request and accept it or do not accept it, after which the comments are corrected. After merging, a special environment unfolds in the trunk branch, on which tests for raising the environment are performed.
When all these stages are completed, the QA engineer takes the changes to his “QA” branch and conducts testing on the previously written test cases for the feature and research testing.
If the QA engineer approves the work done, then the changes go to the Release-Candidate branch and are deployed in an environment that is accessible to external users. In this environment, the customer accepts and verifies our technologies. Then we distill it all into Production.
If at some stage there are bugs, then it is in these branches that we solve these problems and their merge in Develop. We also made a small plugin so that Redmine can tell us what stage the feature is at.
This helps testers to see at what stage you need to connect to the task, and developers to fix bugs, because they see at what stage the error occurred, can go to a specific branch and play it there.
Further development
Business Challenge: Switch between servers without downtime.
Technical solution: Packaging in Kubernetes.
Now, at the end of the deployment, technical experts report jerkings to PROD servers and restart them. This is not very convenient. We want to automate the system’s work by implementing Kubernetes and linking it to the data center, updating them and rolling them all at once.
To move on to this model, we need to finish the following work.
- Bring our current solutions to a stateless architecture so that the user can send requests to all servers indiscriminately. Some of our services still support some kind of session data. This work also applies to database data replication.
- We also need to cut the last little monolith, which contains several business processes. This will lead us to the last major step - Continuous Delivery.
PS What has changed with the transition to microservices
- We got rid of the problem of changing requirements.
- We got rid of the problem of restoring sessions at Tomcat by transferring them to Hazelcast.
- When transferring users from one server to another, they do not have to log in.
- They solved all the problems with the release of resources, shifting them to the shoulders of the operating system.
- Typing and versioning problems were resolved thanks to Feign.
- We are confidently moving towards Continuous Delivery with the help of Gitlab Pipelines.