How we defeated a mess with iron and became bureaucrats from scratch

The difference between the documentation and the knowledge base: the documentation says that this device cools the air up to +18 degrees Celsius, and the knowledge base suggests that there is a rare bug when two sensors immediately show -51 thousand degrees and the device starts feverishly warming the air for the servers.
When you start a new small project, then your piece of iron is on the floor, there is no documentation, no nifig at all, and you can work. Then the project grows to the size of several hundred people and thousands of pieces of iron, and you need to know where exactly what lies, how to do it and so on.
We need a normal accounting of everything. Need documentation. You don’t need situations where you don’t know how much and what you have in your warehouse. I don’t need a story that when an engineer gets sick, the others call him at home and ask how he configured the server a year ago. I don’t need a story when someone said to raise 10 servers and two different people did it differently.
But we started with a simple one. The questions were: Who updates the server firmware? Who is responsible for the result? How it's done? Who should be warned? How to write a rollback plan and what to do if the server crashes? Someone wrote down all the phones you need in advance at least?
In general, the first rake will either kill you to hell, or they will teach you to do everything right. The second thing happened without a rake. Almost no rake. If you already have chaos, then our experience may be useful, because now we feel better.
Accounting for iron
The very first and simplest thing is to consider where what iron is and what it does. This is necessary for working with changes, for inventories and for proper accounting. For example, the memory bar in the server burned out - you need to have an incident with the vendor and change it. The vendor will immediately ask which bar the FRU number is for. The number of the bar is written on the piece of iron itself, and you can also see the number in IMM (but only when it works). That is, if there is no accounting, the engineer will go to the machine room, turn off the server, take out this bar (that is all, because he does not know FRU, but knows DIMM) and, squinting his eyes, will say its number.
It would be correct to scan all numbers from the bracket itself and start the server, or after starting the server, read the data on the brackets remotely (workers can be viewed remotely) in order to quickly understand exactly where the bad memory is and what its number is.
Well, in general, it would be nice to understand what server it is in, when the warranty expires, under which project it is used, what configuration and so on. When there are more than a hundred servers, it is already difficult to manage the infrastructure without a constantly updated map. I don’t want to leave this to the carriers of unique knowledge, like experienced operators, who know in memory what and where.
And you also need to have the described service-resource model, have some sort of spare parts, and understand what is in case of an incident. In the case of a new client in the same part that is closed under the GIS PD, we must well understand what equipment and how many licenses are there, what resources we have that we could connect.
We started here with such cards on each server:

As you can see, all the serial numbers are taken into account here, the technical characteristics of the hardware are rewritten and there may be comments from the operators on specific pieces of iron. And the card also indicates when support began and when support ends, that is, you can set up reports on this - it is useful for planning expenses.

And the card says where it all stands and what is stuck inside. You can see this hierarchy:
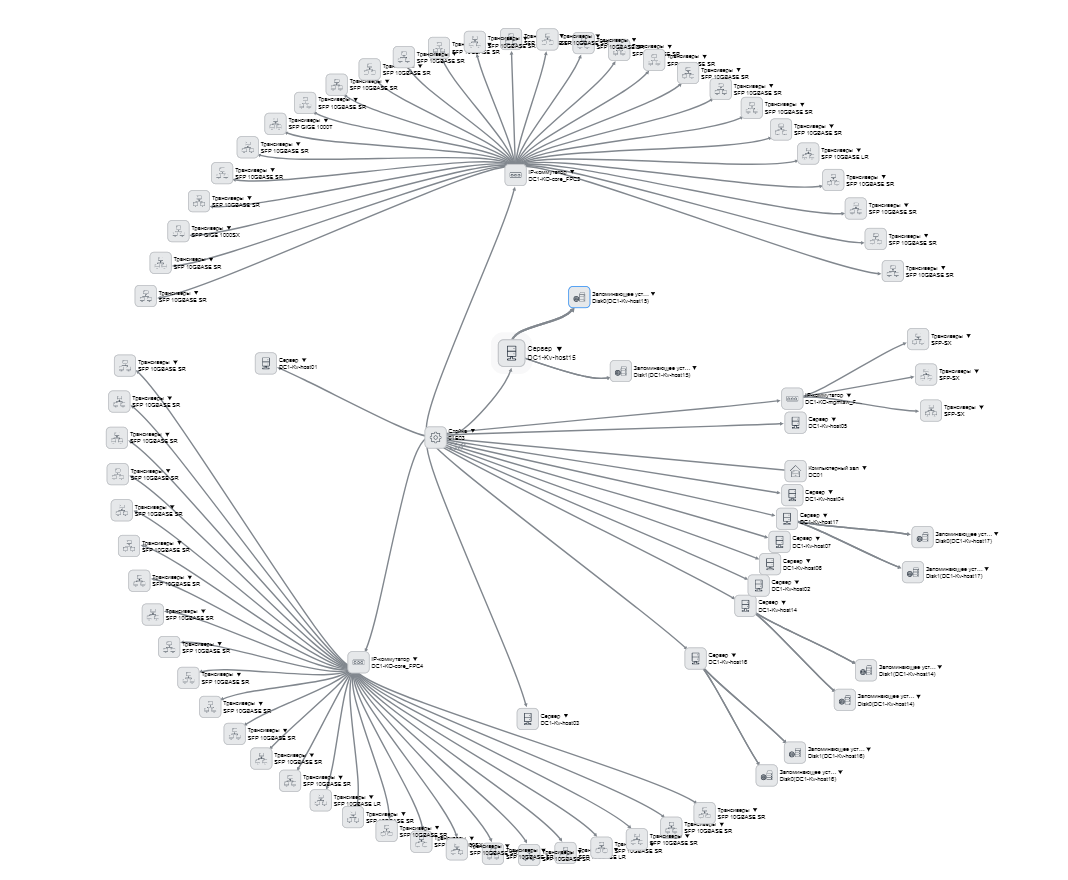
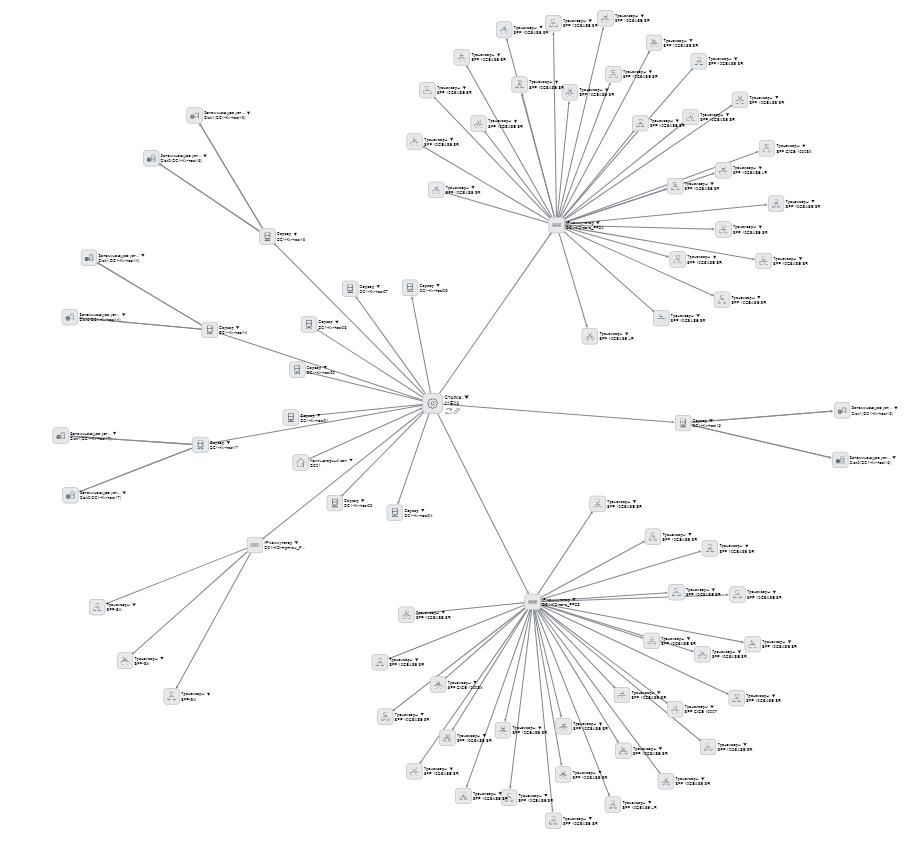
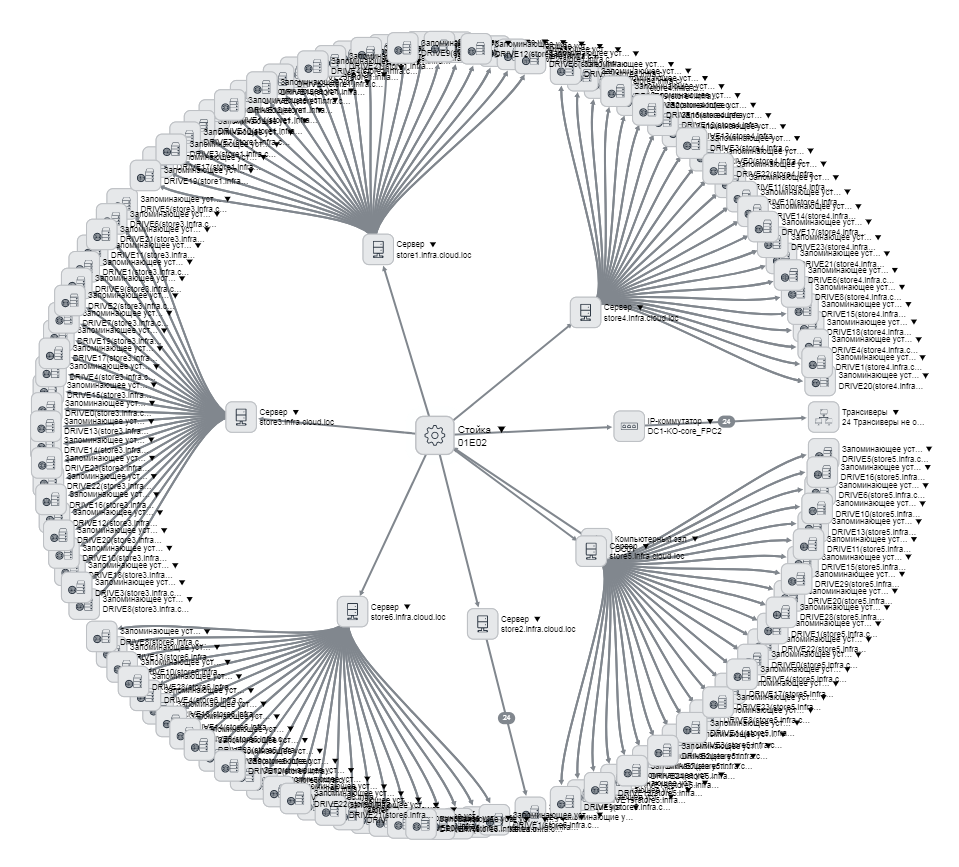
Cards are visible in this list:

We started with servers, then went to switches, transceivers, then we started making SCS elements - how much is, where what is, how it is connected. All servers are described - you can open any, see where it stands, in which data center, in which room, in which rack, in which unit, what is stuck, how it is connected. We made a bunch with accounting with fixed assets - they have the server taken into account as a unit, and now we know which card and network drives are installed in it. The disks are generally the same, differ in serial numbers, and where which one was previously unclear. And now even everyone is tied to a contract by which he is delivered. The practical convenience is that in bookkeeping a large amount of equipment is included in one main tool, and in our case it is distributed in racks that can be in different rooms, or even in general spare parts.

Example disk card, we know everything about it
Now processes
When the iron is warming the soul, for its further maintenance it is necessary to begin to register processes. For example, a bank enters the cloud and you need to add capacity under it. We need a problem statement with architecture and description to determine what to add, where to add, how to configure, how to organize a network.
We used to discuss this in the mail, the task was described in the task tracker, and then, when everyone agreed, the operation went on and did.
Now there are two types of processes. If the changes are standard, then all the individual parts of the processes such as “select a port there” (including a work plan, a return plan, a test plan, are there any contractors identified, etc.) are already described, and each one can appear on the calendar changes to ServiceNow. Since the process is standard, approvals are not necessary, responsible persons are immediately appointed, deadlines are set, and all this falls on specific performers. For each change there is an SLA, the applicant understands the time frame for completing his task.
An example is port allocation. A port can not be allocated everywhere. The first - there are, for example, 100 switches, different, each with 48 ports. The ports are 100 * 48, but this does not mean that any can be distinguished. Switches are located in different data centers, rooms. You need to understand on which ports you can allocate, on which - not. According to the standard change plan, the engineer knows where and which ports to allocate, will not allocate previously reserved ports. The second - the port must interact with something, respectively, different settings must be applied (security, speed, bandwidth limitations, QOS settings, etc.), all this is either described in the request or indicated in the change plan. Third, we know how much is allocated, how much is reserved, this is very useful for subsequent design.
If the changes are non-standard, then the change after registration goes to the change manager. There is a design, what and how, the architecture for implementing the change is being worked out, work plans, risks are assessed, rollback plans are determined, downtime is determined, who should be informed, those responsible for the work, after which everything is sent for approval ... In general, the script sequence is written with all forks from the last paragraph. The one who writes this describes the risks (which he sees) and prepares a rollback plan for each case. Then, through the process, the change goes to the change committee. CAB members are predefined for areas of responsibility. Then each participant looks at the change plan and rollback plans and agrees or not. If necessary - revision. If necessary - windows are consistent. After all approvals, tasks are set for performers. But in practice it turned out that we are not so big. In the combat system, the KAB is left “to grow” as an entity in the system, in fact, these are managers and / or architects.
Each change has a change manager (responsible executor), it is responsible for the change, the shift on duty monitors all changes, monitors the monitoring and communicates with customers in case of emergency. The change is closed only after the on-duty shift confirms operability, the change-manager checks according to the test plan and updates the CMDB and documentation.
The fact is that the result must be recorded in the documentation, and everything that was done during the change should be reflected in the asset base. Elementary update connectivity. But only after that everything will be closed.
Here we began to write such processes:
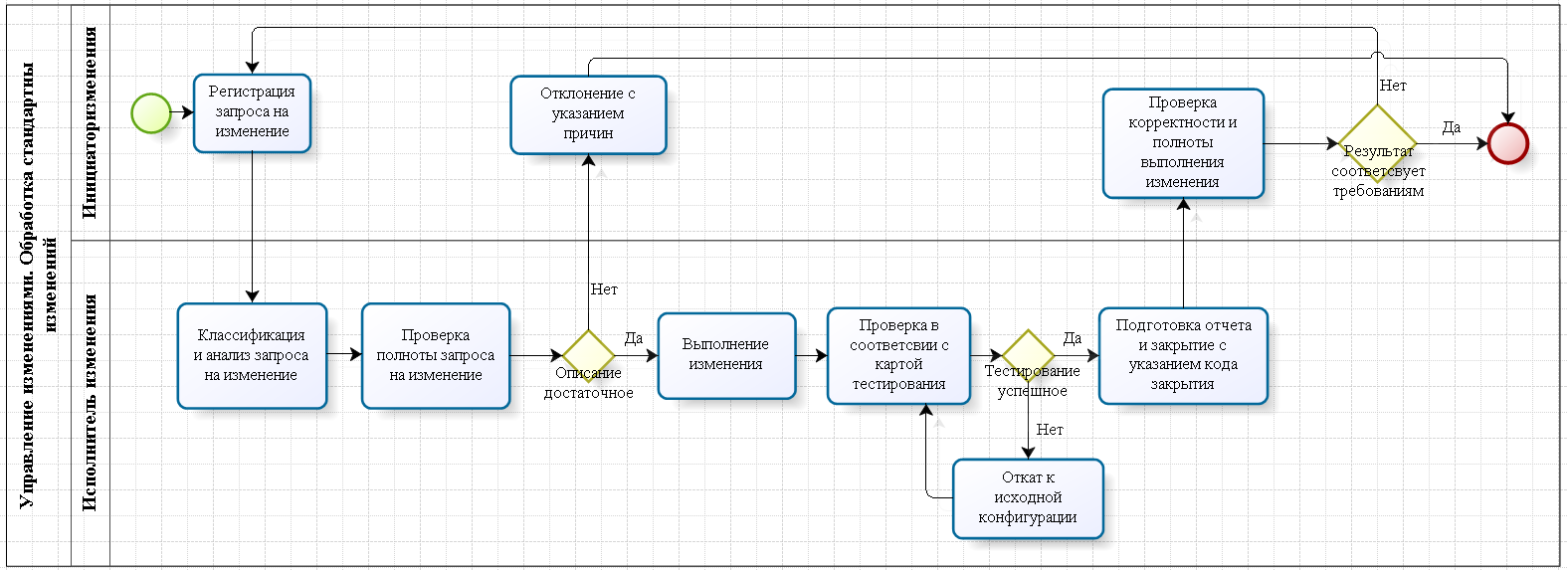
The difference with the process and without it is that with the process there is more documentation and bureaucracy, but it is clear what to do. Previously, whoever wanted to, he did so. It is clear that while there are few people, all this rested on unwritten standards. Grew up - it took them to write, plus without this it is impossible to manage a large number of processes. The area of responsibility has appeared. There are different SLAs for different cases. There was an obligation to prepare plans, to warn all interested, and also to coordinate and document everything at the end. Then all this was automated in ITSM:
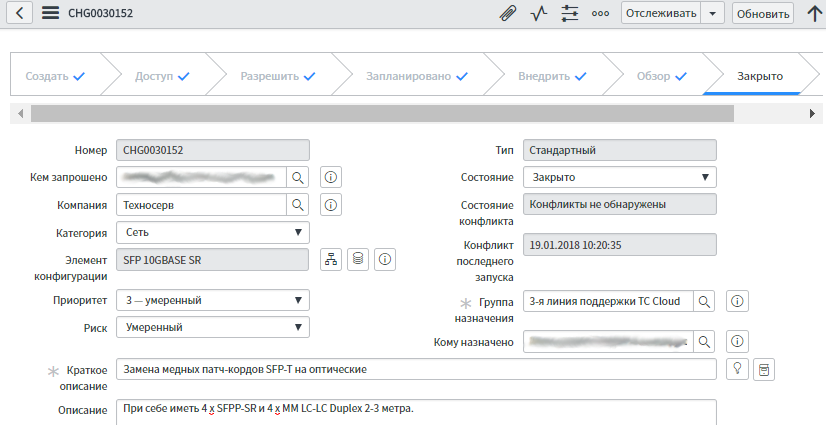
Knowledge base
All work within the framework of changes is associated with configuration items. By registering the change, we know that there is a standardized process: how the work should be performed, on what equipment, and a circle of people is defined - who agrees, who does it, who does what, if something goes wrong, and so on.
We immediately see the risks, and in the future - the cost of work.
But this is not enough.
We need a knowledge base that describes what the process does not describe. For example - a rare bug in the firmware. Or how best to assemble the rack. Or how to connect. Here is an example of a recording:
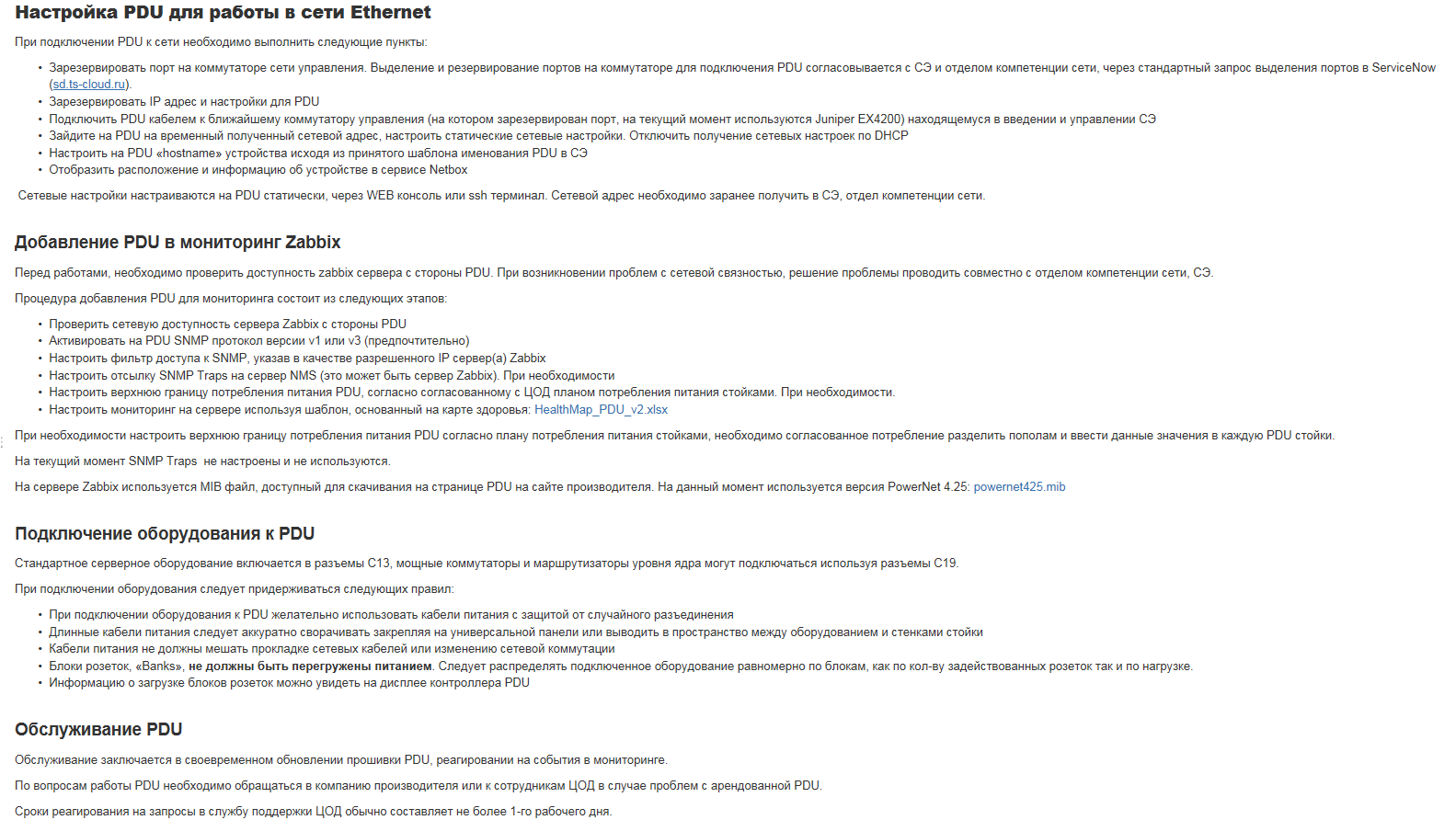
This is done mainly from documents written by an architect at the planning stage. But sometimes engineers and change managers add something new after completing work.
You have no idea what buzz to look at the entries about the piece of iron and know what they did to it and how before. And what a thrill it will be in 3-4 years - just can not convey.
Warehouse
The next part of the story is warehouse storage. We have spare parts, tools, packaging from test equipment. All this was stored right in our offices, where the shift on duty, the operation service and architects sat. When engineers gathered for installation in the data center, sometimes they went to the offices to collect equipment and consumables (patch cords, transceivers, etc.). This leads to chaos, and chaos is cool only at first.
Again, a bit of bureaucracy - and here we have described spare parts and accessories (more precisely, most, a number of things are still in the “box with little things” state). There is targeted storage in the software, but so far the warehouse is not ready to implement it organizationally - each piece will have coordinates in the form of space on the shelf. When the installation task is set for the engineer, something like “take this switch there somewhere, these SFPs here, these patch cords,” is attached to the task. Here are their racks, shelves. ”
Roles for Change
In part, I have already described change management. Another thing in this story is that we have a role distribution:
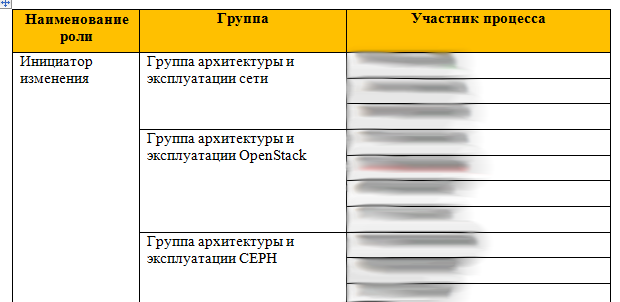
That is, if you are from a VMWare network group, you can only apply in the VMWare zone. Each role has a list of processes that it can do, and a list of tasks that its members can set. That is, the entire organizational structure of the company can also be entered in ITSM.
Who is fighting chaos?
We are fighting the whole team, but I am responsible for the result. By the way, there is still a lot of work. My position is called the “program manager”. This is something like a project manager with the task of maintaining a plan and a list of interdependent projects that need to be implemented to achieve a common goal.
Before that, I was engaged in putting things in order in retail, in particular, automated accounting and deliveries in a large retail chain of stores for correct accounting, reducing the cost of receiving and registering goods, and reducing the time for delivering goods to the shelf. I can say that in the IT company, the process of change is going much more smoothly - everyone understands why this is.
When it became clear that any new engineer can raise the documentation, raise how it was done, read the tuner’s logs (not only those where someone took care of the descendants by the kindness of the soul, but any) and did not collect the stories from colleagues, it’s clear where we are going.
There was nothing at the start, and we launched work from several sides. The full result has not yet been achieved, but over half a year we have become more understandable in working with iron, processes and changes. The cloud is evolving, and this is its logical step. It was not necessary to do this right away, but now is the time.
The other day, we are introducing a new warehouse into test operation and continue to fight chaos in other vectors. The work is even before the fence, but the results are visible to everyone. If it’s interesting, I can tell you a couple of retail stories - there the same projects are complicated by the fact that end users and heads of other departments actively resist them. Well, plus - you need to teach everyone, and for many - to win thinking "we worked normally, don’t touch it."
The text was prepared by Boris Kosolapov, project manager for Technoserv Cloud automation .